
注意力機制(attention)
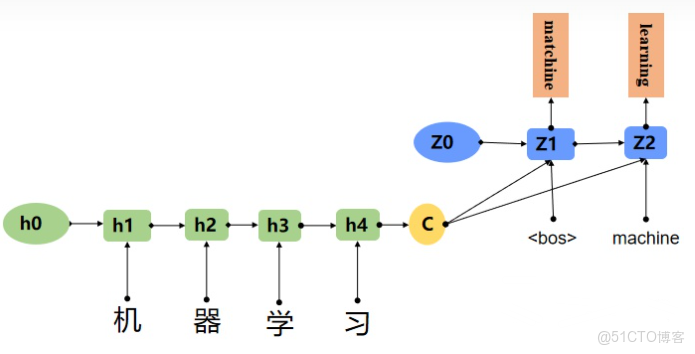
圖片展示的Encoder-Decoder框架沒有體現“注意力模型”,可以把它看做是注意力不集中分心模型。因為在生成目標句子的單詞時,不論生成哪個單詞,它們使用的輸入句子的語義編碼C都是一樣的,沒有任何區別。而語義編碼C是由原句子中的每個單詞經過Encoder編碼產生的,這意味着原句子中任意單詞對生成某個目標單詞來説影響力都是相同的,這就是模型沒有體現出注意力的緣由。
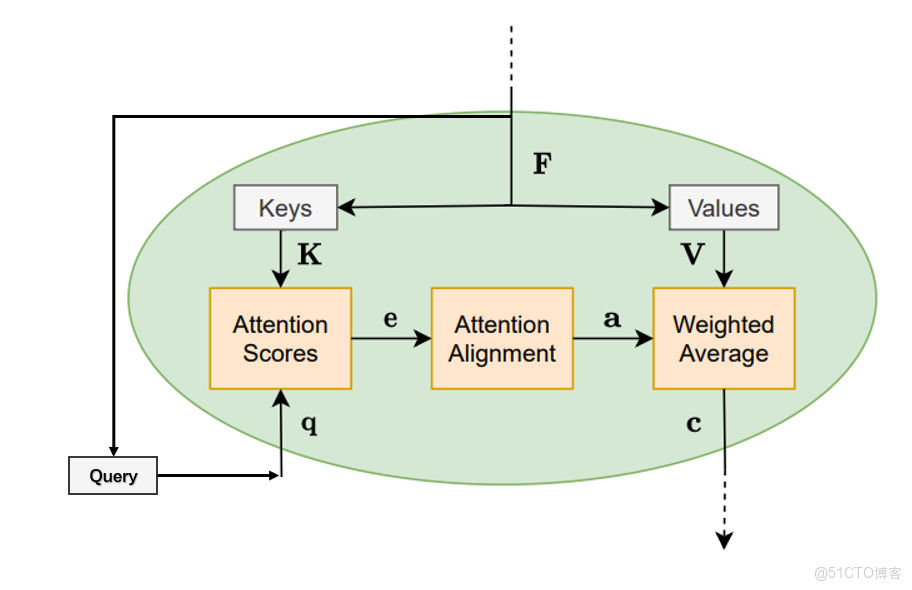
計算重要程度e常用的有以下三種方式:
- 計算Encoder的序列h與Decoder的序列h的餘弦相似度.
- 在1的基礎上,乘上一個Wa,Wa是需要學習的參數,從學習到Encoder和Decoder的隱藏的打分e。
- 設計一個前饋神經網絡,前饋神經網絡的輸入是Encoder和Decoder的兩個隱藏狀態,Va、Wa都是需要學習的參數。
再將e使用softmax進行歸一化就得到權重分數α
將得分分別除以一個特定數值8(K向量的維度的平方根,通常K向量的維度是64)這能讓梯度更加穩定
自注意力機制(self-attention)
如果注意力模型中注意力是完全基於特徵向量計算的,那麼稱這種注意力為自注意力
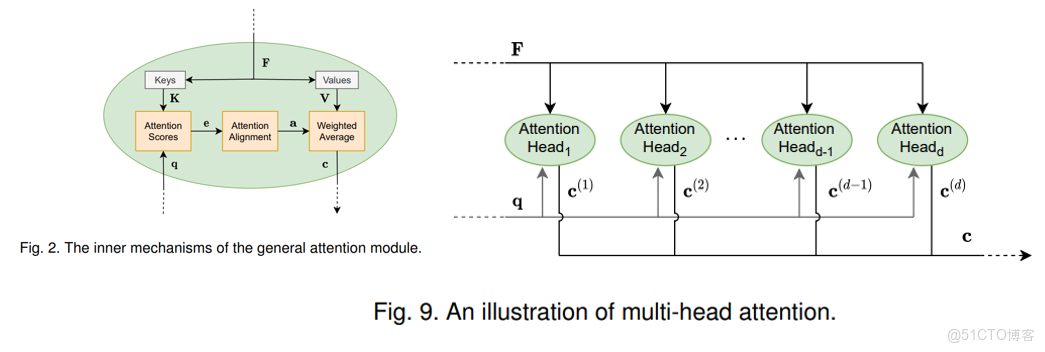
多頭注意力機制(multi-head attention)
多頭注意力通過利用同一查詢的多個不同版本並行實現多個注意力模塊來工作。其思想是使用不同的權重矩陣對查詢 q 進行線性變換得到多個查詢。每個新形成的查詢本質上都需要不同類型的相關信息,從而允許注意模型在上下文向量計算中引入更多信息。
作用:
- 第一個方面,他擴展了模型關注不同位置的能力,這對翻譯一下句子特別有用,因為我們想知道“it”是指代的哪個單詞。
- 第二個方面,他給了自注意力層多個“表示子空間”。對於多頭自注意力機制,我們不止有一組Q/K/V權重矩陣,而是有多組(論文中使用8組),所以每個編碼器/解碼器使用8個“頭”(可以理解為8個互不干擾自的注意力機制運算),每一組的Q/K/V都不相同。然後,得到8個不同的權重矩陣Z,每個權重矩陣被用來將輸入向量投射到不同的表示子空間。
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。