(resilient distributed dataset,RDD)是一個非常重要的分佈式數據架構,即彈性分佈式數據集。
它是邏輯集中的實體,在集羣中的多台機器上進行了數據分 區。通過對多台機器上不同RDD分區的控制,就能夠減少機器之間的數據重排(data shuffling)。Spark提供了“partitionBy”運算符,能夠通過集羣中多台機器之間對原始RDD進 行數據再分配來創建一個新的RDD。RDD是Spark的核心數據結構,通過RDD的依賴關係形 成Spark的調度順序。通過對RDD的操作形成整個Spark程序。
(1)RDD的兩種創建方式
1)從Hadoop文件系統(或與Hadoop兼容的其他持久化存儲系統,如Hive、 Cassandra、Hbase)輸入(如HDFS)創建。
2)從父RDD轉換得到新的RDD。
(2)RDD的兩種操作算子 對於RDD可以有兩種計算操作算子:Transformation(變換)與Action(行動)。
1)Transformation(變換)。 Transformation操作是延遲計算的,也就是説從一個RDD轉換生成另一個RDD的轉換操 作不是馬上執行,需要等到有Actions操作時,才真正觸發運算。
2)Action(行動) Action算子會觸發Spark提交作業(Job),並將數據輸出到Spark系統。
(3)RDD的重要內部屬性
1)分區列表。
2)計算每個分片的函數。
3)對父RDD的依賴列表。
4)對Key-Value對數據類型RDD的分區器,控制分區策略和分區數。
5)每個數據分區的地址列表(如HDFS上的數據塊的地址)。
RDD與分佈式共享內存的異同
RDD是一種分佈式的內存抽象,下表列出了RDD與分佈式共享內存(Distributed Shared Memory,DSM)的對比。在DSM系統中,應用可以向全局地址空間的任意位置進 行讀寫操作。DSM是一種通用的內存數據抽象,但這種通用性同時也使其在商用集羣上實現 有效的容錯性和一致性更加困難。 RDD與DSM主要區別在於,不僅可以通過批量轉換創建(即“寫”)RDD,還可以對任 意內存位置讀寫。RDD限制應用執行批量寫操作,這樣有利於實現有效的容錯。特別是,由 於RDD可以使用Lineage(血統)來恢復分區,基本沒有檢查點開銷。失效時只需要重新計 算丟失的那些RDD分區,就可以在不同節點上並行執行,而不需要回滾(Roll Back)整個程序。
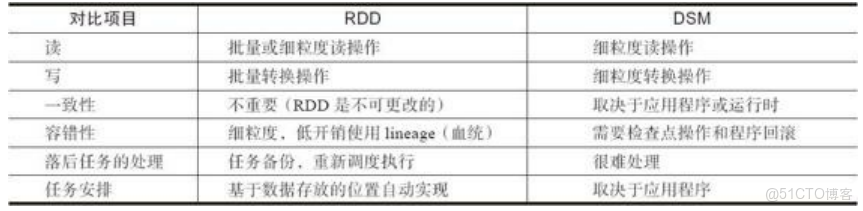
RDD任務劃分
RDD任務切分中間分為:Application、Job、Stage和Task
1)Application:初始化一個SparkContext即生成一個Application
2)Job:一個Action算子就會生成一個Job
3)Stage:根據RDD之間的依賴關係的不同將Job劃分成不同的Stage,遇到一個寬依賴則劃分一個Stage。
4)Task:Stage是一個TaskSet,將Stage劃分的結果發送到不同的Executor執行即為一個Task。
注意:Application->Job->Stage-> Task每一層都是1對n的關係。
例: wordCount