
Hadoop2.7.6學習
Hadoop的發展史

爬取全球的網站,然後計算頁面的PageRank
要解決網站的問題:
a:這些網站怎麼存放
b:這些網站應該怎麼計算
發佈了三篇論文
a:GFS(Google File System)
b:MapReduce(數據計算方法)
c:BigTable:HBase
Doug cutting 花費了自己的兩年業餘時間,將論文實現了出來
;.看到他兒子在牙牙學語時,抱着黃色小象,親暱的叫 hadoop,他靈光一閃,就把這技術命名為 Hadoop,而且還用了黃色小象作為標示 Logo,不過,事實上的小象瘦瘦長長,不像 Logo 上呈現的那麼圓胖。“我兒子現在 17 歲了,所以就把小象給我了,有活動時就帶着小象出席,沒活動時,小象就丟在家裏放襪子的抽屜裏。” Doug Cutting 大笑着説。Hadoop(java)
HDFS
MapReduce
Hadoop三大開源發行版本:Apache、Cloudera(CDH)、Hortonworks(HDP)。Apache版本最原始(最基礎)的版本,對於入門學習最好。Cloudera在大型互聯網企業中用的較多。Hortonworks文檔較好。
Apache Hadoop
官網地址:https://hadoop.apache.org/
下載地址:https://hadoop.apache.org/release.html
Cloudera Hadoop
官網地址:https://www.cloudera.com/downloads/cdh.html
下載地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
1)2008年成立的Cloudera是最早將Hadoop商用的公司,為合作伙伴提供Hadoop的商用解決方案,主要是包括支持、諮詢服務、培訓。
2)2009年Hadoop的創始人Doug Cutting也加盟Cloudera公司。Cloudera產品主要為CDH,Cloudera Manager,Cloudera Support
3)CDH是Cloudera的Hadoop發行版,完全開源,比Apache Hadoop在兼容性,安全性,穩定性上有所增強。Cloudera的標價為每年每個節點10000美元。
4)Cloudera Manager是集羣的軟件分發及管理監控平台,可以在幾個小時內部署好一個Hadoop集羣,並對集羣的節點及服務進行實時監控。
5)Cloudera的標價為每年每個節點4000美元。Cloudera開發並貢獻了可實時處理大數據的Impala項目。
Hortonworks Hadoop
官網地址:https://www.clouderacn.cn/products/hdp.html
下載地址:https://www.cloudera.com/downloads/hdp.html
1)2011年成立的Hortonworks是雅虎與硅谷風投公司Benchmark Capital合資組建。
2)公司成立之初就吸納了大約25名至30名專門研究Hadoop的雅虎工程師,上述工程師均在2005年開始協助雅虎開發Hadoop,貢獻了Hadoop80%的代碼。
3)雅虎工程副總裁、雅虎Hadoop開發團隊負責人Eric Baldeschwieler出任Hortonworks的首席執行官。
4)Hortonworks的主打產品是Hortonworks Data Platform(HDP),也同樣是100%開源的產品,HDP除常見的項目外還包括了Ambari,一款開源的安裝和管理系統。
5)HCatalog,一個元數據管理系統,HCatalog現已集成到Facebook開源的Hive中。Hortonworks的Stinger開創性的極大的優化了Hive項目。Hortonworks為入門提供了一個非常好的,易於使用的沙盒。
6)Hortonworks開發了很多增強特性並提交至核心主幹,這使得Apache Hadoop能夠在包括Window Server和Windows Azure在內的microsoft Windows平台上本地運行。定價以集羣為基礎,每10個節點每年為12500美元。
2018年10月,均為開源平台的Cloudera與Hortonworks公司宣佈他們以52億美元的價格合併。
官方網站:https://www.cloudera.com/
Cloudera 官方文檔: https://www.cloudera.com/documentation/enterprise/latest.html
兩家公司稱合併後公司將擁有2500客户、7.2億美元收入和5億美元現金,且沒有債務,宣佈了它們所謂了相對平等的合併。
兩大開源大數據平台Cloudera與Hortonworks宣佈合併,合併後的企業定位為企業數據雲提供商,推出了ClouderaDataPlatform(CDP),可以跨AWS、Azure、Google等主要公有云架構進行數據管理。2020年6月,Cloudera發佈CDP私有云,將本地部署環境無縫連接至公有云。
CDP的版本號延續了之前CDH的版本號,從7.0開始,目前最新的版本號為7.0.3.0。
那麼CDP對比之前的Cloudera Enterprise Data Hub(CDH企業版)與HDPEnterprise Plus(HDP企業版)到底在組件上發生了哪些變化呢?
由於HDP在國內市場上的市場佔有量很小,大部分公司都是採用CDH,所以對於HDP帶來的一些東西,使用CDH的用户和開發人員會比較陌生,下面帶大家詳細的瞭解一下CDP中的組件一些變化,也方便大家為在2022年以及之後的學習做好準備。
CDP、CDH、HDP中都包含的部分
Apache Hadoop(HDFS/YARN/MR)
Apache HBase
Apache Hive
Apache Oozie
Apache Spark
Apache Sqoop
Apache Zookeeper
Apache Parquet
Apache Phoenix(*CDH中需要額外安裝)最關鍵的一點:CDP的組件代碼在github上找不到,是不再開源了,CDP7以後就沒有社區版了。



Hadoop 1.x ---> 3.x
官網:https://hadoop.apache.org/
注意:課程中的hadoop版本以CDH版本為準,穩定且主流,目前國內主流的是2.x,如果面試的時候説你用的是3.x可能會被。。。。並且2.x的變化都不大
Hadoop Common:基礎型功能
Hadoop Distributed File System (HDFS™):一種分佈式文件系統,可提供對應用程序數據的高吞吐量訪問。負責存放數據
Hadoop YARN:作業調度和集羣資源管理的框架。負責資源的調配
Hadoop MapReduce:基於 YARN 的系統,用於並行處理大型數據集。大數據的計算框架
Hadoop框架透明地為應⽤提供可靠性和數據移動。它實現了名為MapReduce的編程範式:應⽤程序被分割成許多⼩部分,⽽每個部分都能在集羣中的任意節點上執⾏或重新執⾏。此外,Hadoop還提供了分佈式⽂件系統,⽤以存儲所有計算節點的數據,這為整個集羣帶來了⾮常⾼的帶寬。MapReduce和分佈式⽂件系統的設計,使得整個框架能夠⾃動處理節點故障。它使應⽤程序與成千上萬的獨⽴計算的電腦和PB級的數據。
一句話簡述:Hadoop是一個適合海量數據的分佈式存儲和分佈式計算的平台。(面試必問!!!!)
國內現在大數據的行情
1)大數據的薪資屬於同行業最高的
2)相對來講這個技術比較穩定,Hadoop只是大數據的一員或者説是基石,大數據開發環境已經穩定。
(説到這的時候,帶同學畫一下目前主流的框架圖,熟悉主題學習框架和功能,畫圖總結上面的概念)
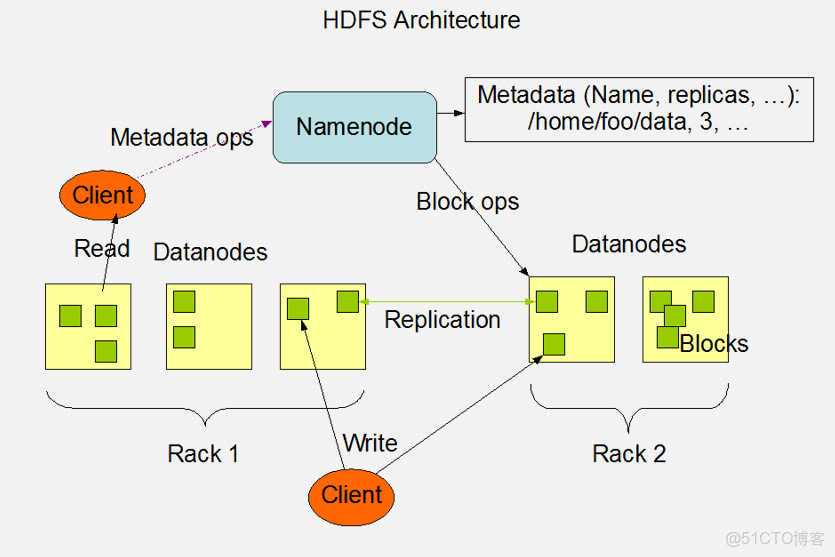
分佈式文件系統架構
一、名詞科普
Apache基金會是專門為支持開源軟件項目而辦的一個非盈利性組織
服務器(節點):企業裏任務和程序基本都是運行在服務器上。服務器內存和cpu以及硬盤等資源和性能遠高於pc機可以理解為我們的一台筆記本/台式機在這裏可以認為是我們的一台虛擬機後面學習中,我們會把一台服務器稱為一個節點
機架:負責存放服務器的架子可以理解為鞋架(^_^)


二、分佈式文件系統(從這開始,下面都是屬於Hadoop中的原理)
1、FS File System
文件系統時極域硬盤之上的文件管理的工具
我們用户操作文件系統可以和硬盤進行解耦
2、DFS Distributed File System
分佈式文件系統
將我們的數據存放在多台電腦上存儲
分佈式文件系統有很多,HDFS(Hadoop Distributed FileSyetem)是Hadoop自帶的分佈式文件系統
HDFS是mapreduce計算的基礎
三、文件切分的思想(引出分而治之的思想 第一個核心思想)
a. 文件存放在一個磁盤上效率肯定是最低的
讀取效率低
如果文件特別大會超出單機的存儲範圍
b. 字節數組
文件在磁盤真實存儲文件的抽象概念
數組可以進行拆分和組裝,源文件不會收到影響
c. 切分數據
對字節數組進行切分
d. 拼接數據
按照數組的偏移量將數據連接到一起,將字節數組連接到一起
e. 偏移量
當前數據在數組中的相對位置,可以理解為下標
數組都有對應的索引,可以快速定位數據
f. 數據存儲的原理:
不管文件的大小,所有的文件都是由字節數組構成
如果我們要切分文件,就是將一個字節數組分成多份
我們將切分後的數據拼接到一起,數據還可以繼續使用
我們需要根據數據的偏移量將他們重新拼接到一起
四、Block拆分標準
數據塊Block
a. 是磁盤進行數據 讀/寫的最小單位,數據被切分後的一個整體被稱之為塊
b. 在Hadoop 1默認大小為64M,在Hadoop 2及其之後默認大小為128M塊,這麼大是為了最小化尋址開銷
c. 同一個文件中,每個數據塊的大小要一致除了最後一個節點外不同文件中,塊的大小可以不一致文件大小不同可以設置不同的塊的數量HDFS中小於一個塊的大小的文件不會佔據整個塊的空間
d. 真實情況下,會根據文件大小和集羣節點的數量綜合考慮塊的大小
e. 數據塊的個數=Ceil(文件大小/每個塊的大小)
拆分的數據塊需要等大(面試題)
a. 數據計算的時候簡化問題的複雜度(否則進行分佈式算法設計的時候會因為數據量不一很難設計)
c. 通過偏移量就知道這個塊的位置
d. 相同文件分成的數據塊大小應該相等
注意事項
a. 只要有任意一個塊丟失,整個數據文件被損壞
b. HDFS中一旦文件被存儲,數據不允許被修改修改會影響偏移量
修改會導致數據傾斜(單節點數據量過多)
修改數據會導致蝴蝶效應
c. 但是可以被追加(一般不推薦)追加設置需要手動打開
d. 一般HDFS存儲的都是歷史數據.所以將來Map Reduce都用來進行離線數據的處理
. 塊的大小一旦文件上傳之後就不允許被修改 128M-512M
五、Block數據安全
a. 只要有任意一個塊丟失,整個數據文件被損壞
b. 肯定要對存儲數據做備份
c. HDFS是直接對原始數據進行備份的,這樣能保證恢復效率和讀取效率
d. 備份的數據肯定不能存放在一個節點上,使用數據的時候可以就近獲取數據
e. 備份的數量要小於等於節點的數量
f. 每個數據塊默認會有三個副本,相同副本是不會存放在同一個節點上
g. 副本的數量可以變更可能近期數據被分析的可能性很大,副本數可以多設置幾個後期數據很少被分析,可以減少副本數
六、Block的管理效率
需要專門給節點進行分工
- 存儲 DataNode 實際存儲數據的節點
- 記錄 NameNode
- 日誌 Secondary NameNode
java模擬切分文件
切分文件
package com.shujia;
import java.io.*;
import java.util.ArrayList;
public class SplitFileBlock {
public static void main(String[] args) throws Exception {
//將數據讀取進來
//字符緩衝輸入流
BufferedReader br = new BufferedReader(new FileReader("data/students.txt"));
int index = 0;
//字符緩衝輸出流
BufferedWriter bw = new BufferedWriter(new FileWriter("data/blocks2/block---" + index));
//現在是假設一行數據是1m,沒128m數據,就生成一個block塊,不到128m也會生成一個block塊
//每次讀到128*1.1約等於140行的數據,就寫入128行,剩下的12行計入下一次block塊中去存儲
//定義一個集合,用於存儲,讀取的內容
ArrayList<String> row = new ArrayList<>();
String line = null;
//定義一個變量,記錄讀取的行數
int offset = 0;
//定義一個變量,記錄讀取的是哪一個block塊
int rowNum = 0;
while ((line = br.readLine()) != null) {
row.add(line);
offset++;
//當我們的偏移量,128*1.1約等於140行的數據,就寫入128行,剩下的12行計入下一次block塊中去存儲
if (offset == 140) {
rowNum = 128 * index;
//循環128次,將集合存儲的數據,寫入到block塊中
for (int i = rowNum; i <= rowNum + 127; i++) {
String s = row.get(i);
bw.write(s);
bw.newLine();
bw.flush();
}
index++;
//將offset設置為12
offset = 12;
bw = new BufferedWriter(new FileWriter("data/blocks2/block---" + index));
}
}
//把剩餘的數據寫到一個block塊中
for(int i = row.size()-offset;i<row.size();i++){
String s = row.get(i);
bw.write(s);
bw.newLine();
bw.flush();
}
//釋放資源
bw.close();
br.close();
}