
##我的需求:x86上Nvidia顯卡訓練好的模型用在AI推理卡上,host端運行C++主程序device端的AI推理卡提供NN算力,進行推理##
華為AI 推理卡
環境配置
安裝ubuntu系統、AI推理卡環境
1,安裝ubuntu20.04.4 Ubuntu Releases 過程忽略,網上教程很多。
2,ubuntu20.04.4設置root登錄,參考 Ubuntu系統設置默認用户為root並自動登錄(詳解)_偷心的小白的博客-
3,ubuntu20.04.4網絡配置
發現可以連接內網,但連接不了外網。通過ifconfig 先查到我的網卡名稱,我的是enp6s0。看大家説要編輯/etc/systemd/resolved.conf 文件,增加 DNS=114.114.114.114 以及 DNS=8.8.8.8然而並無作用。我的做法是 修改/etc/netplan/ 下面的 .yaml文件,下圖是原本的樣子:
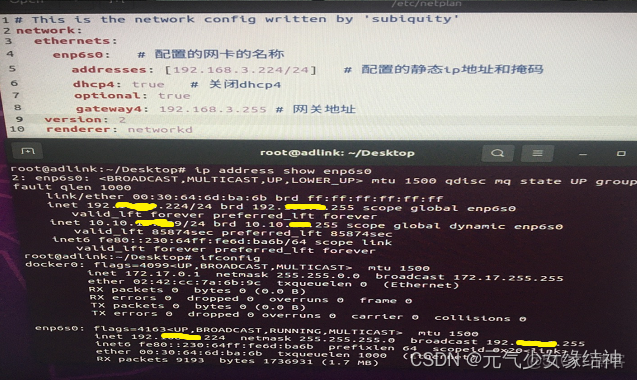
通過上面的命令可以看到這台電腦的內網IP是10.10.XXXXX9/24,於是我將yaml文件修改為下面的樣子,即addresses改成這台機器的內網IP,網關大家可以通過 route 命令查看,然後填在下方即可:
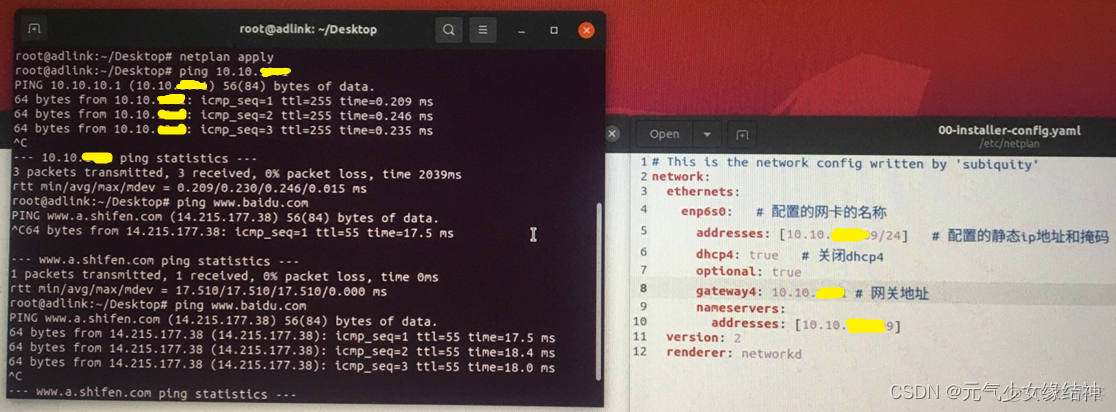
改完 netplan apply 一下,不放心再重啓一次即可看到 ping 內網以及外網均OK了。
4,設置遠程(這步可以不做,我是想通過遠程操作這台主機,因為聲音太吵了)
以前的電腦用16.04的設置是win10 遠程桌面ubuntu16 現在是20.04所以我按照Ubuntu20.04桌面共享-愛碼網 ubuntu20.10設置桌面共享的三種方式_xingyu97的博客_ubuntu桌面共享 這些流程操作發現sharing--Screen Sharing的使能按鈕打不開,無法打到On狀態:
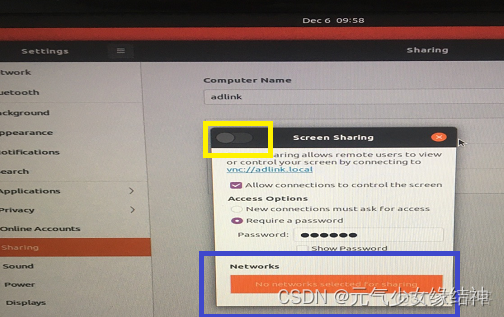
究其原因是藍色處的網絡沒正確自動顯示,導致使用VNC Viewer連接時顯示“The connection was refused by the computer”。查了下按照大家説的將下面設置為自動:
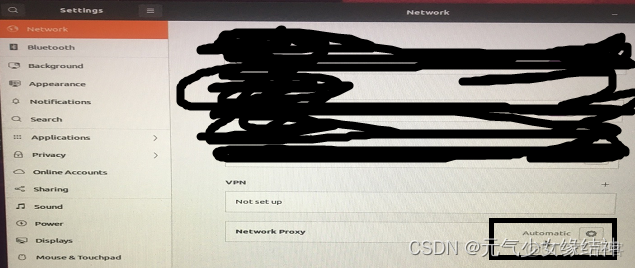
然後並不起作用。後面找了很久xorg - Ubuntu 18.04.1 LTS Can't Enable Screen Sharing - Ask Ubuntu 終於找到這個解決辦法:
cd /etc/NetworkManager
save NetworkManager.conf to NetworkManager.orig (as a backup)
sudo vi NetworkManager.conf
Change managed=false to managed=true
sudo service network-manager restart
cd /etc/netplan
sudo vi xxxxxxxxxx.yaml
Change renderer under networt from networkd to NetworkManager like below:
renderer: NetworkManager
save
sudo netplan apply
I had then to restart the computer for this to be effective.Then you can go to Settings » Sharing » Screen Sharing and set it to On
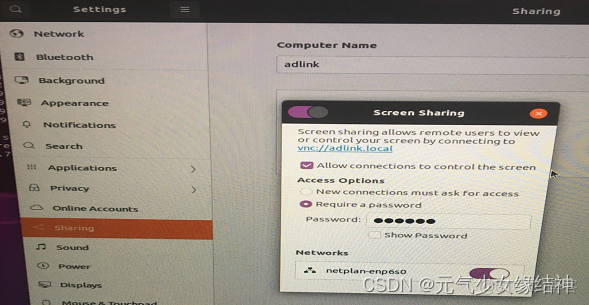
可以看到現在已經可以正常開啓。重啓後,開機時會出現下圖紅色的部分failed,不用在意。
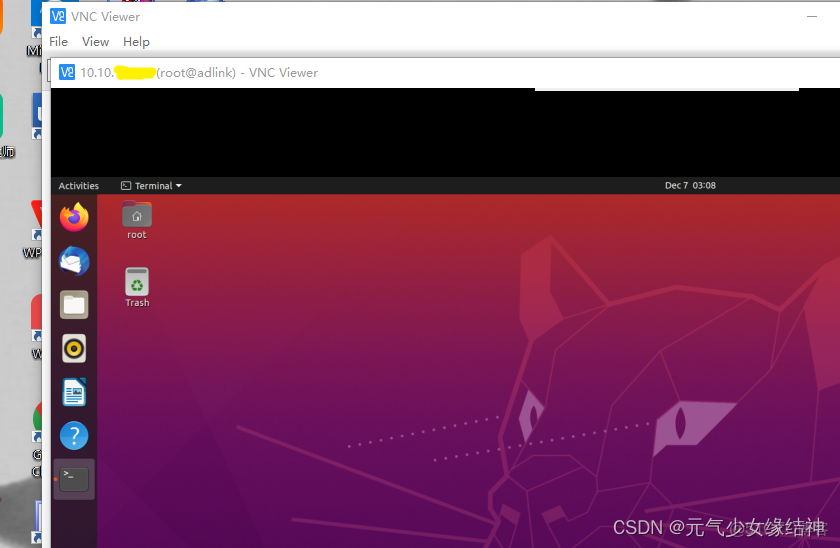
通過VNC Viewer連接大家可以看到已經連接上了這台主機:
如果要ssh遠程,則apt-get install openssh-server 然後將/etc/ssh下的sshd_config文件PermitRootLogin 改成yes
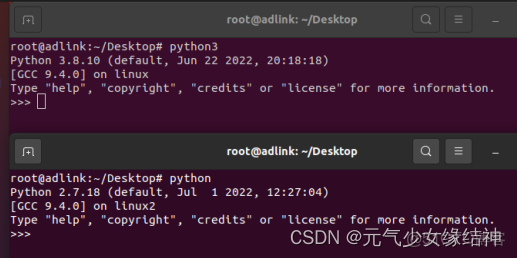
5,python安裝
網上教程很多,如下python2和python3都安裝了:
6,固件與驅動 的安裝大家根據官方文檔《NPU驅動和固件安裝指南》進行即可,參考網址華為 Atlas 300I Pro 配置手冊、產品文檔、PDF - 華為即可,大家可以直接將技術文檔都下載下來。安裝完畢後大家可以 npu-smi info -t board -i NPU ID 命令查詢是可以看到的:
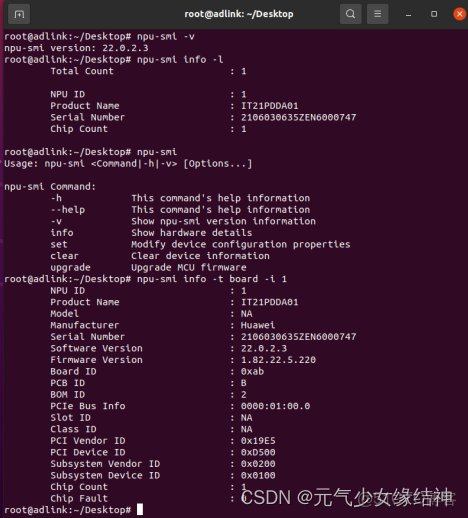
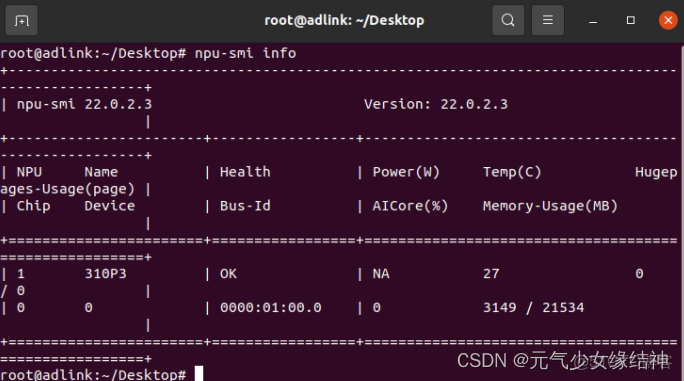
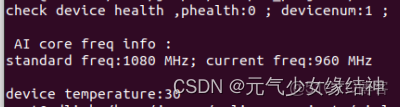
由圖可知我安裝的驅動是22.0.2.3,固件是1.82.22.5.220,處理器是310P3即710芯片。我的這張卡不支持windows。另外後續會説的deviceid就是指的芯片,不是指的服務器也不是指推理卡而是指推理卡中的芯片。看我的deviceid知道我就一個芯片。這些信息除了在終端查看,按這個介紹 調用示例 - Atlas 300I Pro 推理卡 6.0.RC1 DSMI API參考 01 - 華為 還可以如下查看,一定記得加上/usr/local/Ascend/driver/lib64/stub 路徑下的 drvdsmi_host 庫哦:
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
#include <unistd.h>
#include "dsmi_common_interface.h"
int main()//(int argc, char *argv[])
{
int ret=0;
unsigned int phealth = 0;
ret = dsmi_get_device_health(0, &phealth);
if (ret)
{
printf("call dsmi_get_device_health fail, ret = %d \n", ret);
return -1;
}
else
{
/*phealth type is unsigned int, printf value should use %u*/
printf("check device health ,phealth:%u ; ", phealth);
}
int devicenum=0;
ret=dsmi_get_device_count(&devicenum);
if(ret)
{
printf("call dsmi_get_device_count fail, ret = %d \n", ret);
return -1;
}
else
{
printf("devicenum:%d ; ", devicenum);
}
printf("\n\n AI core freq info :\n");
int deviceid=devicenum-1;
struct dsmi_aicore_info_stru pdevice_aicore_info = {0};
ret = dsmi_get_aicore_info(deviceid, &pdevice_aicore_info);
if (ret)
{
printf("call dsmi_get_aicore_info fail, ret = %d \n", ret);
return -1;
}
else
{
printf("standard freq:%u MHz; current freq:%u MHz\n\n", pdevice_aicore_info.freq,pdevice_aicore_info.curfreq);
}
int tempera=0;
ret = dsmi_get_device_temperature(0, &tempera);
if (ret)
{
printf("call dsmi_get_device_temperature fail, ret = %d \n", ret);
return -1;
}
else
{
printf("device temperature:%d \n", tempera);
}
return 0;
}7,華為CANN軟件包
參考步驟5中給出的鏈接文檔《CANN軟件安裝指南》安裝完畢(我安裝的是 昇騰社區-官網丨昇騰萬里 讓智能無所不及這個版本),如下所示:

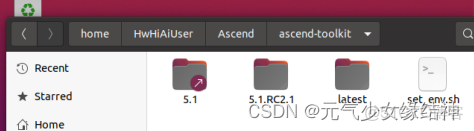
所以對於我的需求而言,不用另外安裝其他CANN相關的軟件包。這個set_env.sh裏是配置環境變量,所以一定要運行生效哦。不過我的這個版本里面沒有配置ATC:
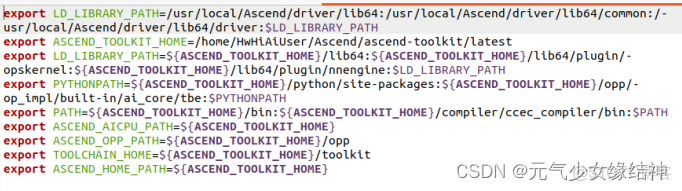
所以要增加ATC的環境變量如下所示:
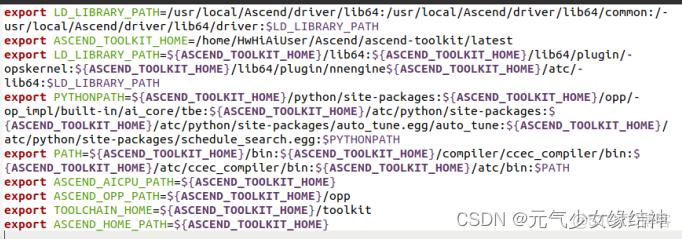
(不好意思,這裏我少打了一個冒號 ,nnengine後面,大家記得加上)使其生效,即將source /home/.../set_env.sh 添加到Home/.bashrc的最後一行,再source一下即可。然後在終端輸入 atc 就會顯示:ATC start working now,please wait for a moment 證明環境生效。
後面我還是決定root重裝到標準路徑/usr/local下,所以我重新按照這個昇騰社區-官網丨昇騰萬里 讓智能無所不及裝了ascend_cann_toolkit 和nnrt對應版本,流程參考昇騰社區-官網丨昇騰萬里 讓智能無所不及 這個即可。安裝完畢分別會有:
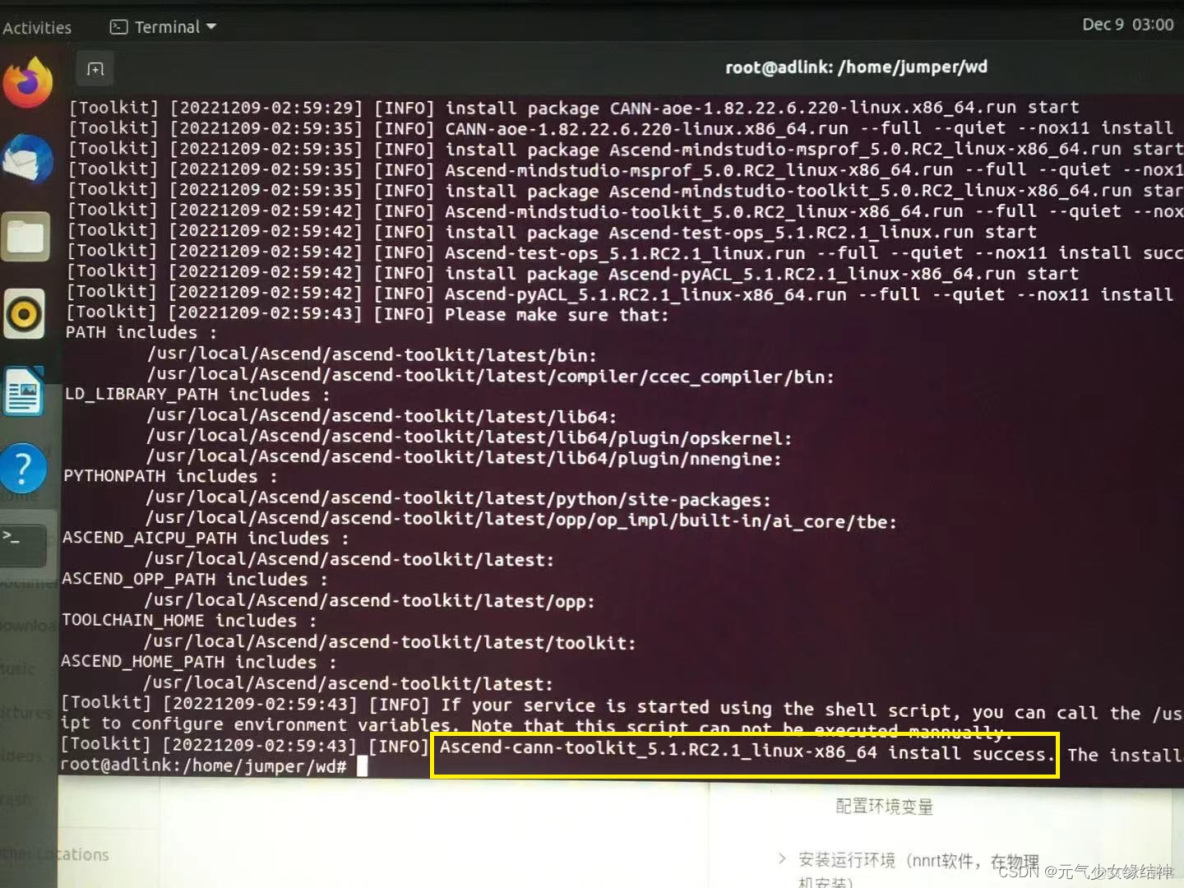
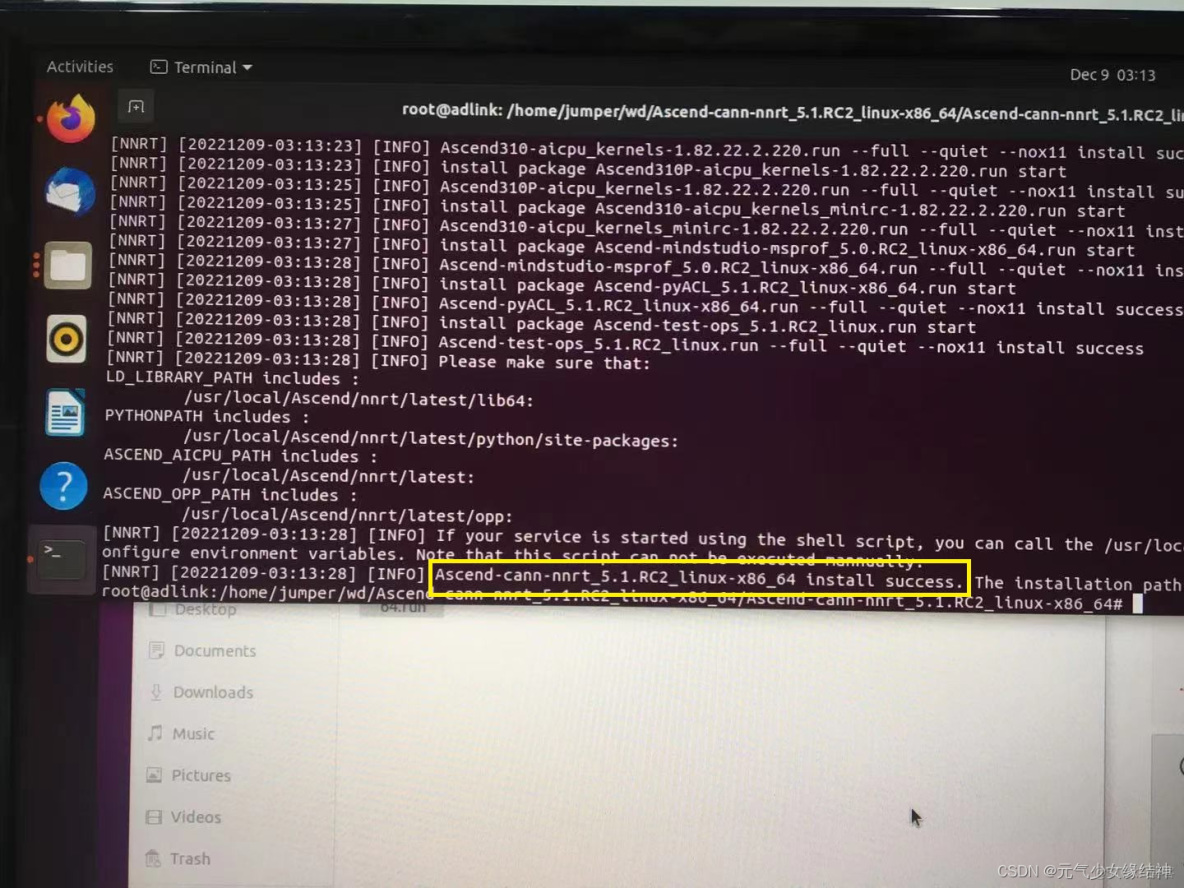
然後atc的環境變量像我上面所述一樣修改生效,直到終端輸出為下面這樣即可:
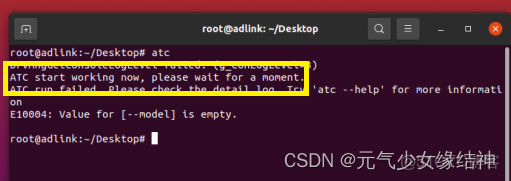
然後輸入 npu-smi info 再檢查一下輸出是否像我開頭那樣就表示安裝正確,如果npu-smi info顯示有問題,則是驅動問題,驅動應該卸載掉重裝。但固件不用重裝,因為固件可以支持很多版本。
8,安裝opencv
安裝opencv依賴庫(可選,也可以先不裝)
9,安裝tensorflow (可選,也可以先不裝)
我是裝的2.5.0


如果後面跑離線模型推理實例需要tf1的時候,大家就在報錯的 .py腳本中自己轉化一下:將import tensorflow as tf改成:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()離線模型inceptionv4推理
使用的是華為提供的模型,參考網址昇騰社區-官網丨昇騰萬里 讓智能無所不及 或者按照昇騰社區-官網丨昇騰萬里 讓智能無所不及 按照這個步驟進行,模型的數據集需要我們自己下載,大家可以在ImageNet Object Localization Challenge | Kaggle kaggle上下載相關的數據集。這個網站要註冊,我就直接在 百度網盤 請輸入提取碼 提取碼:ux59 這裏下載的Imagenet2012 Jpeg格式數據集ILSVRC2012_img_val和Label文件ILSVRC2012_devkit_t12。下完數據集與標籤後,看到 ATC ShuffleNetv1(FP16) :昇騰社區-官網丨昇騰萬里 讓智能無所不及和 ATC Inceptionv4(FP16)(這個例子最簡單,只要python下import numpy成功,就可以運行這個例子,所以建議從這個例子開始吧):昇騰社區-官網丨昇騰萬里 讓智能無所不及 這兩個模型推理都是用的Imagenet2012這個數據集。按照剛剛給的模型鏈接下的步驟操作後,報拼寫錯誤如下所示:

終於知道原因了,原來剛剛官網下載的模型解壓後有空格,所以另外保證總路徑沒有空格即可:

可以看到模型轉換成功了。但下一步build.sh失敗,哪怕我將include路徑也添加到環境變量中:

所以乾脆在cmake文件中將絕對路徑加進去:
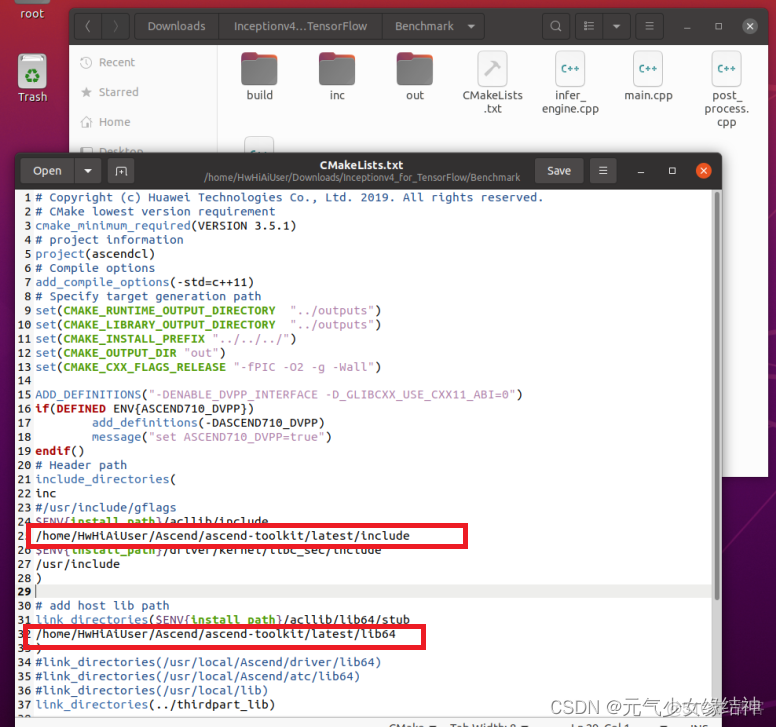
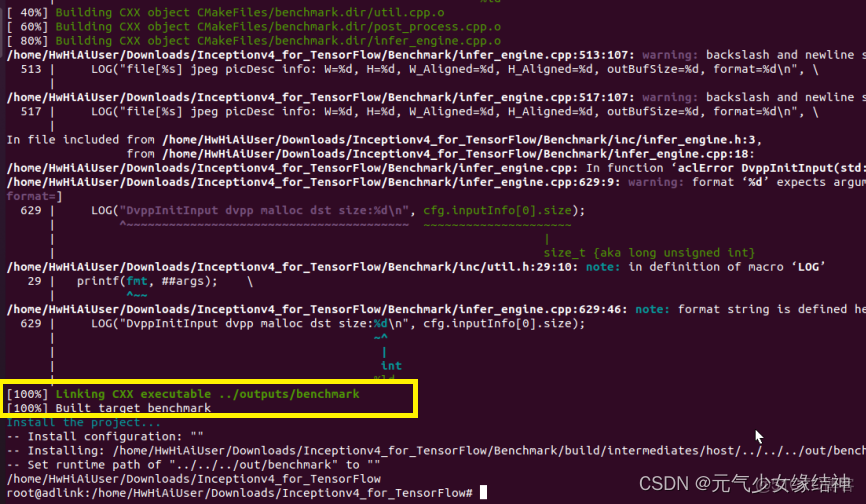
終於build.sh成功。但最後一步推理時還是有問題,我懶得改了。直接按標準路徑重裝,如上面第7步驟所説重新裝cann-toolkit和nnrt以及驅動,然後重新去官網下載、運行這個例子,什麼都不用修改,發現這次什麼錯都沒有,直接完全按照鏈接中的步驟來,一路順風。
這表示這個模型離線推理完畢。終於成功,訣竅就是環境一定要安裝正確。
root@adlink:/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts# bash benchmark_tf.sh --batchSize=1 --modelType=inceptionv4 --imgType=raw --precision=fp16 --outputType=fp32 --useDvpp=1 --deviceId=0 --modelPath=/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/inception_v4_tf_aipp.om --dataPath=/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs --trueValuePath=/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_lable.txt
======================infer test========================
./benchmark --dataDir /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs --om /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/inception_v4_tf_aipp.om --batchSize 1 --modelType inceptionv4 --imgType raw --deviceId 0 --loopNum 1 --useDvpp 1
[INFO]dataDir = /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs
[INFO]om = /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/inception_v4_tf_aipp.om
[INFO]batchSize = 1
[INFO]modelType = inceptionv4
[INFO]imgType = raw
[INFO]deviceId = 0
[INFO]loopNum = 1
[INFO]useDvpp = 1
parase params start
dataDir /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs
output dir ../../results not exists, try to make dir.
outDir ../../results
batchSize 1
modelType inceptionv4
imgType raw
useDvpp is 1
parase params done
context init start
context init done
load model start
binFileBufferData:0x7fcbbaa96010
Load model success. memSize: 6502400, weightSize: 87928832.
load model done
model input num 1
model input[0] size 138624
model input[0] dimCount 4
model input[0] dim[0] info 1
model input[0] dim[1] info 304
model input[0] dim[2] info 304
model input[0] dim[3] info 3
model input[0] format 1 inputType 4
model input[0] name input
model input name input is belone to input 0
model output num 1
model output[0] size 4000
model output[0] dimCount 2
model output[0] dim[0] info 1
model output[0] dim[1] info 1000
model output[0] format 1 outputType 0
model output[0] name InceptionV4/Logits/Logits/BiasAdd:0
model output name InceptionV4/Logits/Logits/BiasAdd:0 is belone to output 0
***********fileNum:10
resizedWidth 304 resizedHeight 304 resizedWidthAligned 304 resizedHeightAligned 304 resizedOutputBufferSize 138624
loopCnt 0, loopNum 1
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000001.JPEG] jpeg picDesc info: W=500, H=375, W_Aligned=512, H_Aligned=384, outBufSize=589824, format=6
w_new=500, h_new=375, format=6
CentralCrop newInputWidth=500 newInputHeight=375 modelInputWidth=447 modelInputHeight=335
the format is 1
inference batch 1 start
ILSVRC2012_val_00000001.JPEG inference time use: 1581 us
inference batch 1 done
save batch 1 start
save batch 1 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000005.JPEG] jpeg picDesc info: W=500, H=333, W_Aligned=512, H_Aligned=336, outBufSize=516096, format=6
w_new=500, h_new=333, format=6
CentralCrop newInputWidth=500 newInputHeight=333 modelInputWidth=447 modelInputHeight=298
the format is 1
inference batch 2 start
ILSVRC2012_val_00000005.JPEG inference time use: 1541 us
inference batch 2 done
save batch 2 start
save batch 2 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000006.JPEG] jpeg picDesc info: W=500, H=368, W_Aligned=512, H_Aligned=368, outBufSize=565248, format=6
w_new=500, h_new=368, format=6
CentralCrop newInputWidth=500 newInputHeight=368 modelInputWidth=447 modelInputHeight=329
the format is 1
inference batch 3 start
ILSVRC2012_val_00000006.JPEG inference time use: 1607 us
inference batch 3 done
save batch 3 start
save batch 3 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000007.JPEG] jpeg picDesc info: W=500, H=334, W_Aligned=512, H_Aligned=336, outBufSize=516096, format=6
w_new=500, h_new=334, format=6
CentralCrop newInputWidth=500 newInputHeight=334 modelInputWidth=447 modelInputHeight=298
the format is 1
inference batch 4 start
ILSVRC2012_val_00000007.JPEG inference time use: 1659 us
inference batch 4 done
save batch 4 start
save batch 4 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000008.JPEG] jpeg picDesc info: W=500, H=375, W_Aligned=512, H_Aligned=384, outBufSize=589824, format=6
w_new=500, h_new=375, format=6
CentralCrop newInputWidth=500 newInputHeight=375 modelInputWidth=447 modelInputHeight=335
the format is 1
inference batch 5 start
ILSVRC2012_val_00000008.JPEG inference time use: 1564 us
inference batch 5 done
save batch 5 start
save batch 5 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000009.JPEG] jpeg picDesc info: W=375, H=500, W_Aligned=384, H_Aligned=512, outBufSize=589824, format=6
w_new=375, h_new=500, format=6
CentralCrop newInputWidth=375 newInputHeight=500 modelInputWidth=335 modelInputHeight=447
the format is 1
inference batch 6 start
ILSVRC2012_val_00000009.JPEG inference time use: 1540 us
inference batch 6 done
save batch 6 start
save batch 6 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000010.JPEG] jpeg picDesc info: W=500, H=375, W_Aligned=512, H_Aligned=384, outBufSize=589824, format=6
w_new=500, h_new=375, format=6
CentralCrop newInputWidth=500 newInputHeight=375 modelInputWidth=447 modelInputHeight=335
the format is 1
inference batch 7 start
ILSVRC2012_val_00000010.JPEG inference time use: 1527 us
inference batch 7 done
save batch 7 start
save batch 7 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000011.JPEG] jpeg picDesc info: W=500, H=400, W_Aligned=512, H_Aligned=400, outBufSize=614400, format=6
w_new=500, h_new=400, format=6
CentralCrop newInputWidth=500 newInputHeight=400 modelInputWidth=447 modelInputHeight=358
the format is 1
inference batch 8 start
ILSVRC2012_val_00000011.JPEG inference time use: 1591 us
inference batch 8 done
save batch 8 start
save batch 8 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000016.JPEG] jpeg picDesc info: W=500, H=333, W_Aligned=512, H_Aligned=336, outBufSize=516096, format=6
w_new=500, h_new=333, format=6
CentralCrop newInputWidth=500 newInputHeight=333 modelInputWidth=447 modelInputHeight=298
the format is 1
inference batch 9 start
ILSVRC2012_val_00000016.JPEG inference time use: 1611 us
inference batch 9 done
save batch 9 start
save batch 9 done
DvppInitInput dvpp malloc dst size:138624
the format is 6
file[/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/val_imgs/ILSVRC2012_val_00000017.JPEG] jpeg picDesc info: W=500, H=375, W_Aligned=512, H_Aligned=384, outBufSize=589824, format=6
w_new=500, h_new=375, format=6
CentralCrop newInputWidth=500 newInputHeight=375 modelInputWidth=447 modelInputHeight=335
the format is 1
inference batch 10 start
ILSVRC2012_val_00000017.JPEG inference time use: 1562 us
inference batch 10 done
save batch 10 start
save batch 10 done
unload model start
unload model done
destory context done
reset device done
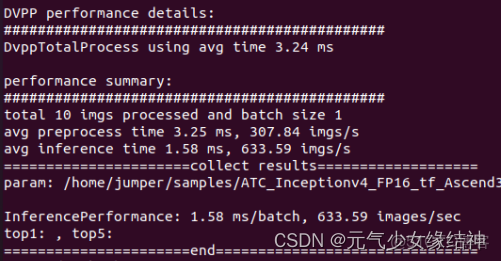
DVPP performance details:
#############################################
DvppTotalProcess using avg time 3.24 ms
performance summary:
#############################################
total 10 imgs processed and batch size 1
avg preprocess time 3.25 ms, 307.84 imgs/s
avg inference time 1.58 ms, 633.59 imgs/s
======================collect results===================
param: /home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts/../results/inceptionv4/,fp32
InferencePerformance: 1.58 ms/batch, 633.59 images/sec
top1: , top5:
======================end===============================
root@adlink:/home/jumper/samples/ATC_Inceptionv4_FP16_tf_Ascend310/Inceptionv4_for_TensorFlow/scripts#大家還可以一邊推理,一邊開另一個終端輸入npu-smi info watch 來查看AI core/AI cpu的佔用率。
離線模型shuffleNetv1推理
直接按照官網的來,因為我之前npu-smi info輸出處理器是310P,所以我只用將昇騰社區-官網丨昇騰萬里 讓智能無所不及這裏的310改成310P3即可,另外模型以及圖片的路徑大家儘量不要像官網用相對路徑,直接用絕對路徑,像我這樣:
atc --model=/home/jumper/samples/ShuffleNetv1_for_TensorFlow/shufflenetv1.pb --framework=3 --output=shufflenetv1_tf_96batch --output_type=FP32 --soc_version=Ascend310P3 --input_shape="input:96,224,224,3" --out_nodes="classifier/BiasAdd:0" --log=info這個例子的4b步驟我運行腳本出錯,所以直接改用命令運行成功,可以看到官網的步驟中少了一步創建result文件夾以及label寫成了label等筆誤,像我下面這樣創建好後全部用絕對路徑::
/home/jumper/samples/ShuffleNetv1_for_TensorFlow/Benchmark/out/benchmark --om=/home/jumper/samples/ShuffleNetv1_for_TensorFlow/shufflenetv1_tf_96batch.om --dataDir=/home/jumper/samples/ShuffleNetv1_for_TensorFlow/scripts/input_bins/ --modelType=shufflenetv1 --outDir=/home/jumper/samples/ShuffleNetv1_for_TensorFlow/results --batchSize=1 --imgType=bin --useDvpp=0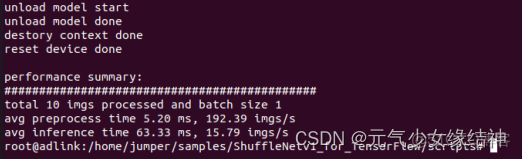
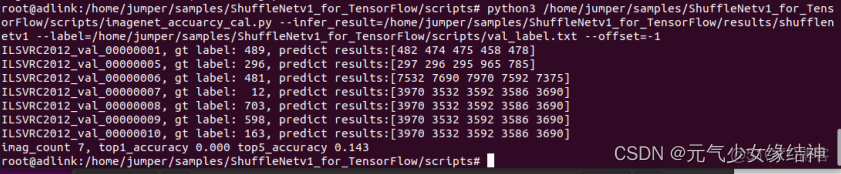
可以看到成功推理了。然後後處理部分我也改用命令運行:
可以看到也同樣成功了。至此我們運行了官網的兩個離線推理實例,均成功。可以看到AI core開始被使用:
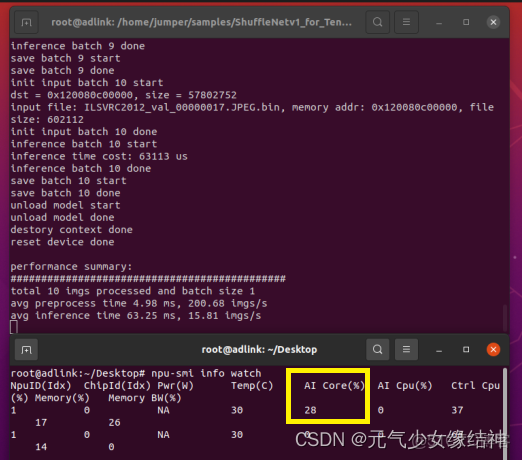
調大batch,AI core佔用率會提高。
AI推理卡的C++環境
下面我們終於可以開始創建AI推理卡的C++開發環境:
第三方C++庫
opencv上面我已經裝過,找到opencv2文件夾。(這裏我重新按我之前的博客編譯了帶並行的opencv,大家若用不着並行,則不必重新編譯)
安裝MindStudio
按照昇騰社區-官網丨昇騰萬里 讓智能無所不及 這個步驟一步步安裝好mindstudio,缺什麼就裝什麼,反正就按官網的流程走。於是就成了下面這樣:

一定要到具體版本號那個文件夾,才會自動顯示。但後面聽説這個不好用,於是決定不用這個IDE,換成VScode。
安裝Visual Studio code
直接在官網下載VScode的deb文件,然後dpkg -i code_xxx.deb安裝即可,然後在終端即可打開。我試了一下固定到任務欄雙擊,發現打不開,於是還是老實使用下面的命令在終端打開:
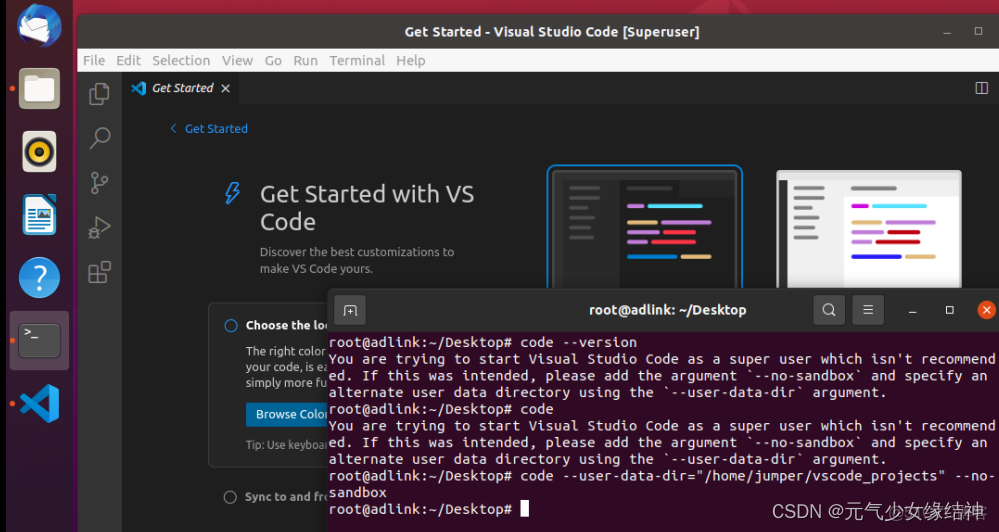
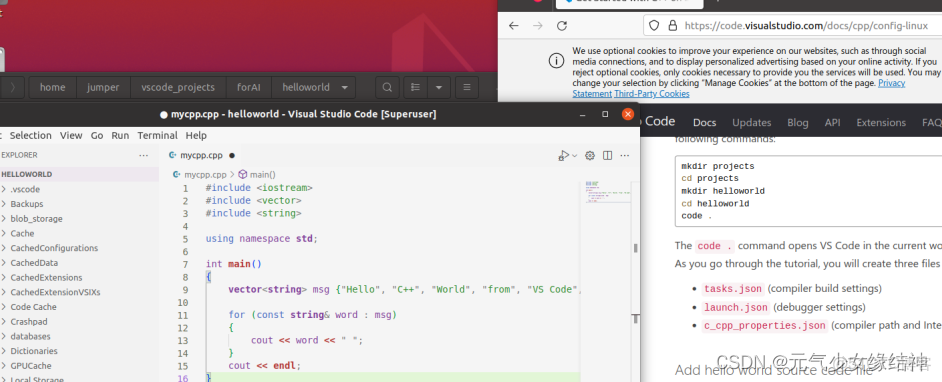
然後按照官網例子,開始創建第一個helloworld程序,或參考Ubuntu快速搭建C++開發環境(VS Code編輯器) - 知乎 它是要先自己選擇好或創建好一個跑工程的文件夾A,再在A下創建 .vscode 文件夾和一些cpp等源文件(源文件也可以之後再新建),再在A下打開終端開啓IDE,就會自動導入這個工程,工程名就是A的名字,最後點擊源文件進行編碼。大家也可直接參考下面的官網,講解了如何編寫配置文件即三個.json,.vscode編寫完畢可以重複使用,即另新建一個工程,也只用將.vscode拷貝過去即可。:
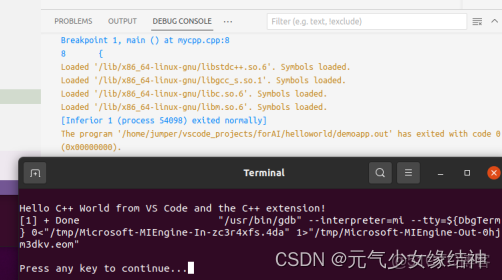
可以看到正確輸出。vscode安裝OK。
code --user-data-dir="/home/jumper/vscode_projects/forAI/helloworld" --no-sandboxAI C++實例
resnet50 C++
1,準備圖片 在官網昇騰社區-官網丨昇騰萬里 讓智能無所不及 這裏下載C++實例代碼簡稱resnet50sample,可以看到有三個h和cpp文件及main文件,再在CIFAR-10 and CIFAR-100 datasets這裏下載C++格式的圖片。
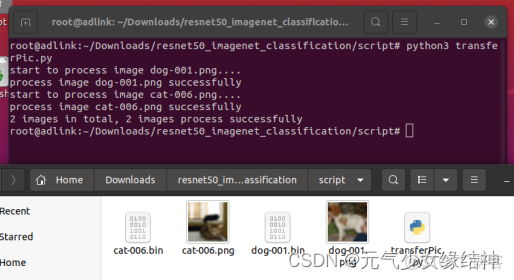
可以看到我下載了兩張png格式的,但實例腳本中是jpg,自己改一下就好,然後直接運行,生成的bin文件就是預處理後的圖片。不好,突然發現官網又有筆誤,即下圖左紅框中是腳本將圖片轉成float16這與右邊模型的輸出不一樣,所以我們將腳本中這處地方改成float32,然後再重新運行一遍這個腳本:

2,模型轉換ATC 官網下載模型昇騰社區-官網丨昇騰萬里 讓智能無所不及 並進行轉換,這個方法已經很熟悉了,因為我上面已經描述了兩個atc轉換並推理的實例。此步不再詳細講解,大家可以往上翻那兩個離線推理實例。
atc --model=/root/Downloads/ATC_Resnet50_V1_from_Tensorflow_Ascend310/resnet_v1_50.pb --framework=3 --output=/root/Downloads/resnet50_imagenet_classification/model/resnet50_tf__batch1_fp16_FP32 --output_type=FP32 --soc_version=Ascend310P3 --input_shape=input:1,224,224,3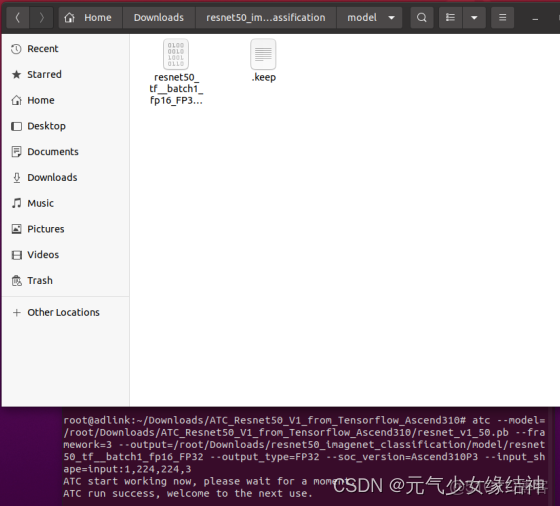
可以看到目標文件夾下生成了om模型。然後將我們處理完的bin圖片和om放入resnet50sample的data以及model下面。
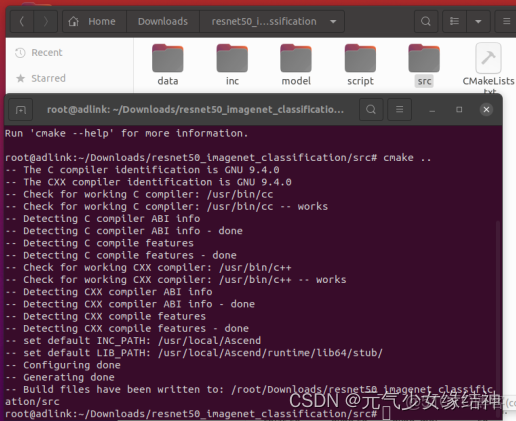
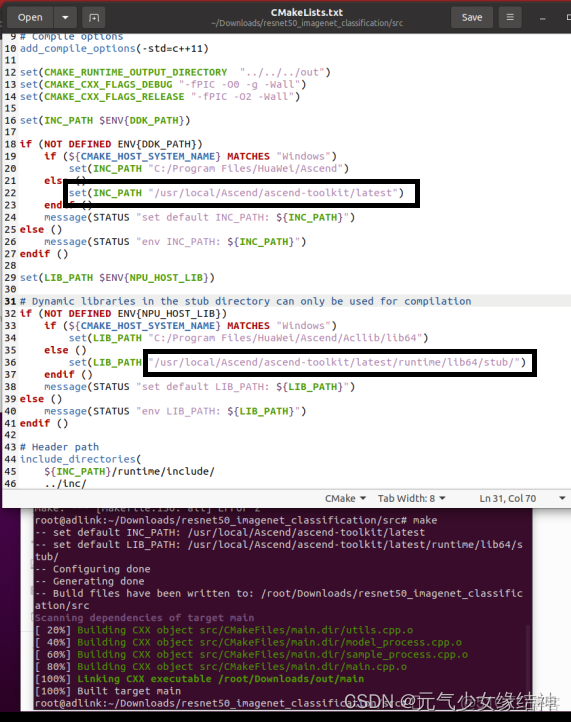
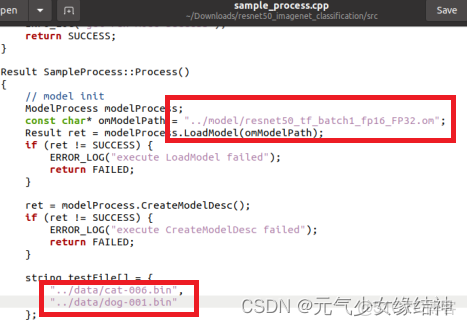
3,C++命令行編譯運行 我們先直接使用命令行編譯試試,如下左一圖很順利。接着我們修改cmakelists.txt文件如下中間的圖,修改黑框位置為自己的安裝路徑,sample_process.cpp紅框部分注意改成與自己的一致(因為這個文件與官網安裝步驟中矛盾,所以要改)。然後再在終端make,可以看到也很順利。make完後out文件夾下會生成一個main可執行文件。這時候其實可以在命令行下運行了,但因為我cmakelists中沒有添加相應的lib,而且我以後也主要是在IDE中編譯運行,所以運行這步我就不做了。大家若感興趣可以試下。
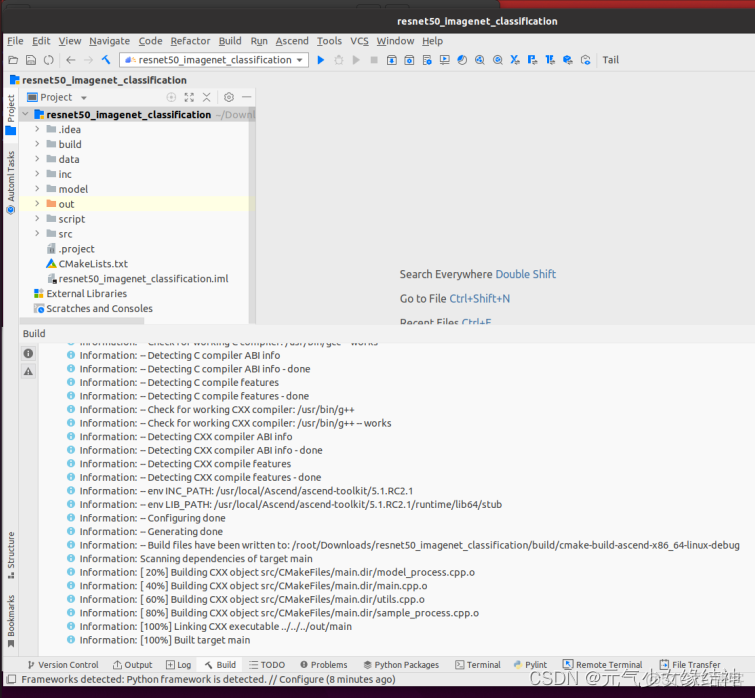
4,C++ IDE編譯運行 如果大家用的是MindStudio 此時就可以按照昇騰社區-官網丨昇騰萬里 讓智能無所不及 直接打開MindStudio,然後工程目錄定位到resnet50sample文件夾下,如下左圖。接着編譯如中間圖,此時out文件夾下會生成main可執行文件,最後運行如右圖。
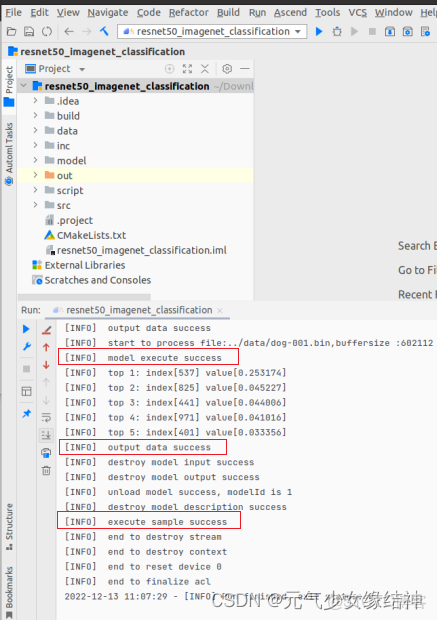
可以看到運行正確。
VGG_SSD C++
官網有很多C++實例,我下載的是這個https://github.com/Ascend/samples/tree/master/cplusplus/level2_simple_inference/2_object_detection/VGG_SSD_coco_detection_CV_without_AIPP,然後和resnet50差不多流程來做,這個鏈接下也有步驟,但有的不正確。我覺得還是華為AI推理卡太新了,使用者太少所以反饋少,他們官網就有很多筆誤處矛盾處沒改正過來,看我寫到現在就發現至少3處。不吐槽了,繼續搞事:先按github這個鏈接中的地址下載好模型。
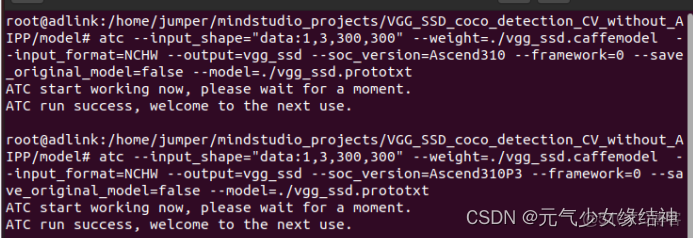
1,atc模型轉換 如下我改名是因為發現與其腳本模型名不一致(再次吐槽官網筆誤太多),所以改成了下面這樣,大家跟着改。
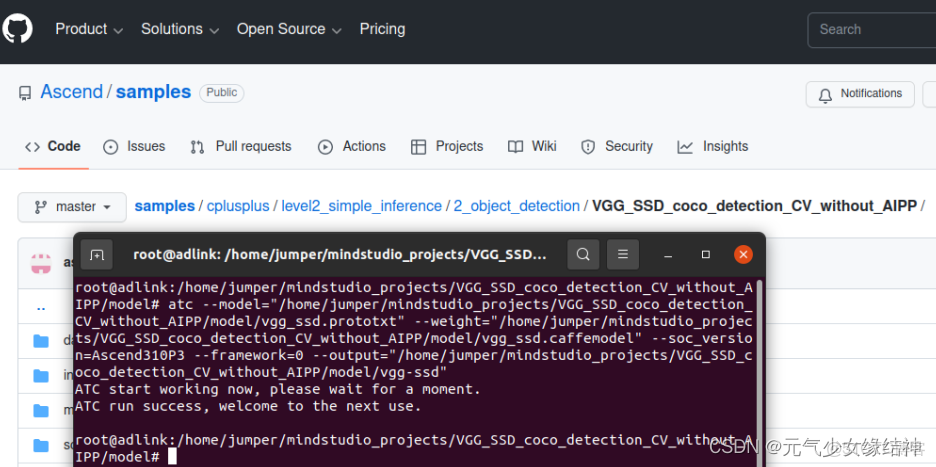
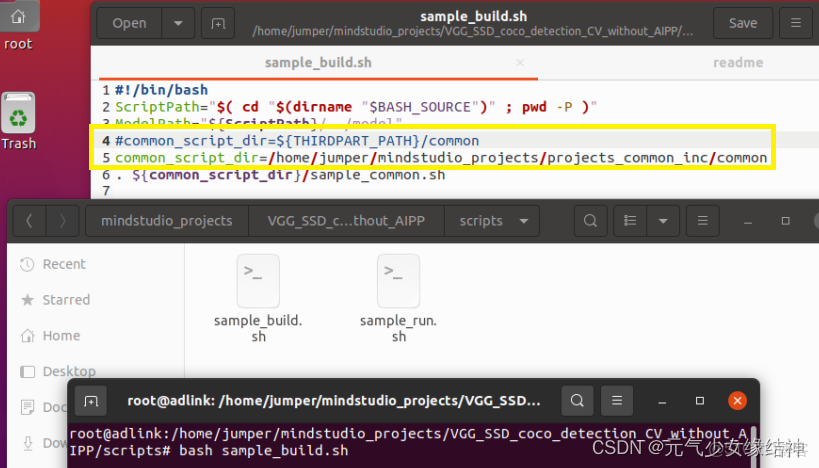
(注意輸出模型名為vgg_ssd.om,不是vgg-ssd.om!!!我貼出的這張圖筆誤了)然後開始打開scripts運行sample_build.sh腳本,注意我修改了框框處的路徑成絕對路徑(sample_run.sh我也同樣先修改好)。運行sample_build.sh成功後data文件夾下自動下載了一張測試圖片。
2,實例的環境 這個例子需要INSTALL_DIR和THIRDPART_PATH,但我們之前按官網教程安裝時set_env.sh中並不是這個名字,而是叫做ASCEND_TOOLKIT_HOME(這又是官網的一個矛盾處,醉了)所以我們只能:
A:將下面這4句添加到/root/.bashrc的後面,然後source生效(我的架構是x86_64,大家可以通過uname -a查看自己的,然後像下面這樣添加):
export CPU_ARCH='x86_64'
export INSTALL_DIR=/usr/local/Ascend/ascend-toolkit/latest
export install_path=/usr/local/Ascend/ascend-toolkit/latest
export THIRDPART_PATH=/usr/local/Ascend/thirdpart/${CPU_ARCH}B:接着再看下這個實例需要的環境samples/cplusplus/environment at master · Ascend/samples · GitHub 我們都先看一遍。然後可以知道要在/usr/local/Ascend下新建一個thirdpart/x86_64文件夾。
C:下載所有實例https://github.com/Ascend/samples直接下載下來解壓,然後samples/catenation_environmental_guidance_CN.md at master · Ascend/samples · GitHub看到samples-master/common文件夾拷貝到步驟B的x86_64下面。再把samples-master/cplusplus/common/acllite文件夾拷貝到步驟B的x86_64下面。
D:然後按照samples/catenation_environmental_guidance_CN.md at master · Ascend/samples · GitHub這個鏈接安裝ffmpeg與x246插件這一步安裝這兩個東西。發現很順利。
E:在x86_64/acllite下面編譯這個文件夾,即make然後make install,發現很順利。然後可以看到x86_64下生成了include和lib文件夾。説明正確。
F:繼續按照samples/catenation_environmental_guidance_CN.md at master · Ascend/samples · GitHub這個步驟編譯presentagent文件夾。可以看到x86_64下又生成了bin文件夾,include和lib下多了很多內容,如此圖
至此C++實例的公共環境編譯完成。最後將我們之前裝的opencv2文件夾拷貝到x86_64/include下面。3,命令行編譯實例 然後我們回到我們下載的VGG-SSD例子中make時發現報黃框中的錯誤,原因是我下載的是opencv4.x,而VGG-SSD實例中用的是opencv2.X,所以我152行、330行都進行了紅框中的修改。
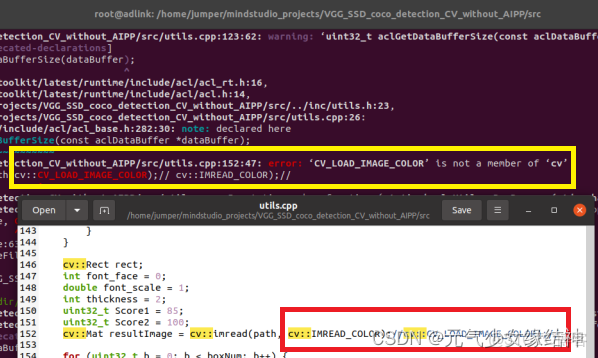
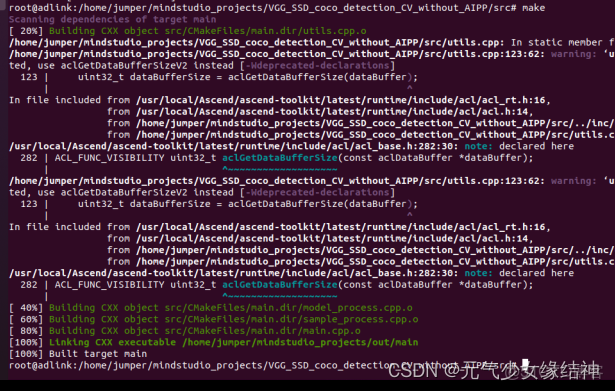
順利完成make和make install。
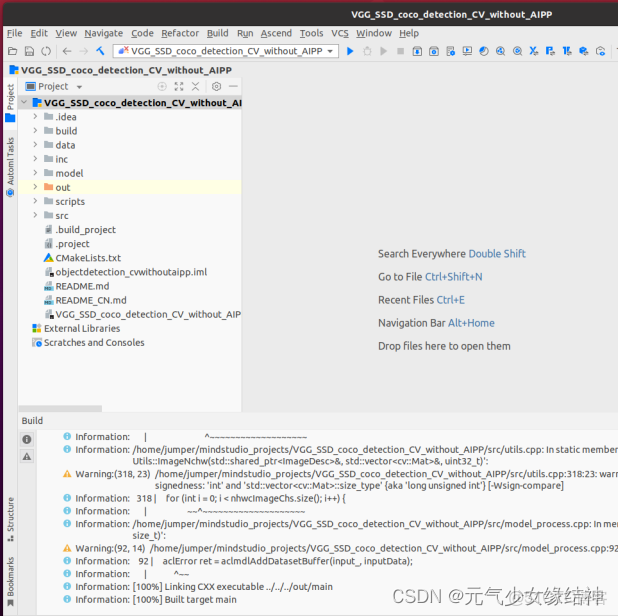
4:IDE中編譯運行 打開Mindstudio,進入工程目錄,編譯很順利out文件夾下生成了main文件,再運行都很順利。
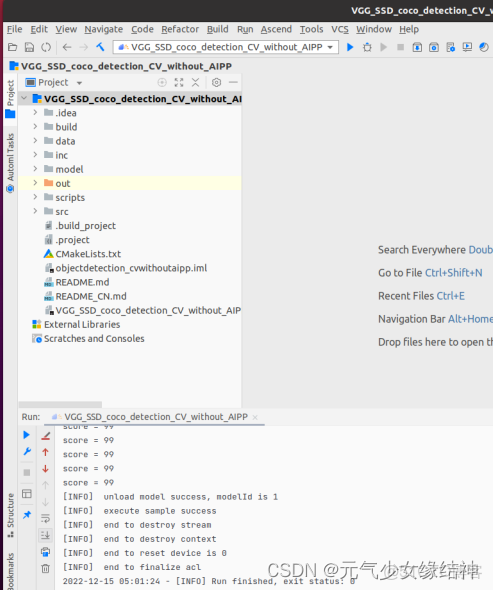
發現竟然沒有生成結果圖,於是我修改了存圖代碼後終於有結果圖了,如下所示:
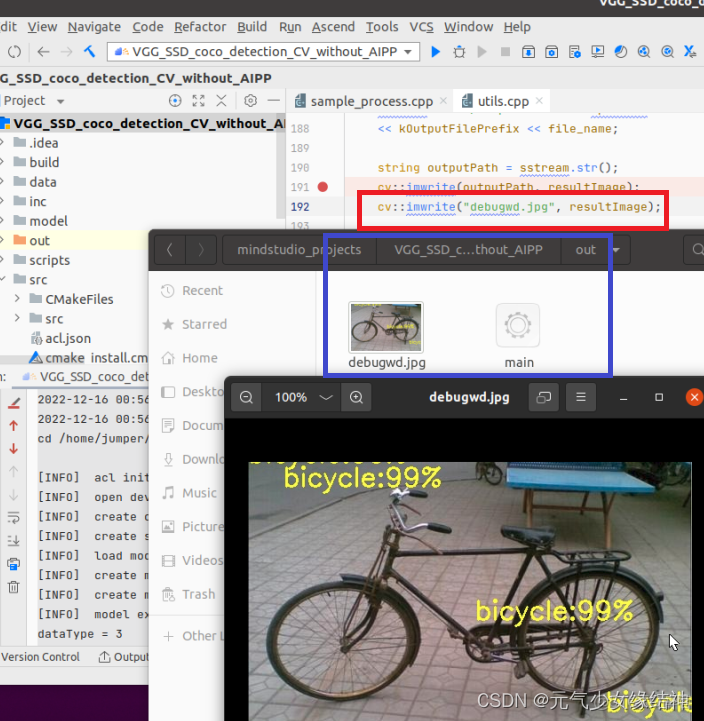
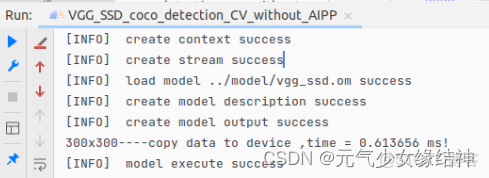
我將其copydatatoDevice的時間打印了出來,300X300 CV32FC3只需要0.6ms!非常快,這比以前Nvidia CUDA或AMD OpenCL快很多。5,可能遇到的問題 大家看到這個實例我ATC轉換時soc_version=310P3,與我的npu-smi info輸出一致,但實例結果圖中卻沒有框框,而且我運行多次發現結果竟然隨機
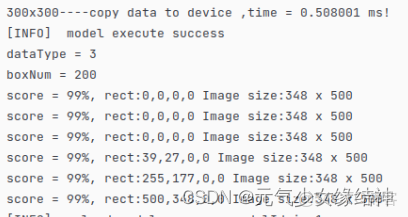
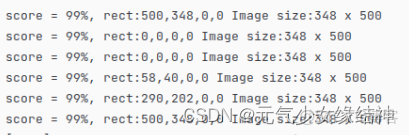
這説明結果不正確,然後聯繫華為他們,發現這兩個指令一個輸出正確一個輸出錯誤,原因就是soc_version,如果用Ascend310輸出的結果圖就是debugwd4.jpg就是正確的。但用Ascend310P3就是隨機的結果是錯誤的:
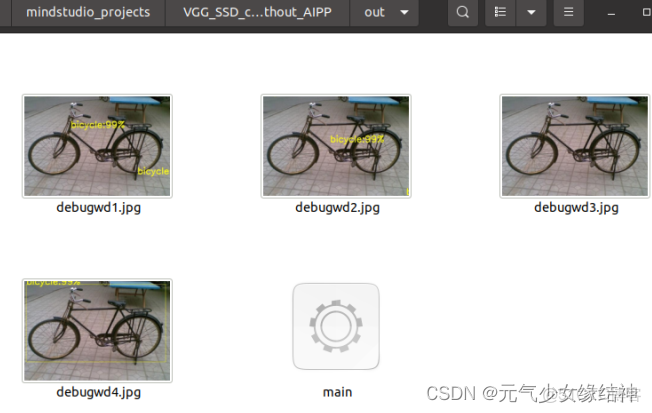

他們已經去反饋這個問題了。等回覆了我再補在這裏(還是忍不住吐槽:是不是技術太新了,都沒人發現這個問題嗎?)他們已回覆在 A300 I pro 使用act轉模型結果不正確 · Issue #I66FPT · Ascend/samples - Gitee.com 即之前的鏈接裏的模型不適合AscendP3,這個技術人員更新的鏈接中的模型才適合AscendP3
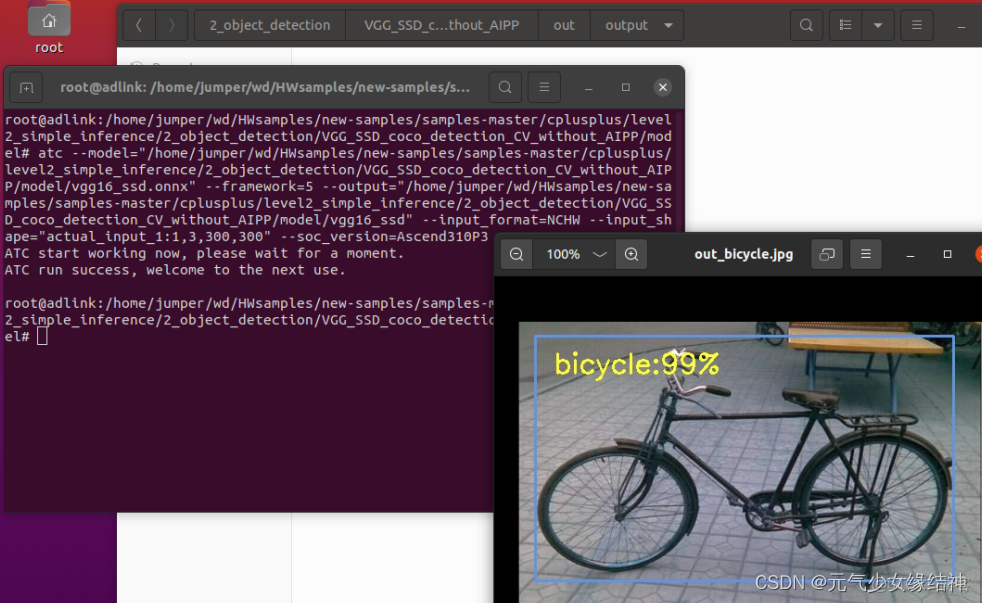
即現在的結果正確了。那麼模型與soc的適配與否取決於什麼?大家可以看那個技術人員後續的回覆。
圖像分割C++實例
接下來我們依葫蘆畫瓢運行自己的例子(模板我上傳在 ),這用的是我幾年前測試過的一個圖像分割實例,在之前的博客裏有跑過Nvidia下的結果,大家可以自己去找看下當時的耗時應該是38ms!現在改到AI推理卡下,步驟如下:
1,創建工程名your_project_name與目錄
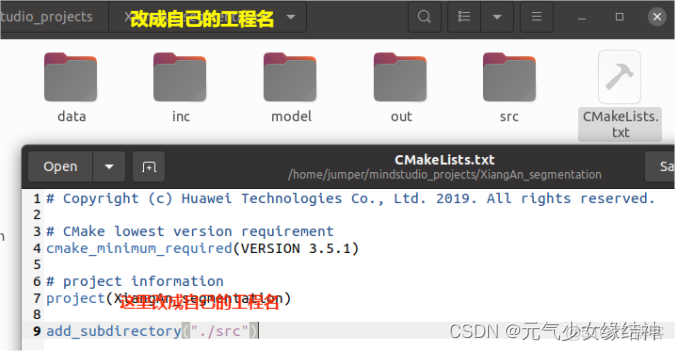
上面所有流程都實踐過的朋友,應該知道data下就放要推理的圖片,inc下放幾個頭文件,model下就放 .om 模型,out下就是編譯後的可執行文件與輸出結果的位置,src下放cpp文件。這一級的cmake的txt文件就只有這幾句話,第7行改成自己的工程名即可。
2,在MindStudio下打開工程到your_peroject_name,然後立刻會自動生成一些東西,不用在意。
3,頭文件與cpp文件
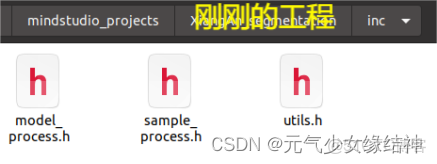
有這幾個文件就夠了。其中acl.json文件中只有一個{}符號。
4,src下的cmakelist.txt與makefile
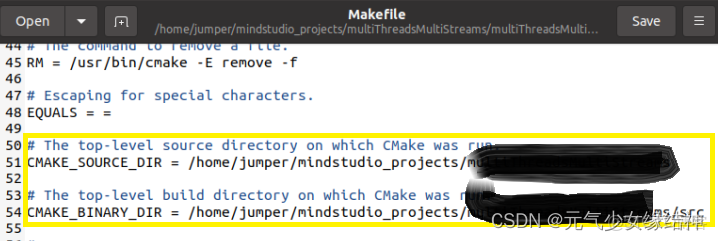
src下的Cmake的txt文件,基本不用改,就是一樣將第7行改成自己的工程名your_project_name。這個txt作用就是規定了輸出的位置、包含的頭文件與庫、需要編譯的源文件等。makefile下改下這些路徑即可
4,修改源文件sample_process.cpp
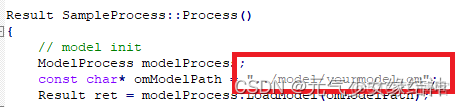
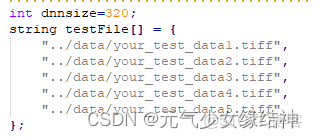
修改模型名稱和模型需要的size即dnnsize大小,以及測試圖片名稱。其它沒什麼需要改的,這裏我自己增加了預處理函數PreProcessCutImgs,若大家不需要則可以刪掉。PreProcess()函數中才是將圖片稍微處理後拷貝到device,不能刪。
5,修改源文件utils.cpp
這個文件中一般只用修改PreProcess,保證是將測試圖的數據傳到inputBuff,然後拷貝給picDevBuffer即可。注意fileSize不能搞錯。
6,修改源文件model_process.cpp
這個文件一般只用修改OutputModelResult(),outData就是推理得到的結果,可以在這個函數裏對推理結果進行後處理,比如我的是將它轉成8bit圖存在本地。
7,頭文件根據上面的修改而修改。
8,Build,Debug也行Release也行,成功後會有一個可執行文件生成在out下。
9,Run,選擇Ascend App然後定位到out下即可。
10,看我的結果:

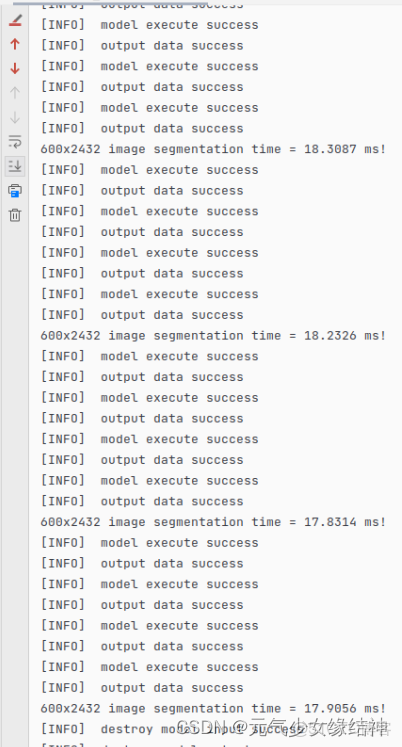
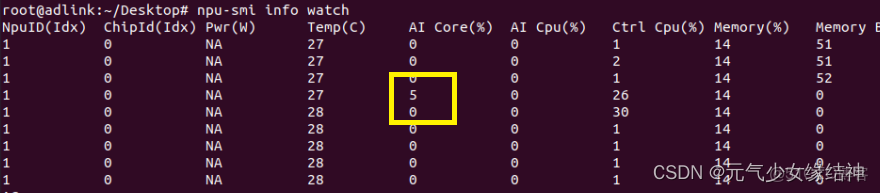
可以看到結果與GPU推理結果一致,release下耗時真的巨短才18ms(在此感嘆:果然是華為!)!當初使用Nvidia 2060 Super耗時是38ms!所以相當於少了20ms!!!然後看了下AI Core的佔用率,才用到5%!還有很多使用空間。
11,換VScode IDE運行此實例,大家推崇vscode,於是我試了下在下圖添加路徑,仍舊報錯找不到頭文件:
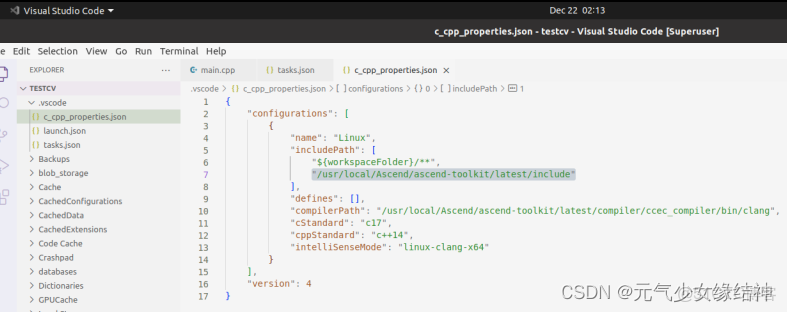
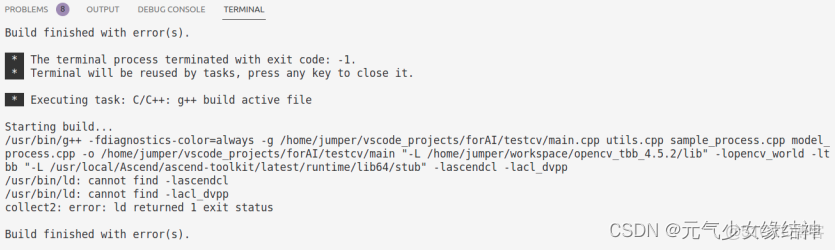
還有ascendcl、acl_dvpp路徑也報錯找不到,明明已經添加進去了!唉,opencv都可以找到,怎麼ascend的找不到,還是用MindStudio吧。
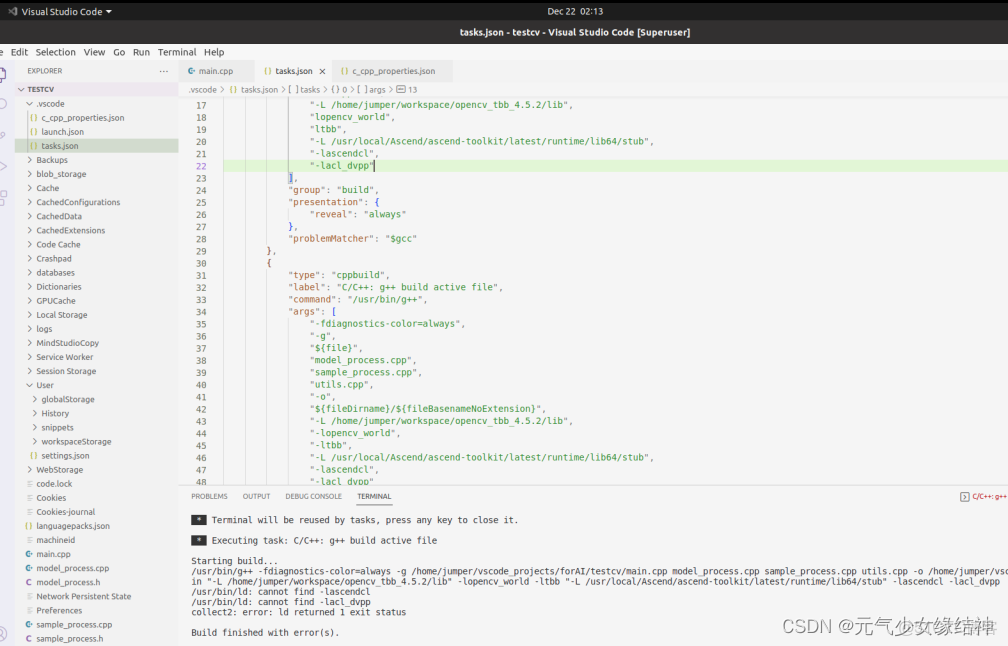
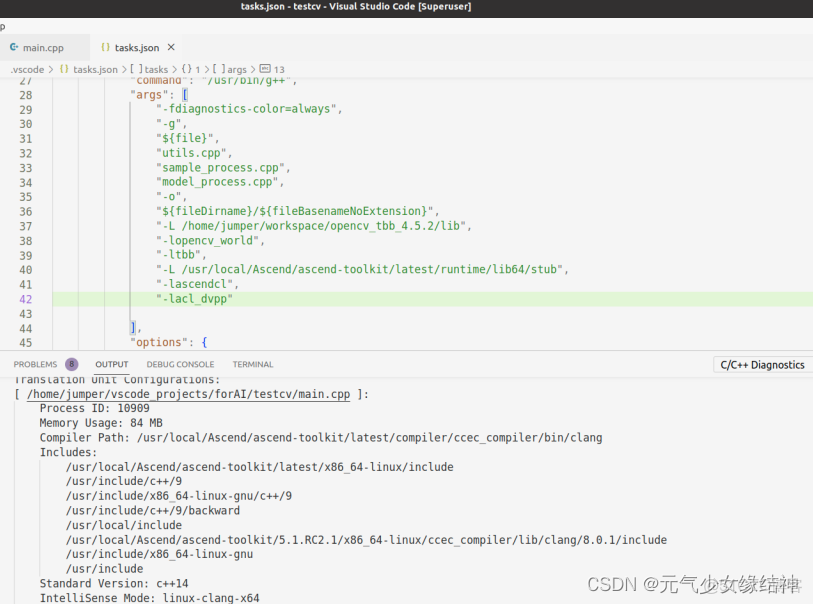
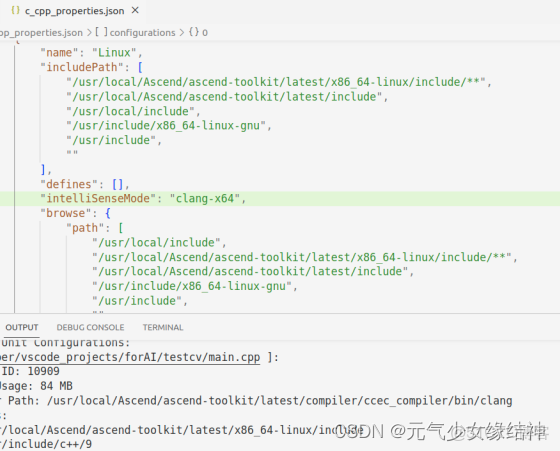
把vscode官網和它的github看了一遍,還是不行。算了不用這個IDE了。然後我又換成了eclipse試一下:
直接將例子放到eclipse下,加入ascendcl、acl_dvpp兩個庫就可以運行了。配置很簡單,至少不會像vscode那樣。雖然功能沒有vscode強大。我們就先用着吧。
C++去模糊實例
這個實例是根據https://arxiv.org/pdf/1711.07064.pdf這篇論文《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》實現,原python代碼在GitHub - dongheehand/DeblurGAN-tf: Tensorflow implementation of DeblurGAN(Blind Motion Deblurring Using Conditional Adversarial Networks) 這裏。然後華為將其作為https://github.com/Ascend/ModelZoo-TensorFlow/tree/master/TensorFlow/contrib/cv/Blur2Sharp/ATC_DeblurGAN_tf_AE實例,github上在https://github.com/Ascend/samples/tree/master/cplusplus/level2_simple_inference/6_other/DeblurGAN_GOPRO_Blur2Sharp此。然後我們按照説明跑一下,下面這幅圖是輸入的模糊圖片:

然後下面這幅是原論文中去模糊後的結果

最後這幅圖是按華為説明得到的結果,看圖最後一百列處藍色海報處的字跡,有損失估計是atc轉換時的精度損失:
然後我們換一幅圖試試,看華為的結果,標記出來的部分有嚴重損失導致馬賽克,這個原因我們暫時不去查。跑通即可:

C++多線程語義分割
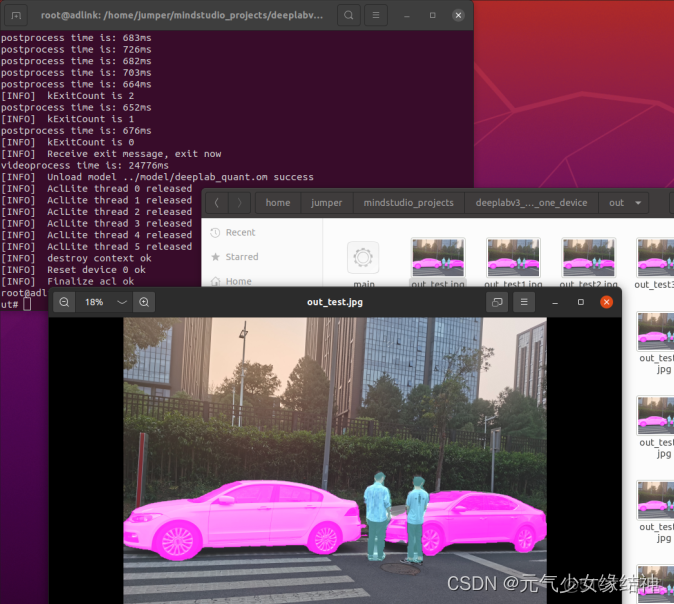
接着我們試下多線程的例子,按照readme中操作反正就不會是一帆風順的,當./sample_build.sh運行完會發現自動下載了多張圖片到data下,接下來就報下圖的錯。不用理會,直接去src下進行cmake .. 與make以及make install即可。然後out文件下生成了main可執行文件,直接運行即可,可以看到右圖正確:
接下來我們分析這個官例是怎麼實現的,還是分析下面這個多線程的例子吧
C++ YOLOV3COCO多線程實例
如上個例子一樣操作,編譯沒問題但就是MindStudo打不開這個MP4文件cv::videocapture去open時總是失敗,手動可以打開,如下圖。
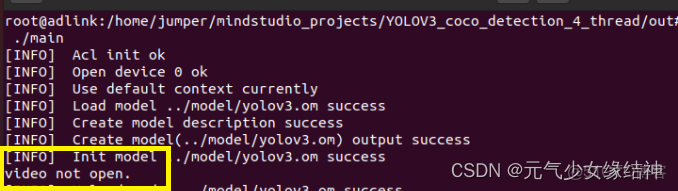
然後將這句代碼移到eclipse下可以打開,
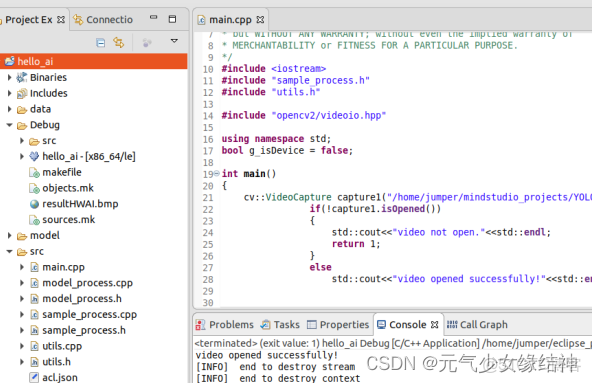
但整個例子移到eclipse又編譯通不過,配置如下:
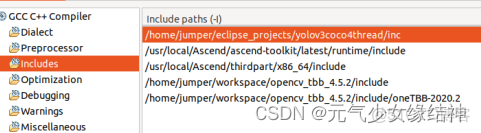
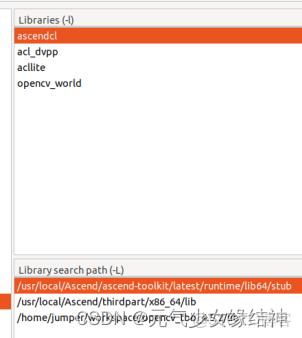
為何,都跑了這麼多實例了,怎麼還會報配置的錯誤?
make all
Building file: ../src/main.cpp
Invoking: GCC C++ Compiler
g++ -std=c++11 -I/home/jumper/eclipse_projects/yolov3coco4thread/inc -I/usr/local/Ascend/ascend-toolkit/latest/runtime/include -I/usr/local/Ascend/thirdpart/x86_64/include -I/home/jumper/workspace/opencv_tbb_4.5.2/include -I/home/jumper/workspace/opencv_tbb_4.5.2/include/oneTBB-2020.2 -O0 -g3 -Wall -c -fmessage-length=0 -MMD -MP -MF"src/main.d" -MT"src/main.o" -o "src/main.o" "../src/main.cpp"
In file included from /usr/local/Ascend/thirdpart/x86_64/include/acllite/AclLiteUtils.h:32,
from ../src/main.cpp:26:
/usr/local/Ascend/ascend-toolkit/latest/runtime/include/acl/ops/acl_dvpp.h:15:2: error: #error "if you want to use dvpp funtions ,please use the macro definition (ENABLE_DVPP_INTERFACE)."
15 | #error "if you want to use dvpp funtions ,please use the macro definition (ENABLE_DVPP_INTERFACE)."
| ^~~~~
In file included from /usr/local/Ascend/thirdpart/x86_64/include/acllite/AclLiteType.h:27,
from /usr/local/Ascend/thirdpart/x86_64/include/acllite/AclLiteUtils.h:34,
from ../src/main.cpp:26:
/usr/local/Ascend/ascend-toolkit/latest/runtime/include/acl/ops/acl_dvpp.h:15:2: error: #error "if you want to use dvpp funtions ,please use the macro definition (ENABLE_DVPP_INTERFACE)."
15 | #error "if you want to use dvpp funtions ,please use the macro definition (ENABLE_DVPP_INTERFACE)."
| ^~~~~
../src/main.cpp: In function ‘void Postprocess(aclrtContext, Queue<message>*)’:
../src/main.cpp:164:27: warning: comparison of integer expressions of different signedness: ‘int’ and ‘std::vector<BBox>::size_type’ {aka ‘long unsigned int’} [-Wsign-compare]
164 | for (int i = 0; i < detectResults.size(); ++i) {
| ~~^~~~~~~~~~~~~~~~~~~~~~
make: *** [src/subdir.mk:23: src/main.o] Error 1
09:25:43 Build Failed. 3 errors, 1 warnings. (took 3s.329ms)終於找到原因,如下所示已解決:
可以看到這個實例多線程下,四個核每個都跑到了幾乎100% 。説明的確是多線程。接下來我們分析一下多線程推理其實現過程:文中是4路視頻,可以理解成4幅圖-----預處理時是4個子線程t1對4幅圖並行處理,但通常不是同時結束預處理preprocess,總會有一個順序假設完-成順序是img2、img4、img1、img3。----那麼當img2完成preprocess時立刻就放入隊列prequeue中了,然後馬上pop出prequeue隊進推理車間,推理完畢後入postqueue隊列中。這些都在主線程T中完成---------可能在img2入隊prequeue後img4緊跟着入隊prequeue中,但如果此時推理車間(主線程T)還在忙着處理img2,那img4就要等待,直到img2已處理完畢即主線程空閒了,才會馬上處理img4,即將img4 pop出prequeue隊進推理車間,推理完畢後入postqueue隊列中------注意img4在推理車間進行處理時,img2此時可能已經被pop出postqueue隊列了,開始子線程t2對img2進行後處理postprocess。 由此可知,並不是真正的並行,而是異步!對於唯一的一個modelid,只能異步。
如果要傳統意義上的真正並行,必須要創建多個modelid 配套不同的context、內存input、output以及device上的buffer等資源,才能真正並行。
獨立並行推理C++
實現真正的獨立且並行推理,根據上面的分析我們知道samples中的實例只是實現了異步推理,並沒有真正實現獨立並行推理,因此我們自己試下。
使用中遇到的問題
多線程下穩定性
之前單線程下測試是沒問題的,今天開始使用多線程進行穩定性測試時,我開了10個線程每個線程處理近六十幾張圖,隔半個小時記錄一次AI卡的温度、AI core佔用率與頻率,結果出現卡在下面左圖十五分鐘以上,不止這個終端卡住,整個系統完全卡死,無法關機,然後一直等到下中圖直接被killed!我以為是哪裏資源沒釋放,但我是參照官例寫的,官例釋放了哪些資源我就照做的。
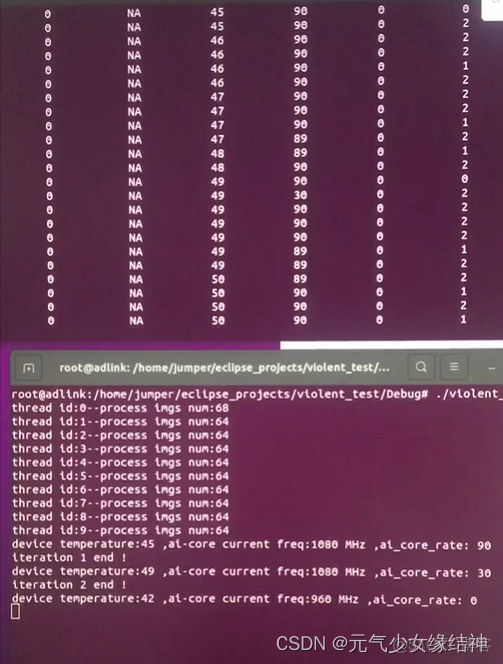
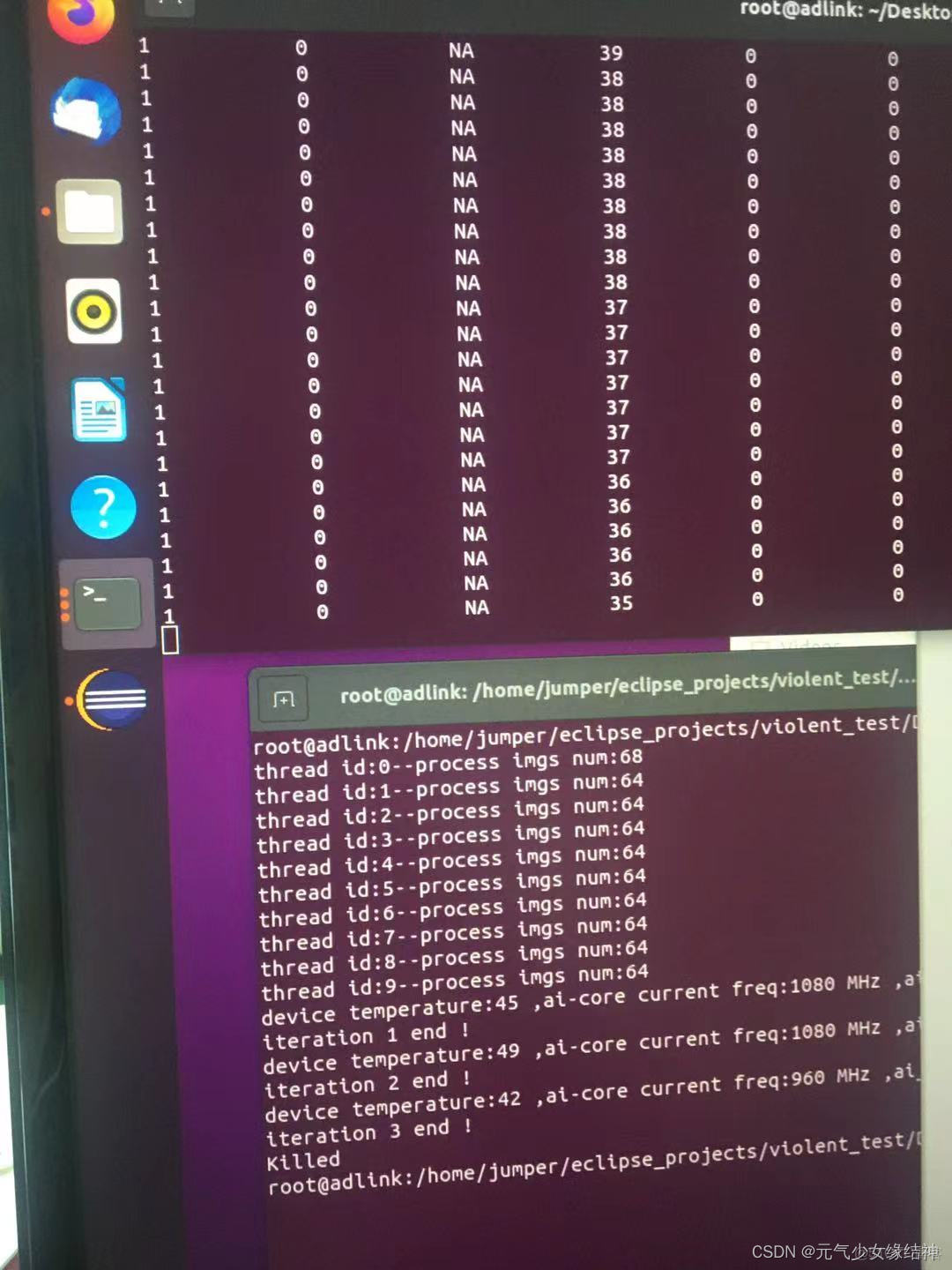
我以為是AI卡的保護機制,可能我線程太多温度太高負荷太大所以把我killed了。於是我減少線程到1並減少圖片數量,然後重新重啓試下,還是會在某次卡死,從top看每個iteration有釋放資源,並不是內存一直增加到爆滿。
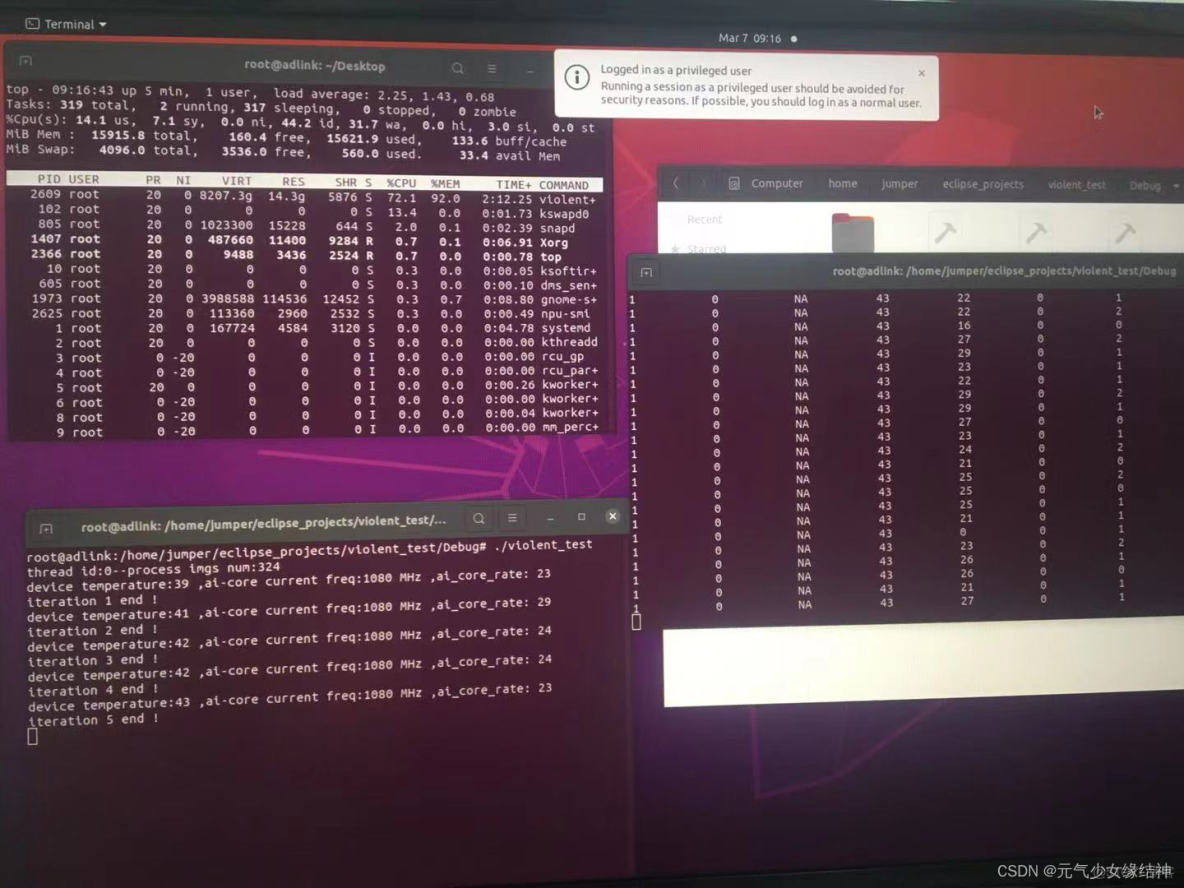
另外查問題可以看下這兩個網站 :日誌收集 msnpureport工具使用 - Atlas 300I Pro 推理卡 5.1.RC2 黑匣子日誌參考 01 - 華為 然後錯誤碼解釋 aclError - CANN 5.0.4 應用軟件開發指南 (C&C++, 推理) 01 - 華為
ModelArts的使用
最近試了一下這個ModelArts,過程如下:
訓練方式1
1,登錄雲計算平台
然後點擊箭頭位置跳到ModelArts控制枱
2,創建notebook實例,並:啓動,然後點擊: 打開
就進入了jupyterLab
這個箭頭位置可以從本地上傳圖片等壓縮包,然後打開終端解壓。終端下將官網支持的模型下載下來:
git clone https://gitee.com/mindspore/models.git然後可以切到1.7版本,我用的是這個版本,因為創建實例notebook時我選的鏡像是mindspore1.7。
3,查看配置文件,在config裏的yaml,自己選擇,然後終端開始訓練
cd models/official/cv/resnet/scripts
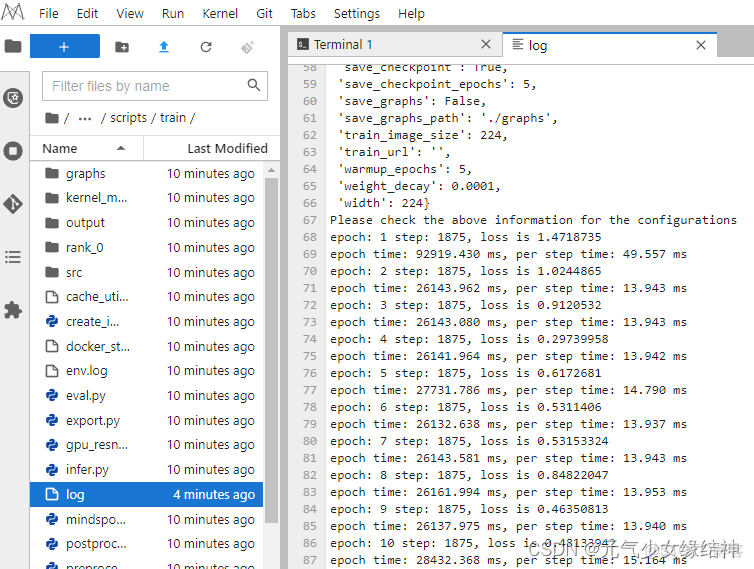
bash run_standalone_train.sh /home/ma-user/work/images/cifar10/data/cifar-10-batches-bin /home/ma-user/work/models/official/cv/resnet/config/resnet50_cifar10_config.yaml會在scripts下生成train,並生成對應的log。右邊狀態欄上有monitor可以查看資源使用率。
log是隔一會兒更新一次,記得手動打開查看多次
4,驗證
類似下面這樣:
bash run_eval.sh ~/cifar10-10-verify-bin /train/output/checkpoint/resnet-90_195.ckpt ../config/resnet50_cifar10_config.yaml
然後會有對應的eval文件生成、以及log,也是隔一會兒更新,可以看到log最後一行的準確率:
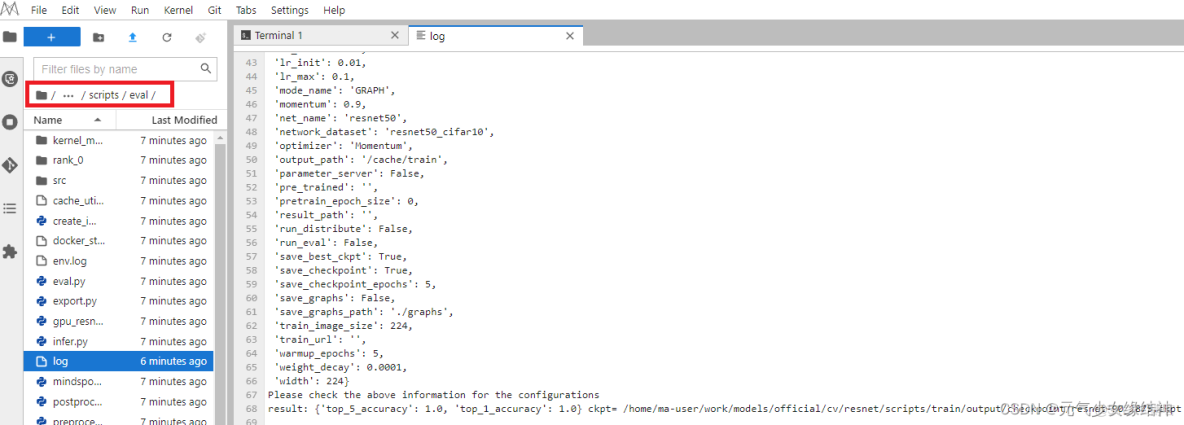
至此,上面已經通過notebook實例在jupyterLab上完成了一次訓練。
訓練方式2
1,上傳jupyterLab上的內容到modelarts中
需要使用moxing:
import moxing as mox
mox.file.copy('/home/ma-user/work/models/official/cv/resnet', 'obs://你自己創建的某個桶名')這樣就將剛剛的resnet模型訓練內容傳到了modelarts上。
2,modelarts上創建訓練作業:創建訓練作業_AI開發平台ModelArts_模型訓練_完成一次訓練_華為雲 查看訓練詳情、日誌等。
3,(麻煩,不做)訓練的可視化 可視化訓練作業介紹_AI開發平台ModelArts_模型訓練_模型訓練可視化_華為雲
IDE調試
對於jupyterLab中的代碼,可以用vscode/pycharm遠程連接從而進行修改、調試、運行
參考 安裝VS Code軟件_AI開發平台ModelArts_開發環境_本地IDE_本地IDE(VS Code)_華為雲
我是選的vscode,於是先安裝,然後跟着教程 VS Code手動連接Notebook_AI開發平台ModelArts_開發環境_本地IDE_本地IDE(VS Code)_華為雲 手動創建連接,然後就可以 在VS Code中遠程調試代碼_AI開發平台ModelArts_開發環境_本地IDE_本地IDE(VS Code)_華為雲 調試修改代碼了。
自動學習
modelarts有自動學習功能,即只需上傳各個類別的樣本,網頁上標註好,設置訓練時長,就可以開始自動訓練了。
1,創建桶並上傳樣本圖片
上傳不同類別的圖片到桶,一定要按照:桶名/文件夾名(我這裏是train)/類別1名/圖片 這種形式,即類別1名不能直接放在桶名下。

我發現jupyterlab上傳圖片時總是會有這種報錯:
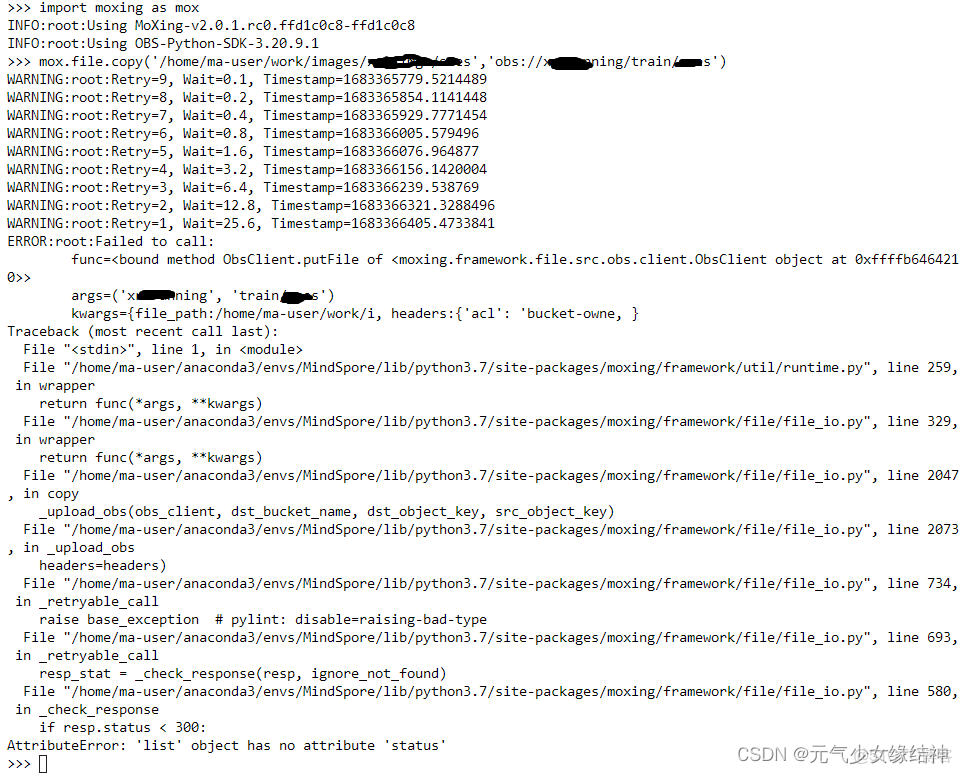
但是不用在意。
2,創建數據集(舊版數據集比新版好用)
先説下,數據集我們哪怕用不同的文件夾上傳的,最終創建數據集時還是會自動給我們混在一起,這點很煩。
3,標籤標註(兩種方式:智能標註或手動)
A,先説智能標註
必須先每個類別手動標註5張,才能啓動智能標註,即所謂的一鍵標註
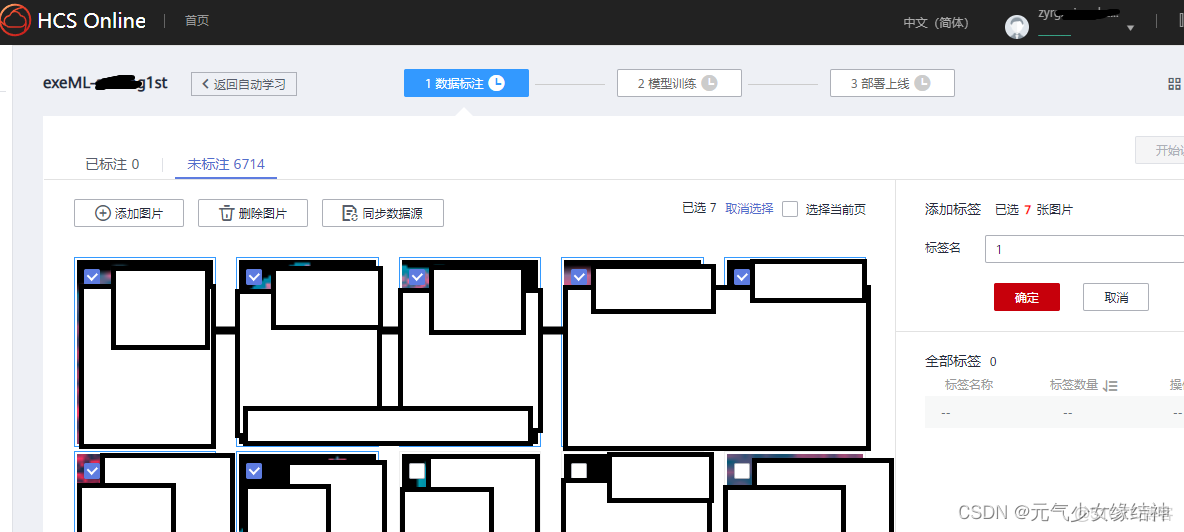
然後再返回數據集,啓動智能標註
但是我試了下,智能標註只針對很好區分的圖片標註才快,否則非常慢或根本標註不出來。因為它系統內是將不同類圖片混合在一起的,哪怕我們手動標了5張,對於難分類的圖,智能標註基本無用。所以我是自己手動標註的。
B,手動標註
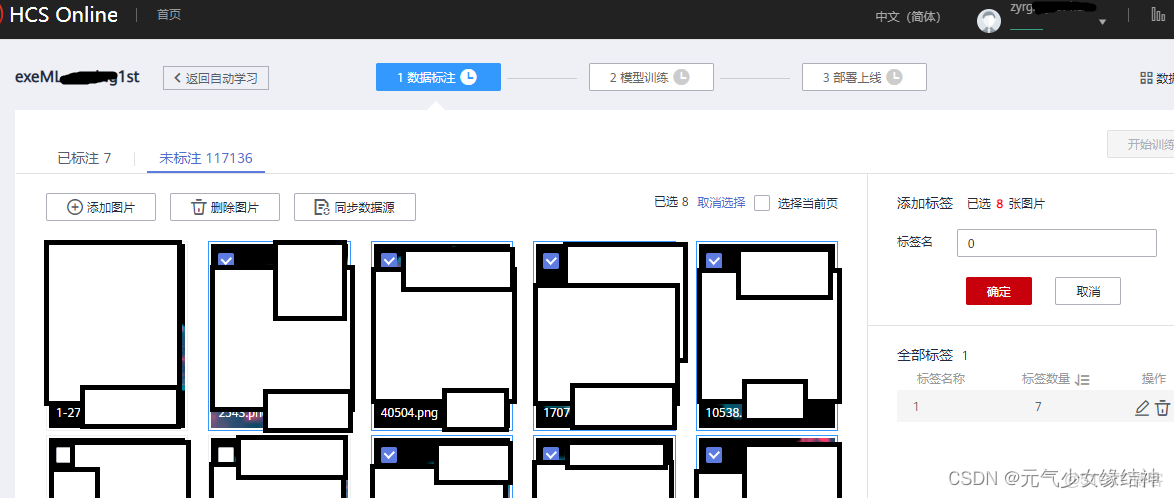
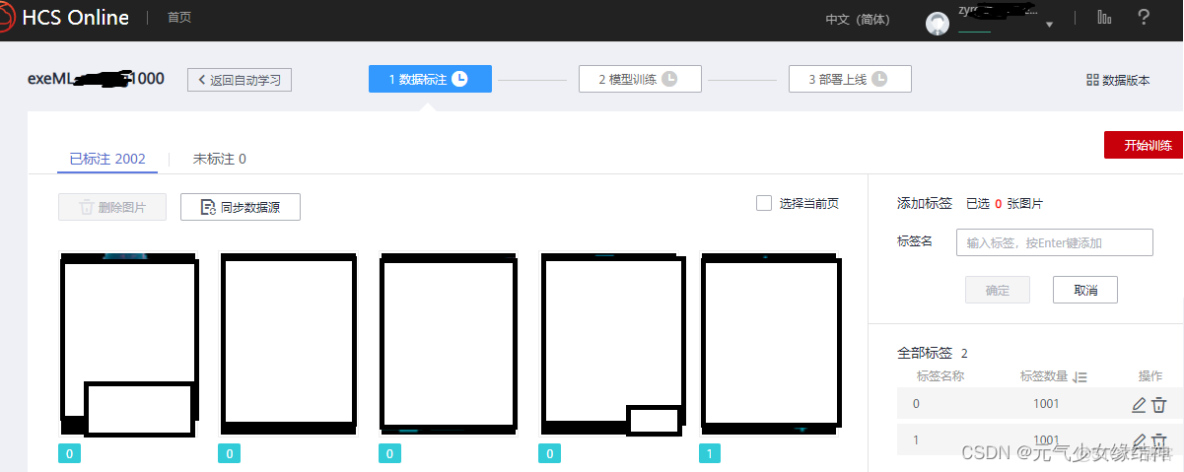
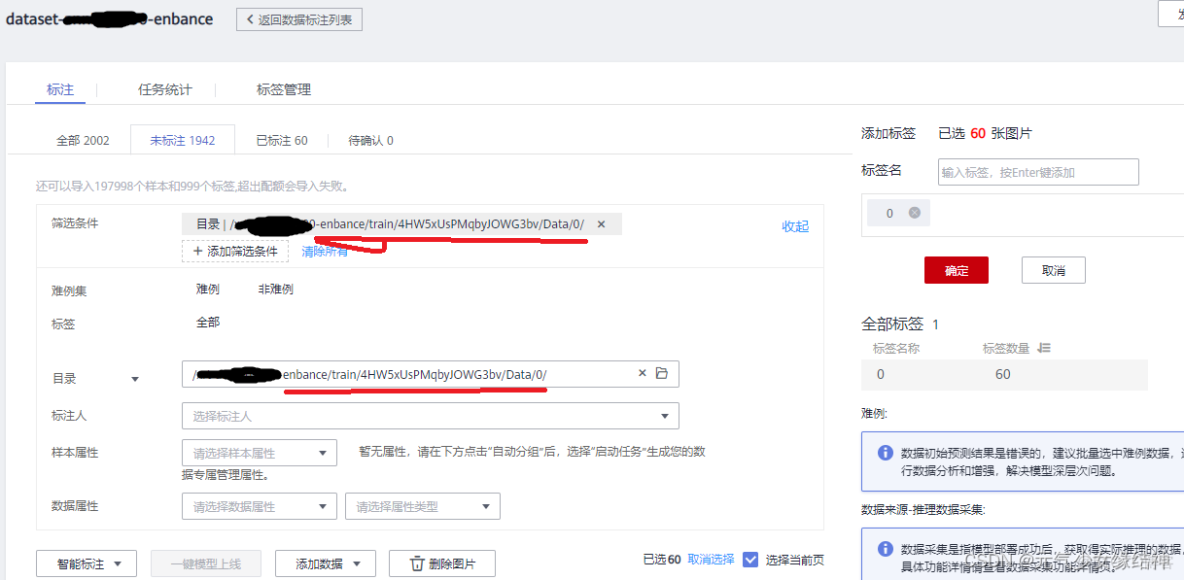
這裏有一個篩選條件,我是直接篩選到目錄即我的類別1下,將所有圖片標註。這裏竟然一次只能最多60個/100個,所以很煩。
4,創建自動學習項目
導入我們之前標註好的數據集
5,開始訓練
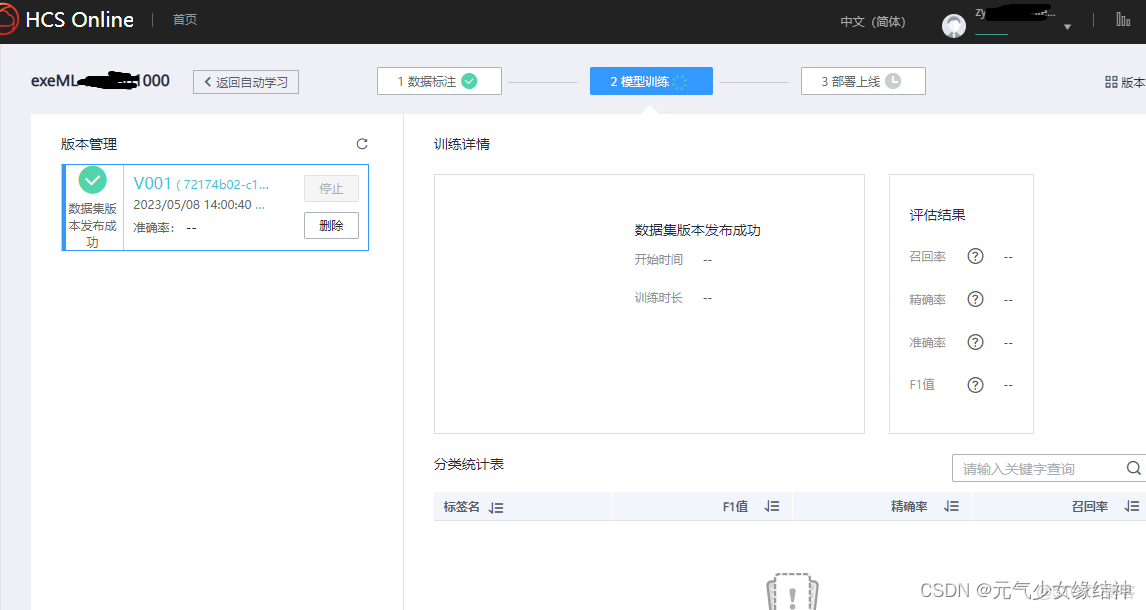
6,訓練結束
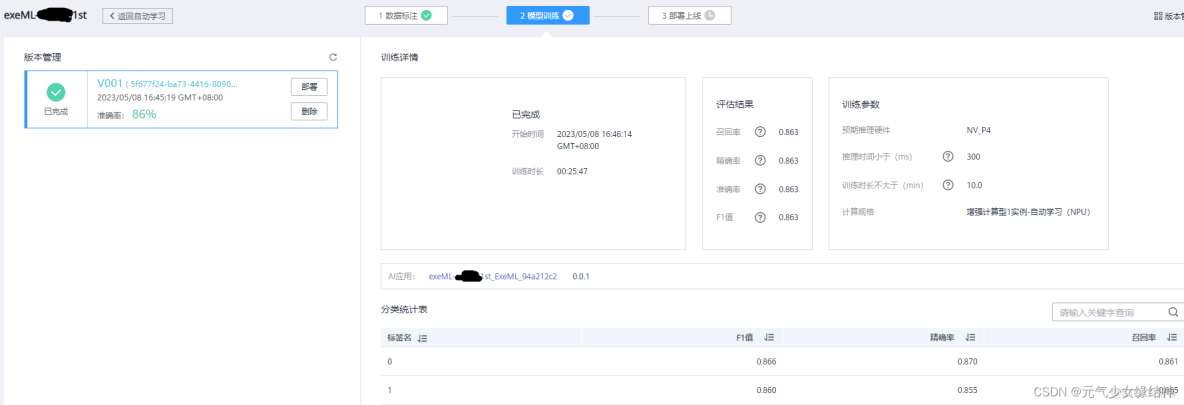
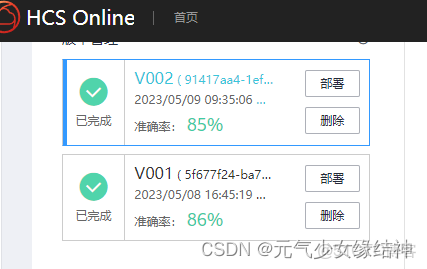
試了幾次,準確率不高。
7,數據處理
數據處理有幾種方式,有數據清除、數據增強等等。我選擇了對上面訓練得不好的數據集/桶做數據增強。
a,需要先自己新建一個增強後的數據集/桶,
b,然後將之前已標註好的數據集/桶中的數據做增強,增強的輸出路徑為新建的這個數據集/桶,
c,然後再對增強輸出結果進行標註。這點很煩,之前已經標註過的圖,增強後生成對應的圖片竟然要重新標註。
d,最後新建自動學習任務,導入標註好的增強圖即可開始訓練。
8,在線部署推理
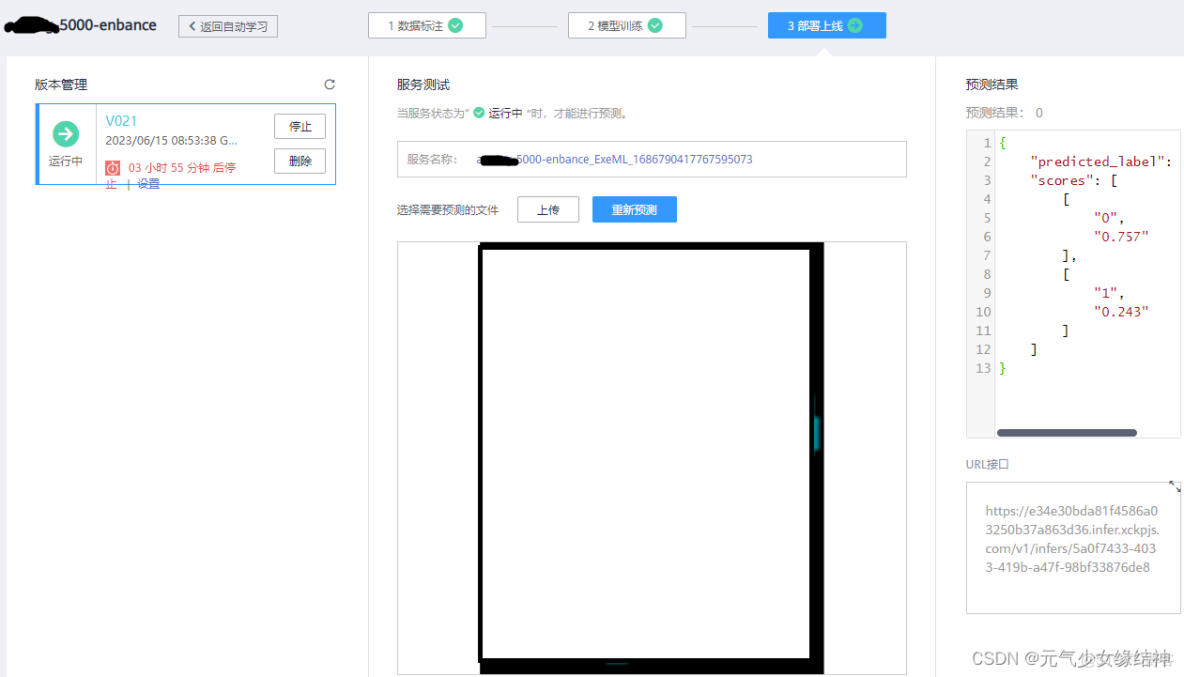
自動學習的模型只可以一張一張在線推理,目前無法批量:
9,模型導出
非自動學習的模型可以導出,如resnet:
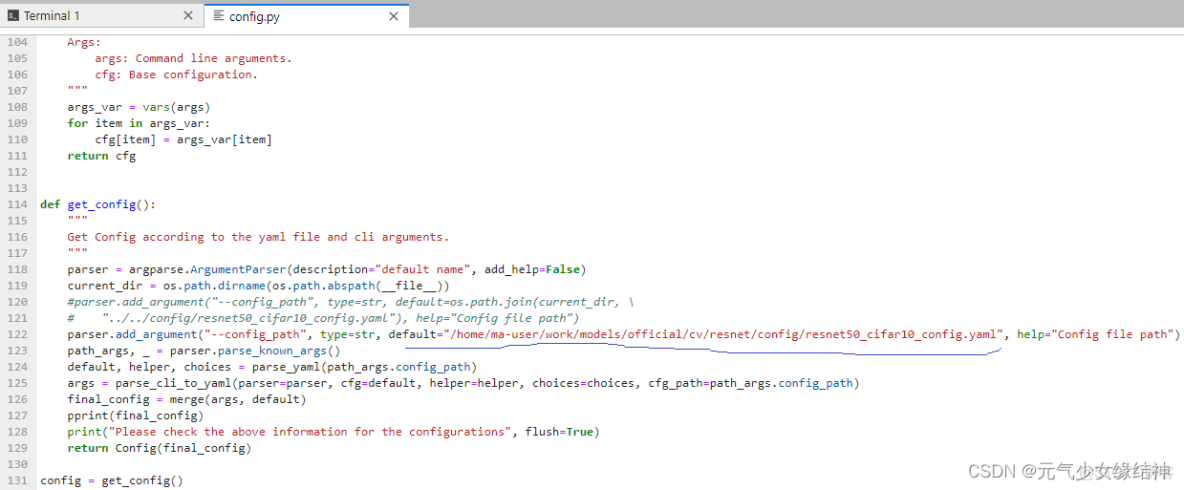
我修改了劃線的地方:
導出模型的名字任意命名:
download到本地磁盤:
參考網址:GitHub - Ascend/samples samples: CANN Samples - Gitee.com 昇騰社區-官網丨昇騰萬里 讓智能無所不及 samples: CANN Samples
########################以下是TensorRT###########################
tensorRT
首先閲讀了大神的一些文章:
https://zhuanlan.zhihu.com/p/547970261 瞭解tensorRT
https://zhuanlan.zhihu.com/p/547966550 瞭解tensorRT
https://zhuanlan.zhihu.com/p/555827562 tensorRT生態鏈
https://zhuanlan.zhihu.com/p/408220584 tensorRT C++部署
https://zhuanlan.zhihu.com/p/344810135 tensorRT C++部署
https://zhuanlan.zhihu.com/p/555829505 tensorRT runtime c++ API,反序列化引擎進行推理
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#perform_inference_c
https://zhuanlan.zhihu.com/p/553367059 tensorRT性能分析與性能優化方法
https://zhuanlan.zhihu.com/p/552537009 在tensorRT中使用DLA(固定層加速引擎)
https://zhuanlan.zhihu.com/p/551268145 tensorRT自定義層
https://zhuanlan.zhihu.com/p/481960581 tensorRT動態batch
https://zhuanlan.zhihu.com/p/407563724 YOLOX網絡的序列化 C++
tensorRT不能直接跨平台/顯卡/tensorrt版本,如果序列化生成engine的平台/顯卡/tensorrt版本與反序列化加載engine並進行推理的平台/顯卡/tensorrt相同,則沒問題;否則要在後者中重新序列化一次。
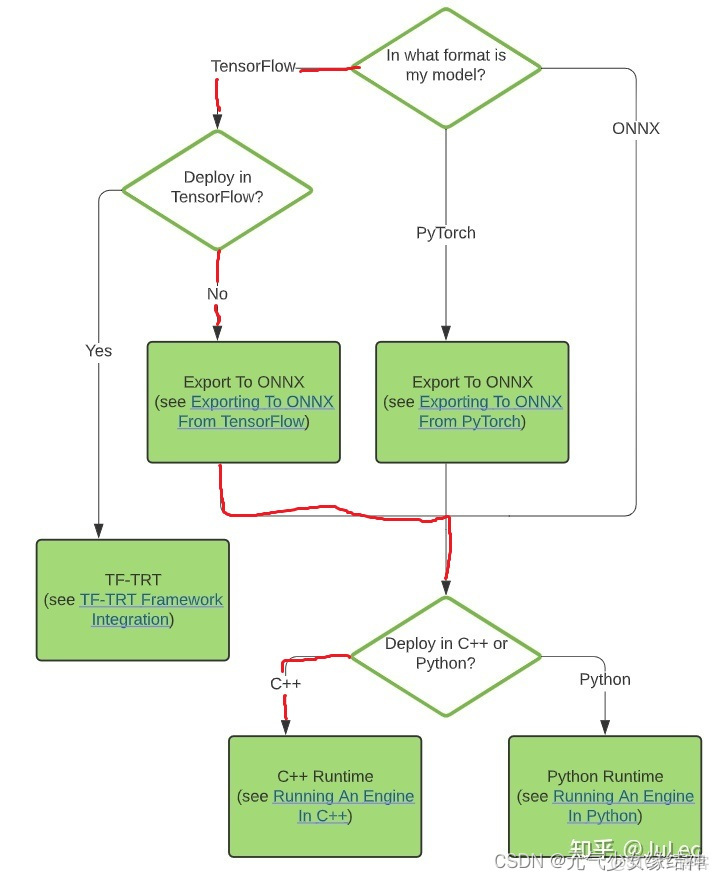
https://zhuanlan.zhihu.com/p/358135157 從論文復現網絡看過上面大神的文章後,知道我要做的就是如下圖紅色步驟:
然後我可能是在Jetson AGX Xavier服務器上實現,關於這個服務器可以Jetson AGX Xavier - 隨筆分類 - 格格_gloria 通過這兩個大神的博客瞭解下。
~~~~~~~~~~~~~~~~~~~~~~ Jetson AGX Xavier安裝CUDA~~~~~~~~~~~~~~~~~~~~~
使用JetPack SDK Manager刷機(通過另一台正常的ubuntu系統作為host,給這個Jetson平台刷系統)部分忽略,因為我拿到手時這台機已刷完ubuntu 18.04.6系統了。
然後我原本準備按之前我的記錄ubuntu下tensorflow 2.0/2.5 c++動態庫編譯gpu版本_元氣少女緣結神的博客ubuntu 查看c++版本給這台機裝TF-GPU C++,發現不行,因為裝CUDA時需要查看兼容性如下Release Notes :: CUDA Toolkit Documentation :可以看到要與系統內核匹配
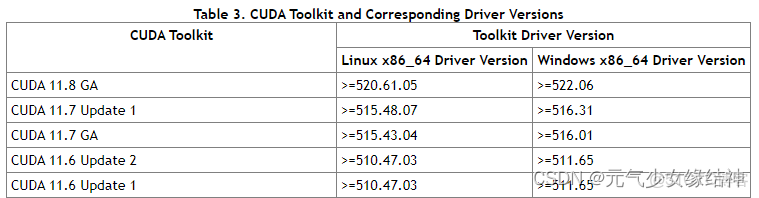
而通過命令uname -a 可以看到Jetson平台的kernel並不是x86_64而是 linux ubuntu 4.9.140-tegra,所以就不能按上面的平常的步驟去安裝CUDA了。
~~~~~~~~~~~~~~~~~~Jetson AGX Xavier安裝TF C++~~~~~~~~~~~~~~~~~~~~~~~~
ubuntu18.04.5下AI推理
換到一台新機上,重頭開始配置。
一、安裝系統ubuntu18.04.5:
教程很多,忽略。注意系統內核別太高,否則後面裝驅動會失敗的,最好內核版本低一些,比如5.4.0-42-generic等等。我的本來是5.15.x,後面ubuntu18.04.4更換內核版本_ubuntu更新內核_小立愛學習的博客- 降低到了5.4.0-42就OK。 另外自動更新取消掉。
二、配置遠程
Windows10通過VNC遠程連接Ubuntu18.04 - 愛碼網 以及 WinSCP 連接 Ubuntu,顯示拒絕訪問。
Atlas 300I Pro 推理卡 5.1.RC2 NPU驅動和固件安裝指南 04 - 華為
將驅動拷貝到/opt下,先check再full,安裝驅動時發現竟然有下面的報錯:
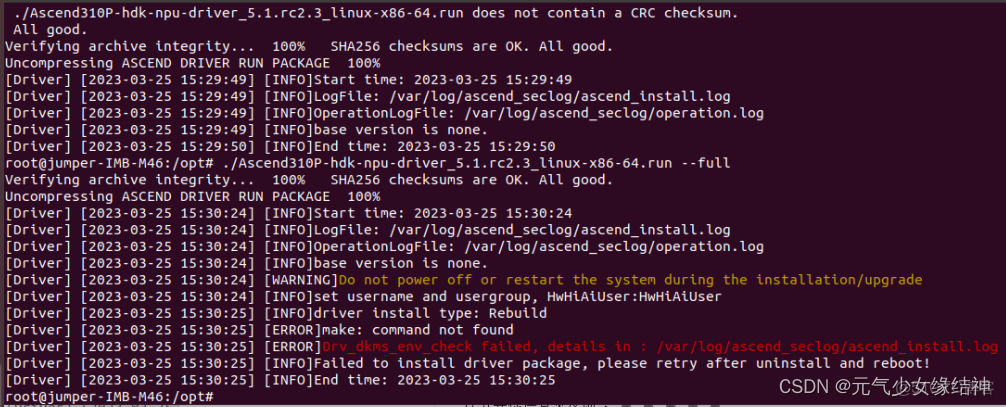
我看下日誌後發現是版本問題,這個驅動與我的內核版本不一致:
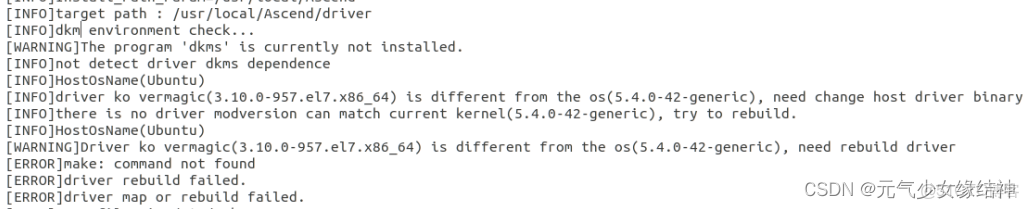
於是我重新下載Ascend HDK 系列 昇騰計算22.0.0 軟件補丁下載 - 華為 一個版本安裝,結果還是同樣的問題。先用apt-get install dkms 把警告dkms的裝了,咦竟然就可以安裝了,看:
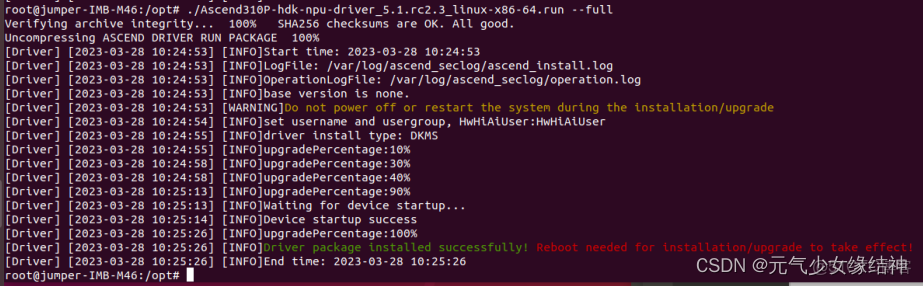
固件也是一樣步驟安裝,先check再full,裝完後現在重啓。重啓後輸入npu-smi -v 可顯示版本號表面正確安裝,輸入npu-smi info可以看到卡信息證明正確。
三、安裝CANN的依賴
我是按照昇騰社區-官網丨昇騰萬里 讓智能無所不及 這個步驟在昇騰社區-官網丨昇騰萬里 讓智能無所不及 這裏下載toolkit的版本進行安裝。
先安裝依賴:
apt-get install -y gcc g++ make cmake zlib1g zlib1g-dev openssl libsqlite3-dev libssl-dev libffi-dev unzip pciutils net-tools libblas-dev gfortran libblas3 libopenblas-dev然後使用下面的檢查是否正確:
gcc --version
g++ --version
make --version
cmake --version
dpkg -l zlib1g| grep zlib1g| grep ii
dpkg -l zlib1g-dev| grep zlib1g-dev| grep ii
dpkg -l libsqlite3-dev| grep libsqlite3-dev| grep ii
dpkg -l openssl| grep openssl| grep ii
dpkg -l libssl-dev| grep libssl-dev| grep ii
dpkg -l libffi-dev| grep libffi-dev| grep ii
dpkg -l unzip| grep unzip| grep ii
dpkg -l pciutils| grep pciutils| grep ii
dpkg -l net-tools| grep net-tools| grep ii
dpkg -l libblas-dev| grep libblas-dev| grep ii
dpkg -l gfortran| grep gfortran| grep ii
dpkg -l libblas3| grep libblas3| grep ii
dpkg -l libopenblas-dev| grep libopenblas-dev| grep ii然後繼續按照昇騰社區-官網丨昇騰萬里 讓智能無所不及流程安裝python,如果遇到timeout報錯就在對應的install前面加上--default-timeout=1000即可。
四、安裝CANN
即按照 昇騰社區-官網丨昇騰萬里 讓智能無所不及 這個安裝toolkit即可,默認會安裝在/usr/local/Ascend/ascend-toolkit/下,然後將下面這句添加到/root/.bashrc下:
source /usr/local/Ascend/ascend-toolkit/set_env.sh然後再source /root/.bashrc 使其生效,這樣在任何一個終端下輸入atc都會出現:
ATC start working now, please wait for a moment.則表示安裝成功。
五、安裝cv及tf(可忽略)
根據自己的需求來安裝opencv以及tensorflow:
pip3 --default-timeout=1000 install opencv-python
pip3 install tensorflow-cpu==2.5.0這裏我還下載了C++ opencv 4.5.2並像在ubuntu20.04.4中一樣編譯了,如果不用C的可以忽略:
1,apt install cmake-qt-gui
2,再下載opencv和對應contrib
3,終端cmake-gui
編譯類型:Release
填入:opencv_extra_module的路徑
勾選:build_opencv_world,WITH_TBB,BUILD_TBB
取消勾選:WITH_ITT
4,make && make install
收集include和lib六、安裝AI並行推理需要的庫
先將下面這4句添加到/root/.bashrc的後面,然後source生效:
export CPU_ARCH='x86_64'
export INSTALL_DIR=/usr/local/Ascend/ascend-toolkit/latest
export install_path=/usr/local/Ascend/ascend-toolkit/latest
export THIRDPART_PATH=/usr/local/Ascend/thirdpart/${CPU_ARCH}再在/usr/local/Ascend下新建一個thirdpart/x86_64文件夾,下載samples-master,然後將samples-master/common文件夾拷貝到步驟B的x86_64下面,再把samples-master/cplusplus/common/acllite文件夾拷貝到x86_64下面。然後按照samples/catenation_environmental_guidance_CN.md at master · Ascend/samples · GitHub 這個鏈接安裝ffmpeg與x246插件這一步安裝這兩個東西。
七、工程配置:
按如下對工程配置即可運行起來:
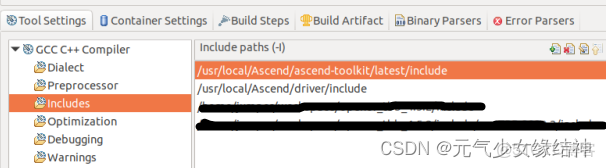
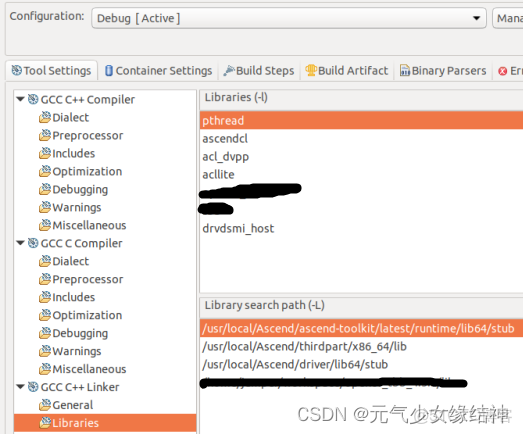
至此ubuntu18.04.5下的所有流程已結束。
今天突然要更換成MindSpore框架:
八、MindSpore
1,先參考MindSpore官網 查看匹配的版本,然後下載合適的版本如mindspore_ascend-1.8.0-cp37-cp37m-linux_x86_64.whl 然後按照安裝步驟 MindSpore官網 安裝。即pip install mindxxxxx.whl 如下:
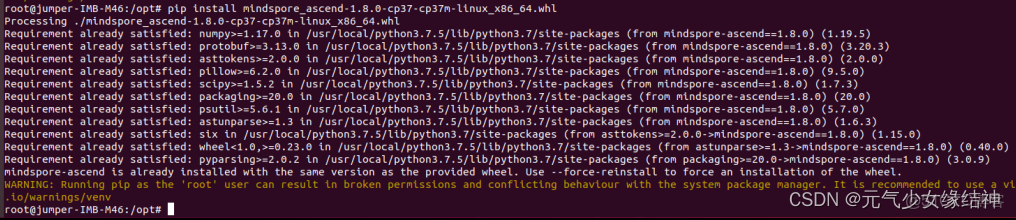
2,有一些其他包的要求,參考 requirements.txt · MindSpore/mindspore - Gitee.com 這個,看自己pip list下哪些還沒有裝,就pip install -default_timeout=1000 xxxx==對應的版本即可。
3,設置環境變量
export GLOG_v=2
LOCAL_ASCEND=/usr/local/Ascend
export LD_LIBRARY_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/lib64:${LOCAL_ASCEND}/driver/lib64:${LOCAL_ASCEND}/ascend-toolkit/latest/opp/op_impl/built-in/op_impl/ai_core/tbe/op_tiling:${LD_LIBRARY_PATH}
export TBE_IMPL_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe
export ASCEND_OPP_PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/opp
export ASCEND_AICPU_PATH=${ASCEND_OPP_PATH}/..
export PATH=${LOCAL_ASCEND}/ascend-toolkit/latest/compiler/ccec_compiler/bin/:${PATH}
export PYTHONPATH=${TBE_IMPL_PATH}:${PYTHONPATH}4,在/usr/local/Ascend/ascend-toolkit/latest/lib64下的幾個.whl如果報錯沒有,那就分別pip install xxx.whl即可
5,驗證是否安裝成功:
python -c "import mindspore;mindspore.run_check()"不出現報錯就成功,但我的有報錯:
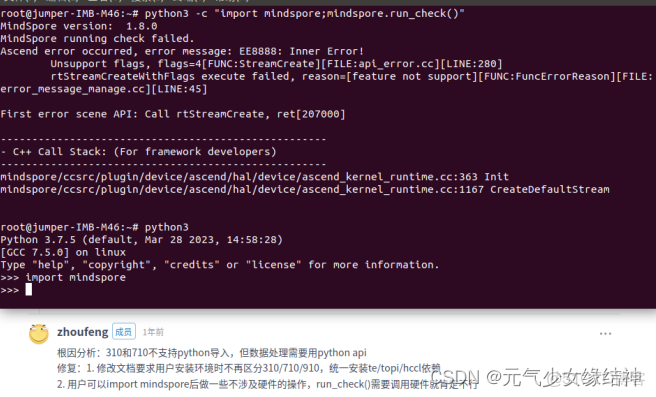
原因如圖中所示。710不支持這種方式驗證mindspore是否安裝成功,因為需要調用訓練卡而我只有推理卡(大家如果有訓練卡是不會報錯的)。所以我直接按之前ModelArts的使用裏面先在那上面訓練,訓練完畢後導出模型。
6,模型推理(離線服務器)
a,先將gitee下models_r1.7下載,解壓到離線服務器
b,安裝 對‘google::FlagRegisterer::FlagRegisterer<unsigned long>(char const*, char const*, )’未定義的引用_守青山的博客-gflags
c,參考 utils/cpp_infer/README_CN.md · MindSpore/models - Gitee.com utils/cpp_infer/README_CN.md · MindSpore/models - Gitee.com 這裏搭建C++推理環境,然後參考 Ascend 310 AI處理器上使用MindIR模型進行推理 — MindSpore master documentation 這裏執行推理。
d,將上面鏈接中説的build.sh、main.cc、Cmakelists.txt以及common_inc都拷貝到一個目錄中,然後根據自己的情況修改main.cc文件如下,最後運行./build.sh編譯成功,生成main的可執行文件與Makefile。但我在執行./main時報錯説我給的測試數據與模型要求不一致,應該換成一致的數據即可。但這個datasize怎麼是30730000這麼奇怪的數字。
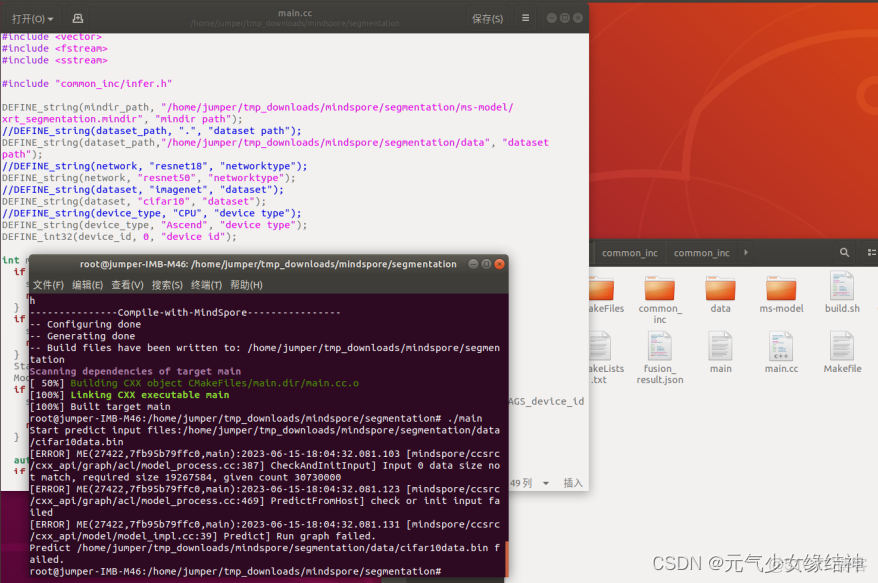
這上面估計是我用的master的代碼,而實際模型是分支1.7下的,所以不一致。
e,於是我將離線代碼也換成r1.7的,然後重來,但是 resnet50在mindspore下訓練導出為mindir後推理報錯 · Issue #I7DU88 · MindSpore/models - Gitee.com 看到依舊報錯:/mindspore/models-r1.7/official/cv/resnet/ascend310_infer/src/main.cc:55: 對google::FlagRegisterer::FlagRegisterer未定義的引用
f,後面發現是將下面5句屏蔽就不會報錯:
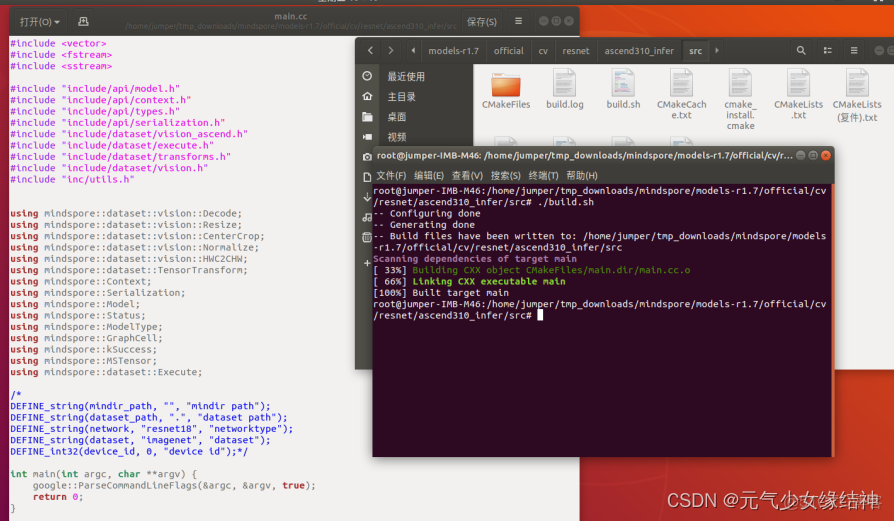
放開就報錯:
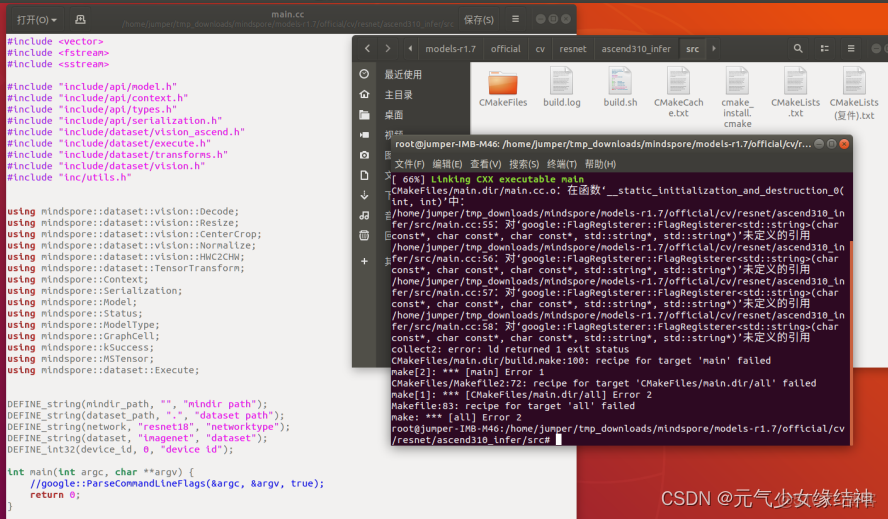
原因未知。
g,我想起d步雖然分支不一樣,但好歹運行到了predict那裏才報錯。於是我將d步master分支下的build.sh、common_inc、main.cc、cmakelists替換到這個報錯的r1.7的src下,這樣就可以不用gflags了,編譯發現沒報錯(中途又發現了官網下的這個文件的諸多小bug,我都懶得放上來了,陳述這些小bug都陳述吐了,解決方式就是自己看日誌、分析、找原因、對症下藥):
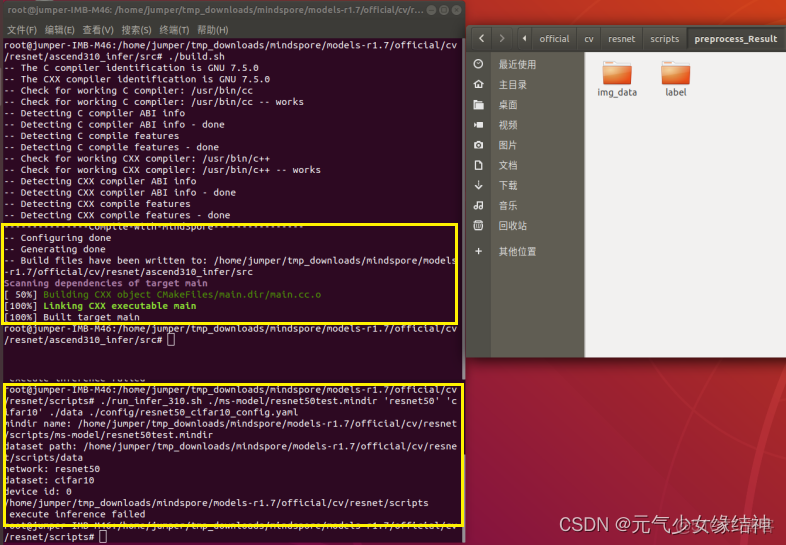
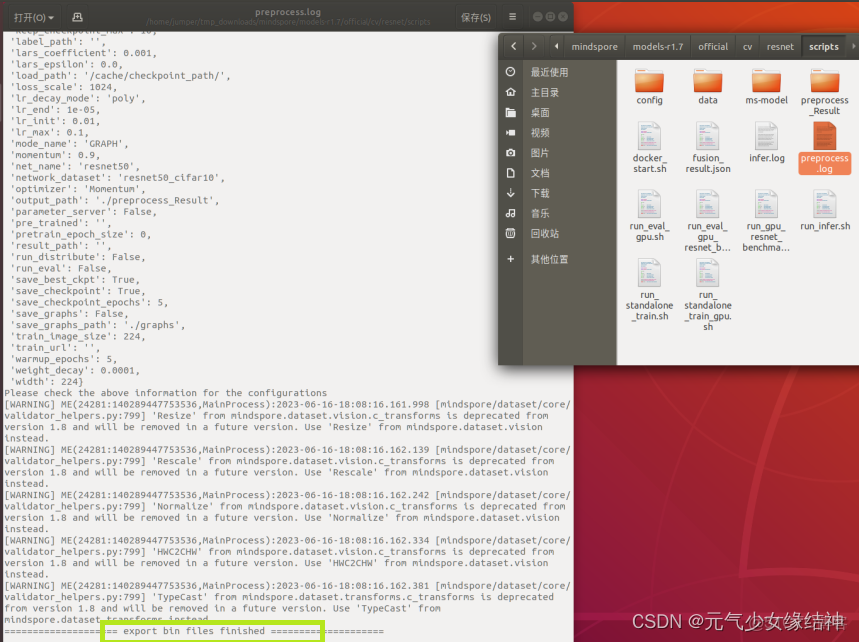
然後現在是推理階段報錯,但至少預處理階段已經運行過了。可以看到生成了處理後的數據img_data、label文件夾以及preprocess的日誌:
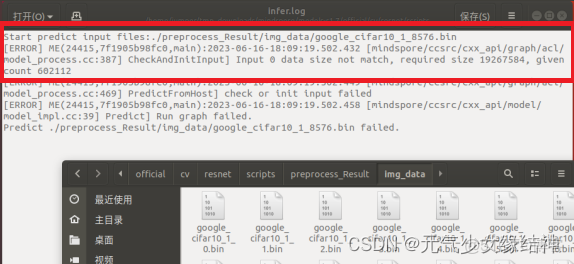
然後我又去查報錯infer日誌看到,這次的報錯datasize尺寸就正常多了,應該是少了一個batchsize的32,説明我最開始給data的bin不正確:
h,於是我重新回到modelarts上,修改那個config.yaml文件的batchsize改成1,然後再導出模型.dir即:
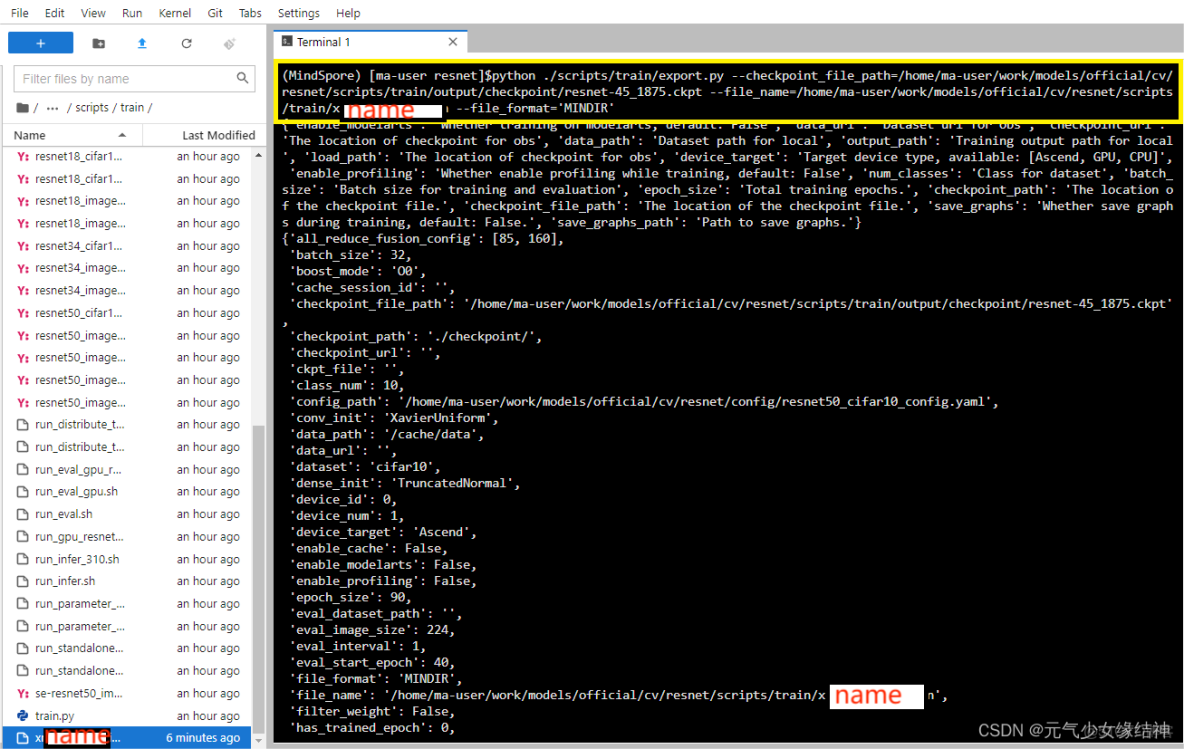
python ./scripts/train/export.py --checkpoint_file_path=/home/ma-user/work/models/official/cv/resnet/scripts/train/output/checkpoint/resnet-45_1875.ckpt --file_name=/home/ma-user/work/models/official/cv/resnet/scripts/train/output/resnet50batchsize1model --file_format='MINDIR'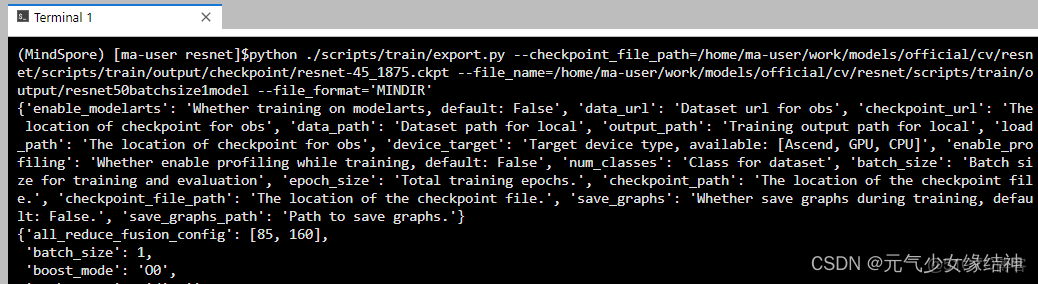
然後將這個yaml以及導出的dir模型download
下載到本地磁盤,上傳到離線服務器中,替換之前報錯的模型與yaml。
i,重新跑之前報錯的run_infer_310.sh腳本:
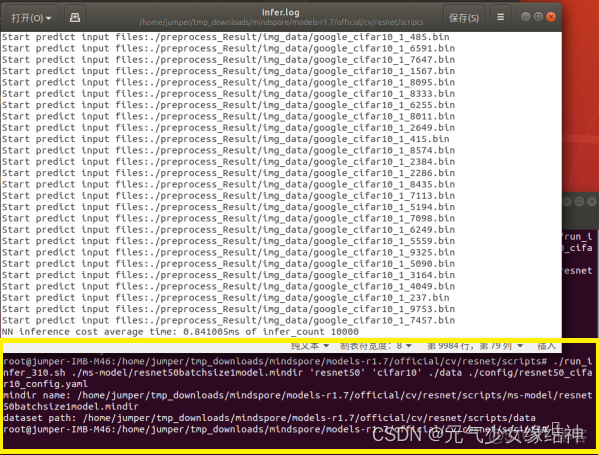
看到已經全部推理成功!!!!!!!且生成了準確率的日誌!!!!!!!
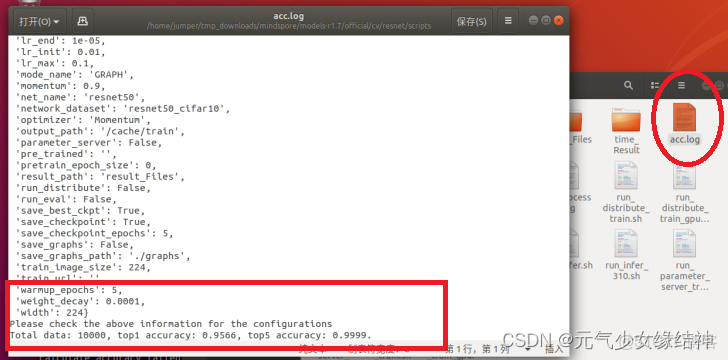
我發誓這篇再也不更新了,剛剛看左下角竟然顯示33000多字了,記錄、記錄、寫寫寫快吐了。
AI卡狀態監測
今天又來更新,AI卡狀態監測demo_1是按官網例子寫的,結構體和函數都遵循官網來的,單獨編譯運行均沒問題,正常反饋AI卡的狀態。但是將demo_1中的結構體和函數編譯進另一個類class_a中,編譯就會報錯。

如上圖class_a中的a.h的81行~85行報錯説這兩個結構體重定義,而我看了下這個結構體的來源是ascend的下面這個頭文件:
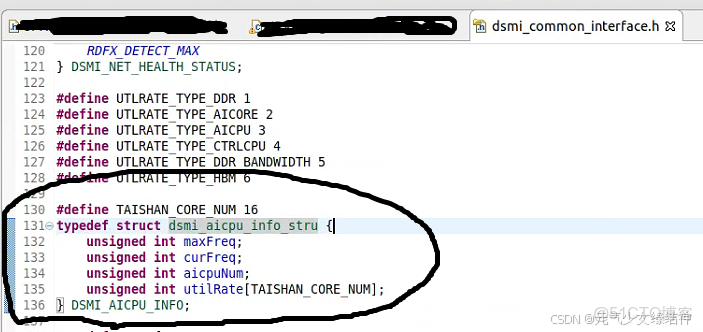
最後沒有辦法,我只能將a.h中的81~85行註釋掉,將81~82行拷貝進a.cpp中。現在已編譯、運行正確。
大模型
相關鏈接:https://gitee.com/mindspore/mindformers/blob/r1.0/research/visualglm/visualglm.md
Ascend/ModelZoo-PyTorch - Gitee.com
MindSpore Lab/mindone - Gitee.com
mindformers-visualglm: 基於MindFormers的visualGLM多模態模型運行在910A上
research/visualglm/visualglm.md · MindSpore/mindformers - Gitee.com