
目錄
寫在前面
一、什麼是MoE
二、MoE 的優勢
1. 參數量巨大但計算量幾乎不變
2. 專家自動分工,能力更豐富(專精化)
3. 訓練效率高
4. 擴展性極強(Scalability)
5. 專家之間天然並行(Parallelism-friendly)
三、MoE 為什麼會變慢?
1. Router 造成額外計算與同步開銷
2. Token 需要在不同專家之間“分發”和“再聚合”
3. 專家負載不均衡導致流水線堵塞
4. 批次小的時候 MoE 效率最差
四、總結
寫在前面
DeepSeek 的出現引發了廣泛關注,它以極低的訓練成本與高參數規模令人驚歎。但我們在實際體驗中也遇到一個困難,相比ChatGPT、Kimi、豆包等同類型的NLP大模型“腹瀉”式的推理速度:“為什麼 DeepSeek 這麼慢?”

許多人誤以為 DeepSeek 的算力更強,因此理應速度更快,其實不然。DeepSeek 應用了極大規模的稀疏Mixture-of-Experts (MoE) 架構,讓模型在等價 FLOPs 基礎上擁有遠超 dense 模型的參數規模。
但在推理場景,越大的 MoE 參數規模往往意味着:路由複雜度增加、通信成本上升、跨設備同步放大、負載不均衡加劇。
:就是深度學習工程界一個常識稀疏模型在訓練時能用稀疏化減少計算,但在推理時絕大多數延遲源自通信,而不是計算。
一、什麼是MoE
讓不同的 token 動態選擇最適合它們的“專家網絡”(Expert)。它的優勢是就是MoE 的核心思想是“不是所有 token 都由同一組參數處理”,而大幅提升模型容量卻幾乎不增加計算量。
MoE 是一種參數稀疏化架構,給定 token 表示 x,路由器計算各專家權重,用公式描述如下:
")
Top-K(通常 K=1 或 K=2)選擇得分最高的 K 個專家集合

。 每個專家

是一個 FFN:
=W_{2,i}\sigma (W_{1,i}x)")
最終輸出為:
")
MoE 模塊結構示意圖:
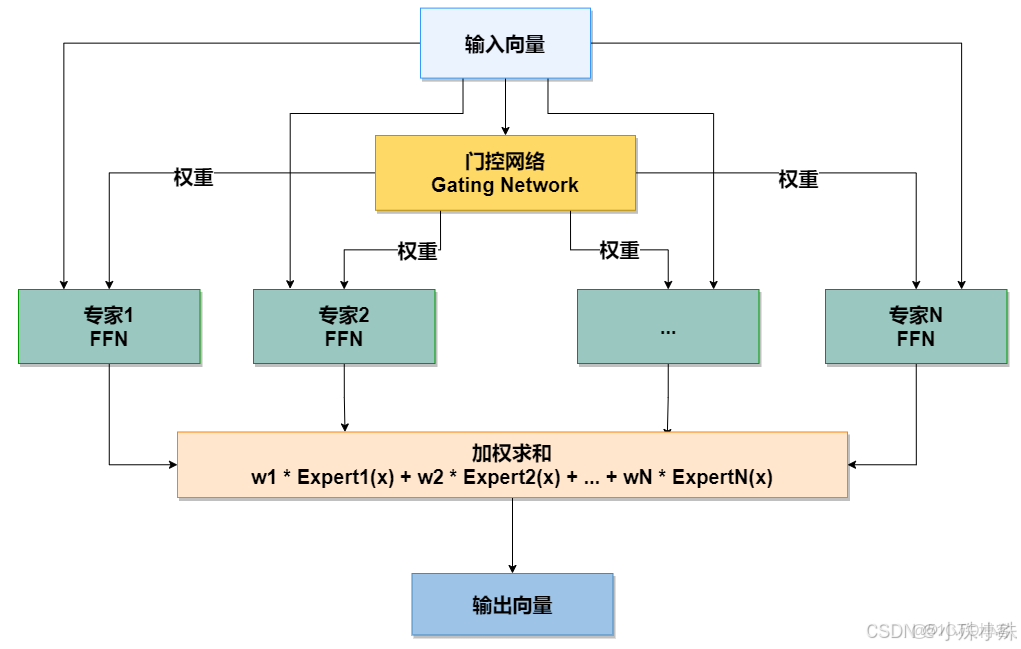
核心組件詳解
1.輸入
一個輸入向量(例如,來自Transformer模型前一層輸出的 token 表示)。
2.門控網絡
功能:這是 MoE 的“路由控制器”。它接收輸入向量,併產生一個權重分佈(通常通過 Softmax 函數)。
輸出:保證計算效率的關鍵。就是一個權重向量 [w1, w2, w3, ..., wN],其中每個 w_i 表示對應專家對於當前輸入的重要性。通常,只有 Top-K(例如 Top-1, Top-2)的專家會被激活,其餘權重置零,這實現了稀疏激活,
3.專家網絡
功能:一個前饋神經網絡)。每個專家都專注於學習輸入數據分佈中的不同部分或模式。就是一羣獨立的、通常是結構相同的子網絡(例如,每個專家都
特點: 所有專家並行存在,但對於任何一個特定輸入,只有少數(K個)專家被激活並參與計算。這使得模型總參數量巨大,但計算成本只與激活的專家數成比例。
4.加權求和
功能:將門控網絡計算出的權重,與對應激活專家的輸出進行加權求和。
公式:Output = w1 * Expert1(x) + w2 * Expert2(x) + ... + wN * ExpertN(x)
結果:最終生成一個與輸入向量同維度的輸出向量,傳遞給模型的下一層。
二、MoE 的優勢
MoE 用更少的計算,獲得更大的模型容量與更強的任務適應性,是現代大模型最具性價比的擴展技術。
1. 參數量巨大但計算量幾乎不變
MoE 最大的強項是稀疏激活:只啓用 Top-K 個專家,其餘專家不參與計算。因此模型參數量可以做到 dense 的 10倍~100倍,但每個 token 的計算量幾乎不增加,這讓 MoE 可以用較低計算成本獲得接近“超大模型”的能力。
2. 專家自動分工,能力更豐富(專精化)
路由器會將不同 token 分配給不同專家,使專家自動學習不同子任務,例如:文本推理、數學、翻譯、代碼、文本糾錯等。
MoE 內部形成多個專精子網絡,使整體泛化能力更強。Dense 模型無法天然做到這種“特化”。
3. 訓練效率高
訓練時每個 token 只激活少數專家,因此FLOPs 低、內存帶寬壓力小、許可用更大的 batch、訓練吞吐率高。
大規模研究顯示:MoE 的訓練速度可比同性能 dense 模型快 3~7 倍。
4. 擴展性極強(Scalability)
Dense 模型參數一旦超過百億級就很難繼續擴展,因為GPU 內存不夠、通信量爆炸、optimizer 狀態佔用率巨大等原因。
MoE 通過稀疏化規避了密集 FFN 的擴展瓶頸:MoE 非常適合構建萬億參數級 LLM。
5. 專家之間天然並行(Parallelism-friendly)
MoE 的專家彼此獨立,使其非常適合分佈式並行,每個 GPU 行負責多個獨立專家\訓練負載容易拆分。相比之下,dense FFN 很難做細粒度並行。
三、MoE 為什麼會變慢?
即使 MoE 理論上計算量低,但它在工程上會造成大量 延遲。DeepSeek 正是因為採用 MoE 才顯得“慢”。
1. Router 造成額外計算與同步開銷
每個 token 都要先經過路由器決定專家選擇,這一步雖然輕量,但得對所有 token 進行 softmax/排序、多 GPU 之間交換路由信息。這些操作會顯著增加 通信延遲。
2. Token 需要在不同專家之間“分發”和“再聚合”
這是MoE速度慢的最主要原因。在 GPU 上,專家通常分佈在不同顯卡甚至不同機器上,因此每個 token 必須經過一個All-to-All 分佈式通信的過程:
tokens -> router -> 分發到對應專家 -> 各專家計算 -> 再匯聚
這就導致:通信遠大於計算、延遲劇烈增加,這一步通常比“推理本身”要慢得多。
3. 專家負載不均衡導致流水線堵塞
Router 不可能完美均衡 token 的分佈,有些專家可能被大量選擇,有些無人使用,結果會出現某些 GPU 堆積大量請求;整個推理速度由最慢的專家決定。這通常叫做 load imbalance(負載不均衡)。
4. 批次小的時候 MoE 效率最差
對於對話式推理(單用户、一個一個 token 地預測),MoE 的並行度利用率極低,因此專家利用率低、通信成本更顯著就成為批次小的時候 MoE 效率最差的原因。
換言之,MoE 更適合大批量推理,但不適合單請求對話場景。
四、總結
工程不足。其根本原因包括:就是DeepSeek 的慢來自 MoE 架構的系統性瓶頸,而不
1.Router 造成額外計算與同步開銷
2.Token → Expert → 匯聚 的 All-to-All 通信主導延遲
3.專家負載不均衡導致流水線堵塞
4.MoE 在小 batch 推理時性能坍塌
5.專家數目大導致通信複雜度上升
6.每層 MoE 都疊加兩次通信 + 路由開銷
Dense 模型推理快,因為:所有計算都是矩陣乘法,沒有任何跨設備不規則通信。
MoE 模型推理慢,因為:大部分時間都在跨 GPU 派發 token、等待最慢專家工作、再同步結果。
這就是 DeepSeek 的慢的技術本質。