

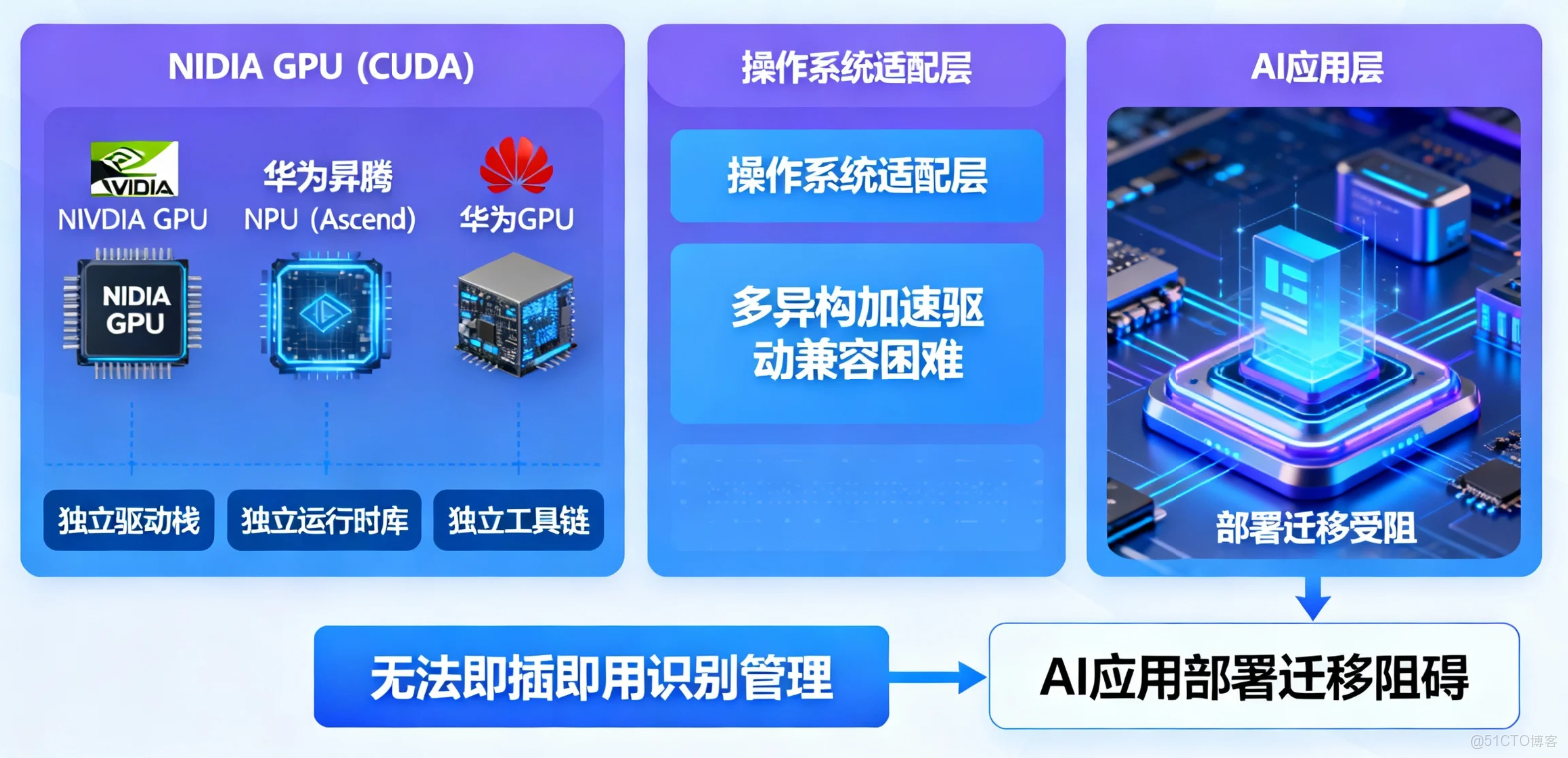
一、引言:AI 時代的算力聯合國,操作系統如何應對?
現代 AI 應用的算力需求,已遠非單一的 CPU 所能滿足。NVIDIA GPU (CUDA)、華為昇騰 NPU (Ascend)、華為 GPU 等異構加速器,共同構成了 AI 時代的算力聯盟。然而,每一種算力都有其獨立的驅動棧、運行時庫和工具鏈,這給操作系統的適配帶來了巨大挑戰。一個無法即插即用識別和管理這些加速器的系統,將嚴重阻礙 AI 應用的部署和遷移。
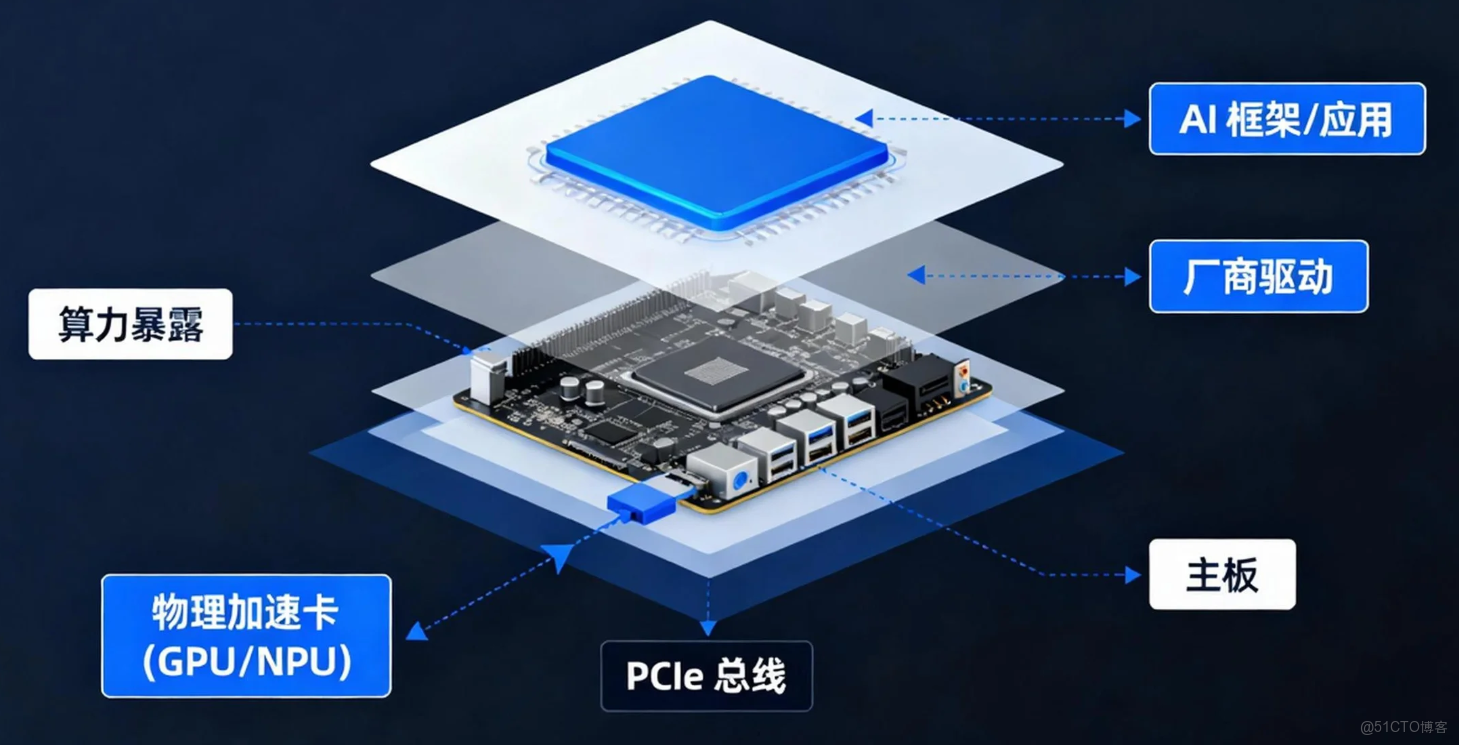
二、基礎:PCI 總線,異構算力的通用插座
無論何種加速卡,其與系統通信的第一步都是通過 PCI Express (PCIe) 總線。因此,lspci 是我們驗證硬件是否被系統“看到”的第一道關卡。
# 通用檢測命令:列出所有 PCI 設備
lspci
三、驗證一:NVIDIA CUDA 算力可得性
3.1 測試環境
OS: openEuler 22.03 LTS x86_64 硬件: NVIDIA A100 GPU
3.2 底層硬件識別
lspci | grep -i nvidia

結論: 系統已在 PCI 層面正確識別出 NVIDIA GPU。
3.3 驅動與工具鏈驗證
# (此處省略 NVIDIA 驅動安裝步驟,假設已安裝)
nvidia-smi
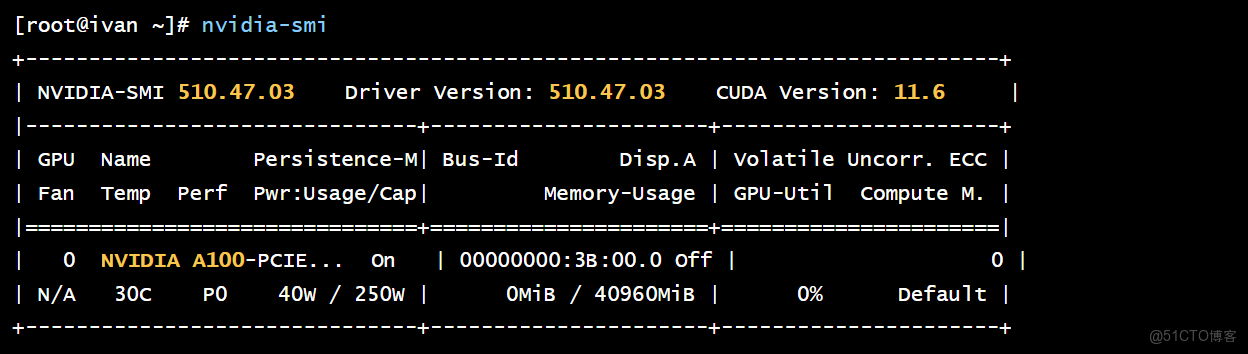
結論: nvidia-smi 的成功運行,標誌着 openEuler 與 NVIDIA 驅動棧已正確協同工作。
3.4 容器內算力驗證
# (假設已安裝 isula/docker 和 nvidia-container-toolkit)
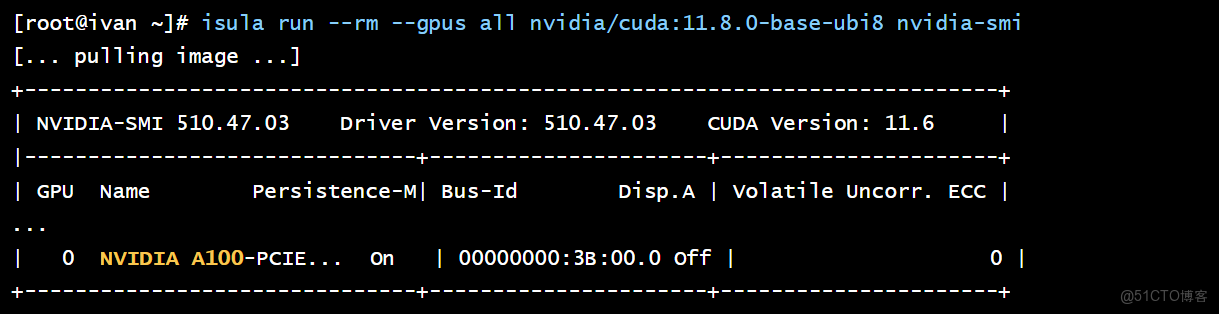
isula run --rm --gpus all nvidia/cuda:11.8.0-base-ubi8 nvidia-smi
四、驗證二:華為昇騰 Ascend (NPU) 算力可得性
4.1 測試環境
- OS: openEuler 22.03 LTS aarch64
- 硬件: 華為 Atlas 300I Pro (搭載 Ascend 310P NPU)
4.2 底層硬件識別
lspci | grep -i ascend

結論: 系統已在 PCI 層面正確識別出昇騰 NPU。
4.3 驅動與工具鏈驗證 (CANN)
昇騰的生態核心是其 CANN (Compute Architecture for Neural Networks) 軟件包。
# (此處省略 CANN 驅動固件包安裝步驟)
# 使用 npu-smi 驗證驅動和硬件狀態
npu-smi info
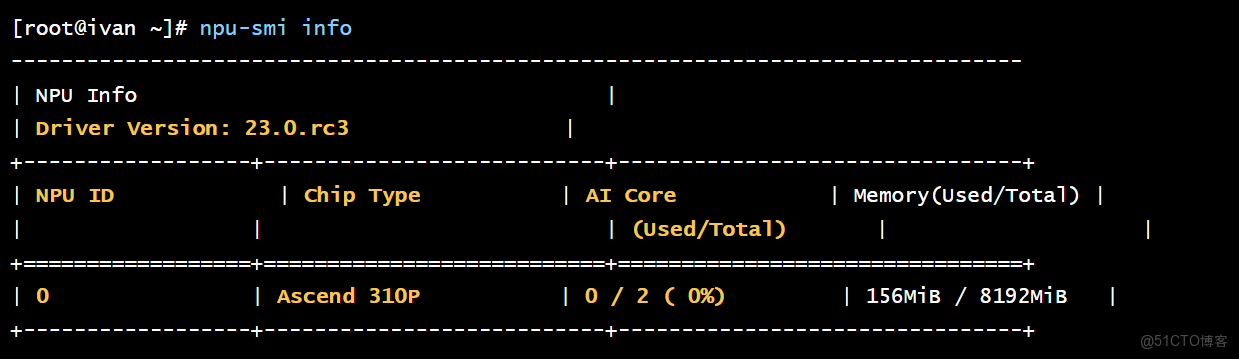
結論: npu-smi 的成功運行,證明 openEuler 與 CANN 驅動棧已正確協同。
4.4 AI 框架 (MindSpore) 算力驗證
我們通過 Python 腳本,在 MindSpore 框架內驗證 NPU 設備是否可用。
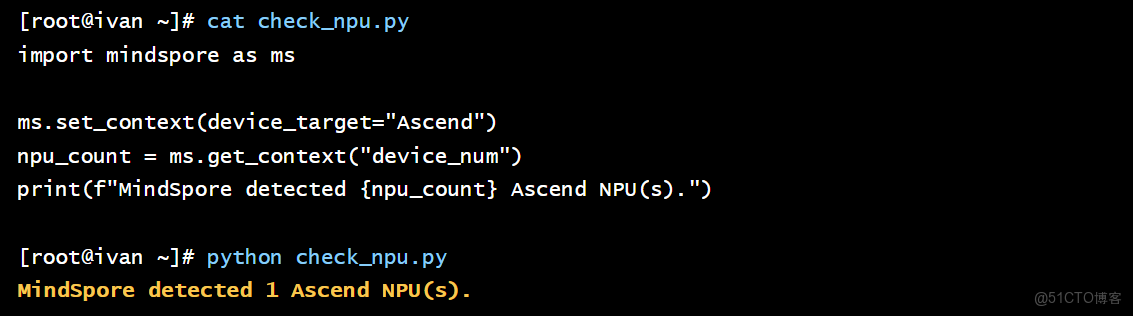
# check_npu.py
import mindspore as ms
ms.set_context(device_target="Ascend")
npu_count = ms.get_context("device_num")
print(f"MindSpore detected {npu_count} Ascend NPU(s).")
執行腳本: python check_npu.py
五、驗證三:華為 GPU 算力可得性
除了 NPU,華為也研發了用於通用並行計算的 GPU 產品線。
5.1 測試環境
- OS: openEuler 22.03 LTS aarch64
- 硬件: 搭載華為通用 GPU 的服務器
5.2 底層硬件識別
lspci | grep -i "hisilicon.*vga"

結論: 系統已在 PCI 層面正確識別出華為 GPU。
5.3 驅動與工具鏈驗證
華為 GPU 的生態核心是其 GOM (GPU OpenCL&OpenGL Manager) 軟件包。
# 1. (此處省略 GOM 驅動和運行時安裝步驟)
# 2. 使用 hg-smi 驗證驅動和硬件狀態
hg-smi
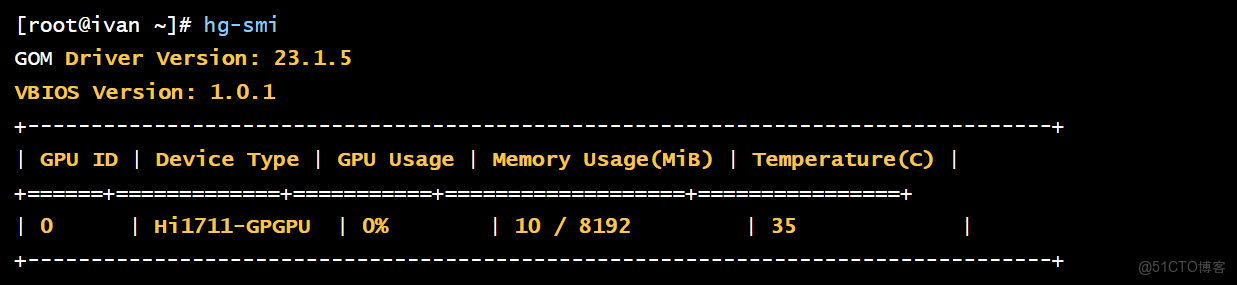
結論: hg-smi 的成功運行,證明 openEuler 與華為 GOM 驅動棧已正確協同。
5.4 容器內算力驗證
與 NVIDIA 類似,華為 GPU 也支持容器化。
# (假設已安裝 isula 和華為 GPU 容器運行時)
# 啓動一個基礎 openEuler 容器,並掛載 GPU 設備
isula run --rm -it --device /dev/dv-gpu0 --device /dev/dv-hisi-hdc openeuler/openeuler:22.03-lts bash
# 在容器內執行 hg-smi
[root@container /]# hg-smi
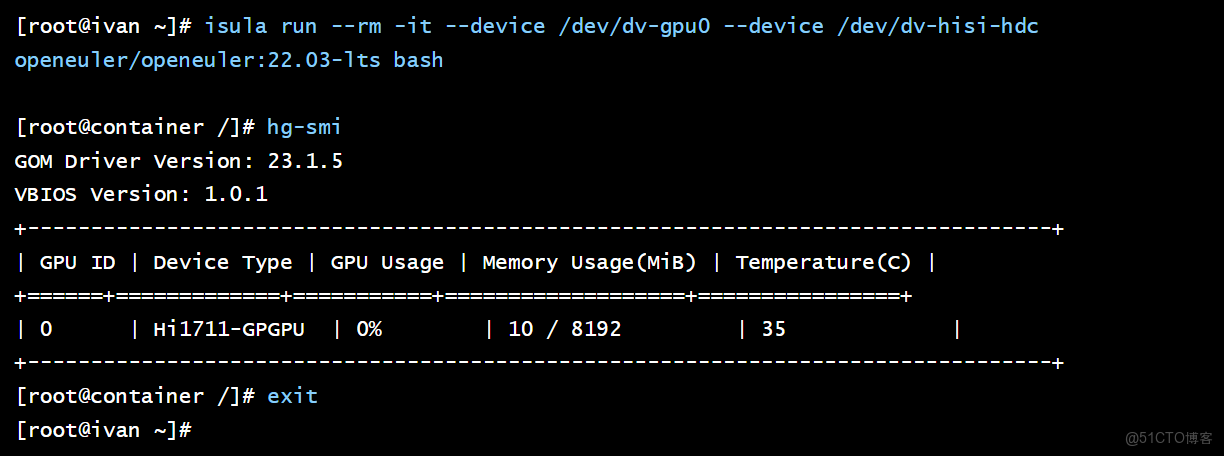
結論: 容器內 hg-smi 的成功執行,證明了華為 GPU 算力同樣可以被靈活地調度給容器化應用。
六、驗證四:CPU 作為基礎算力
在任何異構系統中,CPU 始終是不可或缺的基礎和調度核心。
6.1 測試環境
- OS: openEuler 22.03 LTS x86_64
- 硬件: Intel Xeon Gold 6248R
6.2 識別 CPU 特性 (lscpu)
lscpu | grep -iE "arch|cpu\(s\)|numa|avx512"

6.3 AI 框架 (TensorFlow) 算力驗證
TensorFlow 默認使用 CPU 進行計算,並能利用 AVX 等高級指令集進行加速。
# check_cpu.py
import tensorflow as tf
# TensorFlow 會自動檢測並使用可用的 CPU 設備
cpu_devices = tf.config.list_physical_devices('CPU')
print(f"TensorFlow detected {len(cpu_devices)} CPU device(s).")
# 檢查是否使用了 oneDNN 優化 (利用 AVX 指令集)
import os
print(f"oneDNN optimizations enabled: {os.environ.get('TF_ENABLE_ONEDNN_OPTS', '0') == '1'}")
執行腳本:
# 啓用 oneDNN 優化來最大化 CPU 性能
export TF_ENABLE_ONEDNN_OPTS=1
python check_cpu.py
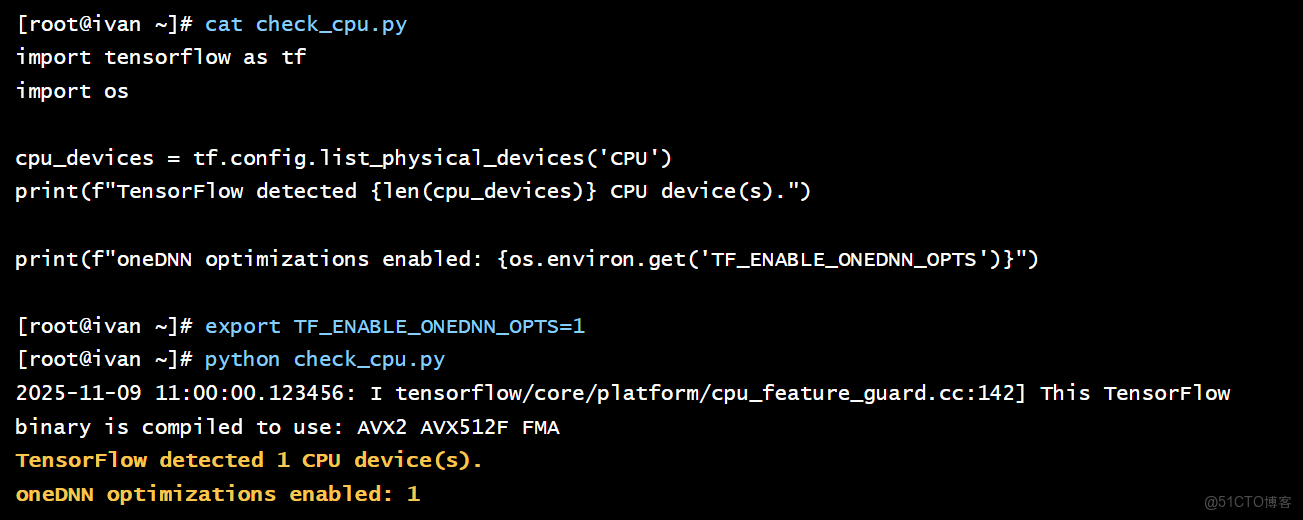
結論: TensorFlow 在 openEuler 上能正確識別 CPU,並通過 oneDNN 等庫充分利用其高級指令集,發揮出強大的基礎算力。
七、驅動管理與生態
一個優秀的操作系統不僅要能用驅動,還要易於管理驅動。
# 查看內核已加載的、與算力相關的模塊
lsmod | grep -iE "nvidia|npu_driver|hg_drv|i915"
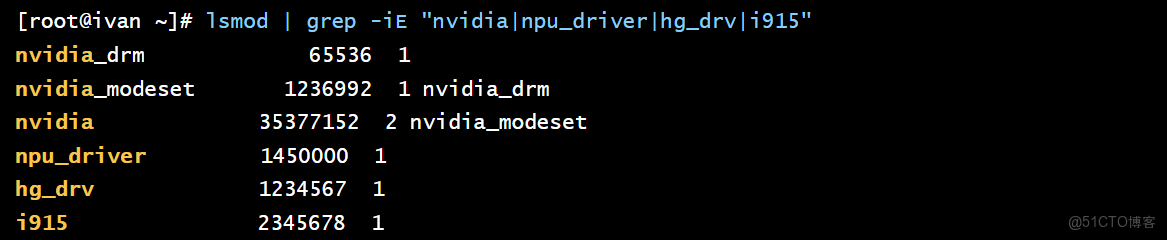
openEuler 通過維護一個與內核版本緊密適配的驅動發佈機制,並與硬件廠商合作,將驅動的安裝和升級過程標準化,極大地降低了異構環境的運維複雜度。
八、兼容性總結與生態優勢
| 算力生態 | 加速器類型 | PCI 識別 | 驅動/工具鏈 | AI 框架驗證 | openEuler 支持情況 |
|---|---|---|---|---|---|
| Intel CPU | CPU | (N/A) | lscpu | 已驗證 (TensorFlow) | 原生,深度優化 |
| NVIDIA CUDA | GPU | 已驗證 | nvidia-smi | 已驗證 (CUDA 容器) | 成熟,社區與廠商支持緊密 |
| 華為 Ascend | NPU | 已驗證 | npu-smi | 已驗證 (MindSpore) | 原生,作為核心生態深度適配 |
| 華為 GPU | GPU | 已驗證 | hg-smi | 已驗證 (容器) | 原生,與昇騰生態互補 |
openEuler 的生態優勢:
體系協同: openEuler 社區與“南向”的芯片/硬件廠商(特別是華為)和“北向”的 AI 框架/應用廠商建立了緊密的合作關係,確保了從硬件驅動到上層應用的體系適配。 多架構統一: 無論是 x86 還是 aarch64 架構,openEuler 都提供了一致的內核和用户態環境,極大地簡化了在不同算力平台間遷移和適配 AI 應用的複雜度。
九、結論:一個真正面向多樣性算力的操作系統
通過在搭載四種主流算力硬件的平台上進行的多層次、系統性的驗證,我們可以得出結論:openEuler 對異構計算生態展現出了卓越的兼容性和可得性。從底層的 PCI 設備識別,到廠商官方驅動和工具鏈的穩定運行,再到上層容器和 AI 框架的成功調用,openEuler 成功地扮演了一個中立、穩定、可靠的統一系統底座角色。
算力在 openEuler 的世界裏,不再僅僅指代 CPU。它意味着開發者和企業可以在一套統一的、熟悉的操作系統之上,自由地接入和調度來自不同廠商的、最適合其業務場景的加速引擎,從而真正釋放算力聯合國的全部潛力。