

一、開啓本地AI開發的新紀元
在生成式AI飛速發展的今天,每一位開發者都渴望擁有無拘無束的算力。不再受制於雲端排隊、網絡延遲或數據隱私的顧慮——NVIDIA DGX Spark橫空出世讓這一切有了可能。
它不僅僅是一台計算機,它是濃縮在精緻桌面機箱中的AI數據中心。作為全球首款基於NVIDIA Grace Blackwell架構的個人AI超級計算機,DGX Spark將工業級的AI性能帶入您的私人工作空間,讓您從原型設計到大規模部署,實現真正的無縫銜接。
二、NVIDIA DGX Spark:小巧機身,PetaFLOP級算力
NVIDIA DGX Spark的核心優勢在於其先進的架構和強大的計算能力,它為本地AI開發提供了工業級的AI體驗。NVIDIA DGX Spark的心臟,是革命性的NVIDIA GB10 Grace Blackwell超級芯片。在緊湊的桌面端外形中,集成了前所未有的計算密度。
1. 令人驚歎的計算性能
- 1 PetaFLOP AI算力:DGX Spark可提供高達每秒1千萬億次的AI計算性能。這意味着您在辦公桌上就擁有了過去需要服務器機架才能實現的算力。
- 第五代Tensor Core:搭載基於Blackwell架構的GPU,專為處理最複雜的AI工作負載而生。
- 高性能混合計算:內置20核Grace Arm CPU(10個Cortex-X925+10個Cortex-A725),強效助力數據預處理和編排,加速從數據清洗到模型調整的全流程。
2. 突破瓶頸的統一內存架構
傳統架構中,數據在CPU和GPU內存之間的搬運是最大的性能殺手。DGX Spark徹底改變了這一點:
- 128GB統一尋址內存 (LPDDR5x):128GB的統一尋址系統內存,支持對FP4數據格式。
- NVLink-C2C互聯技術:提供CPU與GPU間的一致性內存模型,帶寬是第五代PCIe的5倍。
三、 NVIDIA DGX Spark:專為大模型 (LLM) 而生
DGX Spark專為解決生成式AI模型規模和複雜性日益增長帶來的挑戰而設計,特別針對本地進行大模型的原型設計、微調和推理。
1. 單機駕馭200B參數模型
憑藉128GB的統一尋址系統內存和對FP4數據格式的支持,單個NVIDIA DGX Spark系統可以支持對多達200B參數的模型進行試驗、微調或推理。這使AI開發人員能夠在桌面端對新一代AI推理模型進行原型設計、微調和推理。您可以在本地安全地對新一代開源模型進行微調 (Fine-tuning)、量化驗證或高吞吐量推理,無需將敏感數據上傳至雲端。

2. 雙機互聯,挑戰405B參數極限
DGX Spark內置了NVIDIA ConnectX™智能網卡。通過NVIDIA ConnectX互聯技術,可以連接兩台NVIDIA DGX Spark AI超級計算機。這種擴展能力支持對多達405B參數的模型進行推理,例如Llama 3.1 405B等更大的模型。

通過高速互聯技術連接兩台DGX Spark,構建您的桌面微型AI集羣。這種組合可支持高達4050億 (405B) 參數的超大模型推理(例如 Llama 3.1 405B)。這是目前市場上罕見的、能在辦公桌面上運行頂級大模型的解決方案。
3. 部署與遷移
NVIDIA DGX Spark支持本地開發,隨時隨地進行大規模部署。用户可以將其模型從桌面端無縫遷移到DGX Cloud或任何加速雲或數據中心基礎設施,幾乎無需更改代碼。這使得原型設計、微調和迭代過程比以往都更容易。
- 原廠軟件生態:預裝NVIDIA DGX OS和Ubuntu Linux,以及最新的NVIDIA AI軟件堆棧。
- 開箱即用:開發者可直接訪問 NVIDIA NIM™和NVIDIA Blueprint,並流暢使用PyTorch、Jupyter和Ollama等主流工具。
- 從桌面到數據中心:您在DGX Spark上開發的模型,無需修改代碼即可無縫遷移至DGX Cloud或企業級數據中心。它是您低成本、高效率的實驗場。
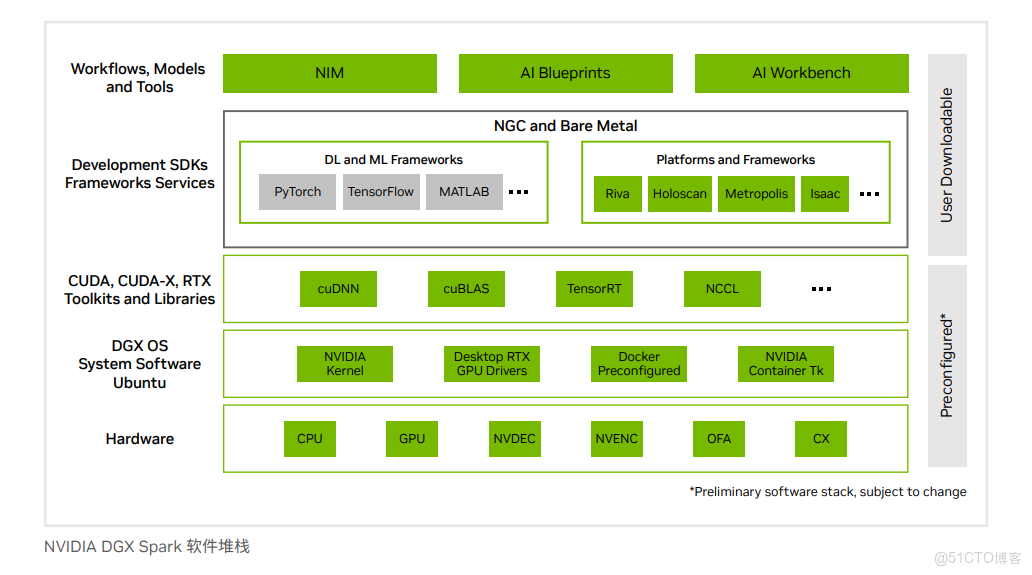
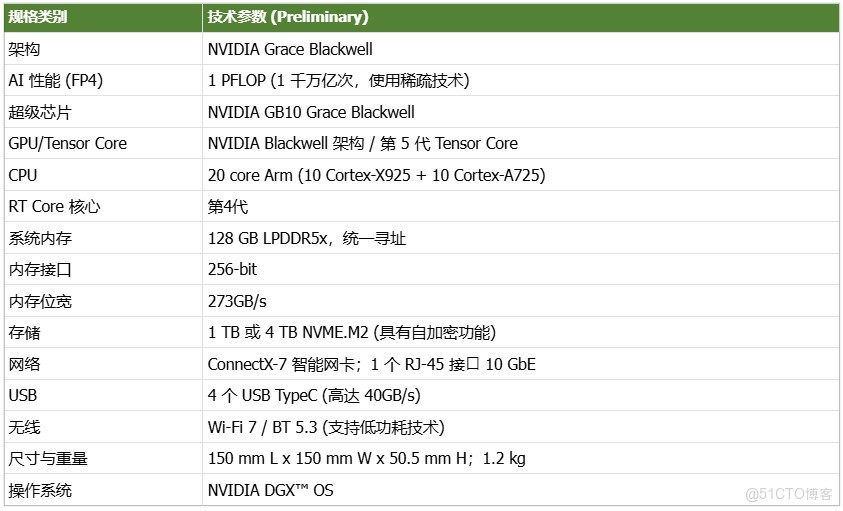
四、 詳細技術規格摘要
DGX Spark在小巧的桌面端外形中提供了出色的性能和強大的功能,旨在幫助開發者、研究人員、數據科學家和學生突破生成式AI的邊界。


五、大模型測試
1. 主流模型測試
本次測試目標明確:驗證DGX Spark能否加載並運行對單卡而言“不可能”的模型。測試結果完美印證了其核心定位,Qwen、DeepSeek等主流大模型均能在DGX Spark上成功加載並穩定運行,充分展現了其強大的模型承載能力。

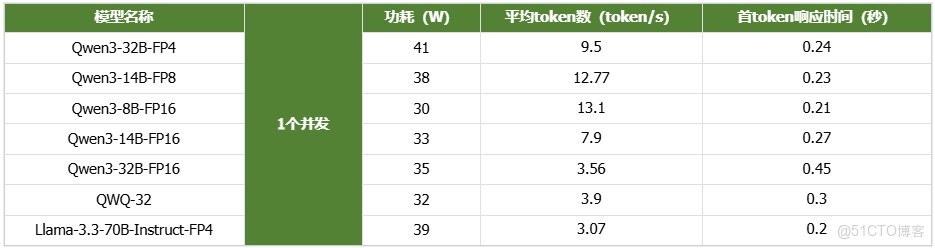
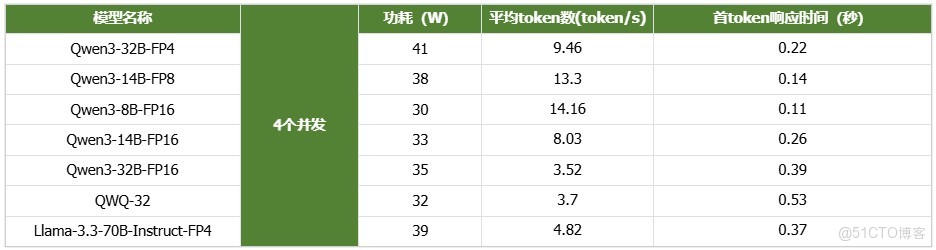
2. 併發測試
- 1個併發
- 2個併發

- 3個併發

- 4個併發
- 5個併發

3. 測試頁面
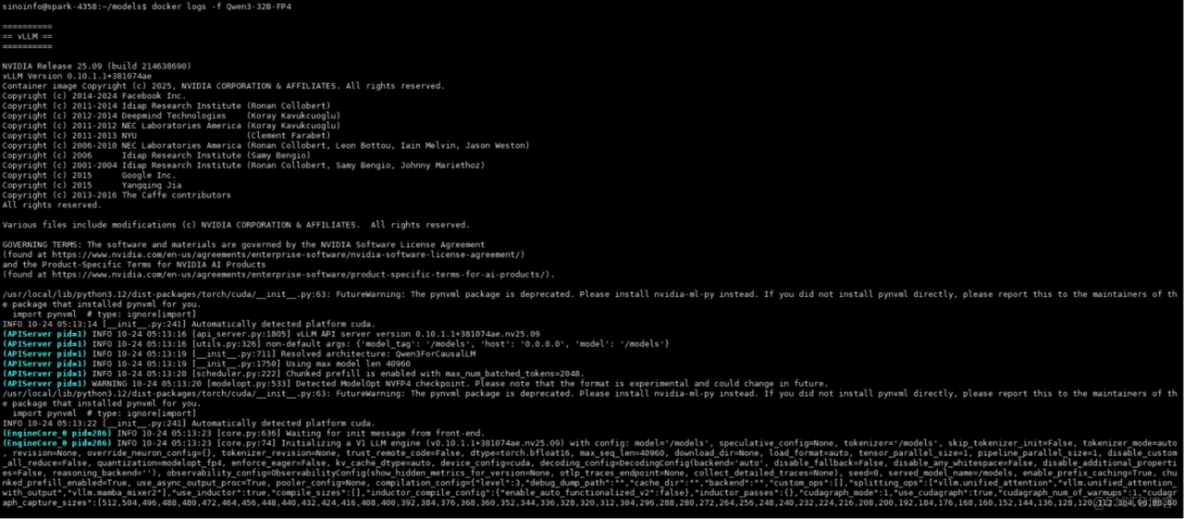
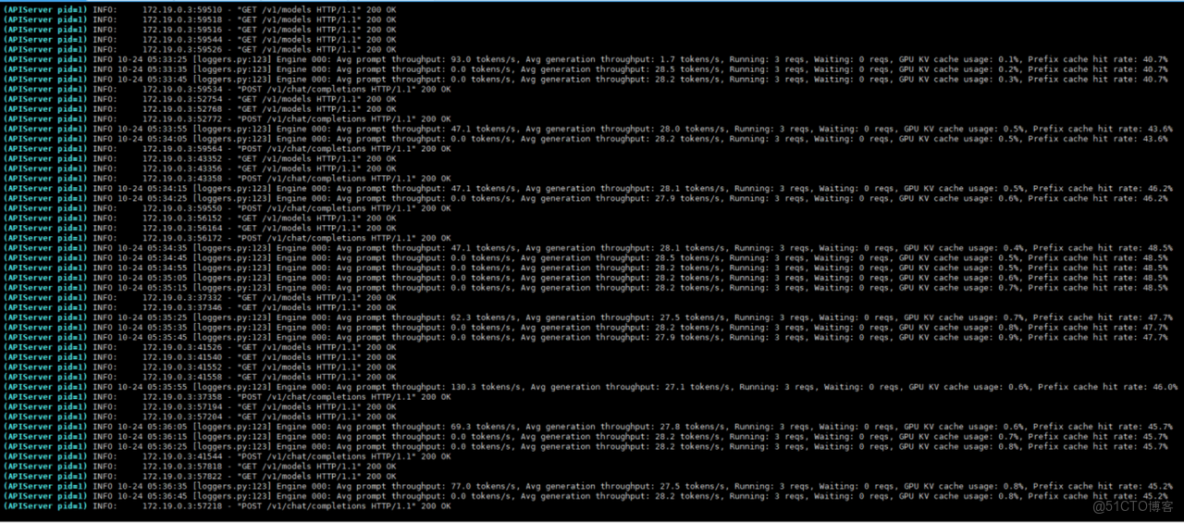
六、大模型微調
1. 微調模型

2. 測試頁面
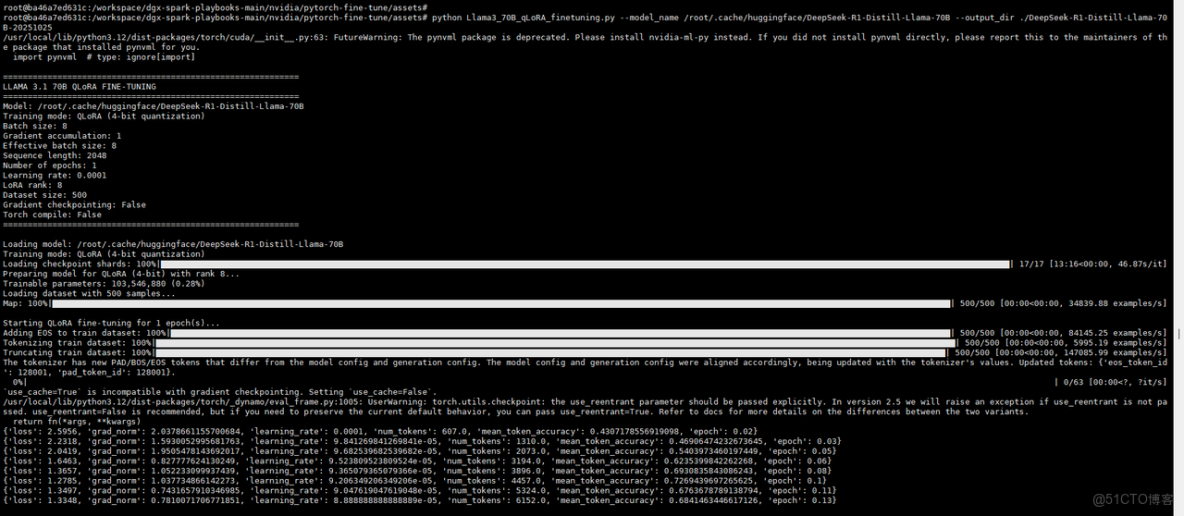
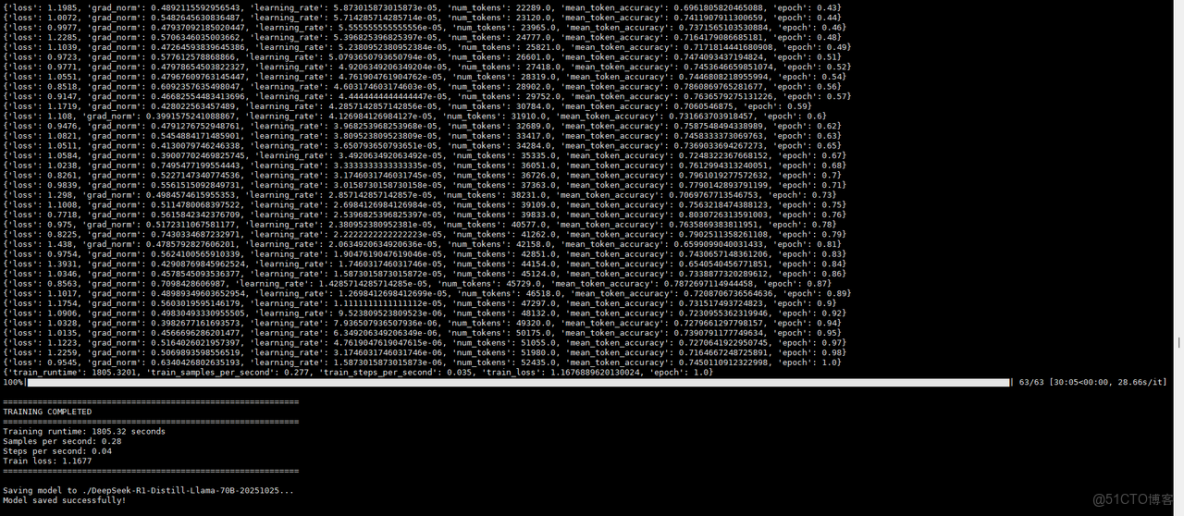
七、MOE模型推理
1. 模型推理
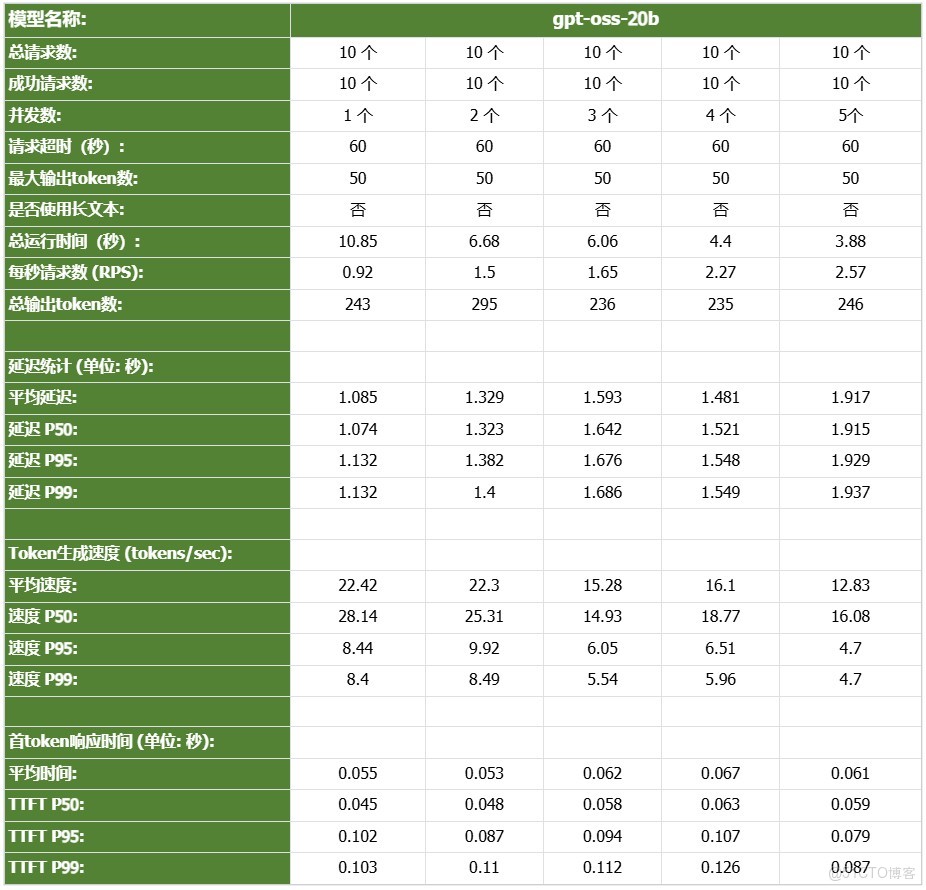
- gpt-oss-20b
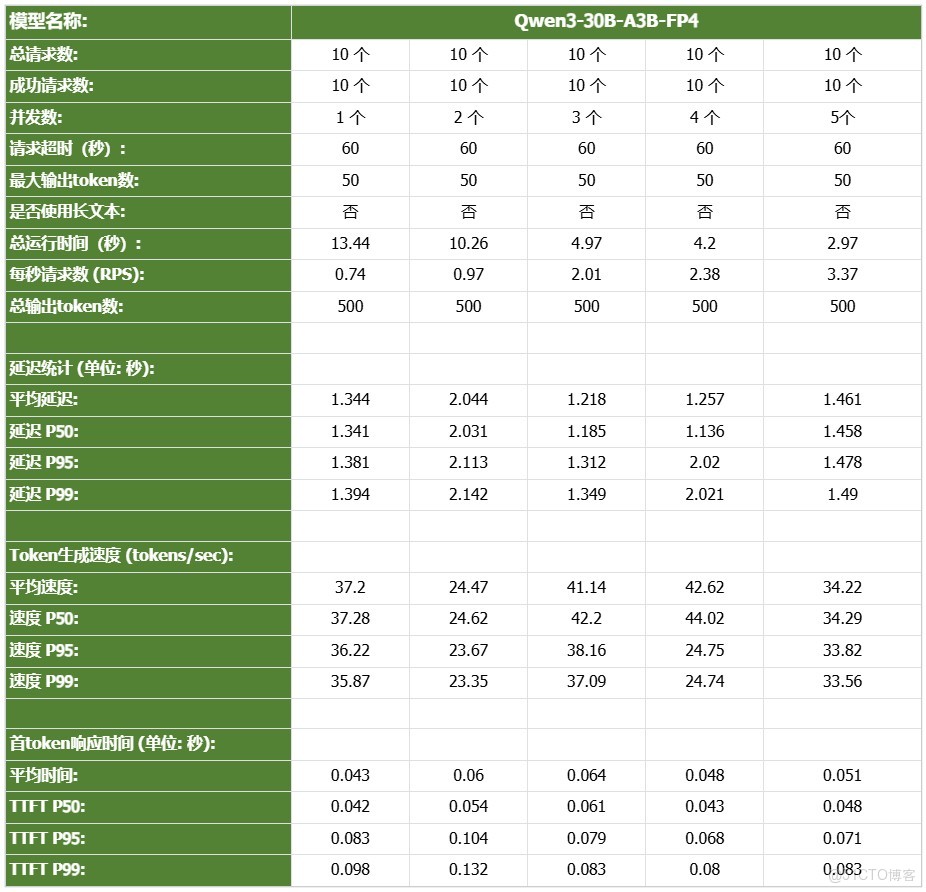
- Qwen3-30B-A3B-FP4
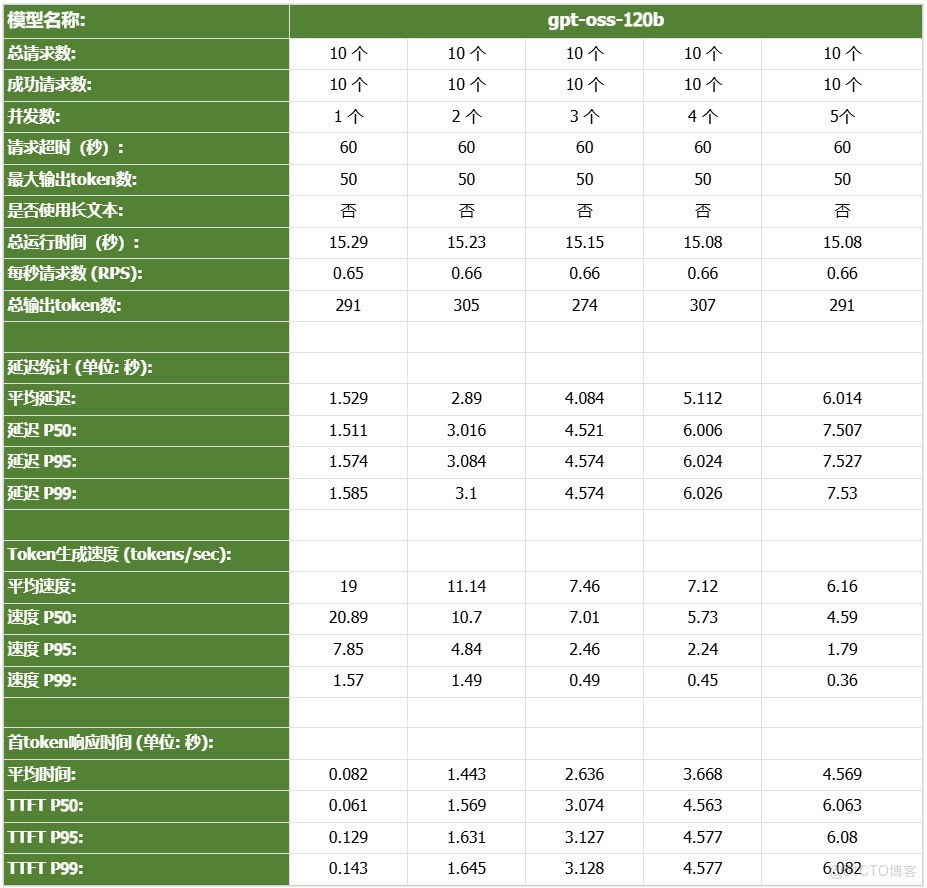
- gpt-oss-120b
2. 測試頁面
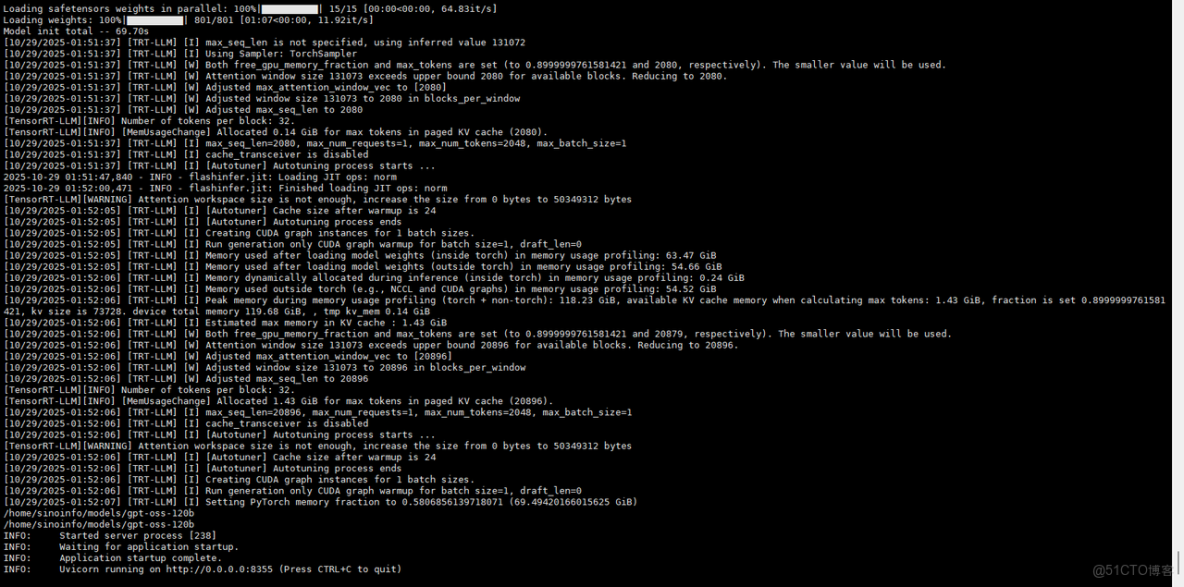
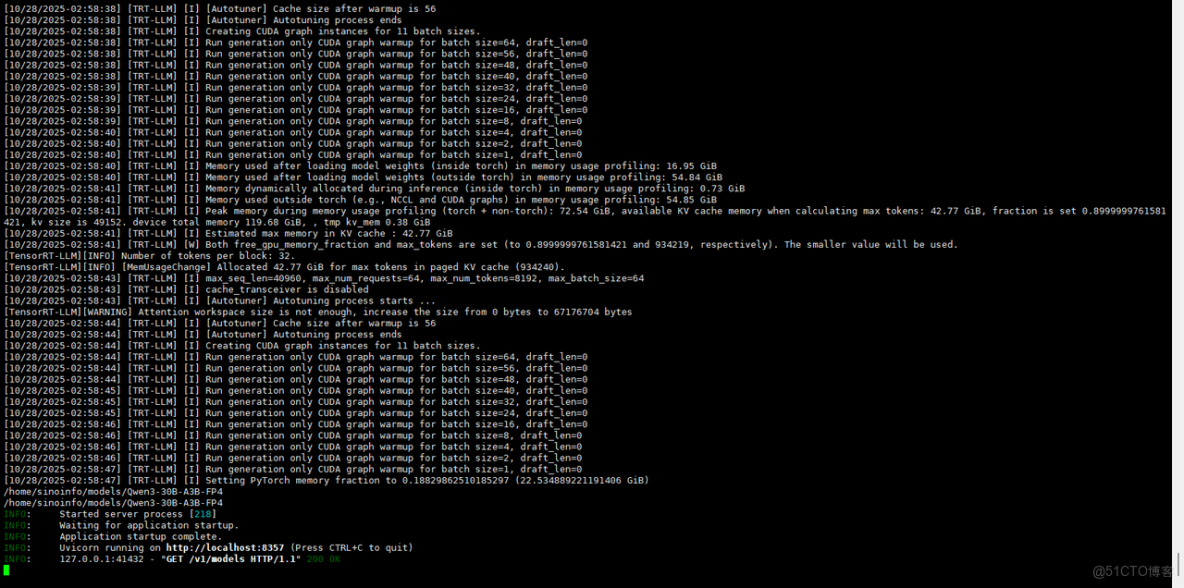
八、測試結論
DGX Spark憑藉其128GB統一共享內存,成功將Qwen3-32B-FP16等模型完整載入。這意味着,開發者終於可以在本地環境中,對那些過去只能在雲端運行的大型模型進行功能驗證、邏輯測試和效果評估。它解決了從0到1的問題,讓模型能跑起來這是後續一切優化的前提。
在我們的實際體驗中,從接通電源到成功運行第一個模型,整個過程流暢得令人驚訝。系統內置了經過優化的AI軟件棧,你無需再為環境配置而分心。這種“開箱即用”的體驗,帶來的不僅僅是時間的節省,更是寶貴創作心流的保持。它讓你從“運維工程師”的角色中解放出來,100%專注於你真正熱愛的事情——編寫代碼、調試模型、探索AI的邊界。同時,其極致的靜音設計和本地化部署,確保了它是一個不打擾、絕對私密的工作夥伴。
九、重塑您的 AI 工作流
NVIDIA DGX Spark 不僅僅是硬件的升級,更是開發範式的革新。它將數據中心的強大能力濃縮於 1.2 公斤的精緻機身中,賦予了每一位 AI 探索者在本地掌控未來的能力。
無論您是探索最前沿算法的研究員,還是需要保障數據隱私的企業開發者,DGX Spark 都是您通往 AGI(通用人工智能)之路上最得力的夥伴。