
序言
大模型已經深入到我們的生活的方方面面,不知不覺中我們的手機電腦,電子設備、辦公需求都被大模型所顛覆,那麼擁抱AI大模型已經是不可阻擋的一個發展趨勢!微調大模型成為必須的一門技能!
擁抱AI從大模型運行環部署開始
本片文章將會三篇文章來詳細描述大模型的環境部署、模型微調、實戰微調一個意圖分類小模型、實戰記錄下用户分類意圖模型是怎麼練成的!
- 環境搭建
- 模型下載
- 微調工具下載
環境搭建
使用python的conda創建一個隔離的大模型環境
conda create --name 新的環境 python=3.11模型下載
modelscope平台下載
Modelscope(魔搭社區)是一個由中國領先的AI公司阿里巴巴達摩院推出的開源AI模型社區與平台。你可以把它理解為中國版的“Hugging Face”,但更側重於服務中文開發者和中國市場。 它的核心目標是降低AI模型的應用門檻,促進AI模型的共享、協作和商業化。
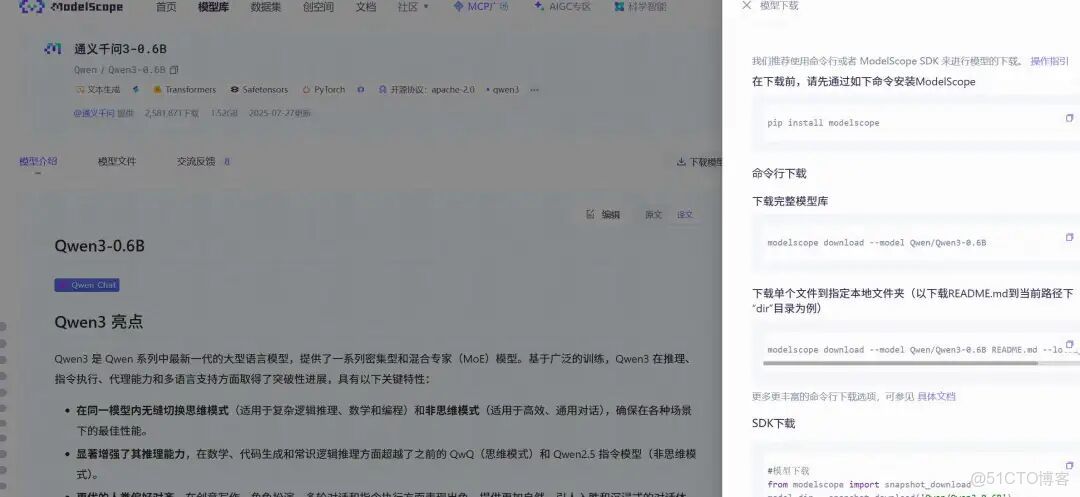
conda activate modelscop_zmmodelscope download --model Qwen/Qwen3-0.6B README.md --local_dir ./dirlocal_dir:下載的本地地址Modelscope 是一個集模型倉庫、在線體驗、開發工具、社區交流和數據集於一體的綜合性AI開源平台。它的出現,極大地推動了AI技術,特別是大模型技術在中國的普及和應用,是中文AI生態中一個非常重要的基礎設施。
如果你想快速上手某個AI模型,或者想了解中文AI領域的最新進展,Modelscope是一個非常棒的起點。
Vllm部署本地模型
vLLM 是一個專為大語言模型推理服務而設計的高效、易用的開源庫。可以把它想象成一個大語言模型的“超高性能發動機”。
它的核心目標是:以更低的成本、更快的速度,同時服務更多的用户請求。
pip insyall vllm=0.11.0CUDA_VISIBLE_DEVICES=6,7 vllm serve ~/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B --port 8008 --max-model-len 6384#CUDA_VISIBLE_DEVICES=6,7:指定顯卡號~/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B:模型的地址VLLM成功部署了本地模型


本地代碼測試模型
from openai import OpenAI# Set OpenAI's API key and API base to use vLLM's API server.openai_api_key = "EMPTY"openai_api_base = "http://27.0.0.1:8008/v1"client = OpenAI( api_key=openai_api_key, base_url=openai_api_base,)chat_response = client.chat.completions.create( model="/root/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B", messages=[ {"role": "user", "content": "你是誰"} ], max_tokens=500, temperature=0.6, top_p=0.95, extra_body={ "top_k": 20, },)print("Chat response:", chat_response)測試結果正確運行,説明部署成功

vLLM 是一個專注於 LLM 推理階段的開源庫,通過其創新的 PagedAttention 技術,實現了吞吐量和內存效率的飛躍,已經成為目前生產環境中部署 LLM 服務的首選推理引擎之一。
微調模型工具LLama-Factory安裝
LLaMA-Factory 的核心目標是:讓沒有深厚機器學習背景的開發者,也能輕鬆、高效地對大規模語言模型進行微調,從而將其適配到特定的任務或領域。
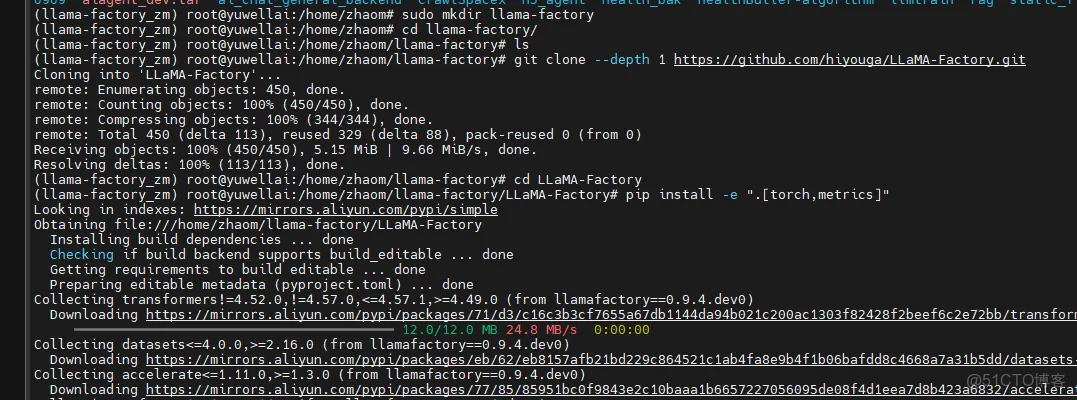
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"安裝成功
webui運行
# 在指定端口啓動webui,並允許外部訪問CUDA_VISIBLE_DEVICES=2 GRADIO_SERVER_PORT=8080 GRADIO_SERVER_NAME=0.0.0.0 llamafactory-cli webui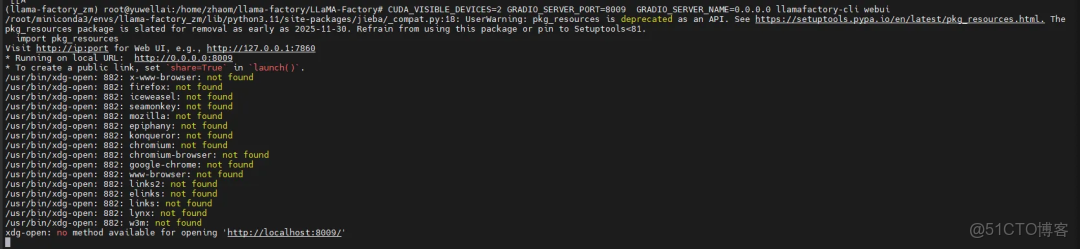
瀏覽器打開http://127.0.0.1:8009/
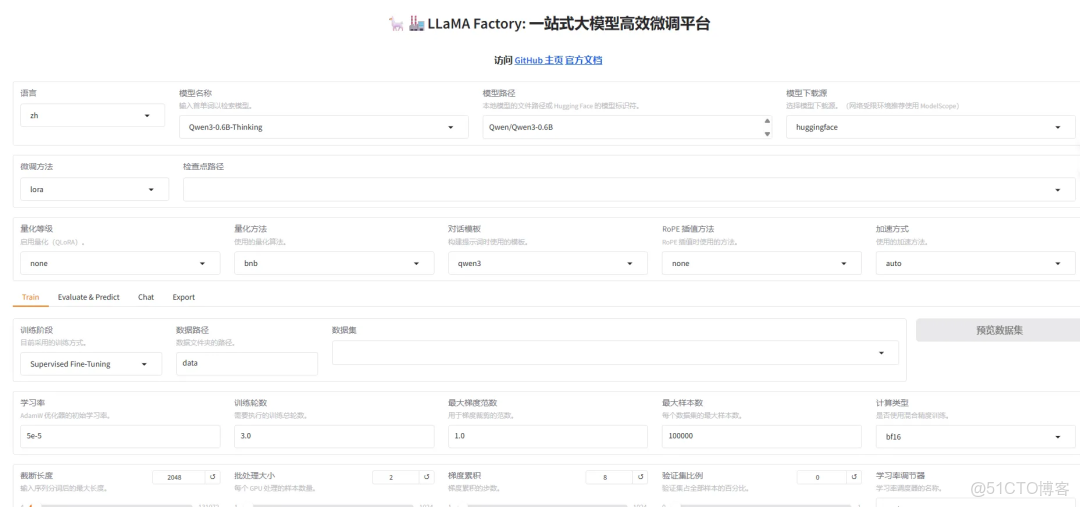
LLama-factory通過提供統一的接口、豐富的算法和可視化的界面,極大地降低了 LLM 微調的技術門檻和資源消耗。
總結
基於以上的modelscope社區、VLLM引擎、llamafactory訓練系統;我們將使用三篇文章詳細講解如何微調一個自己的用户垂直意圖分類小模型。
訓練的結論
- 原生Qwen小模型測試其意圖分類識別能力準確率只有40%左右;
- DeepSeek v3大模型通用意圖分類能力準確度可以達到80%左右;
- 經過微調後的小模型再不喪失原生能力的同時意圖分類能力準確度可以達到恐怖的98%!