
簡介
RAG知識庫構建中,文檔處理是根基,但不應機械套用固定流程。知識庫本質是為大模型服務,實現精確檢索才是核心。處理文檔需根據業務需求靈活進行:結構化數據應提取元數據;非結構化數據需合理分段,保留原始內容用於增強生成,提取核心內容用於精確檢索。同時需進行文檔清洗,過濾無效內容。最終處理方式應基於實際業務需求調整,而非照搬他人流程。
“ 文檔處理在不同的業務場景中需要選擇不同的處理方式,而不送一概而論。”
關於RAG的知識庫構建或者説文檔處理,很多會受限於各種條條框框,比如説應該這樣處理你的文檔,應該那樣建立你的知識庫;但事實上知識庫的建立沒有任何標準,唯一的標準就是怎麼讓你的系統表現的更好,這是知識庫構建的核心。
知識庫構建的核心
在學習RAG的過程中,任何人都無法避開的一個問題就是文檔處理;因為文檔處理是RAG的根基,沒有文檔處理RAG就是水中月鏡中花;但面對真實的業務場景,很多人都不知道該怎麼處理文檔。
在他們的觀念中,所謂的文檔處理就是把文檔拆分,切片向量化入庫即可;但事實上這樣的操作雖然沒有什麼錯,但在很大業務場景中好像並沒什麼用;也就是説你感覺你好像什麼都做了,但事實上等於什麼都沒做,因為沒有什麼效果。
為什麼會出現這種情況?
原因就在於很多人沒有明白知識庫的本質是什麼,建立RAG知識庫的目的有兩個,一是對文檔和數據進行統一管理,二是在檢索方面進行優化,能夠進行更加精準和高效的檢索。
而第二個作用才是知識庫的本質作用,畢竟知識庫就是為大模型服務的,怎麼精確檢索才是RAG的核心問題。
因此,在真實的業務場景中,我們需要根據業務需求,文檔內容對文檔進行適當的處理,然後構建成合理結構的知識庫系統;只有這樣才能進行更加準確的檢索,並實現高效的管理。
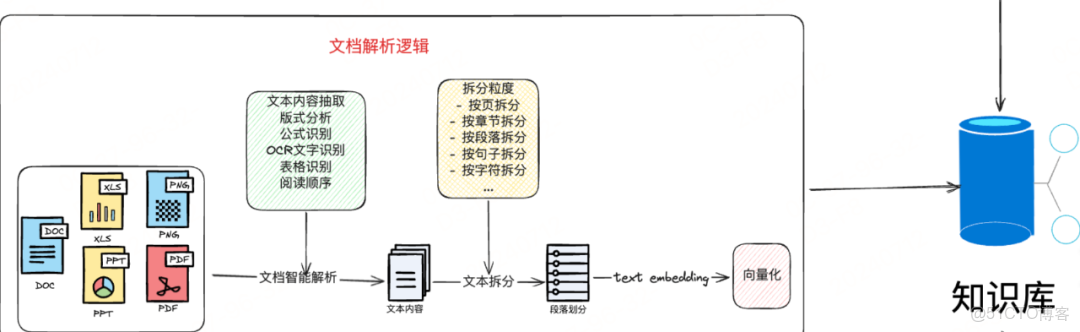
如結構化數據最好是對數據進行元數據提取,比如常用的查詢字段,不同維度的字段標識,如部門,地區等;這樣在檢索時,就可以使用這些字段進行快速且準確的檢索。
而對於非結構化數據,我們要根據段落,標題,標點符號等多種方式對文檔進行分段,並且在分段之後保留其原有內容做增強生成,而對文檔的核心內容進行提取,去除文檔中的噪音和無關數據,用來做精確檢索,只有這樣才能大大提升召回的準確率,並且不影響生成邏輯。
還有,在對文檔處理時,我們首先要對文檔進行清洗;如過濾掉頁眉,頁腳,無效字符;同時,還需要適當丟棄部分內容。
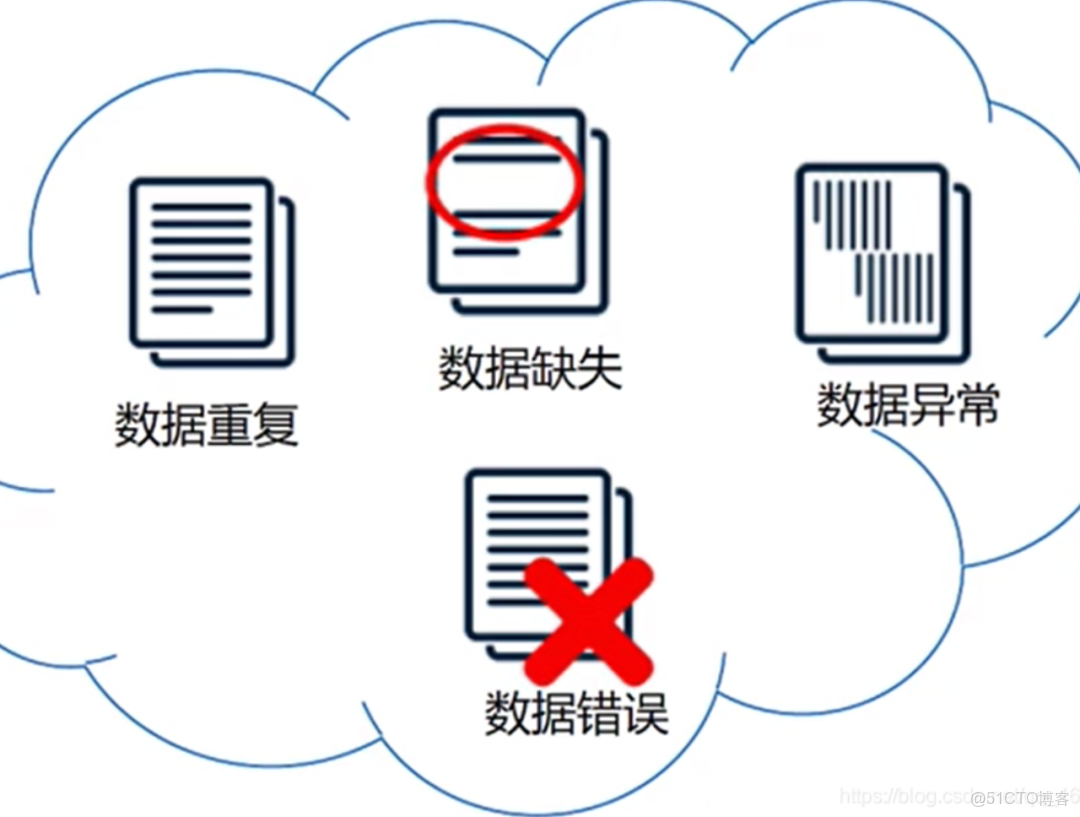
由於真實環境中文檔來源的複雜性,導致文檔質量參差不齊,因此很多文檔中的內容可能只有部分有用;而大部分都是無用數據,因此可以選擇丟棄掉這部分數據,原因在於一個好的知識庫應該知道什麼應該要,什麼不應該要,不要因為一顆老鼠屎,壞了一鍋湯。
而這就是我們平常所説的髒數據,髒數據的出現不但不會提升知識庫的質量,反而會拉低知識庫的質量。
當然,最終的處理方式還要根據你自己的業務需求進行適當的調整,而不是機械的照抄別人的處理流程,最後好像所有流程都是對的,但結果卻往往不盡人意。