
前言
無論是 BERT、GPT 還是 ViT,幾乎都不用 Batch Normalization,而是清一色地用 Layer Normalization。
這不是巧合,而是 Transformer 架構中一個非常深層的設計選擇。
一、BN 和 LN 到底在做什麼?
BN 和 LN 的出發點其實一樣——穩定訓練,防止梯度爆炸或消失。
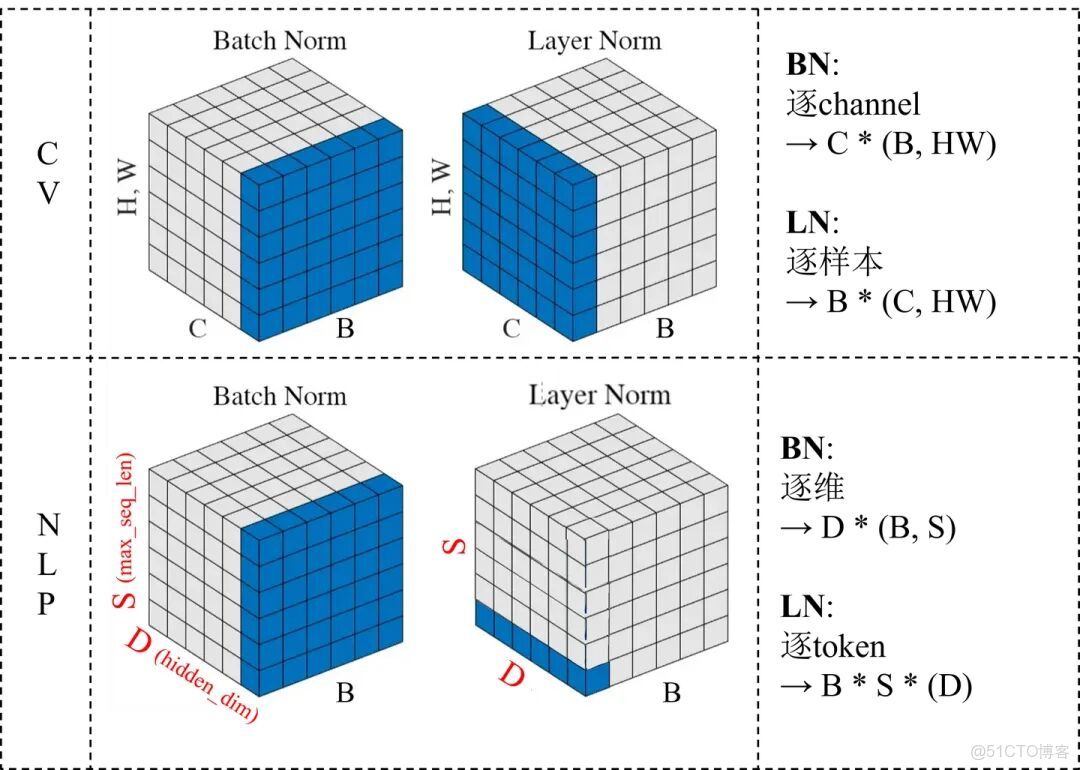
- Batch Normalization(BN)
它在一個 batch 內計算均值和方差,對同一層的所有樣本的每個通道做標準化。
換句話説,BN 關心的是這一批數據的統計特徵。
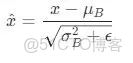
- Layer Normalization(LN)
LN 則是在同一個樣本內部計算均值和方差,對該樣本的所有特徵維度一起歸一化。
換句話説,LN 關心的是單個樣本內部的特徵分佈。
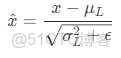
BN 是跨樣本歸一化,LN 是單樣本歸一化。
二、BN 的問題
BN 在 CNN 時代非常成功,但為什麼在 Transformer 中就變得水土不服?
根本原因有三點。
1. Transformer 是序列模型,batch 維度不穩定
BN 的計算依賴 batch 的統計量(均值和方差)。
而 Transformer 的輸入往往是變長序列,不同樣本長度不同,padding 數量不同,導致 batch 內統計特性不一致,BN 的均值和方差變得不可靠。
2. 自注意力機制破壞了空間獨立性
在卷積中,BN 對通道歸一化是合理的,因為每個通道特徵相對獨立。
但在 Transformer 的 Self-Attention 中,每個 token 都與其他 token 有強關聯。
此時再按 batch 統計均值、方差,就會讓不同樣本的分佈互相干擾,破壞注意力機制的學習穩定性。
3. 推理階段 BN 的統計特性難以複用
BN 在推理時會使用訓練階段的滑動均值來做歸一化。
但 Transformer 的輸入分佈在推理階段往往與訓練時不同(比如變長文本、不同語言或領域),這會導致分佈漂移(distribution shift),從而引入偏差。
LN 不依賴 batch,因此天然更穩定。
三、LN 的優勢
相較 BN,LN 有三個天然優勢,讓它幾乎成了 Transformer 的標配:
- 與 batch size 無關
LN 在樣本內部歸一化,batch 只要有一個樣本都能跑。 - 適合變長序列
每個 token 獨立歸一化,不受 padding、mask 等影響。 - 訓練和推理一致
LN 在訓練和推理階段用的統計量完全一致,不存在分佈漂移問題。
這些特性讓 LN 特別適合大模型——尤其是在分佈式、異步、變長輸入的環境下。
更深層次的,BN 的歸一化粒度是 batch 維度,而 Transformer 想捕捉的是 token 之間的微妙關係。
當每個樣本長度不同、token 相關性強時,BN 的跨樣本歸一化反而會削弱模型的表達能力。
LN 的歸一化發生在特徵維度內部,保證了每個 token 的特徵分佈穩定,不會被其他樣本的統計特徵干擾。
這其實是一種從樣本層面向特徵層面的思維轉變。
所以,總結一下:
Transformer 用 LN 而不用 BN,本質上是因為:
- BN 依賴 batch 統計量,不適合變長、分佈差異大的序列數據;
- Attention 機制導致樣本間特徵強耦合,BN 會破壞這種結構;
- LN 與 batch size 無關,推理階段也穩定一致。