
前言
分塊(Chunking)是構建高效RAG(檢索增強生成)系統的核心。從固定分塊、遞歸分塊到語義分塊、結構化分塊和延遲分塊,每種方法都在優化上下文理解和準確性上扮演了關鍵角色。這些技術能大幅提升檢索質量,減少“幻覺”(hallucination),並充分發揮你的RAG pipeline的潛力。

在我近一年構建可擴展AI系統的經驗中,我發現RAG系統的成功大多取決於檢索(retrieval)。你如何切分和存儲文檔——也就是分塊(chunking)——往往是成功背後的隱形推手。
引言
RAG(Retrieval-Augmented Generation)pipeline的性能很大程度上取決於你如何切分文檔(分塊)。在這篇文章中,我會帶你瞭解RAG的流程,重點講講分塊在其中的位置,然後深入探討固定分塊、遞歸分塊、語義分塊、基於結構的分塊和延遲分塊這五種技術,包括它們的定義、權衡和偽代碼,幫你選擇適合自己場景的方法。
RAG工作流程(高層次概覽)
標準流程如下:
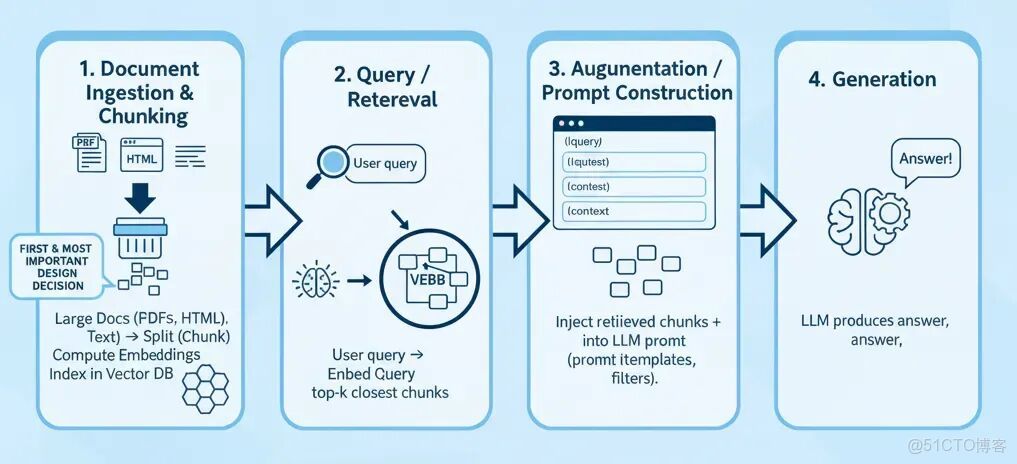
- 文檔攝取與分塊
拿來大份文檔(PDF、HTML、純文本) → 切分成小塊(chunk) → 計算embeddings → 存儲到vector DB中。 - 查詢與檢索
用户輸入查詢 → 將查詢轉為embedding → 檢索top-k最相似的塊(通過cosine similarity)。 - 增強與提示構建
將檢索到的塊(加上metadata)注入到LLM的提示中,通常會用模板和過濾器。 - 生成
LLM基於檢索到的上下文和模型先驗知識生成答案。
因為生成器(generator)只能看到你餵給它的內容,檢索質量直接決定了結果。如果分塊不合理或無關緊要,哪怕最好的LLM也救不回來。這就是為什麼很多人説RAG的成功70%靠檢索,30%靠生成。
在深入探討技術之前,先説説為什麼好的分塊不是可有可無的:
- Embedding和LLM模型有context window限制,你沒法直接處理超大文檔。
- 分塊需要語義連貫。如果你在句子或概念中間切開,embedding會變得雜亂或誤導。
- 如果分塊太大,系統可能會漏掉細粒度的相關內容。
- 反過來,如果分塊太小或重疊太多,你會存儲冗餘內容,浪費計算和存儲資源。
接下來,我們來探索五種主流的分塊技術,從最簡單到最複雜。
1. 固定分塊(Fixed Chunking)
按固定大小(按token、單詞或字符)把文本切成等大的塊,通常塊之間會有重疊。
這是RAG項目的良好起點,適合文檔結構未知或內容單一的場景(比如日誌、純文本)。
實現代碼示例:
def fixed_chunk(text, max_tokens=512, overlap=50): tokens = tokenize(text) chunks = [] i = 0 while i < len(tokens): chunk = tokens[i : i + max_tokens] chunks.append(detokenize(chunk)) i += (max_tokens - overlap) return chunks2. 遞歸分塊(Recursive Chunking)
先按高層邊界(比如段落或章節)切分。如果某個塊還是太大(超過限制),就遞歸地進一步切分(比如按句子),直到所有塊都在限制範圍內。
適合半結構化文檔(有章節、段落),你想盡量保留語義邊界,同時控制塊大小。
它能儘量保留邏輯單元(段落),避免不自然的切分,生成適合內容變化的多種塊大小。
遞歸分塊示例(LangChain):
from langchain.text_splitter import RecursiveCharacterTextSplitter# 示例文本text = """輸入文本佔位符..."""# 定義遞歸分塊器text_splitter = RecursiveCharacterTextSplitter( chunk_size=200, # 每個塊的目標大小 chunk_overlap=50, # 塊之間的重疊以保持上下文連貫 separators=["\n\n", "\n", " ", ""] # 遞歸切分的優先級)# 切分文本chunks = text_splitter.split_text(text)# 顯示結果for i, chunk in enumerate(chunks, 1): print(f"Chunk {i}:\n{chunk}\n{'-'*40}")這能確保後續embedding和檢索時,不會丟失邊界處的關鍵上下文。
3. 語義分塊(Semantic Chunking)
根據語義變化來切分文本。用embeddings(比如sentence embeddings)決定一個塊的結束和下一個塊的開始。如果相鄰段落的相似度很高,就把它們放在一起;當相似度下降時,就切分。
適合需要高檢索精度的場景(法律文本、科學文章、支持文檔),但要注意embedding和相似度計算的成本,定義相似度閾值也需要仔細調整。
實現代碼示例:
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer("all-MiniLM-L6-v2")def semantic_chunk(text, sentence_list, sim_threshold=0.7): embeddings = model.encode(sentence_list) chunks = [] current = [sentence_list[0]] for i in range(1, len(sentence_list)): sim = util.cos_sim(embeddings[i-1], embeddings[i]).item() if sim < sim_threshold: chunks.append(" ".join(current)) current = [sentence_list[i]] else: current.append(sentence_list[i]) chunks.append(" ".join(current)) return chunks4. 基於結構的分塊(Structure-based Chunking)
利用文檔的固有結構(比如標題、副標題、HTML標籤、表格、列表項)作為自然的切分邊界。
比如,每個章節或標題可以成為一個塊(或者再遞歸切分)。
適合HTML頁面、技術文檔、類似Wikipedia的內容,或任何有語義標記的內容。
根據我的經驗,這種策略效果最好,尤其是結合遞歸分塊時。
但它需要解析和理解文檔格式,如果章節太大,可能會超過token限制,可能需要結合遞歸切分。
實現提示:
- 用HTML/Markdown/PDF結構解析庫。
- 以章節/
、
等作為塊的根。
- 如果某部分太大,就回退到遞歸切分。
- 對於表格/圖片,要麼單獨作為一個塊,要麼總結其內容。
5. 延遲分塊(Late Chunking / 動態/查詢時分塊)
定義
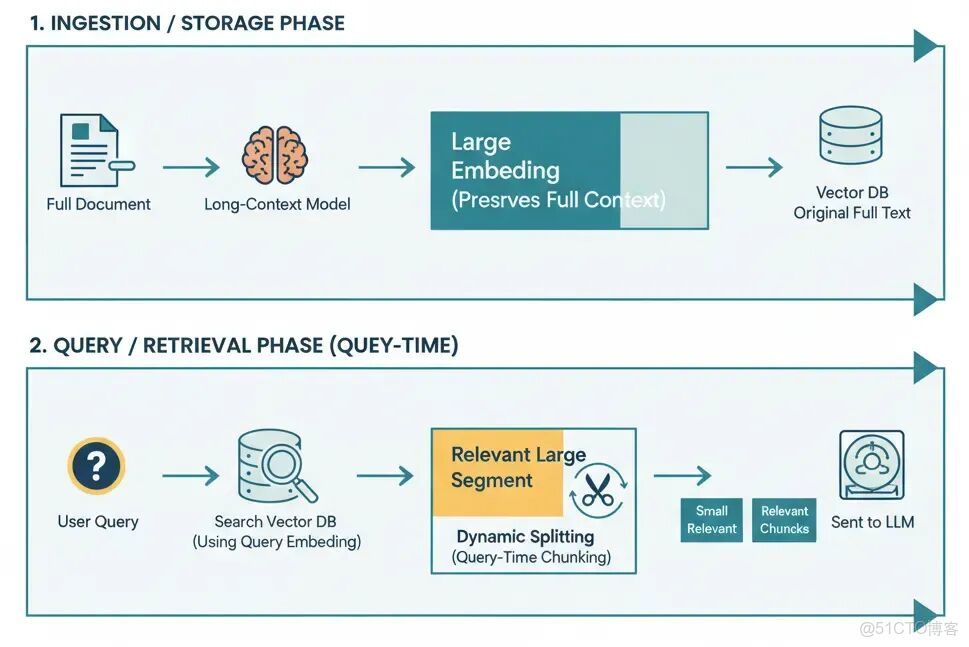
延遲分塊是指推遲文檔的切分,直到查詢時才決定。不是提前把所有內容切好,而是存儲更大的段落甚至整個文檔。收到查詢時,只對相關段落動態切分(或過濾)。這樣做的目的是在embedding時保留完整上下文,只在必要時切分。
Weaviate將延遲分塊描述為“顛倒傳統的embedding和chunking順序”。
- 先用長上下文模型對整個文檔(或大段)做embedding。
- 然後池化並創建塊的embeddings(基於token範圍或邊界線索)。
概念流程:
- 在索引中存儲大段或整個文檔。
- 查詢時,檢索1-2個最相關的段落。
- 在這些段落中,動態切分(比如語義或重疊)出匹配查詢的部分。
- 過濾或排序這些塊,餵給生成器。
這種方法就像編程中的late binding,推遲到有更多上下文時再決定。
適用場景:
- 大型文檔集(技術報告、長篇內容),跨段落的上下文很重要。
- 文檔內容經常變化的系統,避免重新切分節省時間。
- 高風險或精度敏感的RAG應用(法律、醫療、監管),誤解代詞或引用可能代價高昂。
聽起來很高級,但它也有成本。
對整個文檔(或大段)做embedding計算成本高,可能需要支持長token限制的模型。
查詢時的計算成本和潛在延遲也會更高。