
前言
在企業級 RAG系統的演進過程中,我們通常會經歷兩個階段。
第一階段是“建設期”。在這個階段,開發者的核心任務是將非結構化文檔切分、向量化,並存入向量數據庫。
當用户提出問題時,系統通過語義相似度檢索出 Top-K 個片段,餵給大模型生成答案。這套流程在處理“事實性問答”時,表現優異且成本低廉。
然而,隨着系統上線並接入真實業務,我們很快會進入第二階段——“瓶頸期”。
用户開始提出更復雜的問題,比如“分析 A 供應商的違約風險對我們下季度交付的影響”。
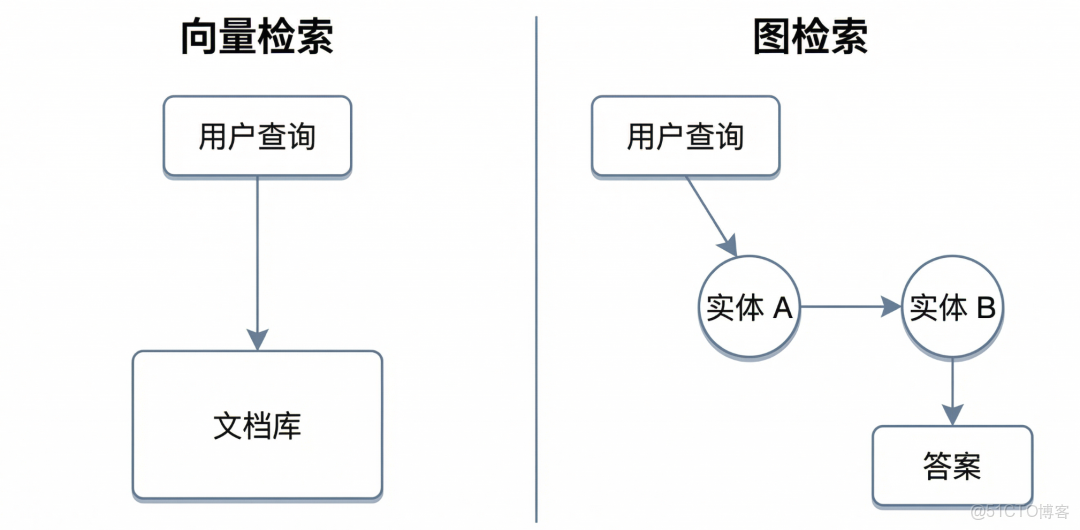
此時,單一的向量檢索開始顯露疲態:它能找到“A 供應商”的簡介,也能找到“交付計劃”的文檔,但它無法將這兩者之間的隱性邏輯鏈條串聯起來。
面對這種困境,盲目引入昂貴的知識圖譜(GraphRAG)並不是最優解。真正的架構突破點在於:我們不應該用同一種檢索策略去應對所有類型的問題。
試圖用一套檢索邏輯解決所有問題,會導致系統在“過度設計”(造成資源浪費)和“能力不足”(導致回答錯誤)之間搖擺。
我們需要構建一個智能查詢路由器(IntelligentQueryRouter),讓系統具備“審時度勢”的能力,根據用户意圖的複雜度,動態選擇最合理的檢索路徑。
01 生產環境中的真實痛點
為了理解為什麼需要路由,我們先還原兩個真實的生產場景。
場景 A:極速響應的需求
用户提問:“2023 年 Q3,華東大區的總銷售額是多少?”
系統行為:這是一個典型的低上下文依賴問題。答案明確地寫在某一份財報的表格裏。
技術現狀:現有的向量檢索(Vector Search)或者關鍵詞檢索(BM25)完全可以勝任。如果此時系統強行調用複雜的推理模塊,不僅浪費 GPU 算力,還會顯著增加響應延遲,降低用户體驗。
場景 B:深度推理的需求
用户提問:“最近股價下跌,是否受到了原材料供應商罷工事件的傳導影響?”
系統行為:這是一個高上下文依賴且涉及多跳推理的問題。
- 原始文檔中可能沒有任何一句話直接寫着“罷工導致股價下跌”。
- 系統需要先找到“原材料供應商是誰?”(實體 A)。
- 再查找“實體 A 最近發生了什麼?”(事件 B)。
- 最後分析“事件 B 與股價波動(事件 C)的時間相關性”。
技術現狀:傳統的向量檢索只能基於“股價”、“罷工”這些關鍵詞,召回一堆碎片化的新聞片段。大模型拿到這些碎片後,由於缺乏中間的邏輯連接點(即“誰供應了誰”的關係),極易產生幻覺,編造出一個看似合理的錯誤答案。
02 查詢特徵的四維分析
要實現智能路由,首先必須對用户的查詢進行量化分析。我們不能僅憑關鍵詞匹配,而需要利用 LLM 對查詢進行語義層面的深度解構。
我們在實踐中總結了四個通用的分析維度,用於評估一個查詢的“重量”:
複雜度
我們定義“複雜度”為查詢所需的認知負荷。
- 低 (0.0-0.3):事實性檢索。例如查詢具體的參數、人名、地點。
- 中 (0.4-0.7):聚合類查詢。例如要求總結某段時間內的所有事件。
- 高 (0.8-1.0):歸因與推理性查詢。涉及因果分析、趨勢判斷或假設性問題。
關係密集度
定義查詢涉及的實體數量以及實體間關聯的緊密程度。
- 判別標準:查詢是否跨越了多個獨立的知識域?是否需要追蹤實體間的交互路徑(如資金流向、股權穿透)?如果需要跨文檔關聯,該指標通常較高。
推理需求
- 多跳推理 (Multi-hop):是否需要 A -> B -> C 的傳遞性推理?
- 對比分析:是否需要同時提取兩個對象的特徵進行比對?
- 因果分析:是否在詢問事件之間的邏輯聯繫?
實體識別
統計查詢中包含的明確命名實體(NER)的數量。實體越多,意味着系統需要處理的“節點”越多,對圖譜精確匹配的需求通常越高。
示例:
- Input: “分析 A 公司股價下跌是否與 B 供應商違約有關?”
- Output*(JSON)*:
{
"query_analysis": {
"complexity": 0.9,
"relationship_intensity": 0.85,
"reasoning_required": true,
"entities": ["A公司", "B供應商", "股價下跌", "違約"],
"intent_category": "causal_analysis"
}
}03 三種核心檢索範式
基於上述分析結果,系統應動態選擇以下三種檢索策略之一。這三種策略分別對應了不同的成本與能力模型。
-
傳統混合檢索
- 機制:同時執行向量檢索(語義相似度)和關鍵詞檢索(BM25),並使用 RRF(倒數排名融合)算法合併結果。
- 適用場景:簡單查詢、事實性查詢。
- 價值:響應速度極快,計算成本最低,對顯性信息的召回率高。
-
圖 RAG 檢索
- 機制:利用知識圖譜的結構化特性。系統從查詢中的實體出發,在圖譜中向外擴展 2-3 跳(Hops),遍歷鄰居節點,提取包含相關實體及其關係的子圖結構,最後轉化為文本描述。
- 適用場景:複雜推理、多跳查詢、關係密集型查詢。
- 價值:它是解決“邏輯斷層”的關鍵。它能發現文本中未直接表述的隱性關聯,提供具有可解釋性的證據鏈。例如,它能明確告訴 LLM:“A 公司持有 B 公司 30% 的股份”,這是向量檢索很難提取出的精確結構信息。
-
組合檢索
- 機制:並行執行“傳統檢索”和“圖檢索”,並將結果進行去重和融合。
- 適用場景:中等複雜度查詢、或者意圖模糊的查詢。
- 價值:互補性強。向量檢索保證了廣度(不會漏掉非結構化的描述),圖檢索提供了深度(補充了結構化的關係)。
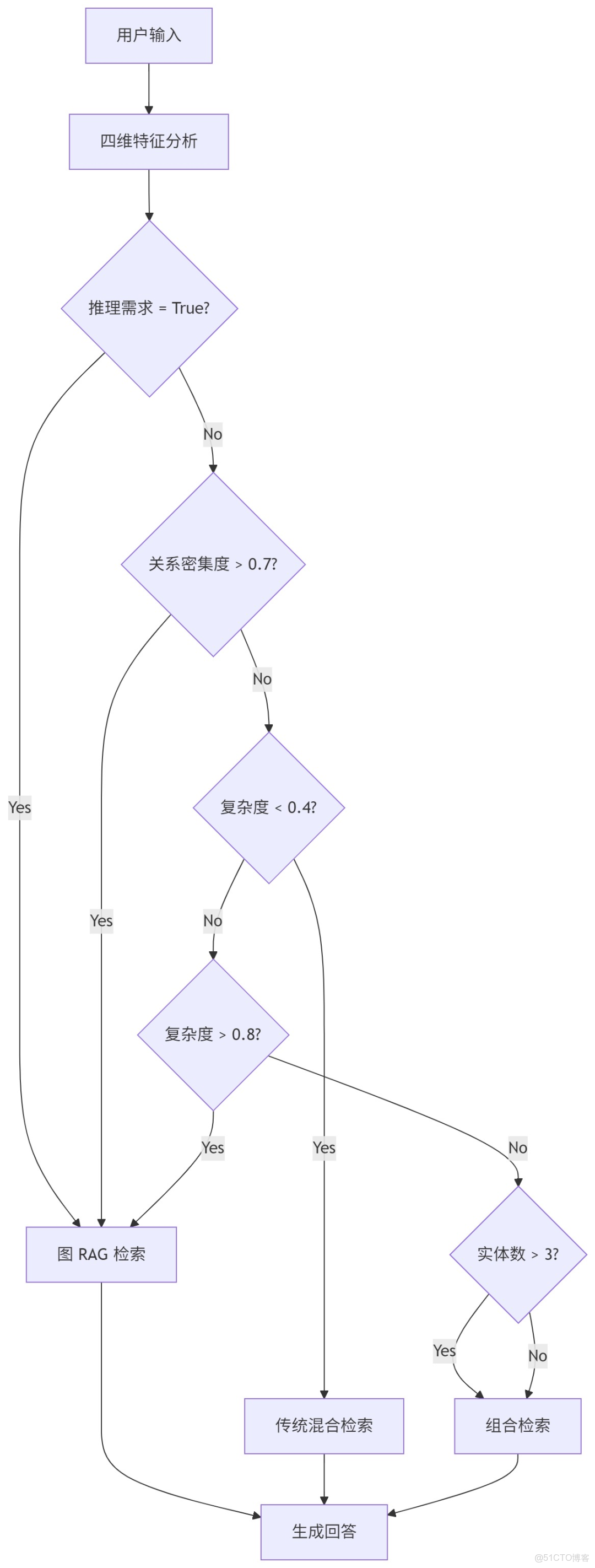
我們可以基於上述的檢索策略構建一個動態路由:
- 若系統判定為簡單事實查詢,直接走傳統混合檢索。這避免了殺雞用牛刀,節省了圖查詢的開銷。
- 若系統判定為複雜分析,走圖 RAG 檢索。在此場景下,向量檢索極易失效,必須依賴知識圖譜的結構化信息。
- 對於介於兩者之間的查詢,或者當意圖分析的置信度不高時,採用組合檢索。通過並行檢索最大化召回率,寧可多算,不可漏算。
以下是一個簡單的邏輯示例,可以根據具體的場景動態調整:
04 降級策略
在工程落地中,我們必須考慮到異常情況。高級檢索策略可能因各種原因(圖數據庫超時、圖譜覆蓋不全等)而失效。一個成熟的系統必須具備優雅降級的能力。
- 檢索降級鏈: 這是一個自動化的“替補機制”。
- 系統優先嚐試 圖 RAG 檢索。
- 如果圖檢索返回結果為空(説明圖譜中沒有覆蓋該知識點),系統不應報錯,而應自動無縫切換為 組合檢索 或 傳統混合檢索。
- 如果傳統檢索也失敗,系統應返回預設的兜底回覆,並記錄錯誤日誌,而不是拋出異常導致服務中斷。
結語
圖 RAG 並非要取代向量 RAG,而是其能力的升維補充。構建高效 RAG 系統的關鍵,不在於盲目堆砌圖數據庫,而在於構建一個能夠“審時度勢”的大腦。
通過“簡單問題向量查,複雜問題圖譜查,模糊問題混合查”的自適應策略,我們可以在系統性能、成本和回答質量之間找到最優的平衡點。這種架構設計,才是企業級 RAG 系統的核心競爭力所在。