
前言
微調大語言模型是利用特定任務或領域的定製數據集,對預訓練模型進行調整;而檢索增強生成(RAG)則將檢索系統與生成模型相結合,動態地將外部的、最新的知識融入生成結果中。
隨着生成式人工智能(Gen AI)和自然語言處理(NLP)技術的持續演進,業界對更強大、更高效模型的需求呈指數級增長。從聊天機器人、虛擬助手,到複雜的內容生成與搜索系統,NLP 應用正日益成為現代技術不可或缺的組成部分。然而,伴隨着這一不斷增長的需求,也帶來了如何提升這些系統性能與適應能力的挑戰,尤其是在複雜且動態變化的環境中。
目前,提升 NLP 模型性能的兩種主流方法是檢索增強生成(Retrieval-Augmented Generation, RAG)和微調(fine-tuning)。微調長期以來一直是機器學習領域的常用手段,通過使用額外數據進行訓練,使模型能夠適應特定任務;而 RAG 則引入了一種創新範式——將檢索系統的優勢與生成模型相結合,構建出一種動態機制,以應對那些需要大規模信息訪問和上下文敏感性的任務。
AI 工程師在項目中常常面臨一個艱難抉擇:究竟應選擇 RAG 還是微調?每種方法都有其獨特的優勢與權衡取捨,因此必須深入理解它們各自的強項、侷限性以及最適合的應用場景。本文旨在全面解析這兩種技術,幫助讀者掌握所需知識,從而做出明智決策,並在其工作中高效地運用這些強大工具。
自然語言處理技術背景
自然語言處理(NLP)的發展歷程由一系列創新推動,旨在讓機器能夠精準且細膩地理解和生成人類語言。早期的方法,如基於規則的系統和統計模型,依賴人工設計的特徵和領域特定的規則。然而,這些方法在可擴展性和泛化能力方面常常面臨困難。
深度學習的興起成為 NLP 發展的關鍵轉折點,引入了能夠從大規模數據集中捕捉複雜模式的神經網絡架構。word2vec 和 GloVe 等模型率先提出了詞嵌入方法,將詞語表示為稠密向量空間中的點,從而提升了對上下文的理解能力。隨後,基於 Transformer 架構的大語言模型(Large Language Models, LLMs)——如谷歌提出的 BERT(Bidirectional Encoder Representations from Transformers)和 OpenAI 開發的 GPT(Generative Pre-trained Transformer)——通過自注意力機制實現了對文本上下文的深度理解,徹底革新了整個領域。
儘管取得了這些進展,挑戰依然存在。在大規模語料庫上訓練的模型雖然在通用任務上表現優異,但在特定領域應用或面對不斷變化的數據時往往缺乏適應性。這一差距催生了微調(fine-tuning)等技術的發展:即利用額外的任務特定數據對預訓練模型進行進一步優化。微調被證明非常有效,但通常需要大量的計算資源和時間投入。
近年來,檢索增強生成(Retrieval-Augmented Generation, RAG)作為一種互補性方法應運而生。RAG 將檢索系統與生成模型相結合,無需進行大規模重新訓練,即可讓模型在推理過程中動態訪問外部知識庫。這一創新為那些需要實時獲取最新信息或領域專業知識的任務提供了傳統微調之外的一種極具吸引力的替代方案。
解碼基礎:深入解析 RAG 與微調
檢索增強生成(RAG)詳解
RAG 是 NLP 領域的一項創新方法,它將信息檢索能力與語言生成能力有機結合。其核心思想是在生成過程中,使大語言模型能夠動態訪問並利用外部知識,從而顯著增強其表達與推理能力。
RAG 架構主要由兩個關鍵組件構成:檢索器(retriever)和生成器(generator)。檢索器負責從龐大的文檔集合或知識庫中搜索並提取與當前任務相關的信息。該組件通常採用先進的信息檢索技術,例如稠密向量表示(dense vector representations)和高效的相似性搜索算法,以針對給定查詢或上下文精準定位最相關的知識片段。
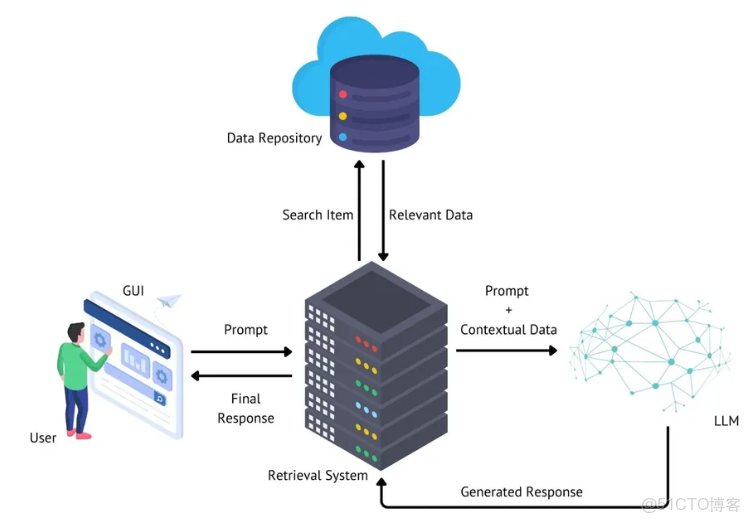
另一方面,生成器(generator)是一種語言模型,它結合檢索到的信息與原始輸入,生成連貫、語境恰當且準確的響應。該組件利用預訓練語言模型(如 GPT 或 BART)的強大能力,在生成類人文本的同時,融入檢索器提供的外部知識。
RAG 通過將生成過程以檢索到的信息為條件,將外部知識整合進語言模型中。這種方法使模型能夠訪問其初始訓練數據中可能不存在的最新或任務特定信息。因此,經過 RAG 增強的模型能夠在各種任務和領域中提供更準確、更及時、信息更豐富且上下文更相關的回答。
一個典型的 RAG 系統包含以下關鍵組件:
- 知識庫(Knowledge Base)
:可以是一個大規模文檔語料庫、包含外部信息的結構化數據,甚至整個互聯網。 - 檢索器(Retriever)
:負責從知識庫中搜索並提取相關信息的模塊。 - 編碼器(Encoder)
:將輸入查詢和文檔轉換為稠密向量表示的組件。 - 相似性搜索(Similarity Search)
:一種基於向量相似度識別最相關文檔的算法。 - 生成器(Generator)
:利用檢索到的信息和輸入上下文生成最終輸出的語言模型。 - 融合機制(Fusion Mechanism)
:一種將檢索信息與輸入相結合以引導生成過程的方法。
微調詳解
微調(Fine-tuning)是 NLP 中一種強大的技術,指對預訓練語言模型進行進一步訓練,使其適應特定任務或專門領域。該過程充分利用大型通用模型已有的知識和能力,並對其進行定製化調整,從而在目標應用場景中實現更優性能。
本質上,微調建立在遷移學習(transfer learning)的概念之上——即模型可將在一個任務中學到的知識遷移到另一個相關任務中。在語言模型的語境下,這意味着模型在預訓練階段獲得的通用語言理解與生成能力,可以被進一步細化和專業化,以滿足具體用例的需求。這種方法顯著減少了對任務特定訓練數據的需求,並加速了面向各類應用的高性能模型的開發進程。
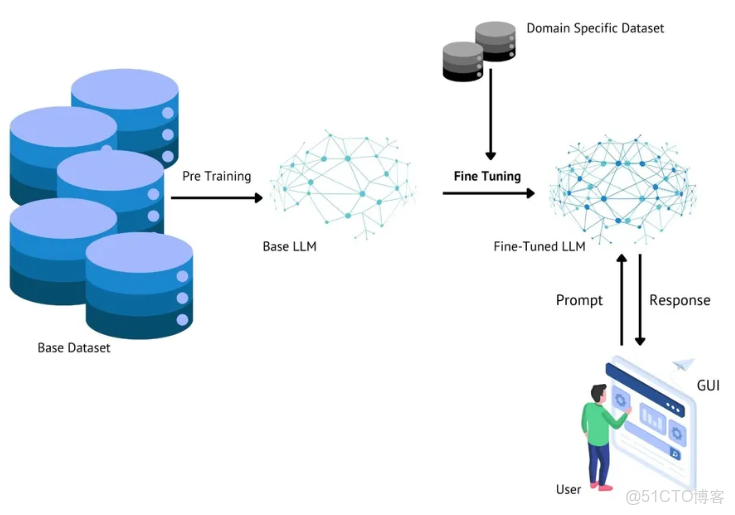
微調過程包括將預訓練模型暴露於一個精心構建的、能夠代表目標任務或領域的數據集。在此階段,模型的參數會被調整,以優化其在新任務上的表現,同時保留預訓練階段獲得的基礎語言知識。這種精妙的平衡使模型既能利用其對語言的廣泛理解,又能發展出針對特定應用場景的專業能力。
微調模型的主要步驟包括:
- 選擇一個合適的預訓練模型作為起點
- 準備高質量、面向具體任務的微調數據集
- 定義任務特定的模型架構(例如,添加分類層)
- 配置微調過程中的超參數
- 在新數據集上訓練模型,並更新模型參數
- 在獨立的測試集上評估微調後模型的性能
- 根據需要迭代優化整個流程,直至達到預期效果
微調使開發者能夠在無需大量計算資源或海量數據的前提下,為各種應用場景(如情感分析、命名實體識別和問答系統等)構建專用模型。這一方法大大降低了使用前沿語言模型的門檻,加速了人工智能解決方案在各行各業的落地與普及。
RAG 與微調正面交鋒:性能指標對比
準確性與精確度
在評估 RAG 與微調方法的性能時,準確性和精確度是關鍵指標,其表現會因具體任務而異。RAG 在需要最新或專業知識的場景中表現卓越,而微調則在任務模式清晰、數據分佈穩定的情況下更具優勢。
影響兩種方法準確性的因素各不相同。對於 RAG 而言,外部知識庫的質量與相關性至關重要;檢索機制的有效性,以及將檢索信息與生成過程融合的能力,也顯著影響最終準確性。此外,知識庫的多樣性與覆蓋廣度決定了 RAG 在不同領域中的表現。
對於微調而言,任務特定訓練數據的質量與數量極為關鍵。預訓練領域與目標任務領域之間的相似度也會影響準確性。此外,學習率、訓練輪數等超參數的選擇,也會顯著影響微調後模型的性能。
在需要訪問大量且最新信息的場景中,RAG 通常優於微調。例如,在開放域問答任務中,RAG 可藉助其龐大的知識庫提供更準確的答案,尤其對於涉及近期事件或原始訓練數據未涵蓋的專業主題的問題。
相反,在任務結構清晰、數據分佈穩定的場景下(如命名實體識別或情感分析),微調模型往往表現更佳。這類任務在不同文本中保持相對一致的模式,微調模型可通過專門學習任務特有的模式和細微差別,實現更高的準確率。
事實核查是 RAG 展現更高準確性的另一領域。通過從知識庫中的多個來源檢索並交叉驗證信息,RAG 能提供比微調模型更可靠的事實驗證——後者僅受限於訓練期間編碼到模型參數中的信息。
然而,在需要深入理解特定領域術語或高度專業化語言模式的任務中,微調可能勝過 RAG。例如,在法律文書分析或醫療報告生成等場景中,若外部知識庫未能全面覆蓋該專業領域,那麼基於領域數據微調的模型往往會比 RAG 系統取得更高的準確性。
適應性與泛化能力
適應性與泛化能力是人工智能模型的關鍵特性,決定了模型在面對新數據和新任務時的表現能力。檢索增強生成(RAG)模型與微調模型在這兩個方面展現出不同的特點,各自具有獨特的優勢與侷限。
RAG 模型在適應新信息和新場景方面表現更優。通過利用外部知識庫,RAG 無需重新訓練即可整合最新信息,使其在信息快速變化的動態環境中始終保持時效性和相關性。
相比之下,微調模型雖然在特定任務上高度專業化,但在適應性方面往往存在困難。它們容易出現“災難性遺忘”現象——即模型在適應新任務或新數據時,會丟失先前學到的知識。這是因為微調過程會調整模型參數以優化新任務的性能,可能會覆蓋掉對先前任務有用的知識。
RAG 通過維護一個獨立且可更新的知識庫來避免災難性遺忘問題。它不修改模型內部參數,而是從外部來源檢索相關信息,從而在適應新數據的同時,不會損害其在已學任務上的表現。
泛化能力在以下任務中尤為重要:
- 開放域問答
:RAG 能夠訪問廣泛的知識庫,即使面對訓練中未見過的主題,也能回答多樣化的問題。 - 零樣本學習
:RAG 可藉助知識庫中的相關信息,在未經顯式訓練的任務上取得合理表現。 - 跨語言任務
:微調模型在遇到訓練數據中未包含的語言或方言時可能表現不佳,而 RAG 則有可能檢索並利用多語言信息。 - 時序推理
:RAG 能整合最新信息,因此更適合處理涉及當前事件或不斷演進知識的任務。
RAG 與微調在適應性方面的關鍵差異包括:
- 知識整合方式
:RAG 動態整合新信息,而微調模型需重新訓練。 - 災難性遺忘
:RAG 基本避免了該問題,微調模型則容易受其影響。 - 任務靈活性
:RAG 無需重新訓練即可適應更廣泛的任務,而微調模型更具任務專一性。 - 持續學習能力
:RAG 通過更新知識庫支持持續學習;微調模型訓練完成後知識通常是固定的。 - 對未見數據的泛化能力
:得益於廣泛的一般知識訪問,RAG 在全新場景中通常表現更佳。
資源需求與計算開銷
RAG 與微調模型的計算需求存在顯著差異,這直接影響它們在實際應用中的部署與可擴展性。由於 RAG 需要在推理時實時維護並查詢大型外部知識庫,通常需要更多的計算資源。
在 GPU/TPU 使用方面,微調在訓練階段通常需要大量計算資源,但推理階段效率更高。RAG 模型在初始設置階段計算負擔較輕,但在推理過程中需要持續的 GPU/TPU 算力,以支持實時信息檢索與整合。
內存需求也大不相同。微調模型將所有信息存儲於模型參數中,導致模型體積較大,但推理速度可能更快。RAG 模型的核心部分較小,但需要額外內存來存儲和訪問外部知識庫。
兩種方法在可擴展性方面各有挑戰。微調模型在特定任務上擴展性良好,但若需覆蓋不同領域,往往需要重新訓練或使用多個獨立模型。RAG 系統因其模塊化結構,在多樣化任務中具備更好的可擴展性——只需更新知識庫,無需改動核心模型。
|
模型規模
|
任務
|
RAG 計算開銷
|
微調計算開銷
|
|
小
|
問答
|
中
|
低
|
|
中
|
命名實體識別
|
高
|
中
|
|
大
|
摘要生成
|
極高
|
高
|
優化 RAG 系統資源使用的建議:
- 實現高效的索引與檢索算法。
- 對高頻訪問信息使用緩存機制。
- 對大規模知識庫採用分佈式計算。
優化微調的建議:
- 使用參數高效微調技術(如適配器層)。
- 應用量化與剪枝以減小模型體積。
- 利用遷移學習減少新任務的訓練時間。
兩種方法均可受益於硬件加速和優化的推理引擎。選擇 RAG 還是微調,通常需在計算開銷、任務靈活性和性能需求之間進行權衡,具體取決於應用場景。
推理速度與延遲
RAG 模型雖靈活且能訪問動態實時信息,但本質上推理速度較慢。其高延遲主要源於檢索過程:在生成響應前,RAG 必須搜索知識庫、檢索相關信息,並將其與用户查詢整合。儘管這一額外步驟增強了模型獲取最新信息的能力,但也帶來了顯著的時間開銷。
在推理階段的計算需求方面,兩者也有明顯區別。微調模型已將任務特定知識內化到參數中,推理時通常計算負擔較輕,僅依賴輸入和預訓練/微調後的權重。而 RAG 模型需維護並查詢大型外部知識庫,計算密集度高,可能需要額外硬件資源。
部署時選擇 RAG 還是微調,取決於應用的具體需求。對於實時聊天機器人或自動交易系統等對延遲敏感的任務,微調模型的低延遲更具優勢。而對於新聞摘要或動態事實核查等對信息時效性要求高的應用,RAG 的額外延遲可能是可接受的,因其能獲取並整合最新信息。
實施策略:讓 RAG 與微調落地
RAG 實施藍圖
構建 RAG 系統包含若干關鍵步驟,每一步都對模型的有效性和效率至關重要。首先進行數據準備,收集並預處理高質量、多樣化的語料庫,作為 RAG 系統運行時查詢的知識基礎。
其次,訓練檢索器組件。RAG 中的檢索器通常使用嵌入模型(如 BERT 或 DPR,即 Dense Passage Retriever)將查詢和文檔編碼為稠密向量表示,以便進行相似性搜索。
接下來是檢索器與生成器的集成,這是關鍵環節。需設計一條高效流水線,能根據輸入查詢快速檢索相關信息,並無縫融入生成過程。生成器通常是一個預訓練語言模型(如 GPT),需進一步微調以有效利用檢索到的信息。
常用 RAG 框架與工具包括:
- Haystack
:端到端 RAG 框架,提供文檔存儲、檢索器和閲讀器組件。 - LangChain
:簡化大語言模型與外部數據源及其他計算模塊結合的庫。 - Hugging Face Transformers
:提供用於檢索和生成任務的預訓練模型與工具。
以下是一個簡化的 RAG 系統偽代碼:
def rag_system(query, knowledge_base): # 檢索相關文檔 relevant_docs = retriever.get_relevant_documents(query, knowledge_base) # 拼接檢索到的文檔作為上下文 context = " ".join(relevant_docs) # 結合查詢與上下文生成響應 response = generator.generate(query + context) return response# 使用示例query = "法國的首都是哪裏?"response = rag_system(query, knowledge_base)print(response)RAG 實施最佳實踐:
- 確保知識庫內容多樣且高質量,覆蓋廣泛主題。
- 定期更新知識庫以保持準確性和時效性。
- 實現高效的索引與檢索機制,降低延遲。
- 在任務特定數據上微調生成器,提升輸出連貫性與相關性。
- 建立穩健的評估流程,衡量檢索信息與生成響應的質量。
- 考慮在初步檢索後加入重排序步驟,提升相關性。
- 嘗試不同檢索與生成模型組合,找到最適合具體用例的配置。
微調實施藍圖
對預訓練語言模型進行微調需採用系統化方法,確保模型有效適應目標任務或領域。首先進行數據準備:收集、清洗並按需標註高質量的領域特定數據集,作為模型專項訓練的基礎。
隨後進入模型選擇階段,挑選合適的預訓練模型(如 BERT、GPT 或 T5),並根據任務需求(如分類、摘要或問答)對模型架構進行微調,例如添加任務特定層。
準備好數據與模型後,開始微調過程:使用合適的超參數、損失函數和優化器在任務特定數據集上訓練模型,並通過驗證集定期評估,防止過擬合。
常用微調框架與工具包括:
- Hugging Face Transformers
:提供預訓練模型、分詞器及多種 NLP 任務的微調工具。 - PyTorch 與 TensorFlow
:主流機器學習框架,支持自定義模型的實現與微調。 - Google Colab 與 Kaggle
:提供免費 GPU 的雲端平台,適合微調小型模型。
以下是一個用於情感分析的微調偽代碼示例:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments# 加載預訓練模型與分詞器model_name = "bert-base-uncased"model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)tokenizer = AutoTokenizer.from_pretrained(model_name)# 數據預處理def preprocess_function(examples): return tokenizer(examples["text"], truncation=True, padding=True)tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)# 訓練參數設置training_args = TrainingArguments( output_dir="./results", evaluation_strategy="epoch", save_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3, weight_decay=0.01,)# 定義訓練器trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"],)# 開始訓練trainer.train()微調實施最佳實踐:
- 任務數據質量
:確保數據集乾淨、標註準確,並能代表目標領域或任務。 - 超參數調優
:嘗試不同學習率、批次大小和訓練輪數以優化性能。 - 防止過擬合
:使用 dropout、早停或正則化等技術提升泛化能力。 - 定期評估
:訓練過程中監控驗證集表現,確保有效學習。 - 利用預訓練層
:凍結基礎模型,僅微調任務特定層,提高資源效率。 - 高效資源利用
:使用 GPU/TPU 雲資源及批處理加速微調。 - 持續更新
:定期用新數據重新訓練模型,保持時效性與準確性。
遵循此藍圖,可高效實現各類 NLP 任務的微調,在保證任務性能的同時優化資源使用。
選擇合適的 AI 模型增強技術
RAG 的優勢場景
RAG 在需要訪問海量、最新信息且無需重新訓練即可適應新數據的場景中表現卓越。這使其特別適用於知識持續演進或信息範圍過於廣泛、難以完全內化到單一模型參數中的領域。
典型例子是開放域問答系統。與僅依賴參數內嵌知識的微調模型不同,RAG 能動態從知識庫中檢索並整合最新信息。這一能力對虛擬助手或客服聊天機器人至關重要,因為它們需在廣泛主題上提供準確、及時的回答。
RAG 在需要事實準確性與內容多樣性的內容生成任務中同樣出色。例如,在自動新聞摘要或報告生成中,RAG 可引入最新數據與統計信息,確保內容既新穎又準確。這種動態知識整合在金融等領域尤為寶貴,因為市場狀況與公司信息瞬息萬變。
RAG 處理頻繁更新信息的能力在許多現實應用中具有顯著優勢。例如在醫療領域,基於 RAG 的系統無需反覆重新訓練,即可同步最新研究成果、治療方案和藥物信息,確保醫護人員在關鍵決策時獲得最新、最相關的知識。
RAG 的主要應用場景包括:
- 開放域問答與聊天機器人
- 實時新聞摘要與分析
- 科學文獻綜述與研究輔助
- 金融市場分析與報告
- 教育工具與互動學習平台
- 事實核查與虛假信息檢測系統
在這些場景中,RAG 將大語言模型的泛化能力與信息檢索系統的精準性與時效性相結合,成為處理複雜、知識密集型任務的強大工具。
微調的優勢場景
微調適用於任務特定優化和低延遲性能至關重要的場景。一個典型領域是特定領域的自然語言處理任務。例如,在法律、醫療或技術文檔分析中,微調模型通過專項訓練理解專業術語、上下文和細微差別,表現優於通用模型。
任務特定性能優化是微調的另一優勢。在情感分析、垃圾郵件檢測或命名實體識別等應用中,微調模型通過聚焦特定任務數據集,實現卓越性能,不僅能準確識別,還能穩健處理領域特有細節。
微調在低延遲環境中同樣表現出色。由於不依賴外部檢索機制,微調模型比 RAG 等檢索增強系統生成響應更快,非常適合聊天機器人、語音助手和實時翻譯等對響應速度要求極高的應用。
在醫療或金融等數據隱私至關重要的環境中,微調模型還具備額外優勢:通過將任務知識直接嵌入模型,減少了對外部數據檢索的依賴,從而降低數據泄露或隱私違規風險。
微調的主要應用場景包括:
- 社交媒體或客户反饋的情感分析
- 法律與醫療文檔分析
- 個性化推薦與用户畫像
- 金融系統中的欺詐檢測與風險評估
- 低延遲客户服務聊天機器人
- 任務特定摘要與報告生成
- 領域特定翻譯與語言模型
- 技術支持與故障排查助手
在這些場景中,微調模型憑藉其任務專精能力和快速響應效率,成為不可或缺的方法。其對穩定數據集和內嵌知識的依賴,使其在可預測、任務聚焦的應用中持續高效。
混合方法:兩全其美
結合 RAG 與微調的混合方法,為同時需要最新信息檢索與任務特定優化的場景提供了強大解決方案。這類方法融合兩者優勢,構建出更靈活高效的 AI 系統。
一種有效策略是以微調模型作為 RAG 系統的基礎。這樣,模型既具備特定領域的專業知識,又能訪問並整合外部信息。例如,在醫療診斷系統中,基礎模型可微調於醫學術語和常見診療流程,而 RAG 能力則使其檢索最新研究成果或罕見病例。
另一種方法是先用 RAG 進行初步信息檢索,再對輸出生成過程進行微調。這在事實準確性與風格一致性均重要的內容創作任務中尤為有用。例如,新聞摘要系統可用 RAG 收集相關事實,再通過微調語言模型按特定新聞風格生成摘要。
混合方法的實際應用包括:
- 法律研究工具:結合微調模型理解法律語言,RAG 訪問最新判例與法規。
- 教育平台:微調用於個性化教學,RAG 檢索多樣且最新的學習資料。
- 金融分析系統:微調模型預測市場趨勢,RAG 整合實時經濟數據。
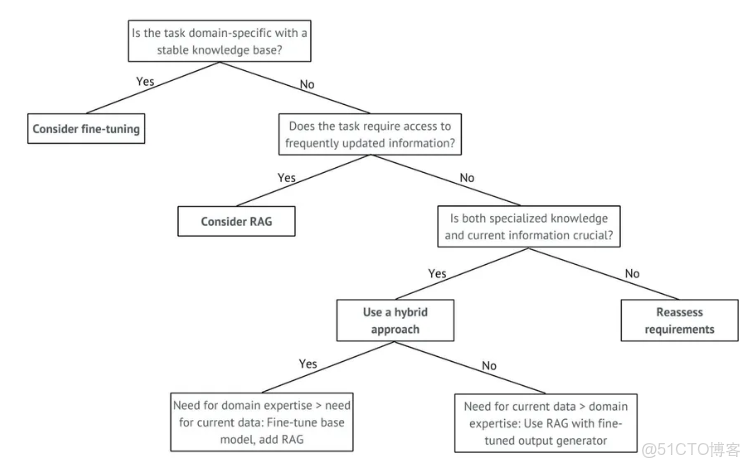
下圖決策樹可指導從業者根據具體用例選擇最合適的方法,在專業深度與信息時效性之間取得平衡。
結論
RAG 與微調代表了提升 AI 模型性能的兩種不同路徑,各有優勢與侷限。RAG 擅長需要訪問大規模、頻繁更新知識庫的場景,具備無需重新訓練即可適應新信息的靈活性。而微調則在任務專精應用中表現突出,提供更快的推理速度和更緊湊的模型。
選擇 RAG 還是微調時,需綜合考慮任務性質、數據更新頻率、計算資源及可解釋性需求。RAG 更適合開放域任務和需要最新信息的應用;微調則適用於知識穩定、定義明確的專項任務。
將所選方法與項目具體需求和約束對齊至關重要。需權衡推理速度、模型大小、適應性以及對外部知識庫的依賴程度。某些情況下,結合 RAG 與微調的混合方法可能是最優解。
鼓勵從業者親自嘗試兩種方法,積累實踐經驗。
常見問題解答
Q:RAG 與微調在推理速度上有何差異?
A:微調模型通常推理速度更快。圖表顯示,在所有模型規模(小、中、大)下,微調模型的推理時間始終低於 RAG 模型。
Q:實施 RAG 系統的主要挑戰有哪些?
A:關鍵挑戰包括構建與維護大規模、最新知識庫,實現高效檢索機制,平衡檢索準確性與速度。此外,確保檢索信息的相關性及其與生成過程的無縫整合也較為複雜。
Q:如何判斷我的任務是否只需微調,還是應考慮 RAG?
A:若任務定義清晰、知識領域穩定且無需頻繁更新,可選擇微調。若應用需訪問廣泛且頻繁更新的知識庫,或需處理原始訓練數據範圍之外的查詢,則應考慮 RAG。
Q:RAG 與微調能否有效結合?
A:可以。混合方法非常有效。例如,可將微調模型作為 RAG 系統的基礎,結合專業領域知識與外部信息檢索能力;也可先用 RAG 檢索信息,再對生成過程進行微調以適配特定任務或風格。
Q:RAG 與微調在模型可解釋性方面有何差異?
A:RAG 通常更具可解釋性,因其能提供檢索信息的來源,便於追溯模型決策過程。微調模型雖在特定任務上可能更準確,但其推理過程透明度較低。
Q:除 RAG 與微調外,模型增強技術還有哪些新興趨勢?
A:新興趨勢包括:持續學習技術(使模型無需完整重訓即可更新知識)、更高效的參數高效微調方法、基於先進神經架構的改進檢索機制,以及能動態決定何時使用內部知識 vs. 外部檢索的模型。