
前語
最近在一直研究各種RAG技術用來工程化應用,但是嘗試了耳熟能詳的GraphRAG和LightRAG後,也發現了一些棘手的問題。
- 構建
知識圖譜即 index 過程過於複雜,對於大文檔來説非常耗時。 知識圖譜的構建效果比較差,經常抽取出垃圾甚至錯誤的實體和三元組。- 在錯誤的
知識圖譜引導下,其效果在感官上(直覺)甚至不如樸素的RAG。(在qwen3-embedding這種基於大語言模型的詞嵌入模型加持下) 知識圖譜的構建過程過於複雜,讀代碼也很頭疼。(也可能作者能力有限)
直到我讀到了一篇新論文 《LinearRAG: Linear Graph Retrieval-Augmented Generation on Large-scale Corpora》 ,或許這種RAG架構很接近我設想的方式。
接下來,讓我們進入真正的主題:LinearRAG
傳統RAG vs GraphRAG vs LinearRAG:誰更勝一籌?
|
方法
|
工作原理
|
優點
|
缺點
|
|
✅ Naive RAG
|
把文檔切塊 → 向量化 → 按相似度檢索 → 生成答案
|
簡單直接、穩定可靠
|
容易丟失上下文,難以處理多跳推理
|
|
⚠️ GraphRAG
|
提取實體和關係 → 構建知識圖譜 → 在圖上檢索路徑 → 生成答案
|
支持複雜推理、召回能力強
|
圖譜質量差、噪聲多、構建成本高
|
|
💡 LinearRAG(本文主角)
|
只提取實體 + 語義鏈接 → 構建三元層級圖 → 兩階段檢索
|
高效、準確、抗噪、線性擴展
|
新方法,需進一步驗證
|
📌 簡單説:
Naive RAG像是“關鍵詞搜索”,快但淺。GraphRAG像是“構建思維導圖後推理”,容易被噪聲影響,負責、耗時。LinearRAG則另闢蹊徑:不畫抽取關係,只抓關鍵節點,靠“語義橋”連通信息孤島。
GraphRAG 的“致命傷”:圖譜越建越亂
你可能以為,有了知識圖譜 = 萬事大吉。但真相是:很多時候GraphRAG系統在真實場景下表現還不如最原始的RAG,其原因是,自動構建的知識圖譜,往往充滿錯誤。
研究發現,現有GraphRAG系統的性能下降,主要來自兩個層面的問題:
局部不準(Local Inaccuracy)
比如這句話:
“愛因斯坦沒有因為相對論獲得諾貝爾獎。”
如果交給關係抽取模型處理,可能會被錯誤識別為:
(愛因斯坦, 獲得諾貝爾獎, 相對論)👉 直接把“否定”理解成“肯定”,事實完全顛倒!
這類錯誤在自然語言中極為常見,尤其是帶有否定、條件、隱喻等表達時。
全局不一致(Global Inconsistency)
再看這個例子:
文檔A説:“AI包括NLP和CV。”
文檔B説:“AI包括無監督學習。”
文檔C説:“無監督學習用於NLP。”
但如果每個句子獨立抽關係,系統可能認為“NLP”、“CV”、“無監督學習”都是AI的並列子領域,忽略了‘無監督學習’其實是NLP中的技術方法。
結果就是:圖譜結構混亂,推理路徑出錯。
🧠 打個比方:
這就像一羣人各自畫地圖,沒人溝通協調,最後拼起來的地圖東一塊西一塊,根本沒法導航。
破局之道:放棄關係抽取,擁抱“輕量級結構”
面對這些問題,港理工團隊提出了一個大膽設想:
我們真的需要顯式地抽取“主謂賓”三元組嗎?
他們認為:不需要!
真正重要的是什麼?
是那些跨文檔對齊的實體(如“愛因斯坦”、“諾貝爾獎”、“相對論”),它們才是連接碎片化知識的“錨點”。
關係語義去哪了?
保留在原文段落裏!大模型本身就能理解上下文中的複雜關係,何必強行拆成三元組引入噪音?
於是,提出了 LinearRAG ——一種無需關係抽取、高效可擴展的新一代檢索增強框架。
PS:這個觀點我非常認可,我一直都有這個想法, 抽取實體、關係三元組本身就會造成信息的丟失甚至信息的錯誤表達。而這個三元組本身就是從
chunk中派生出來的。 現如今,embedding模型越來越強大,完全有可能通過語義相似度的方式去構建關係,而節點完全可以是chunk,這樣既降低的構建知識圖譜的複雜性,又保留了更多的語義信息。我認為LinearRAG甚至可以更進一步,拋棄sentence節點來進行實現。(純屬個人觀點)
核心創新:Tri-Graph + 兩階段檢索
1. 構建 Tri-Graph:三層結構,輕盈又完整
LinearRAG 構建了一個名為 Tri-Graph(三圖) 的層級圖結構,包含三類節點:
- 🟦 實體節點(Entity):如“愛因斯坦”、“AI”、“氣候變化”
- 🟨 句子節點(Sentence):原文中的每一句話
- 🟥 段落節點(Passage):原始文本塊
實體抽取方法:
- 不依賴大模型,直接使用spaCy(輕量級模型) 進行抽取。
邊的連接規則很簡單:
- 實體出現在某句子中 → 連接到該句子
- 實體出現在某段落中 → 連接到該段落
這樣就形成了兩個關係矩陣:
Mention Matrix:句子←→實體Contain Matrix:段落←→實體
特點:
- 不依賴LLM做關係抽取,零Token消耗
- 使用輕量NER工具(spaCy),速度快、精度高
- 圖譜更新只需局部重建,支持線性擴展
**實驗顯示:**相比傳統GraphRAG,索引時間減少77%以上!
2. 兩階段檢索:先激活實體,再召回段落
檢索過程分為兩個階段,層層遞進:
第一階段:局部語義橋接(Local Semantic Bridging)
🎯 目標:找出與問題相關的“中間實體”,打通多跳路徑。
舉個例子:
問:“哪些技術推動了現代語音識別的發展?”
單純匹配“語音識別”可能找不到提到“深度神經網絡”的段落。但通過“語義橋”可以發現:
- “語音識別” ↔ “端到端模型” ↔ “Transformer” ↔ “深度神經網絡”
這些中間實體雖然沒出現在問題中,但語義相近,能幫助打通信息鏈。
🔧 方法:
- 計算查詢與初始實體的語義相似度
- 在句子層傳播相似性,激活潛在相關實體
- 形成“激活實體集”
第二階段:全局重要性聚合(Global Importance Aggregation)
🎯 目標:從全局視角評估哪些段落最重要。
🔧 方法:使用 個性化PageRank(Personalized PageRank)
- 將第一階段激活的實體作為“種子”
- 在實體-段落子圖上運行PR算法
- 得到每個段落的重要性得分
- 返回Top-K最相關段落
實驗結果:全面超越SOTA!
直接貼上論文中的數據:
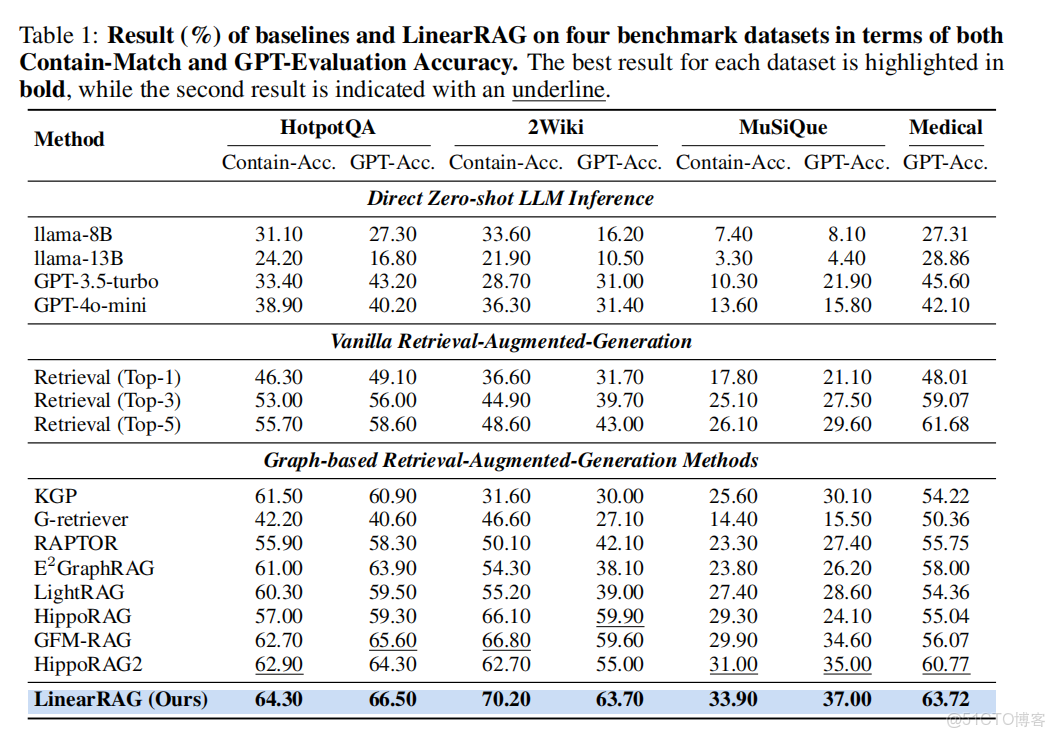
四個基準數據集上的結果, 包括包含匹配準確率和GPT評估準確率
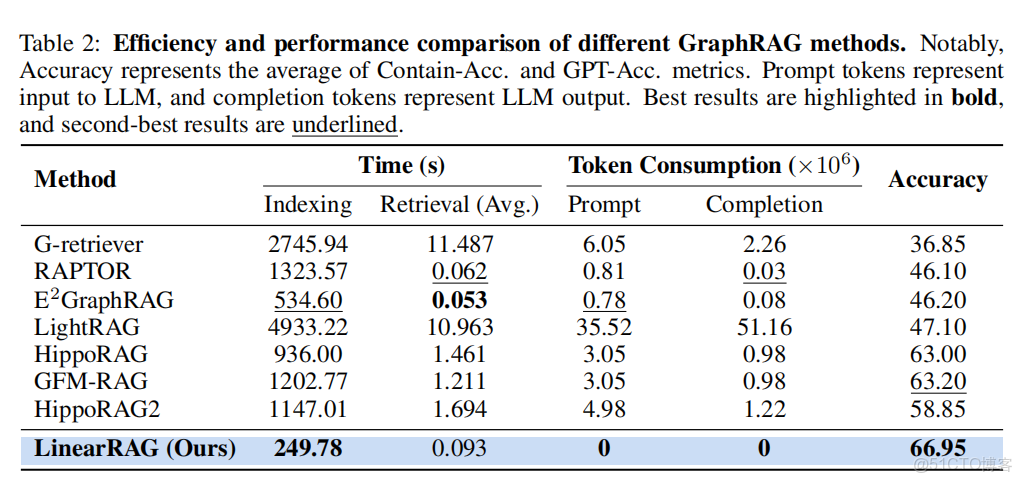
index耗時-token消耗-準確度表
📈 關鍵結論:
它的構建速度更快、資源消耗更低,真正實現了“高性能 + 高效率 + 高可靠性”三位一體。
為什麼 LinearRAG 是未來的方向?
|
優勢
|
説明
|
|
🚫 無需關係抽取
|
避免錯誤三元組污染圖譜
|
|
⚡ 輕量高效
|
使用spaCy等輕模型,不燒LLM Token
|
|
🔁 線性可擴展
|
數據越多,擴展越平穩
|
|
🧠 多跳推理強
|
通過語義橋實現單次遍歷多跳檢索
|
|
🛡️ 抗噪能力強
|
不依賴脆弱的關係結構
|