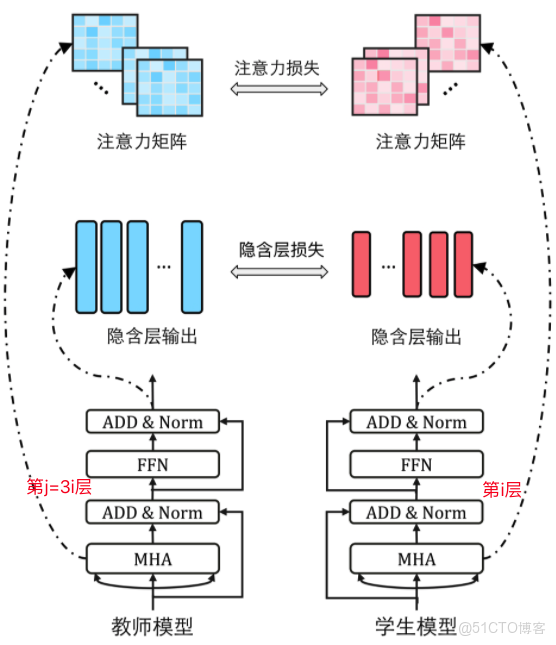
從大模型到邊緣智能體:基於行為蒸餾的 Agent 能力壓縮與泛化研究
一、背景與問題引入
隨着大語言模型(LLM)的能力不斷增強,**Agent(智能體)**在任務規劃、工具調用、環境感知等方面表現出極強的通用性。然而,一個現實問題逐漸顯現:
大模型很強,但太“重”了。
在以下場景中,大模型往往並不適用:
- 邊緣設備 / IoT / 嵌入式系統
- 高併發 Agent 集羣(如多 Agent 仿真、博弈系統)
- 實時決策系統(自動化運維、機器人控制)
- 成本敏感的商業部署
因此,一個關鍵問題出現了:
如何將大模型中“有價值的智能”遷移到輕量級 Agent?
答案之一,正是 **模型蒸餾(Model Distillation)**。
二、什麼是智能體模型蒸餾?
傳統模型蒸餾主要用於分類或迴歸任務,而在 Agent 場景中,蒸餾的對象不再只是“預測結果”,而是:
- 決策策略
- 行為分佈
- 中間推理能力
- 工具調用偏好
- 長期行為一致性
我們可以將其抽象為:
Teacher Agent(大模型)
↓
行為 / 策略 / 思維軌跡
↓
Student Agent(小模型)
三、Agent 場景下的蒸餾類型
1️⃣ 行為蒸餾(Behavior Distillation)
讓輕量 Agent 學習大模型在相同狀態下的動作選擇。
s → a_teacher → a_student
適合:
- 強化學習 Agent
- 自動控制系統
- 遊戲智能體
2️⃣ 軟標籤蒸餾(Logits Distillation)
蒸餾大模型輸出的概率分佈,而非單一結果。
P_teacher(a|s) → P_student(a|s)
優勢:
- 學到不確定性
- 行為更平滑、更穩定
3️⃣ 思維軌跡蒸餾(Chain-of-Thought Distillation)
在 LLM Agent 中尤其重要,讓 Student 學會:
- 如何拆解問題
- 如何逐步推理
- 如何選擇工具
四、整體系統架構設計
一個典型的 Agent 蒸餾系統如下:
┌────────────┐
│ 大模型Agent │ ← 推理 / 規劃 / 決策
└─────┬──────┘
│ 行為日誌 / 推理軌跡
┌─────▼──────┐
│ 蒸餾數據集 │
└─────┬──────┘
│ 監督學習
┌─────▼──────┐
│ 小模型Agent │
└────────────┘
五、示例:Agent 行為蒸餾代碼實戰(PyTorch)
1️⃣ 定義 Teacher Agent(已訓練大模型)
class TeacherAgent:
def act(self, state):
# 假設這是一個大模型推理結果
action_probs = {
"move_left": 0.1,
"move_right": 0.6,
"stay": 0.3
}
return action_probs
2️⃣ 構建 Student Agent(輕量網絡)
import torch
import torch.nn as nn
class StudentAgent(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 64),
nn.ReLU(),
nn.Linear(64, action_dim)
)
def forward(self, state):
return self.net(state)
3️⃣ 蒸餾損失函數(KL Divergence)
def distillation_loss(student_logits, teacher_probs, temperature=2.0):
student_log_probs = torch.log_softmax(
student_logits / temperature, dim=-1
)
teacher_probs = torch.tensor(
teacher_probs, dtype=torch.float32
)
loss = torch.nn.functional.kl_div(
student_log_probs,
teacher_probs,
reduction="batchmean"
)
return loss
4️⃣ 訓練 Student Agent
optimizer = torch.optim.Adam(student.parameters(), lr=1e-3)
for state in training_states:
teacher_action_probs = teacher.act(state)
state_tensor = torch.tensor(state, dtype=torch.float32)
student_logits = student(state_tensor)
loss = distillation_loss(
student_logits,
list(teacher_action_probs.values())
)
optimizer.zero_grad()
loss.backward()
optimizer.step()
六、蒸餾 Agent 的效果與收益
| 維度 | 大模型 Agent | 蒸餾後 Agent |
|---|---|---|
| 參數規模 | 數十億 | 數百萬 |
| 推理延遲 | 高 | 低 |
| 成本 | 高 | 極低 |
| 行為一致性 | 強 | 接近 |
| 可部署性 | 雲端 | 邊緣 / 本地 |
在實際項目中,蒸餾 Agent 往往能保留 70%~90% 的決策能力,卻只消耗 5% 的算力。
七、工程實踐中的關鍵經驗
- 蒸餾數據比模型結構更重要
- 真實環境軌跡 > 合成數據
- 多策略混合蒸餾效果優於單一策略
- 可結合 RL 微調(Distill + RL Fine-tune)
- 日誌系統是 Agent 蒸餾的基礎設施
八、未來發展方向
- 多 Agent 協作蒸餾
- 基於區塊鏈的蒸餾可信溯源
- 自動蒸餾策略搜索(Auto Distillation)
- LLM + 規則混合 Agent 壓縮
九、總結
智能體模型蒸餾技術為“大模型能力規模化落地”提供了一條現實路徑:
不必讓每個 Agent 都是大模型,但可以讓每個 Agent 都擁有“大模型的智慧”。
在多 Agent 系統、邊緣智能、工業自動化等場景中,模型蒸餾正在成為連接“理論能力”和“工程可用性”的關鍵橋樑。
如果你正在構建 高併發 Agent 系統、國產算力部署或輕量智能體框架,模型蒸餾值得你認真投入。