
處理海量日誌對每一個運維來説都非常的頭疼,日誌分析我們首先需要把需要的數據從海量的日誌中匹配出來,降低數據量,然後在分析這些日誌。那麼從海量的日誌中把我們需要的日誌找出來就需要我們寫一個公式來匹配,那麼如何才能寫一個這樣的公式呢?
正則表達式其實就是通過給定的符號生成一個字符串匹配的公式,通過該公式把需要的數據匹配出來。
比如
- 匹配正確的IP地址
- 匹配正確的e-mail地址
一、正則表達式介紹
正則表達式(Regular Expression、regex或regexp,縮寫為RE),也譯為正規表示法、常規表示法,是一種字符模式,用於在查找過程中匹配指定的字符。
許多程序設計語言都支持利用正則表達式進行字符串操作。例如,在Perl中就內建了一個功能強大的正則表達式引擎。
正則表達式這個概念最初是由Unix中的工具軟件(例如sed和grep)普及開的。
支持正則表達式的程序如:locate |find| vim| grep| sed |awk
正則表達式是一個三方產品,被常用計算機語言廣泛使用,比如:shell、PHP、python、java、js等!
shell中也支持正則表達式,但不是所有的命令都支持,常見的命令中只有grep,sed,awk命令
簡單來説,就是使用它提供的特殊字符,生成一個公式,用這個公式從海量的數據中篩選出想要的數據
二、正則表達式特殊字符
1、定位符使用技巧:同時錨定開頭和結尾,做精確匹配;單一錨定開頭或結尾或者不錨定的,做模糊匹配。
|
定位符
|
説明
|
|
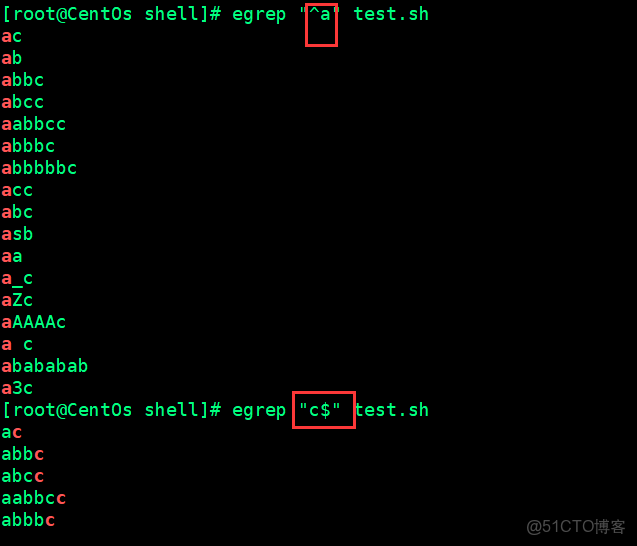
^
|
錨定開頭 ^a 以a開頭 默認錨定一個字符
|
|
$
|
錨定結尾 a$ 以a結尾 默認錨定一個字符
|
egrep和grep -e 相等
(centos7得使用-E)
精確匹配:
[root@CentOs shell]# egrep "^ac$" test.sh
ac
[root@CentOs shell]#模糊匹配
2、配符:匹配字符串
|
匹配符
|
説明
|
|
|
.
|
匹配除回車以外的任意一個字符
|
|
|
( )
|
字符串分組
|
|
|
[ ]
|
定義字符類,匹配括號中的一個字符
|
|
|
[ ^ ]
|
表示否定括號中出現字符類中的字符,取反。
|
|
|
\
|
轉義字符
|
|
|
|
|
|
或
|
(1)“.”字符測試

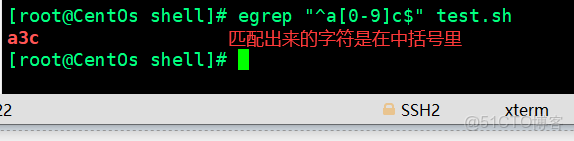
(2)中括號字符測試

(3)轉義字符測試


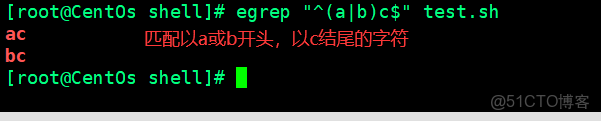
(4)小括號與或測試
小括號分組
3、限定符:對前面的字符或者(字符串)出現的次數做限定説明
|
限定符
|
説明
|
|
*
|
某個字符之後加星號表示該字符不出現或出現多次 a* (ab)*
|
|
?
|
與星號相似,但略有變化,表示該字符出現一次或不出現
|
|
+
|
與星號相似,表示其前面字符出現一次或多次,但必須出現一次
|
|
{n,m}
|
某個字符之後出現,表示該字符最少n次,最多m次
|
|
{m}
|
正好出現了m次
|
(1)*號限定符(出現多次或不出現)
[root@CentOs shell]# egrep "^ab*c$" test.sh (中間可以有一個或多個b)
ac
abbc
abbbc
abbbbbc
abc
[root@CentOs shell]#
(2)?號限定符(出現一次或不出現)
[root@CentOs shell]# egrep "^ab?c$" test.sh
ac
abc
[root@CentOs shell]#
(3)+號限定符(至少出現一次)
[root@CentOs shell]# egrep "^ab+c$" test.sh
abbc
abbbc
abbbbbc
abc
[root@CentOs shell]#
(4)大括號限定出現的次數
[root@CentOs shell]# egrep "^ab{3}c$" test.sh
abbbc
[root@CentOs shell]#
[root@CentOs shell]# egrep "^ab{2,5}c$" test.sh
abbc
abbbc
abbbbbc
[root@CentOs shell]#
三、正則表達式POSIX字符
posix字符一次只匹配一個範圍中的一個字節
|
特殊字符
|
説明
|
|
[:alnum:]
|
匹配任意字母字符0-9 a-z A-Z
|
|
[:alpha:]
|
匹配任意字母,大寫或小寫
|
|
[:digit:]
|
數字 0-9
|
|
[:graph:]
|
非空字符( 非空格控制字符)
|
|
[:lower:]
|
小寫字符a-z
|
|
[:upper:]
|
大寫字符A-Z
|
|
[:cntrl:]
|
控制字符
|
|
[:print:]
|
非空字符( 包括空格)
|
|
[:punct:]
|
標點符號
|
|
[:blank:]
|
空格和TAB字符
|
|
[:xdigit:]
|
16 進制數字
|
|
[:space:]
|
所有空白字符( 新行、空格、製表符)
|
注意:
注意[[ ]] 雙中括號的意思: 第一個中括號是匹配符[] 匹配中括號中的任意一個字符,第二個[]是格式 如[:digit:]
測試:
[root@CentOs shell]# egrep "^a[[:alnum:]]c$" test.sh (中間一個空格都不能有)
acc
abc
aZc
a3c
[root@CentOs shell]#
[root@CentOs shell]# egrep "^a[[:upper:]]c$" test.sh
aZc
[root@CentOs shell]#
可以與前面搭配使用
[root@CentOs shell]# egrep "^a[[:alnum:]]*c$" test.sh
ac
abbc
abcc
aabbcc
abbbc
abbbbbc
acc
abc
aZc
aAAAAc
a3c
abbbbbbbc
[root@CentOs shell]#
匹配ip地址:
[root@CentOs shell]# egrep '^((25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?).){3}(25[0-5]|2[0-4][[:digit:]]|[01]?[[:digit:]][[:digit:]]?)$' --color ip.txt
1.1.1.1
192.168.11.0
[root@CentOs shell]#

經過我一上午的測試,發現 egrep "^a.a$" test.sh 這種情況下匹配不出字符,不知道為啥,懷疑是中間的那個“.”的問題,但是首尾字符不一致,中間加上“.”也能匹配出來,很困惑~