
在 RAG 智能問答系統的搭建系列中,我們已逐步攻克數據處理、向量存儲、檢索優化等關鍵環節。但當系統需要對接結構化數據庫,讓非技術用户通過日常語言獲取數據時,單純的文本檢索已無法滿足需求。此時,Text2SQL 技術與工作流的結合,成為打通 “自然語言→數據庫查詢→結果反饋” 全鏈路的核心方案。本文將帶您完整實現一套基於 RAG 的數據庫智能查詢系統,讓用户無需掌握 SQL 語法,也能輕鬆從數據庫中提取所需信息。
一、Text2SQL:讓自然語言成為數據庫 “鑰匙”
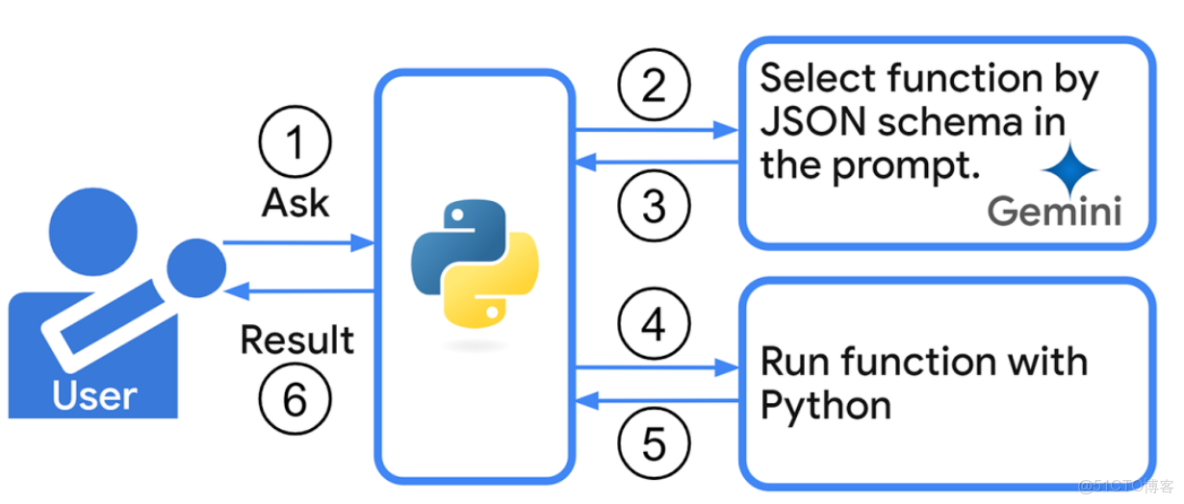
在傳統數據庫使用場景中,用户必須熟悉 SQL 語法才能編寫查詢語句 —— 這對企業中的業務人員、教育場景下的師生等非技術羣體來説,無疑是一道高門檻。而 Text2SQL 技術的出現,恰好解決了這一痛點:它能將用户輸入的自然語言(如 “獲取所有 2022 年入學學生的基本信息”),自動轉換為可執行的 SQL 語句,讓 “用聊天查數據” 成為可能。
1.1 Text2SQL 的核心能力
一套成熟的 Text2SQL 系統,需要具備四大核心功能,才能確保轉換的準確性和實用性:
- 自然語言理解(NLU):通過分詞、詞性標註、命名實體識別等 NLP 技術,精準解析用户提問的意圖。例如,當用户問 “計算機專業學生的高等數學成績” 時,系統需識別出 “計算機專業” 是篩選條件、“高等數學” 是目標科目、“成績” 是查詢字段。
- 語義解析:將理解後的自然語言,映射為數據庫可識別的結構信息。這一步需要明確查詢涉及的表名(如 “student” 表、“score” 表)、列名(如 “major”“subject”“score”)、篩選條件(如 “major = ' 計算機科學 '”),甚至多表關聯關係(如通過 “student_id” 關聯學生表與成績表)。
- SQL 生成:根據語義解析結果,生成語法正確的 SQL 語句。既支持簡單的 SELECT 查詢(如 “獲取所有學生姓名”),也能處理包含 JOIN、WHERE、GROUP BY 等複雜操作的語句(如 “統計各專業學生的平均年齡”)。
- 查詢執行與結果返回:將生成的 SQL 語句發送至數據庫執行,並將返回的結構化結果(如表格數據)整理為自然語言反饋給用户,讓用户無需查看原始數據,就能直接理解查詢結果。
1.2 Text2SQL 的典型應用場景
Text2SQL 並非單一場景的技術,而是能廣泛適配各類需要數據庫查詢的場景:
- 商業智能(BI):企業中的運營、銷售等業務人員,無需依賴數據分析師,可直接通過自然語言查詢銷售數據、用户增長趨勢,快速生成業務報表。
- 數據探索:數據分析師在初步探索數據時,無需反覆編寫 SQL 語句,通過自然語言快速驗證數據猜想,例如 “查看不同學期高等數學成績的分佈情況”。
- 客户支持:客服人員在接待用户諮詢時,可通過自然語言查詢數據庫中的訂單狀態、用户會員信息,無需切換多個系統,提升響應效率。
- 教育場景:教師可查詢學生的各科成績、班級平均分,學生也能自主查詢個人選課信息,簡化教務數據的獲取流程。
1.3 Text2SQL 面臨的技術挑戰
儘管 Text2SQL 優勢顯著,但在實際落地中仍需應對三大核心挑戰:
- 自然語言歧義:同一表述可能存在多種含義。例如 “2022 年之後入學的學生”,既可能指 “2022 年及以後”,也可能指 “2022 年之後(不含 2022 年)”,系統需結合上下文精準判斷用户意圖。
- 數據庫模式理解:系統需完全掌握數據庫的結構,包括表名、列名、字段類型、表間關聯關係(如外鍵)。若無法識別 “student_id” 是關聯 “student” 表與 “score” 表的關鍵字段,將無法生成正確的多表查詢語句。
- 複雜查詢處理:對於嵌套查詢(如 “查詢平均成績高於 85 分的專業”)、多表連接(如同時關聯學生表、成績表、課程表)等複雜場景,需要更精細的語義解析邏輯,才能確保生成的 SQL 語句邏輯正確。
二、工作流:讓 Text2SQL 流程更可控、可維護
當 Text2SQL 與 RAG 結合,需要處理 “檢索表信息→生成 SQL→執行查詢→反饋結果” 等多步驟操作時,單純的線性代碼會導致邏輯混亂、難以調試。而工作流通過 “事件驅動 + 步驟拆分” 的方式,能將複雜流程拆解為清晰的模塊,讓整個系統更易維護、更易擴展。
2.1 工作流的核心邏輯
工作流本質是一種 “事件觸發步驟、步驟生成事件” 的循環機制:將整個系統拆分為多個獨立的 “步驟”(如 “檢索表信息”“生成 SQL”“執行查詢”),每個步驟由特定 “事件” 觸發(如 “用户發起查詢” 觸發 “檢索表信息” 步驟),步驟執行完成後,再生成新的事件觸發下一個步驟。
以數據庫 RAG 查詢為例,一個典型的工作流流程如下:
- StartEvent(啓動事件):用户輸入自然語言查詢(如 “獲取所有學生的基本信息”),觸發工作流啓動;
- 檢索表信息步驟:系統從向量數據庫中檢索與查詢相關的表結構信息(如 “student” 表的字段、註釋),生成 “TableRetrieveEvent(表檢索完成事件)”;
- 生成 SQL 步驟:接收 “TableRetrieveEvent”,結合用户查詢與表信息,生成 SQL 語句,生成 “TextToSQLEvent(SQL 生成完成事件)”;
- 執行查詢與生成響應步驟:接收 “TextToSQLEvent”,執行 SQL 語句並將結果整理為自然語言,生成 “StopEvent(結束事件)”,將結果反饋給用户。
這種流程設計的優勢在於:每個步驟獨立可調試,若 “生成 SQL” 步驟出現錯誤,只需修改該模塊,無需改動其他步驟;同時,可靈活添加新步驟(如 “SQL 語法檢查” 步驟),擴展系統功能。
2.2 為什麼選擇工作流?
在 RAG 數據庫查詢系統中,工作流相比傳統的有向無環圖(DAG)框架,更能應對複雜場景的需求:
- 避免邏輯嵌套混亂:DAG 需將循環、分支邏輯編碼在圖形邊緣,導致流程難以理解;而工作流通過事件與步驟的對應關係,讓循環(如 “SQL 語法錯誤時重新生成 SQL”)、分支(如 “簡單查詢直接執行,複雜查詢先優化”)邏輯更清晰。
- 簡化數據傳遞:DAG 中節點間的數據傳遞需要處理可選值、默認值等複雜邏輯;而工作流通過事件攜帶數據(如 “TableRetrieveEvent” 攜帶表信息字符串),數據傳遞更直觀、不易出錯。
- 更貼合 AI 應用開發習慣:對於包含 RAG、LLM 調用的複雜 AI 應用,開發人員更習慣按 “步驟拆分” 的思路編寫代碼,工作流的設計更符合這一習慣,降低開發門檻。
三、實戰:從零實現 RAG+Text2SQL 數據庫查詢系統
接下來,我們將通過代碼實戰,搭建一套完整的 “自然語言→數據庫查詢” 系統。系統將基於 Python 實現,核心依賴 llama_index(處理 RAG 與工作流)、SQLAlchemy(數據庫連接)、Milvus(向量存儲表結構信息)。
3.1 環境準備與依賴安裝
首先,安裝所需依賴庫,確保系統能正常連接數據庫、處理向量存儲與工作流:
# 基礎依賴:llama_index 核心庫、工作流工具、SQLAlchemy(數據庫連接)
pip install llama-index-core llama-index-utils-workflow sqlalchemy
# 向量存儲依賴:Milvus(存儲表結構信息)
pip install llama-index-vector-stores-milvus pymilvus
# 數據庫連接依賴:MySQL 驅動、加密庫(解決 MySQL 8.0+ 認證問題)
pip install pymysql cryptography
# LLM 依賴:根據實際使用的模型安裝(如 deepseek 等)
pip install deepseek-ai3.2 核心模塊實現
系統分為 5 個核心模塊,分別負責數據庫連接、向量存儲表信息、工作流調度、Text2SQL 生成、前端交互,各模塊職責清晰、可獨立複用。
模塊 1:數據庫 RAG 基礎類(database_rag.py)
該類負責連接數據庫、加載表結構信息、創建向量索引,為後續檢索表信息提供支持:
from llama_index.core import SQLDatabase, StorageContext
from llama_index.core.objects import SQLTableSchema, SQLTableNodeMapping, ObjectIndex
from sqlalchemy import create_engine
from llama_index.vector_stores.milvus import MilvusVectorStore
import re
from .config import RagConfig # 配置類:存儲數據庫連接字符串、Milvus 地址等
class DatabaseRAG:
def __init__(self, **kwargs):
# 1. 連接數據庫:從配置中獲取連接字符串
self.engine = create_engine(RagConfig.db_connection_string)
self.sql_database = SQLDatabase(self.engine)
async def load_data(self):
# 2. 加載數據庫表結構:獲取所有表名,提取表描述與字段信息
tables = self.sql_database.get_usable_table_names()
table_schema_objs = []
for table in tables:
# 獲取單表信息(包含字段、註釋)
table_info = self.sql_database.get_single_table_info(table)
# 提取表描述(若不存在,用表名作為描述)
match = re.search(r"with comment: \((.*?)\)", table_info)
table_desc = match.group(1) if match else f"{table} table"
# 創建表結構對象(用於後續向量存儲)
table_schema_objs.append(
SQLTableSchema(table_name=table, context_str=table_desc)
)
return table_schema_objs
async def create_index(self, collection_name="database"):
# 3. 創建向量索引:將表結構信息存儲到 Milvus
# 加載表結構數據
table_data = await self.load_data()
# 建立表與節點的映射關係
table_node_mapping = SQLTableNodeMapping(sql_database=self.sql_database)
# 初始化 Milvus 向量存儲
vector_store = MilvusVectorStore(
uri=RagConfig.milvus_uri,
collection_name=collection_name,
dim=RagConfig.embedding_model_dim, # 嵌入模型維度(如 768)
overwrite=True
)
# 創建存儲上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 生成向量索引(用於後續檢索表信息)
index = ObjectIndex.from_objects(
objects=table_data,
object_mapping=table_node_mapping,
storage_context=storage_context
)
return index模塊 2:Text2SQL 工作流類(text_to_sql_workflow.py)
該類繼承自工作流與 DatabaseRAG,實現 “檢索表信息→生成 SQL→執行查詢→反饋結果” 的全流程:
from llama_index.core.indices.struct_store.sql_retriever import SQLRetriever
from llama_index.core.workflow import Workflow, Context, StartEvent, Event, step, StopEvent
from .database_rag import DatabaseRAG
from .prompts import TEXT_TO_SQL_PROMPT, RESPONSE_SYNTHESIS_PROMPT # 預定義提示模板
from .llms import deepseek_llm # 自定義 LLM 加載函數
from .utils import parse_response_to_sql # 自定義 SQL 解析函數
# 自定義事件:表檢索完成事件(攜帶查詢與表信息)
class TableRetrieveEvent(Event):
query: str
table_content_str: str
# 自定義事件:SQL 生成完成事件(攜帶查詢與 SQL)
class TextToSQLEvent(Event):
query: str
sql: str
class TextToSQLWorkflow(Workflow, DatabaseRAG):
def __init__(self, **kwargs):
# 初始化工作流與數據庫 RAG
Workflow.__init__(self, **kwargs)
DatabaseRAG.__init__(self, **kwargs)
@step
async def retrieve_tables(self, ctx: Context, ev: StartEvent) -> TableRetrieveEvent:
"""步驟 1:檢索與用户查詢相關的表信息"""
# 加載 Milvus 中的表結構索引
index = await self.create_index(collection_name="database")
# 檢索前 20 個最相關的表結構(避免遺漏關鍵信息)
retriever = index.as_retriever(similarity_top_k=20)
table_schema_objs = retriever.retrieve(ev.query)
# 整理表信息為字符串(便於 LLM 理解)
table_content_str = "\n\n".join([node.text for node in table_schema_objs])
return TableRetrieveEvent(query=ev.query, table_content_str=table_content_str)
@step
async def generate_sql(self, ctx: Context, ev: TableRetrieveEvent) -> TextToSQLEvent:
"""步驟 2:根據查詢與表信息生成 SQL"""
# 格式化提示模板(注入用户查詢與表信息)
prompt = TEXT_TO_SQL_PROMPT.format_messages(
query=ev.query,
table_context_str=ev.table_content_str
)
# 調用 LLM 生成 SQL
llm = deepseek_llm()
chat_response = llm.chat(prompt)
# 解析 LLM 響應,提取純 SQL 語句(去除多餘文本)
sql = parse_response_to_sql(chat_response)
return TextToSQLEvent(query=ev.query, sql=sql)
@step
async def generate_response(self, ctx: Context, ev: TextToSQLEvent) -> StopEvent:
"""步驟 3:執行 SQL 並生成自然語言響應"""
# 執行 SQL 查詢(獲取結構化結果)
sql_retriever = SQLRetriever(sql_database=self.sql_database)
query_result = sql_retriever.retrieve(ev.sql)
# 格式化響應模板(注入查詢、SQL、結果)
response_prompt = RESPONSE_SYNTHESIS_PROMPT.format_messages(
query=ev.query,
sql=ev.sql,
context_str=query_result
)
# 返回結果(包含響應提示與原始 SQL,便於調試)
return StopEvent(result={"message": response_prompt, "sql": ev.sql})模塊 3:提示模板配置(prompts.py)
預定義 Text2SQL 與響應合成的提示模板,引導 LLM 生成準確的 SQL 與自然語言響應:
from llama_index.core import PromptTemplate
from llama_index.core.prompts import PromptType
# Text2SQL 提示模板:限定 LLM 只使用指定表、生成正確語法的 MySQL 語句
TEXT_TO_SQL_PROMPT_STRING = """
給定一個輸入問題,首先創建語法正確的 MySQL 查詢來運行,然後查看查詢結果並返回答案。
注意事項:
1. 只查詢問題中需要的列,不要查詢表中所有列;
2. 僅使用下面列出的表結構信息,不要使用其他表或列;
3. 若涉及多表查詢,需通過外鍵(如 student_id)關聯,確保表關係正確;
4. 生成的 SQL 語句需包含完整的表名、列名,避免語法錯誤。
你必須使用以下格式:
Question: {query}
SQLQuery: 要運行的 SQL 查詢
SQLResult: (無需填寫,僅為格式要求)
Answer: (無需填寫,僅為格式要求)
可用表結構信息:
{table_context_str}
SQLQuery:
"""
TEXT_TO_SQL_PROMPT = PromptTemplate(
TEXT_TO_SQL_PROMPT_STRING,
prompt_type=PromptType.TEXT_TO_SQL
)
# 響應合成提示模板:將 SQL 結果整理為自然語言
RESPONSE_SYNTHESIS_PROMPT_STRING = """
根據用户問題、執行的 SQL 語句和查詢結果,合成簡潔易懂的自然語言回答。
要求:
1. 直接回答用户問題,不要包含 SQL 語句;
2. 若結果為表格數據,用清晰的列表或段落描述,避免展示原始數據;
3. 語言口語化,讓非技術用户能快速理解。
用户問題:{query}
執行的 SQL:{sql}
查詢結果:{context_str}
Response:
"""
RESPONSE_SYNTHESIS_PROMPT = PromptTemplate(RESPONSE_SYNTHESIS_PROMPT_STRING)模塊 4:配置文件(config.py)
存儲數據庫連接、Milvus 地址、嵌入模型維度等配置,便於統一管理:
from pydantic import Field
from pydantic_settings import BaseSettings
import os
class RagConfig(BaseSettings):
# 數據庫連接字符串(從環境變量讀取,避免硬編碼)
db_connection_string: str = Field(
default=os.getenv("DB_CONNECTION_STRING"),
description="MySQL 數據庫連接字符串"
)
# Milvus 向量存儲配置
milvus_uri: str = Field(default="http://localhost:19530", description="Milvus 服務地址")
embedding_model_dim: int = Field(default=768, description="嵌入模型維度(如 BGE 模型為 768)")
# 實例化配置(全局複用)
rag_config = RagConfig()模塊 5:前端交互(chainlit_ui.py)
使用 Chainlit 搭建簡單的 Web 界面,讓用户通過可視化界面輸入查詢、查看結果:
import chainlit as cl
from llama_index.core import Settings
from .text_to_sql_workflow import TextToSQLWorkflow
from .llms import deepseek_llm
# 初始化 LLM(用於響應流式輸出)
Settings.llm = deepseek_llm()
@cl.on_chat_start
async def start():
# 向用户發送歡迎消息
await cl.Message(content="歡迎使用數據庫智能查詢系統!請輸入您的查詢(如“獲取所有學生的基本信息”)").send()
@cl.on_message
async def main(message: cl.Message):
# 1. 創建 Text2SQL 工作流實例
workflow = TextToSQLWorkflow()
# 2. 運行工作流(傳入用户查詢)
result = await workflow.run(query=message.content)
# 3. 提取結果(SQL 語句與響應提示)
sql = result.get("sql")
response_prompt = result.get("message")
# 4. 向用户展示生成的 SQL(便於調試)
await cl.Message(content=f"生成的 SQL 語句:\n```sql\n{sql}\n```", author="系統").send()
# 5. 流式輸出自然語言響應
msg = cl.Message(content="", author="系統")
response_gen = Settings.llm.stream_chat(response_prompt)
for token in response_gen:
await msg.stream_token(token.delta)
await msg.send()3.3 系統測試與常見問題解決
測試步驟
- 啓動 Milvus 服務:確保 Milvus 向量數據庫正常運行(本地或雲端);
- 配置環境變量:設置數據庫連接字符串(避免硬編碼):
# Windows
set DB_CONNECTION_STRING=mysql+pymysql://root:root123@localhost:3306/student_db
# Linux/Mac
export DB_CONNECTION_STRING=mysql+pymysql://root:root123@localhost:3306/student_db- 啓動前端界面:
chainlit run rag/chainlit_ui.py -w- 輸入查詢測試:在 Web 界面輸入 “獲取所有計算機科學專業學生的姓名、年齡和入學年份”,查看生成的 SQL 與響應結果。
常見問題解決
- 問題 1:RuntimeError: 'cryptography' package is required for sha256_password or caching_sha2_password auth methods原因:MySQL 8.0+ 默認使用 caching_sha2_password 認證方式,依賴 cryptography 庫加密;解決:安裝 cryptography 庫:
pip install cryptography。- 問題 2:生成的 SQL 語句缺少表關聯(如查詢成績時未關聯 student 表與 score 表)原因:LLM 未明確表間關聯關係;解決:在提示模板的 “可用表結構信息” 中,補充表間關聯説明(如 “score 表的 student_id 外鍵關聯 student 表的 id 字段”)。
- 問題 3:檢索不到相關表信息原因:Milvus 中未正確創建表結構索引;解決:檢查
create_index方法,確保overwrite=True(覆蓋舊索引),且嵌入模型維度與表結構向量維度一致。
四、總結與後續優化方向
本文實現的 RAG+Text2SQL 系統,已能滿足基本的數據庫自然語言查詢需求,但在實際應用中,仍有多個優化方向可提升系統性能與用户體驗:
- SQL 語法檢查與糾錯:添加 “SQL 語法驗證” 步驟,使用 SQLAlchemy 的語法檢查功能,若生成的 SQL 存在語法錯誤,自動觸發重新生成;
- 多輪對話優化:支持上下文記憶,例如用户先問 “獲取計算機專業學生”,再問 “他們的高等數學成績”,系統能識別 “他們” 指代 “計算機專業學生”,無需重複輸入;
- 結果可視化:在前端界面中,將查詢結果(如表格數據)轉換為柱狀圖、折線圖,更適合業務人員分析數據;
- 權限控制:針對企業場景,添加用户權限管理,限制不同用户可查詢的表或字段(如客服只能查詢用户訂單信息,不能查詢財務數據)。
通過 Text2SQL 與工作流的結合,我們成功將 RAG 智能問答系統的能力擴展到結構化數據庫領域。這一方案不僅降低了數據庫的使用門檻,也為後續構建更復雜的 AI 應用(如多模態數據庫查詢、智能報表生成)奠定了基礎。