
|
隨着Apache Hadoop的起步,雲客户的增多面臨的首要問題就是如何為他們新的的Hadoop集羣選擇合適的硬件。 儘管Hadoop被設計為運行在行業標準的硬件上,提出一個理想的集羣配置不想提供硬件規格列表那麼簡單。 選擇硬件,為給定的負載在性能和經濟性提供最佳平衡是需要測試和驗證其有效性。(比如,IO密集型工作負載的用户將會為每個核心主軸投資更多)。 在這個博客帖子中,你將會學到一些工作負載評估的原則和它在硬件選擇中起着至關重要的作用。在這個過程中,你也將學到Hadoop管理員應該考慮到各種因素。
|
|
結合存儲和計算過去的十年,IT組織已經標準化了刀片服務器和存儲區域網(SAN)來滿足聯網和處理密集型的工作負載。儘管這個模型對於一些方面的標準程序是有相當意義 的,比如網站服務器,程序服務器,小型結構化數據庫,數據移動等,但隨着數據數量和用户數的增長,對於基礎設施的要求也已經改變。網站服務器現在有了緩存 層;數據庫需要本地硬盤支持大規模地並行;數據遷移量也超過了本地可處理的數量。 大部分的團隊還沒有弄清楚實際工作負載需求就開始搭建他們的Hadoop集羣。硬 件提供商已經生產了創新性的產品系統來應對這些需求,包括存儲刀片服務器,串行SCSI交換機,外部SATA磁盤陣列和大容量的機架單元。然 而,Hadoop是基於新的實現方法,來存儲和處理複雜數據,並伴隨着數據遷移的減少。 相對於依賴SAN來滿足大容量存儲和可靠性,Hadoop在軟件層次處理大數據和可靠性。
|
|
工作負載很重要嗎?在幾乎所有情形下,MapReduce要麼會在從硬盤或者網絡讀取數據時遇到瓶頸(稱為IO受限的應用),要麼在處理數據時遇到瓶頸(CPU受限)。排序是一個IO受限的例子,它需要很少的CPU處理(僅僅是簡單的比較操作),但是需要大量的從硬盤讀寫數據。模式分類是一個CPU受限的例子,它對數據進行復雜的處理,用來判定本體。 下面是更多IO受限的工作負載的例子:
下面是更多CPU受限的工作負載的例子:
|
|
Cloudera的客户需要完全理解他們的工作負載,這樣才能選擇最優的Hadoop硬件,而這好像是一個雞生蛋蛋生雞的問題。大多數工作組在沒有徹底剖析他們的工作負載時,就已經搭建好了Hadoop集羣,通常Hadoop運行的工作負載隨着他們的精通程度的提高而完全不同。而且,某些工作負載可能會被一些未預料的原因受限。例如,某些理論上是IO受限的工作負載卻最終成為了CPU受限,這是可能是因為用户選擇了不同的壓縮算法,或者算法的不同實現改變了MapReduce任務的約束方式。基於這些原因,當工作組還不熟悉要運行任務的類型時,深入剖析它才是構建平衡的Hadoop集羣之前需要做的最合理的工作。
|
|
接下來需要在集羣上運行MapReduce基準測試任務,分析它們是如何受限的。完成這個目標最直接的方法是在運行中的工作負載中的適當位置添加監視器來檢測瓶頸。我們推薦在Hadoop集羣上安裝Cloudera Manager,它可以提供CPU,硬盤和網絡負載的實時統計信息。(Cloudera Manager是Cloudera 標準版和企業版的一個組件,其中企業版還支持滾動升級)Cloudera Manager安裝之後,Hadoop管理員就可以運行MapReduce任務並且查看Cloudera Manager的儀表盤,用來監測每台機器的工作情況。
|
|
第一步是弄清楚你的作業組已經擁有了哪些硬件 在為你的工作負載構建合適的集羣之外,我們建議客户和它們的硬件提供商合作確定電力和冷卻方面的預算。由於Hadoop會運行在數十台,數百台到數千台節點上。通過使用高性能功耗比的硬件,作業組可以節省一大筆資金。硬件提供商通常都會提供監測功耗和冷卻方面的工具和建議。
|
|
為你的CDH(Cloudera distribution for Hadoop) Cluster選擇硬件選擇機器配置類型的第一步就是理解你的運維團隊已經在管理的硬件類型。在購買新的硬件設備時,運維團隊經常根據一定的觀點或者強制需求來選擇,並且他們傾向於工作在自己業已熟悉的平台類型上。Hadoop不是唯一的從規模效率上獲益的系統。再一次強調,作為更通用的建議,如果集羣是新建立的或者你並不能準確的預估你的極限工作負載,我們建議你選擇均衡的硬件類型。 Hadoop集羣有四種基本任務角色:名稱節點(包括備用名稱節點),工作追蹤節點,任務執行節點,和數據節點。節點是執行某一特定功能的工作站。大部分你的集羣內的節點需要執行兩個角色的任務,作為數據節點(數據存儲)和任務執行節點(數據處理)。
|
|
這是在一個平衡Hadoop集羣中,為數據節點/任務追蹤器提供的推薦規格:
名字節點角色負責協調集羣上的數據存儲,作業追蹤器協調數據處理(備用的名字節點不應與集羣中的名字節點共存,並且運行在與之相同的硬件環境上。)。Cloudera推薦客户購買在RAID1或10配置上有足夠功率和企業級磁盤數的商用機器來運行名字節點和作業追蹤器。
|
|
NameNode也會直接需要與羣集中的數據塊的數量成比列的RAM。一個好的但不精確的規則是對於存儲在分佈式文件系統裏面的每一個1百萬的數據塊,分配1GB的NameNode內存。於在一個羣集裏面的100個DataNodes而言,NameNode上的64GB的RAM提供了足夠的空間來保證羣集的增長。我們也推薦把HA同時配置在NameNode和JobTracker上, 這裏就是為NameNode/JobTracker/Standby NameNode節點羣推薦的技術細節。驅動器的數量或多或少,將取決於冗餘數量的需要。
記住, 在思想上,Hadoop 體系設計為用於一種並行環境。
|
|
如果你希望Hadoop集羣擴展到20台機器以上,那麼我們推薦最初配置的集羣應分佈在兩個機架,而且每個機架都有一個位於機架頂部的10G的以太網交換。當這個集羣跨越多個機架的時候,你將需要添加核心交換機使用40G的以太網來連接位於機架頂部的交換機。兩個邏輯上分離的機架可以讓維護團隊更好地理解機架內部和機架間通信對網絡需求。 Hadoop集羣安裝好後,維護團隊就可以開始確定工作負載,並準備對這些工作負載進行基準測試以確定硬件瓶頸。經過一段時間的基準測試和監視,維護團隊將會明白如何配置添加的機器。異構的Hadoop集羣是很常見的,尤其是在集羣中用户機器的容量和數量不斷增長的時候更常見-因此為你的工作負載所配置的“不理想”開始時的那組機器不是在浪費時間。Cloudera管理器提供了允許分組管理不同硬件配置的模板,通過這些模板你就可以簡單地管理異構集羣了。
|
|
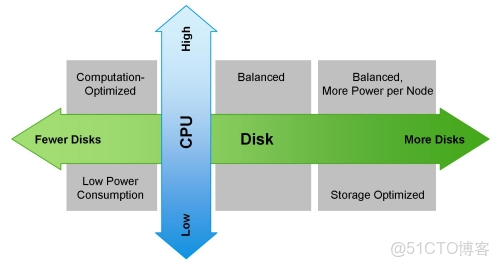
下面是針對不同的工作負載所採用對應的各種硬件配置的列表,包括我們最初推薦的“負載均衡”的配置:
(注意Cloudera期望你配置它可以使用的2x8,2x10和2x12核心CPU的配置。) 下圖向你展示瞭如何根據工作負載來配置一台機器:
|
|
其他要考慮的 記住Hadoop生態系統的設計是考慮了並行環境這點非常重要。當購買處理器時,我們不建議購買最高頻率(GHZ)的芯片,這些芯片都有很高的功耗(130瓦以上)。這麼做會產生兩個問題:電量消耗會更高和熱量散發會更大。處在中間型號的CPU在頻率、價格和核心數方面性價比是最好的。
|
|
當計算需要多少內存的時候,記住Java本身要使用高達10%的內存來管理虛擬機。我們建議把Hadoop配置為只使用堆,這樣就可以避免內存與磁盤之間的切換。切換大大地降低MapReduce任務的性能,並且可以通過給機器配置更多的內存以及給大多數Linux發佈版以適當的內核設置就可以避免這種切換。 優化內存的通道寬度也是非常重要的。例如,當我們使用雙通道內存時,每台機器就應當配置成對內存模塊(DIMM)。當我們使用三通道的內存時,每台機器都應當使用三的倍數個內存模塊(DIMM)。類似地,四通道的內存模塊(DIMM)就應當按四來分組使用內存。
|
|
超越MapReduceHadoop不僅僅是HDFS和MapReduce;它是一個無所不包的數據平台。因此CDH包含許多不同的生態系統產品(實際上很少僅僅做為MapReduce使用)。當你在為集羣選型的時候,需要考慮的附加軟件組件包括Apache HBase、Cloudera Impala和Cloudera Search。它們應該都運行在DataNode中來維護數據局部性。 HBase是一個可靠的列數據存儲系統,它提供一致性、低延遲和隨機讀寫。Cloudera Search解決了CDH中存儲內容的全文本搜索的需求,為新類型用户簡化了訪問,但是也為Hadoop中新類型數據存儲提供了機會。Cloudera Search基於Apache Lucene/Solr Cloud和Apache Tika,並且為與CDH廣泛集成的搜索擴展了有價值的功能和靈活性。基於Apache協議的Impala項目為Hadoop帶來了可擴展的並行數據庫技術,使得用户可以向HDFS和HBase中存儲的數據發起低延遲的SQL查詢,而且不需要數據移動或轉換。
|
關注資源管理是你成功的關鍵。 |
|
由於垃圾回收器(GC)的超時,HBase的用户應該留意堆的大小的限制。別的JVM列存儲也面臨這個問題。因此,我們推薦每一個區域服務器的堆最大不超過16GB。HBase不需要太多別的資源而運行於Hadoop之上,但是維護一個實時的SLAs,你應該使用多個調度器,比如使用fair and capacity 調度器,並協同Linux Cgroups使用。 Impala使用內存以完成其大多數的功能,在默認的配置下,將最多使用80%的可用RAM資源,所以我們推薦,最少每一個節點使用96GB的RAM。與MapReduce一起使用Impala的用户,可以參考我們的建議 - “Configuring Impala and MapReduce for Multi-tenant Performance.” 也可以為Impala指定特定進程所需的內存或者特定查詢所需的內存。
|
|
搜索是最有趣的訂製大小的組件。推薦的訂製大小的實踐操作是購買一個節點,安裝Solr和Lucene,然後載入你的文檔羣。一旦文檔羣被以期望的方式來索引和搜索,可伸縮性將開始作用。持續不斷的載入文檔羣,直到索引和查詢的延遲,對於項目而言超出了必要的數值 - 此時,這讓你得到了在可用的資源上每一個節點所能處理的最大文檔數目的基數,以及不包括欲期的集羣複製此因素的節點的數量總計基數。 結論購買合適的硬件,對於一個Hapdoop羣集而言,需要性能測試和細心的計劃,從而全面理解工作負荷。然而,Hadoop羣集通常是一個形態變化的系統,而Cloudera建議,在開始的時候,使用負載均衡的技術文檔來部署啓動的硬件。重要的是,記住,當使用多種體系組件的時候,資源的使用將會是多樣的,而專注與資源管理將會是你成功的關鍵。 我們鼓勵你在留言中,加入你關於配置Hadoop生產羣集服務器的經驗! Kevin O‘Dell 是一個工作於Cloudera的系統工程師。
|