

在 Java 應用中,PDF 解析(PDF parsing in Java)通常用於從 PDF 文件中提取可用信息,本文將基於Spire.PDF for Java,從實際開發角度出發,介紹在Java項目中常見的PDF解析操作。

在 Java 應用中,PDF 解析(PDF parsing in Java)通常用於從 PDF 文件中提取可用信息,而不僅僅是將其渲染出來進行展示。常見的應用場景包括文檔索引、自動化報表處理、發票分析以及數據採集與導入流程等。
與 JSON、XML 等結構化數據格式不同,PDF 的設計目標是保證視覺呈現效果的一致性。文本、表格、圖像等內容在 PDF 中並不是以邏輯結構存儲的,而是以帶有座標信息的繪製指令形式存在。因此,在 Java 中進行 PDF 解析,核心在於理解 PDF 內部的內容表示方式,以及 Java PDF 庫是如何通過 API 將這些內容暴露出來的。
本文將基於 Spire.PDF for Java,從實際開發角度出發,介紹在 Java 項目中常見的 PDF 解析操作。文章不會將 PDF 解析視為一個單一的線性流程,而是按功能劃分,分別講解文本、表格、圖像和元數據的提取方式,便於在真實項目中按需組合使用。
從實現角度理解 Java 中的 PDF 解析
從實踐層面來看,Java 中的 PDF 解析並不是一個單一操作,而是一組針對同一 PDF 文檔執行的不同數據提取任務,具體取決於應用需要獲取哪類信息。
在實際系統中,PDF 解析通常用於獲取以下內容:
- 純文本內容,用於搜索、索引或文本分析
- 結構化數據(如表格),用於後續處理或存儲
- 嵌入資源(如圖片),用於歸檔或下游處理
- 文檔元數據,用於分類、審計或版本管理
PDF 解析之所以複雜,根本原因在於 PDF 的內容存儲方式。與結構化文檔不同,PDF 並不會顯式保存段落、行或表格等邏輯結構,而是主要由以下內容組成:
- 頁面級內容流
- 通過座標定位的文本片段
- 用於構成視覺結構的圖形元素(圖片、線條、間距、邊框等)
因此,Java 中的 PDF 解析本質上是基於頁面佈局信息還原內容語義的過程。這也是為什麼在實際項目中,往往需要藉助專業的 PDF 解析庫:它既能暴露底層頁面內容,又提供了文本提取、表格識別等高級功能,從而減少手寫解析邏輯的複雜度。
Java 中實用的 PDF 解析思路
在生產環境中,PDF 解析更適合被設計為一組可獨立調用的解析操作,而不是固定順序的流水線。這種設計方式有助於隔離錯誤,也能讓應用只執行真正需要的解析邏輯。
本文使用 Spire.PDF for Java 作為示例庫。它提供了文本提取、表格解析、圖像導出和元數據訪問等 API,適用於後端服務、批量任務以及文檔自動化系統。
安裝 Spire.PDF for Java
載並手動引入依賴。如果項目使用 Maven,也可以通過以下配置進行安裝:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>完成安裝後,即可直接使用 Java 代碼加載和解析 PDF 文件,無需依賴外部工具。
在 Java 中加載並驗證 PDF 文檔
在執行任何解析操作之前,首先需要加載並驗證 PDF 文檔。建議將這一步作為獨立操作,用於確認文檔是否可以被後續解析邏輯安全處理。
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// 創建 PdfDocument 實例
PdfDocument pdf = new PdfDocument();
// 加載 PDF 文件
pdf.loadFromFile("sample.pdf");
// 獲取頁面總數
int pageCount = pdf.getPages().getCount();
System.out.println("總頁數: " + pageCount);
}
}控制枱輸出示例

從實現角度來看,只要能夠成功加載文檔並訪問頁面集合,就已經驗證了多個關鍵條件:
- 文件格式受支持
- 文檔結構可以正常解析
- 頁面樹存在且可訪問
在生產系統中,這一步通常作為入口校驗使用,無法加載或頁面結構異常的 PDF 可以直接被攔截,避免影響後續流程,有助於在批處理或自動化場景中避免錯誤級聯。
使用 Java 解析 PDF 頁面中的文本
文本解析是 Java 中最常見的 PDF 處理需求之一,其核心目標是從 PDF 頁面中提取並重組可讀文本內容。使用 Spire.PDF for Java 解析 PDF 文本時,文本解析不應簡單理解為一次性 API 調用,而應通過 PdfTextExtractor 配合可配置的 PdfTextExtractOptions 來實現,以獲得更穩定、可控的解析結果。
將文本解析設計為獨立的處理步驟,可以在文檔索引、內容分析、全文搜索或數據遷移等場景中靈活複用。
Java 中文本解析的實現流程
在典型的 Java 實現中,PDF 文本解析通常由以下幾個清晰的步驟構成,每一步都能在代碼中直接體現:
- 將 PDF 文件加載為 PdfDocument 實例
- 通過 PdfTextExtractOptions 配置文本解析行為
- 針對每一頁創建對應的 PdfTextExtractor
- 按頁面提取文本並彙總解析結果
這種基於頁面的解析方式與 PDF 的底層結構高度一致,也為多頁文檔的處理提供了更好的控制能力。
示例:使用 Java 提取 PDF 頁面中的文本
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// 創建並加載 PDF 文檔
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 使用 StringBuilder 高效累積解析結果
StringBuilder extractedText = new StringBuilder();
// 配置文本解析選項
PdfTextExtractOptions options = new PdfTextExtractOptions();
// 啓用簡化解析模式,提高文本可讀性
options.setSimpleExtraction(true);
// 遍歷 PDF 中的每一頁
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 為當前頁面創建文本解析器
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// 按配置選項解析當前頁面文本
String pageText = extractor.extract(options);
// 追加到結果緩衝區
extractedText.append(pageText).append("\n");
}
// 此時 extractedText 已包含完整文本內容,
// 可用於存儲、索引或後續處理
System.out.println(extractedText.toString());
}
}控制枱輸出示例
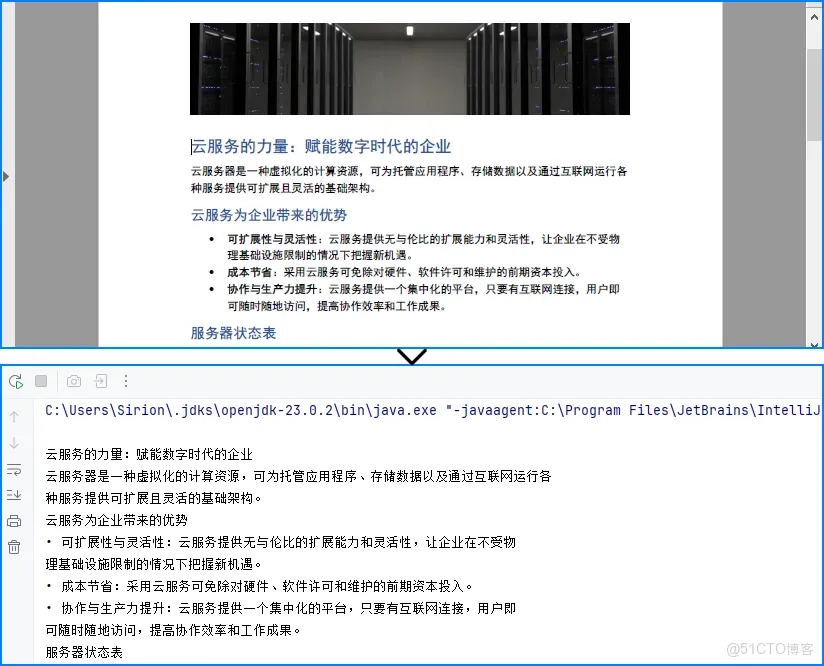
關鍵類與配置説明
- PdfTextExtractor 以頁面為解析單位,對文本內容進行提取和重組,提供比全局提取更精細的控制能力。
- PdfTextExtractOptions 用於控制文本解析行為。啓用 setSimpleExtraction(true) 可在多數場景下生成更乾淨、更易讀的文本結果,減少因佈局干擾導致的斷行或錯序問題。
- 按頁解析策略 將解析範圍限定在單頁,有助於處理大體量 PDF 文檔,也更容易在出現異常時定位和隔離問題頁面。
技術要點與實現注意事項
- PDF 中的文本並不是以段落或行結構存儲的,而是由帶有位置信息的字符(glyph)組合而成,因此文本解析本質上是一個基於座標的重組過程
- 文本提取行為可以通過 PdfTextExtractOptions 進行調整,以在佈局還原精度和文本可讀性之間取得平衡
- 採用頁面級文本提取能夠顯著提升容錯性和靈活性,尤其適合多頁或結構不完全一致的 PDF 文件
- 提取後的文本在進入搜索、分析或數據處理系統之前,通常仍需要進行額外的規範化處理,例如清理多餘空白、合併斷行、統一編碼等
這種基於頁面的文本解析方式非常適合佈局相對穩定、以文字內容為主的文檔,如報告、合同和説明文檔;也是在 Java 中使用 Spire.PDF for Java 解析 PDF 頁面文本的推薦實踐。
使用 Java 解析 PDF 頁面中的表格
表格解析屬於較為高級的 PDF 解析操作,其目標是在 PDF 頁面中識別出表格結構,並將其還原為具有行和列關係的結構化數據。與純文本解析相比,表格解析更強調單元格之間的語義關係,常用於發票、財務報表、業務統計報表等場景。
在 Java 中進行 PDF 解析時,表格解析可以將視覺上對齊的數據轉換為程序可直接處理的結構化內容,便於存儲、分析或導出。
Java 中表格解析的實現思路
表格解析的核心不再是簡單的文本提取,而是基於頁面佈局和對齊關係進行結構推斷:
- 將 PDF 文檔加載為 PdfDocument
- 創建並綁定 PdfTableExtractor
- 從指定頁面解析表格結構
- 根據解析結果還原行和列
- 對單元格數據進行校驗和規範化
與文本解析不同,表格解析是通過元素的視覺對齊和佈局一致性來推斷結構的,從而實現對原本“散落在頁面上的文本”的行列級訪問。
示例:使用 Java 從 PDF 頁面中解析表格
下面的示例展示瞭如何使用 PdfTableExtractor 從 PDF 頁面中解析表格,並將其轉換為按行列組織的數據結構,便於後續處理或導出。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// 載入 PDF 文檔
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 創建 PdfTableExtractor 對象
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 從第一頁解析表格(頁索引從 0 開始)
PdfTable[] tables = extractor.extractTable(0);
// 遍歷表格
if (tables != null) {
for (PdfTable table : tables) {
// 獲取表格的行數和列數
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
// 獲取單元格數據
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
System.out.println(tableData.toString());
}
}
}
}控制枱輸出示例

實現細節説明
- PdfTableExtractor: 通過分析頁面級內容,根據文本對齊和佈局特徵識別表格區域。
- 結構還原: 行和列是通過文本元素的相對位置推斷得出的,可通過行列索引訪問單元格內容。
- 按頁解析: 每頁單獨解析,有助於應對不同頁面佈局不一致的問題。
表格解析的實際注意事項
- 表格邊界來源於視覺佈局,而非顯式定義
- 表頭行可能需要額外識別或處理邏輯
- 單元格內容在存儲或導出前通常需要規範化
- 佈局複雜或不規則的表格可能影響解析精度
儘管存在一定限制,表格解析依然是 Java PDF 解析中極具價值的能力之一,特別適合從結構化業務文檔中自動提取數據。
使用 Java 解析 PDF 頁面中的圖像
圖像解析是一種專門用於提取 PDF 頁面中嵌入圖像資源的解析能力。與文本或表格解析不同,圖像解析並不依賴內容流或佈局推斷,而是直接分析頁面資源,識別其中的圖像對象。
在 Java PDF 處理系統中,圖像解析常用於視覺內容歸檔、文檔組成審計,或將圖像數據傳遞給下游處理流程。
Java 中圖像解析的工作方式
從實現角度來看,圖像解析主要基於頁面級資源:
- 將 PDF 文檔加載為 PdfDocument
- 初始化 PdfImageHelper 工具類
- 遍歷頁面並獲取圖像資源信息
- 提取並導出每個嵌入的圖像對象
由於圖像作為獨立資源存儲,這一解析過程不依賴文本順序、佈局重建或表格識別邏輯。
示例:使用 Java 從 PDF 頁面中解析圖像
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class extractPdfImages {
public static void main(String[] args) throws IOException {
// 載入 PDF 文檔
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 創建 PdfImageHelper 對象
PdfImageHelper imageHelper = new PdfImageHelper();
// 遍歷每一頁
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 獲取當前頁的圖片信息
PdfImageInfo[] imageInfos =
imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// 獲取指定圖片
BufferedImage image = imageInfos[j].getImage();
// 保存圖片為 PNG 文件
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}提取結果示例

圖像解析的關鍵説明
- PdfImageHelper / PdfImageInfo: 用於分析頁面資源並以 BufferedImage 形式訪問嵌入圖像。
- 按頁處理: 即使多頁文檔中存在重複或複用圖像,也能準確提取。
- 與佈局無關: 圖像解析不依賴文本流或表格結構,適用於所有視覺資源。
圖像解析的實際注意事項
- 提取的圖像可能包含裝飾性或背景元素
- 不同 PDF 的圖像分辨率、色彩空間和格式可能不同
- 大型 PDF 文檔可能包含大量圖像,需要合理管理內存和存儲
- 圖像解析通常與文本、表格和元數據解析結合使用,共同構成完整的 PDF 解析流程
使用 Java 解析 PDF 元數據
元數據解析是 PDF 解析中的基礎能力之一,主要用於讀取獨立於頁面內容之外的文檔級信息。與文本或表格解析不同,元數據解析不依賴頁面佈局,因此在絕大多數 PDF 文件中都具有較高的穩定性。
在 Java PDF 處理系統中,元數據通常作為前置分析步驟,用於文檔分類、流程路由或索引決策。
Java 中元數據解析的實現方式
元數據解析是文檔級操作,其實現步驟通常如下:
- 將 PDF 加載為 PdfDocument
- 訪問文檔信息字典
- 讀取可用的元數據字段
- 將解析結果用於分類、路由或索引邏輯
由於元數據不依賴渲染內容,這一解析過程開銷小、速度快,且結果較為一致。
示例:使用 Java 解析 PDF 文檔元數據
import com.spire.pdf.PdfDocument;
public class parsePdfMetadata {
public static void main(String[] args) {
// 載入 PDF 文檔
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 獲取 PDF 文檔元數據信息
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}控制枱輸出示例

元數據解析的要點説明
- 文檔信息字典: 元數據存儲在 PDF 的獨立結構中,與頁面渲染內容無關。
- 字段完整性: 並非所有 PDF 都包含完整元數據,使用前應進行空值校驗。
- 解析成本低: 不需要遍歷頁面,適合作為初始解析步驟。
元數據解析的常見用途
- 文檔分類與標籤管理
- 搜索索引與篩選
- 工作流路由與權限控制
- 版本管理與審計記錄
由於不受佈局和內容流影響,元數據解析在複雜 PDF 中通常比文本或表格解析更加穩定。
Java PDF 解析的實現注意事項
在實際項目中,往往需要在同一處理流程中組合多種 PDF 解析能力。
組合使用多種解析操作
常見的實現模式包括:
- 提取文本用於索引,同時解析表格用於結構化存儲
- 利用元數據決定文檔進入哪條處理流程
- 在定時任務或批處理作業中異步執行解析操作
將文本、表格、圖像和元數據解析視為相互獨立但可組合的模塊,有助於系統的擴展性、可測試性和長期維護。
實際限制與約束
即便使用成熟的 Java PDF 解析庫,仍存在一些不可避免的限制:
- 掃描版 PDF 在解析前,需要先進行 OCR 處理
- 佈局高度複雜或不一致的文檔會降低解析精度
- 自定義字體或編碼方式可能影響文本還原效果
充分理解這些限制,有助於在生產環境中制定合理的解析策略,並降低異常處理複雜度。
總結
在 Java 中進行 PDF 解析時,將其視為一組目標明確、彼此獨立的提取操作,往往比線性流程更高效、更可靠。通過分別處理文本、表格和元數據,Java 應用可以穩定地將 PDF 文檔轉換為可用數據。
藉助 Spire.PDF for Java 這樣的專業庫,開發者可以構建可維護、可擴展,並能滿足真實業務需求的 PDF 處理解決方案。
Java PDF 解析常見問題解答
Q1:如何在 Java 中解析 PDF 頁面中的文本?
A:可以使用 Spire.PDF for Java 提供的 PdfTextExtractor 與 PdfTextExtractOptions,按頁面提取文本,適用於索引、分析或內容遷移場景。
Q2:如何在 Java 中提取 PDF 表格?
A:通過 PdfTableExtractor 識別表格區域並還原行列結構,解析結果可進一步處理或導出為結構化數據。
Q3:Java 可以解析 PDF 中的圖片嗎?
A:可以。使用 PdfImageHelper 和 PdfImageInfo 可提取頁面中的嵌入圖像,也可將整頁 PDF 轉換為圖片。
Q4:如何在 Java 中讀取 PDF 元數據?
A:通過 PdfDocumentInformation 獲取標題、作者、創建時間等字段,該操作速度快且不依賴頁面內容。
Q5:Java PDF 解析是否存在限制?
A:複雜佈局、掃描版 PDF 和自定義字體都會影響解析效果。掃描文檔需要先進行 OCR 處理。