
一、項目簡介
本項目基於 Rust 語言開發,目標是爬取豆瓣電影 Top250 榜單的核心信息,包括電影名稱、評分、導演、主演、上映年份、劇情簡介等關鍵數據,並將結果以 JSON 格式持久化存儲,便於後續數據分析或二次開發。相較於其他語言,Rust 的內存安全性和高效性能讓爬蟲在處理頁面解析與數據處理時更穩定,同時通過異步編程實現高效請求,避免網絡等待導致的性能浪費。
二、技術棧
本項目選取 Rust 生態中成熟穩定的第三方庫,兼顧功能完整性與學習成本,具體技術棧如下:
- HTTP 客户端:
reqwest(Rust 異步 HTTP 客户端的事實標準,支持 TLS 加密、請求頭配置,能模擬瀏覽器請求規避反爬,同時支持連接複用提升效率) - HTML 解析:
scraper(基於 W3C 選擇器標準,支持 CSS 選擇器定位元素,輕量高效,能精準提取頁面中的電影數據) - JSON 序列化:
serde+serde_json(Rust 生態的序列化標杆庫,通過派生宏簡化數據結構與 JSON 的轉換,支持格式化輸出提升可讀性) - 異步運行時:
tokio(高性能異步運行時,負責調度 HTTP 請求與解析任務,實現非阻塞 IO 操作,提升爬蟲整體效率) - 錯誤處理:
anyhow(簡化錯誤傳遞流程,支持為錯誤添加上下文信息,無需手動定義複雜錯誤類型,便於調試) - 日誌輸出:
log+env_logger(輕量級日誌方案,可通過環境變量控制日誌級別,輸出請求狀態、解析進度等關鍵信息)
三、項目結構
項目採用簡潔清晰的結構,核心邏輯集中在 main.rs 中,同時預留擴展模塊的空間,便於後續功能迭代。具體結構如下:
douban-movie-top250-crawler/
├── Cargo.toml # 項目配置與依賴管理
├── src/
│ └── main.rs # 核心邏輯(請求、解析、存儲全流程)
└── douban_top250.json # 輸出結果文件(運行後自動生成)各文件職責説明:
Cargo.toml:聲明項目名稱、版本、edition 等基礎信息,配置所有依賴庫及其版本和特性,確保編譯環境一致src/main.rs:包含數據結構定義、HTTP 請求發送、HTML 解析、數據提取、JSON 存儲等核心邏輯,是程序執行的入口douban_top250.json:爬蟲運行成功後生成的結果文件,存儲格式化的電影數據,便於後續查看和使用
四、項目開發
4.1 環境準備
首先確保本地已安裝 Rust 開發環境(通過 rustup 安裝),驗證環境:
rustc --version # 輸出 Rust 版本(建議 ≥1.63.0)
cargo --version # 輸出 Cargo 版本4.2 初始化項目
通過 Cargo 命令創建項目並進入目錄:
cargo new douban-movie-top250-crawler
cd douban-movie-top250-crawler4.3 配置依賴(Cargo.toml)
編輯 Cargo.toml 文件,添加項目所需依賴,指定版本和必要特性(版本可通過 crates.io 查詢最新穩定版):
[package]
name = "douban-top250-scraper"
version = "0.1.0"
edition = "2021"
[dependencies]
reqwest = { version = "0.11", features = ["json", "gzip", "brotli", "stream", "rustls-tls"] }
scraper = "0.17"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
tokio = { version = "1", features = ["full"] }
regex = "1.10"
thiserror = "1.0"
rand = "0.8"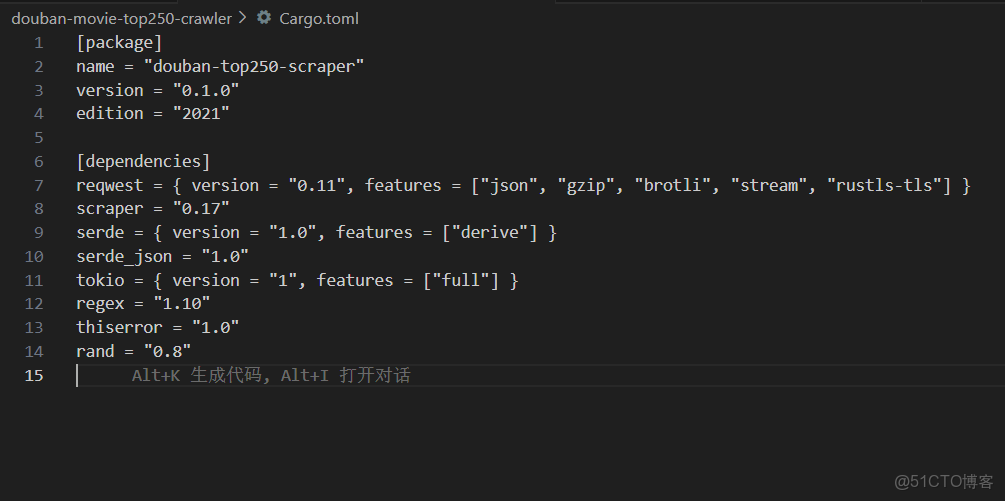
4.4 核心邏輯實現(src/main.rs)
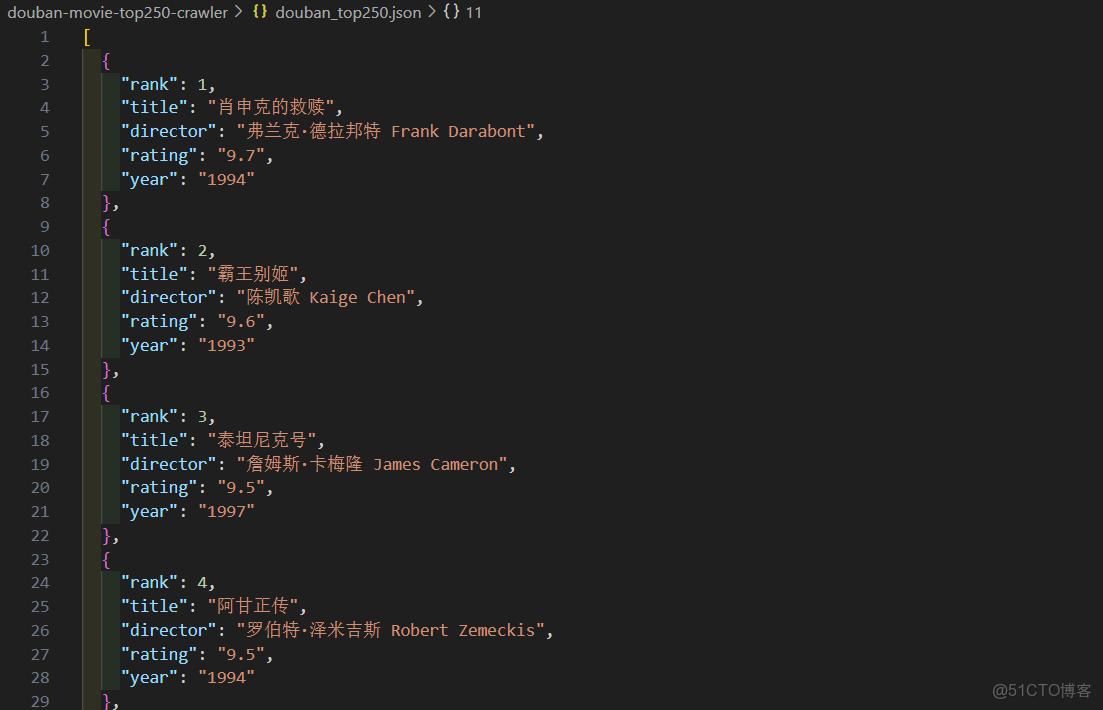
1. 數據結構定義(Movie 結構體)
#[derive(Debug, Serialize, Deserialize, Clone)]
struct Movie {
rank: u32, // 電影排名(1-250)
title: String, // 電影名稱
director: String, // 導演
rating: String, // 豆瓣評分
year: String, // 上映年份
}- 派生宏説明:
Debug:支持調試打印(如println!("{:?}", movie));Serialize/Deserialize:支持與 JSON 格式互轉;Clone:支持結構體深拷貝(實際場景中可根據需求移除)。
- 字段設計:均使用
String類型存儲文本數據,避免類型轉換錯誤,兼容“未知信息”等默認值場景。
2. 自定義錯誤類型(ScraperError)
#[derive(thiserror::Error, Debug)]
pub enum ScraperError {
#[error("網絡請求錯誤: {0}")]
RequestError(#[from] reqwest::Error), // 網絡請求相關錯誤
#[error("解析錯誤: {0}")]
ParseError(String), // HTML 解析相關錯誤
}- 基於
thiserror實現,錯誤信息語義化,便於調試; - 支持從
reqwest::Error自動轉換(#[from]宏),簡化錯誤處理流程。
3. 主函數(程序入口)
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error>> {
// 1. 爬取所有電影數據
let movies = scrape_douban_top250().await?;
// 2. 控制枱打印結果
for movie in &movies {
println!(
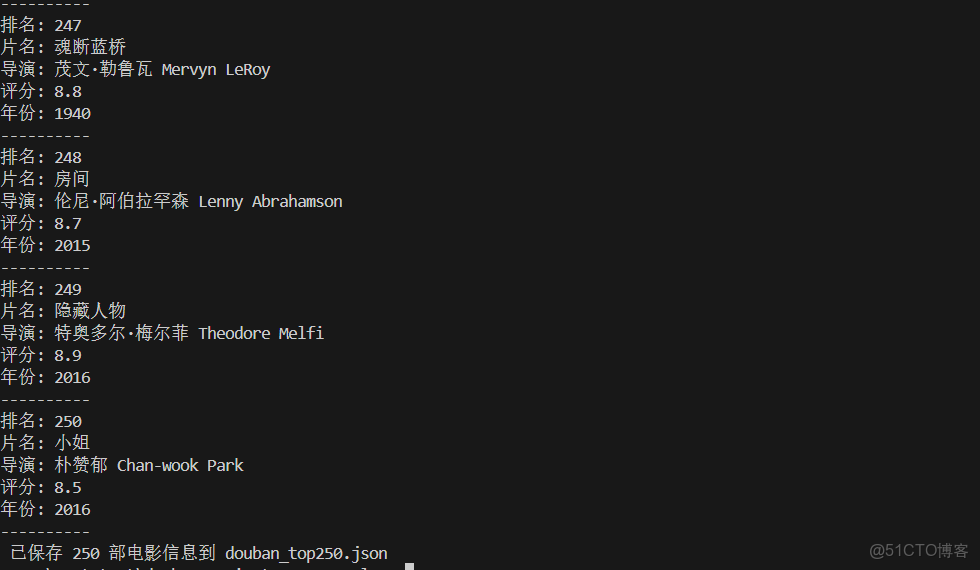
"排名: {}\n片名: {}\n導演: {}\n評分: {}\n年份: {}\n----------",
movie.rank, movie.title, movie.director, movie.rating, movie.year
);
}
// 3. 序列化並保存為 JSON 文件
let json = serde_json::to_string_pretty(&movies)?;
tokio::fs::write("douban_top250.json", json).await?;
println!("已保存 {} 部電影信息到 douban_top250.json", movies.len());
Ok(())
}- 入口註解
#[tokio::main]:啓用 Tokio 異步運行時,支撐後續異步函數調用; - 核心流程:爬取數據 → 控制枱輸出 → JSON 持久化;
- 異步文件寫入
tokio::fs::write:與 Tokio 運行時兼容,避免阻塞線程。
4. 核心爬取邏輯(scrape_douban_top250)
async fn scrape_douban_top250() -> Result<Vec<Movie>, ScraperError> {
// 1. 創建 HTTP 客户端(帶請求頭配置)
let client = create_http_client()?;
let mut all_movies = Vec::new();
// 2. 遍歷 10 頁榜單(豆瓣 Top250 每頁 25 條)
for page in 0..10 {
let start = page * 25; // 分頁偏移量(0、25、50...)
let url = format!("https://movie.douban.com/top250?start={}&filter=", start);
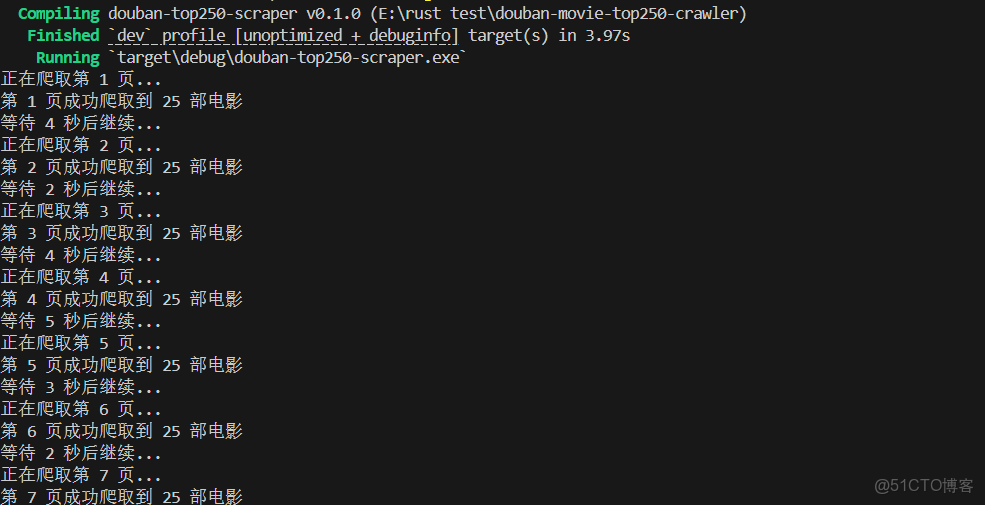
println!("正在爬取第 {} 頁...", page + 1);
// 3. 爬取當前頁數據
match scrape_page(&client, &url, start).await {
Ok(mut movies) => {
println!("第 {} 頁成功爬取到 {} 部電影", page + 1, movies.len());
all_movies.append(&mut movies);
}
Err(e) => {
eprintln!(" 爬取頁面失敗 {}: {}", url, e);
}
}
// 4. 反爬優化:隨機延遲 2~5 秒
let delay_secs = rand::thread_rng().gen_range(2..=5);
println!(" 等待 {} 秒後繼續...", delay_secs);
sleep(Duration::from_secs(delay_secs)).await;
}
Ok(all_movies)
}- 分頁邏輯:通過
start參數控制分頁(start=0為第 1 頁,start=25為第 2 頁,以此類推); - 錯誤處理:使用
match捕獲單頁爬取錯誤,僅打印警告不中斷整體爬取; - 反爬設計:隨機延遲 2~5 秒,模擬人工瀏覽行為,避免高頻請求被豆瓣封禁 IP。
5. HTTP 客户端配置(create_http_client)
fn create_http_client() -> Result<reqwest::Client, ScraperError> {
let mut headers = HeaderMap::new();
// 模擬瀏覽器請求頭,規避基礎反爬
headers.insert(USER_AGENT, HeaderValue::from_static("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"));
headers.insert(ACCEPT, HeaderValue::from_static("text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8"));
headers.insert(ACCEPT_LANGUAGE, HeaderValue::from_static("zh-CN,zh;q=0.9,en;q=0.8"));
let client = reqwest::Client::builder()
.default_headers(headers) // 設置默認請求頭
.timeout(Duration::from_secs(30))
.build()?;
Ok(client)
}- 核心作用:配置請求頭模擬瀏覽器行為,避免被豆瓣識別為爬蟲;
- 關鍵配置:
USER_AGENT:標識客户端類型,使用主流 Chrome 瀏覽器 UA;ACCEPT:聲明可接收的響應格式,符合 HTTP 規範;ACCEPT_LANGUAGE:指定語言偏好,適配豆瓣中文頁面;timeout:設置 30 秒超時,防止因網絡問題導致程序卡死。
6. 單頁數據解析(scrape_page)
這是最核心的解析模塊,負責從 HTML 中提取單頁電影數據:
async fn scrape_page(client: &reqwest::Client, url: &str, start_offset: usize) -> Result<Vec<Movie>, ScraperError> {
// 1. 發送 HTTP 請求並檢查響應狀態
let response = client.get(url).send().await?;
let status = response.status();
if !status.is_success() {
eprintln!("HTTP請求失敗,狀態碼: {}", status);
return Err(ScraperError::RequestError(reqwest::Error::from(
response.error_for_status().unwrap_err(),
)));
}
// 2. 解析 HTML 文檔
let body = response.text().await?;
let document = Html::parse_document(&body);
let item_selector = Selector::parse("div.item").unwrap(); // 電影項容器選擇器
let mut movies = Vec::new();
// 3. 遍歷所有電影項,提取字段
for (index, element) in document.select(&item_selector).enumerate() {
// 排名 = 分頁偏移量 + 頁內索引 + 1
let rank = (start_offset + index + 1) as u32;
// 提取片名(CSS 選擇器:span.title)
let title = element
.select(&Selector::parse("span.title").unwrap())
.next()
.map(|e| e.text().collect::<String>())
.unwrap_or_else(|| "未知片名".to_string()); // 缺失時使用默認值
// 提取評分(CSS 選擇器:span.rating_num)
let rating = element
.select(&Selector::parse("span.rating_num").unwrap())
.next()
.map(|e| e.text().collect::<String>())
.unwrap_or_else(|| "暫無評分".to_string());
// 提取導演和年份(複雜文本處理,使用正則)
let mut director = "未知導演".to_string();
let mut year = "未知年份".to_string();
// 找到包含導演、年份的容器(CSS 選擇器:div.bd p)
if let Some(bd_element) = element.select(&Selector::parse("div.bd p").unwrap()).next() {
let bd_text: String = bd_element.text().collect::<String>();
// 清洗文本:去除換行、非-breaking 空格,修剪首尾空白
let clean_text = bd_text.replace("\n", " ").replace("\u{00a0}", " ").trim().to_string();
// 正則提取導演(匹配 "導演: XXX" 格式)
let re_director = regex::Regex::new(r"導演:\s*([^主演]+)").unwrap();
if let Some(cap) = re_director.captures(&clean_text) {
director = cap[1].trim().to_string();
}
// 正則提取年份(匹配 4 位數字)
let re_year = regex::Regex::new(r"(\d{4})").unwrap();
if let Some(caps) = re_director.captures(&clean_text) {
year = caps[1].to_string();
}
}
// 4. 構建 Movie 對象並添加到列表
movies.push(Movie {
rank,
title,
director,
rating,
year,
});
}
Ok(movies)
}- 解析流程:
- 請求響應處理:檢查 HTTP 狀態碼,非 2xx 則返回錯誤;
- HTML 解析初始化:將響應文本轉為
Html文檔對象,定義電影項容器選擇器div.item; - 字段提取邏輯:
- 簡單字段(片名、評分):直接通過 CSS 選擇器提取,缺失時使用默認值(如“未知片名”);
- 複雜字段(導演、年份):先清洗文本(去除無效字符),再通過正則表達式提取(應對非結構化文本);
- 排名計算:基於分頁偏移量 + 頁內索引,確保排名連續(1-250)。
五、運行説明
運行命令
cargo run輸出結果
- 控制枱打印每部電影的排名、片名、導演、評分、年份;
- 項目根目錄生成
douban_top250.json文件,包含所有電影的 JSON 格式數據。
六、項目總結
本項目通過實踐驗證了Rust在爬蟲開發中的優勢—類型安全保障了數據處理的準確性,異步運行時提升了網絡請求效率,內存高效的特性使程序在長時間運行中仍保持穩定。同時,項目也凸顯了“合規爬取”的重要性,後續開發中需持續遵守豆瓣robots協議,進一步優化請求策略,在獲取數據價值的同時尊重目標網站的服務規則。
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。