
前言
本期基於某光伏電站發電功率數據集,推出一組Informer-SENet預測對比模型合集。包括'LSTM', 'Transformer-encoder', 'Informer', 'Informer-encoder', 'Informer-SENet', 'Informer-encoder-SENet'等6組模型對比實驗:
1 模型合集簡介
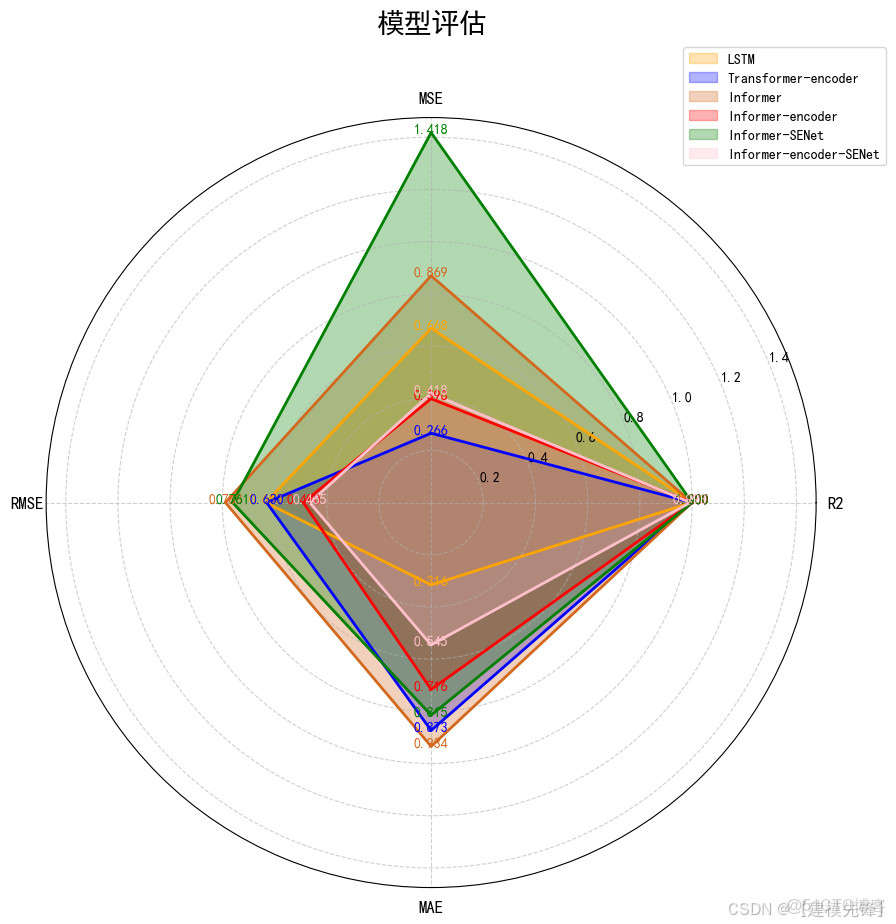
1.1 模型評估:
(1)指標雷達圖可視化對比
(2)指標柱狀圖對比:

1.2 預測可視化對比:
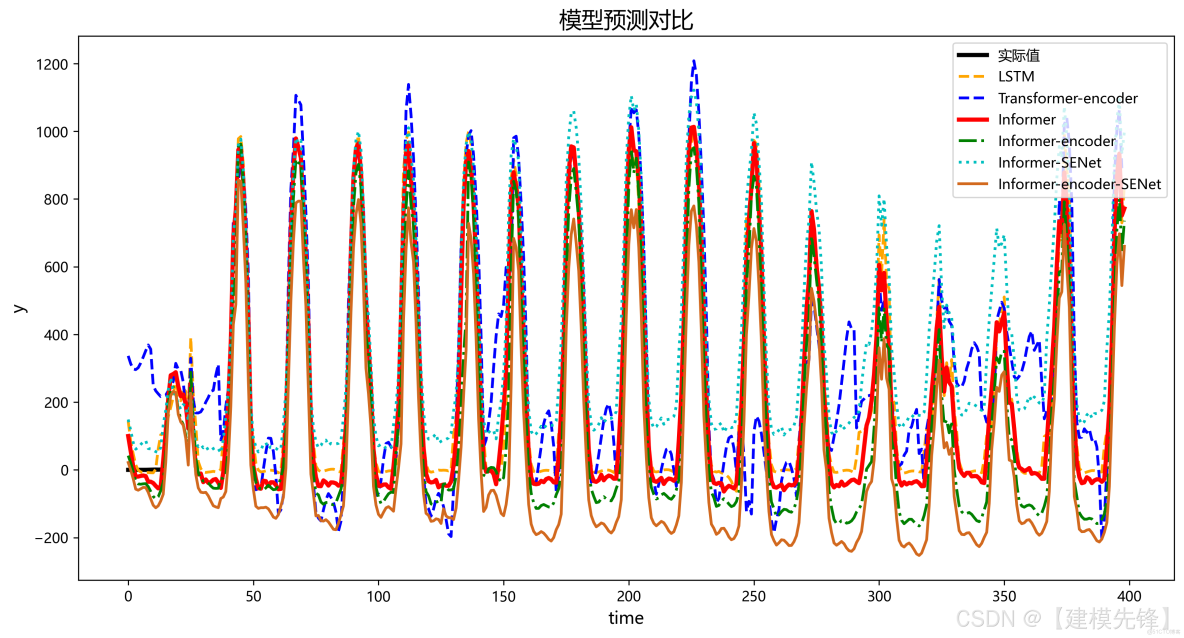
我們同時提供詳細的資料、解説文檔和視頻講解,包括如何替換自己的數據集、參數調整教程,預測任務的替換等,代碼逐行註釋,參數介紹詳細!
● 數據集:某光伏電站發電功率數據集(適用多特徵數據集)
● 環境框架:python 3.9 pytorch 2.1 及其以上版本均可運行
● 模型實驗:6組對比模型的完整實驗!
● 使用對象:論文需求、畢業設計需求者
● 代碼保證:代碼註釋詳細、即拿即可跑通。
2 模型創新點介紹
深度學習模型如LSTM和Transformer在時間序列預測中取得了顯著進展。LSTM能夠捕獲序列中的長期依賴關係,而Transformer通過注意力機制有效處理序列數據。Informer是一種專為長序列預測設計的高效Transformer變體,其通過稀疏注意力機制提高效率。SENet能夠通過自適應特徵重校準機制,增強深度網絡的特徵提取能力。
1.1 時序特徵捕捉與建模
使用Informer來捕捉長時間信號時序依賴特徵
- 長時間序列處理:傳統的RNN和LSTM等方法在處理長時間序列時存在計算效率低、梯度消失等問題。Informer通過改進Transformer架構,使用ProbSparse Self-Attention機制,有效地提高了計算效率,特別是對於長時間序列數據。
- 全局特徵提取:通過多頭注意力機制,Informer能夠捕捉序列數據中的全局特徵和長時間依賴關係,確保對時序特徵進行全面建模。

1.2 概率稀疏注意力機制(ProbSparse Self-attention)
概率稀疏自注意力是Informer模型中引入的一種稀疏自注意力機制。其核心思想是通過概率方法選擇最重要的一部分注意力權重進行計算,而忽略那些對結果影響較小的權重。這種方法能夠顯著降低計算複雜度,同時保持較高的模型性能。
- 稀疏自注意力:不同於標準 Transformer 的密集自注意力機制,Informer 引入了 ProbSparse Self-attention,通過概率抽樣機制選擇重要的 Q-K 對進行計算,減少了計算複雜度。
- 效率提升:稀疏注意力機制顯著降低了計算複雜度,從 O(L2⋅d) 降低到 O(L⋅log(L)⋅d),其中 L 是序列長度,d 是每個時間步的特徵維度。
1.3 多尺度特徵提取-信息蒸餾
Informer的架構圖並沒有像Transformer一樣在Encoder的左邊標註來表示N個Encoder的堆疊,而是一大一小兩個梯形。橫向看完單個Encoder(也就是架構圖中左邊的大梯形,是整個輸入序列的主堆棧)。
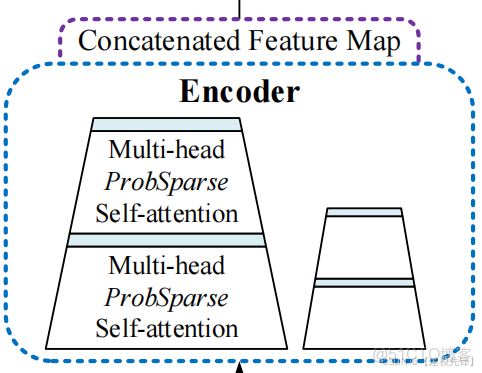
Encoder的作用是Self-attention Distilling,由於ProbSparse自相關機制有很多都是用V的mean填充的,所以天然就存在冗餘的attention sorce ,因此在相鄰的Attention Block之間應用卷積與池化來對特徵進行下采樣,所以作者在設計Encoder時,採用蒸餾的操作不斷抽取重點特徵,從而得到值得重點關注的特徵圖。

- 多尺度時間序列特徵提取:Informer 通過多尺度的方式對不同時間粒度的特徵進行建模,可以更好地捕捉時間序列中的多尺度依賴關係。
- 信息蒸餾:引入了信息蒸餾機制,通過層次化的時間卷積池化層逐步縮減時間步長,提取不同尺度的特徵,實現長時間依賴的高效建模。
- 卷積降維:在編碼器中使用1D卷積池化層進行降維,步長為2,使得序列長度減半,進一步減少計算複雜度。
- 信息壓縮:通過卷積池化層進行信息壓縮,將長序列信息濃縮到較短的時間步長中,從而更高效地進行時序建模。
1.4 特徵增強與融合
Informer結合SENet進行特徵增強
- 自適應特徵校準:SENet通過Squeeze-and-Excitation模塊,對每個通道的特徵進行自適應權重調整,增強重要特徵,抑制無關或冗餘特徵。這種機制可以提升模型對故障信號關鍵特徵的敏感度,提高故障診斷的準確性。
- 通道間依賴建模:SENet能夠捕捉不同通道特徵之間的關係,通過重新校準特徵通道的權重,使得模型能夠更加有效地融合多通道信息,提升整體特徵表達能力。
將Informer與SENet結合,利用Informer的長序列建模能力和SENet的特徵重校準能力,實現對光伏發電功率的精確預測。
1.5 時間編碼
Informer在原始向量上不止增加了Transformer架構必備的PositionEmbedding(位置編碼)還增加了與時間相關的各種編碼:
- 日週期編碼:表示一天中的時間點。
- 週週期編碼:表示一週中的時間點。
- 月週期編碼:表示一個月中的時間點。
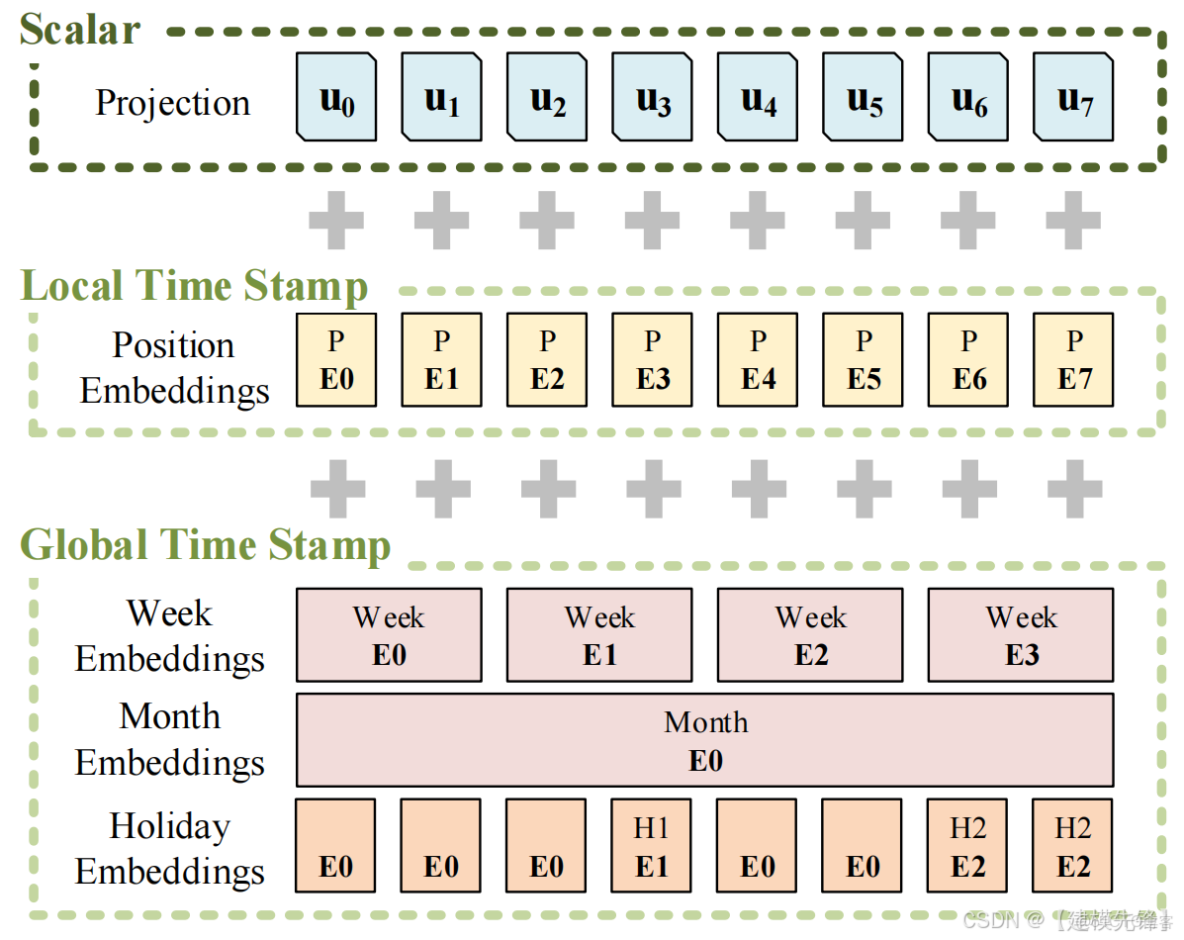
在 LSTF 問題中,捕獲遠程獨立性的能力需要全局信息,例如分層時間戳(周、月和年)和不可知時間戳(假期、事件)。
更多詳細內容參考講解視頻!
3 數據集製作可視化
光伏發電作為可再生能源的重要組成部分,其發電功率的精確預測對於電力系統的調度優化和可再生能源的高效利用至關重要。
3.1 導入數據
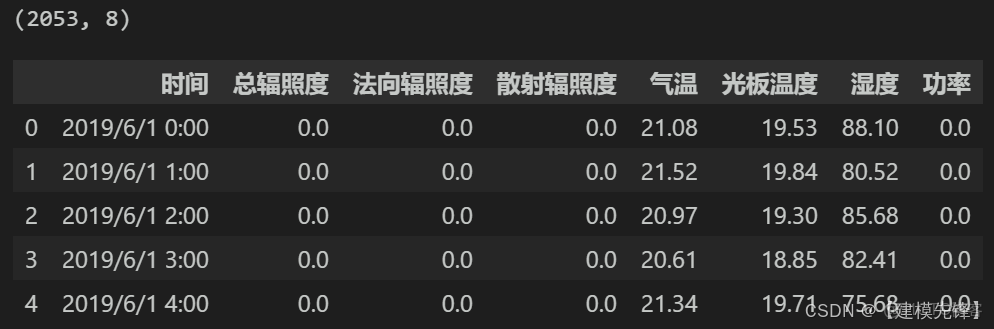
光伏電站發電功率數據集一共2053個樣本,8個特徵,可視化如下:

3.2 其它數據集介紹

3.3 數據集製作與預處理
詳細介紹見提供的文檔
4 基於 Informer-SENet的預測模型
4.1 定義Informer-SENet預測網絡模型
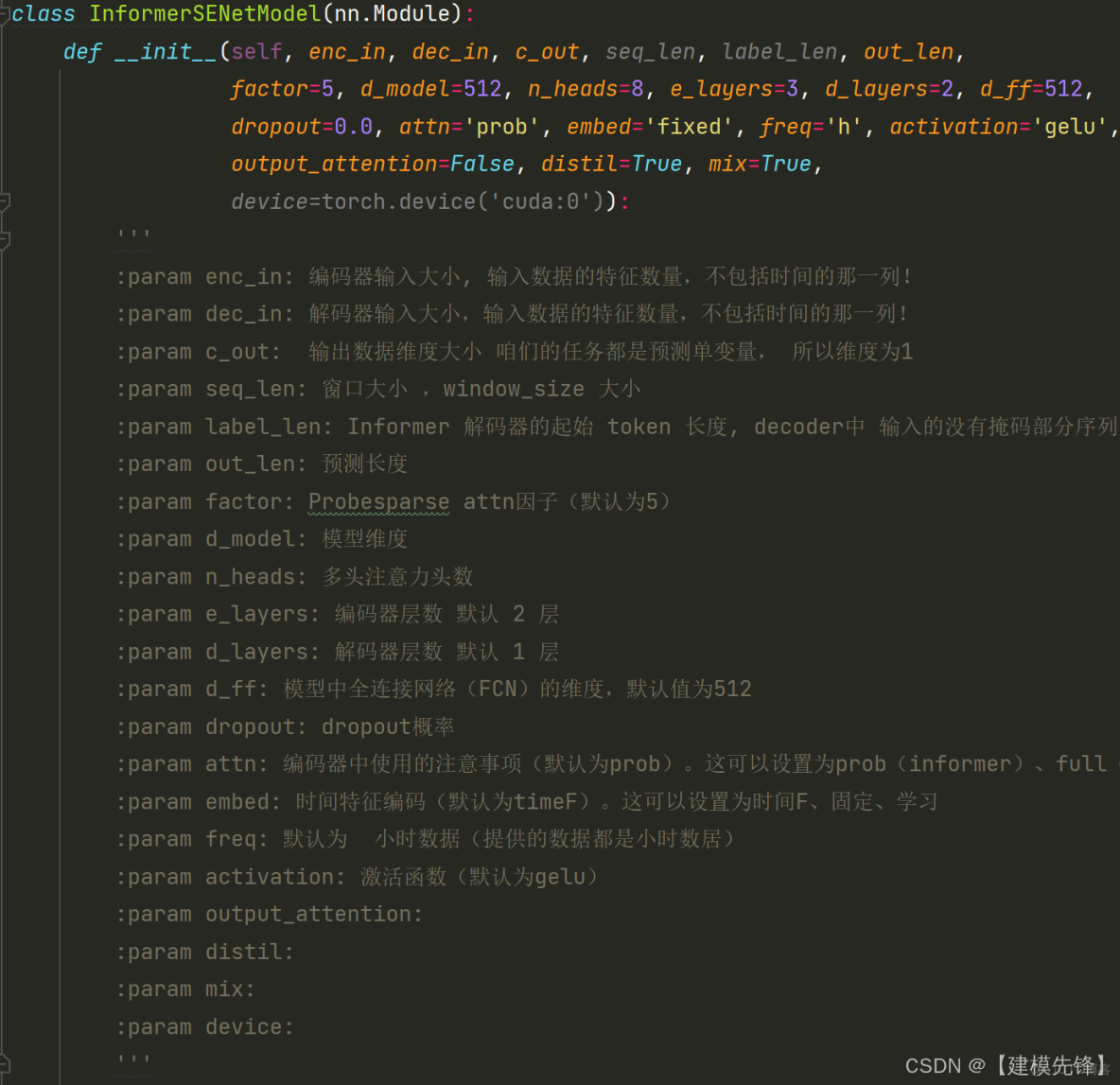
4.2 設置參數,訓練模型
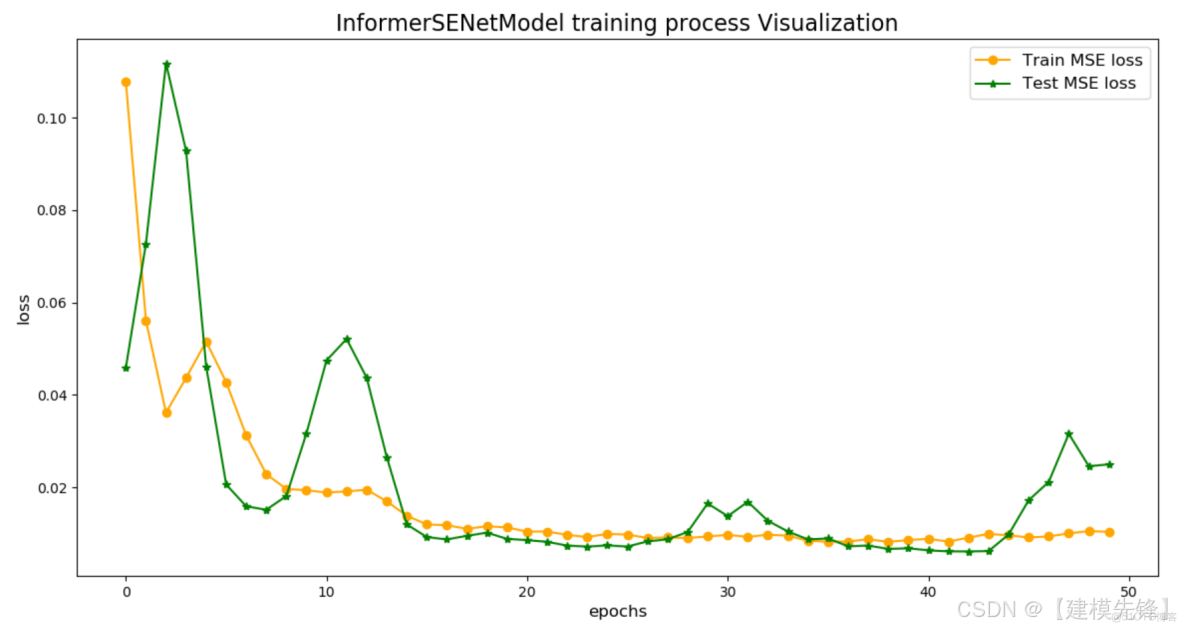
4.3 6組模型預測對比可視化
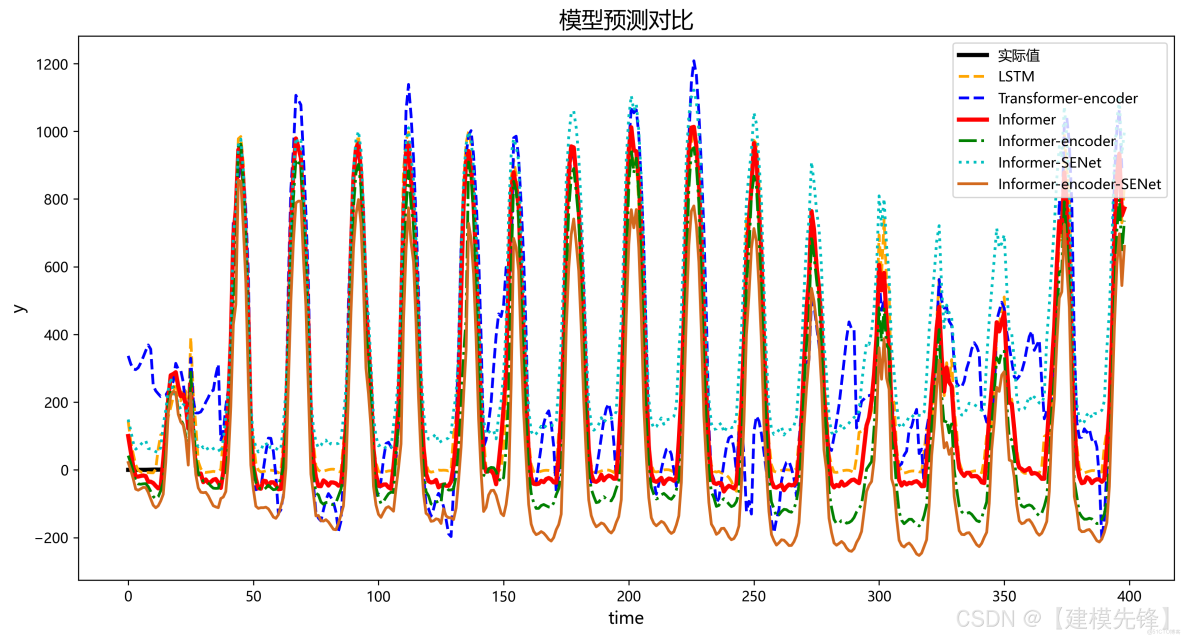
我們精心推出的Informer-SENet對比實驗合集,深入探討了六組模型的性能:LSTM、Transformer-encoder、Informer、Informer-encoder、Informer-SENet以及Informer-encoder-SENet。
每個模型都經過嚴格的實驗驗證,涵蓋了從基礎到複雜的預測方法,幫助您全面瞭解不同技術在時間序列預測中的應用效果。我們的實驗數據涵蓋多個評價指標,包括MAE、RMSE和MAPE,確保您能從多角度分析模型的優劣勢。
此外,合集提供詳細的實驗設置和參數調整指南,使得研究者能夠輕鬆復現實驗結果。無論你是希望提升模型預測精度,還是探索新興技術組合的研究者,這套實驗合集都將成為您不可或缺的資源。