
一.strlen實現
str的原理:它的作用是計算字符串長度,根據這個知識我們來寫代碼吧。
int MyStrlen(const char* s)
{
int count = 0;//用於計算長度
while(*s != '\0')
{
count++;
s++;
}
return count;
}其實strlen的模仿是比較簡單的,只要死抓strlen是以'\0'結尾的即可,下面我用圖帶着大家理解一下吧。
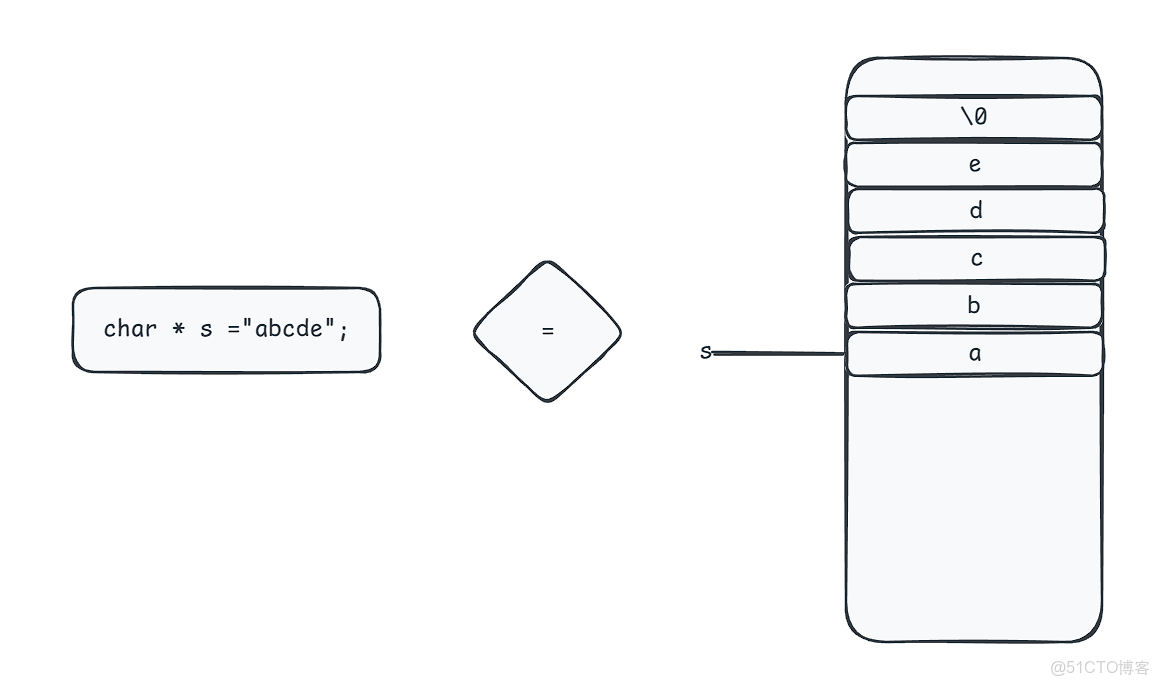
其實就是這樣的,s每次++其實就是往上移動一格,直到碰到'/0'才會停止,我們就輕鬆搞定了strlen的模擬實現。
二.strcpy
strcpy的原理:將源字符串 src(包括結束符 '\0')複製到目標地址 dest 指向的內存空間中。
strcpy(char* dest,char* src)根據strcpy的定義其實也能清楚它到底要幹嘛,將src拷到dest你可以理成把src的字符一個一個拷到dest即可。
下面我們就來實現它吧!
char* strcpy(char* des, const char* src)
{
assert(des != NULL);//看是不是NULL
assert(src != NULL);
char* str = des;//保留des用於返回
while (*src != '\0')
{
*str = *src;
str++;
src++;
}
*str = '\0';
return des;
} 但是這個代碼其實是有槽點的很且很不安全,下面我們用圖來分析這個槽點是什麼
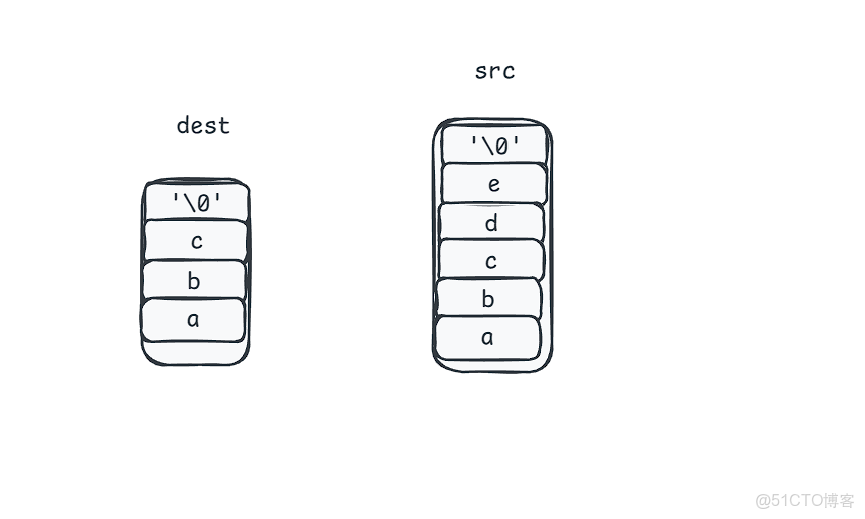
你發現了沒,如果真的要把src內容全部塞給dest那麼就會導致dest訪問越界,這也C語言中strcpy的一個安全隱患
三.strcmp
strcmp的原理:按字典順序依次比較兩個字符串的字符大小(即:從第一個字符開始依次往下比)前者大返回一個任意整數(我將用1代替)相等返回0,後者大返回任意一個負數(我用-1代替)
int strcmp(const char* str1, const char* str2)
{
assert(str1);
assert(str2);
const char* s1 = str1;
const char* s2 = str2;
while (*s1 != '\0' && *s2 != '\0')
{
if (*s1 > *s2)
{
return 1;
}
else if (*s1 < *s2)
{
return -1;
}
else
{
s1++;
s2++;
}
}
if (*s1 == '\0' && *s2 =='\0')
{
return 0;
}
else if (*s1 != '\0')
{
return 1;
}
else
{
return -1;
}
}循環終止時,結果只能是1或-1,因為此時字符比較已出現差異。若循環未終止,則存在三種可能情況:前者字符串到達終止符'\0'、後者字符串到達'\0',或雙方同時到達'\0'。
四.strstr
strstr的原理:在一個字符串(主串)中找另一個字符串(子串)首次出現的位置
char* strstr(const char* str1, const char* str2)
{
assert(str1 != NULL);
assert(str2 != NULL);
if (!*str2)
return((char*)str1);//這裏強轉是因為C的一個特殊的情況,就是參數是const char*返回的確實char*
const char* cp = str1;
const char* s1, * s2;
while (*cp)
{
s1 = cp;
s2 = str2;
while (*s1 == *s2 && *s2 != '\0')
{
s1++;
s2++;
}
if(*s2 == '\0' )
return (char*)cp;
cp++;
}
return(NULL);
}防止野指針與空字符串處理
assert用於確保str1和str2非空指針,避免野指針問題。若str2為空字符串,直接返回str1,因為空串是任何字符串的子串。
循環核心邏輯
外層循環通過cp遍歷str1的每個字符作為匹配起點。內層循環通過s1和s2同步移動比較字符,若完全匹配(*s2 == '\0'),則返回當前cp的位置。若中途不匹配,則外層循環跳到下一個字符重新開始匹配。
可優化點説明
- 循環邊界優化
外層循環可限制為strlen(str1) >= strlen(str2)的情況,避免無效比較。例如str1="ab"與str2="abc"無需比較。 - 兩層循環的必要性
以str1="bbac"和str2="bac"為例:
- 第一次從
str1的第一個'b'開始匹配,內層比較到第二個字符'b' != 'a'失敗。 - 外層循環跳到第二個
'b'重新匹配,此時內層完整匹配"bac",返回正確結果。
- 終止條件
*s2 != '\0'的作用
防止比較越界。例如str1="abc\0xxx"和str2="abc",當s2指向'\0'時匹配成功,若未檢查可能導致s1和s2繼續向後訪問,引發越界。
五.memcpy
memcpy的原理:其核心是按字節,逐個複製內存數據,不關心數據的類型(因此是 “內存拷貝”)
//des:目的地,src:來源,count:拷貝幾個字節
void* memcpy1(void* dst, const void* src, size_t count)
{
assert(dst);
assert(src);
char* s1 = (char*)dst;
char* s2 = (const char*)src;
while (count--)
{
*s1 = *s2;
s1++;
s2++;
}
return dst;
}其實memcpy和strcpy原理都是差不多的,不過memcpy要實現的是任意類型,而strcpy只能實現字符類型,其實要理解這個代碼只需要認識內存即可,下面我通過一張圖來展示
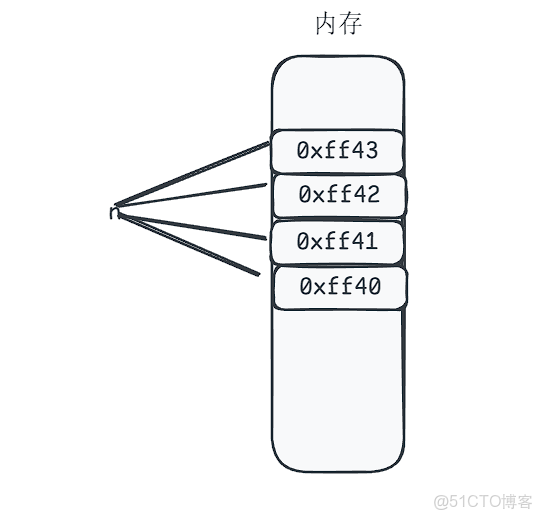
這裏我們以整數類型為例(int n = 4)。整數類型在內存中佔4個字節空間,其地址取最低位的那個字節地址。只要保證這4個字節空間連續存儲即可。接下來我們重點討論內存移動的問題。
為什麼使用void指針?可以將其理解為無類型屬性(就像五行中的"無"),而其他類型都有特定屬性(金、木、水、火、土)。要實現所有類型的拷貝,就需要一個能承載各種類型的通用載體,void*(無類型)顯然是最合適的選擇。
但為什麼又要轉為char類型呢?因為void*不能直接解引用操作,只能作為載體使用。選擇char類型是因為:char類型大小為1字節,因此char指針每次移動1字節這樣就能確保精確控制內存移動。如果使用short(每次移動2字節),就無法正確處理char類型數據(1字節),會導致產生垃圾數據。
理解了這些,memcpy的工作原理就清晰了。相信聰明的你已經明白了其中的原理。
但是這個代碼是可能有問題的,至於什麼問題下面我用圖來展示。
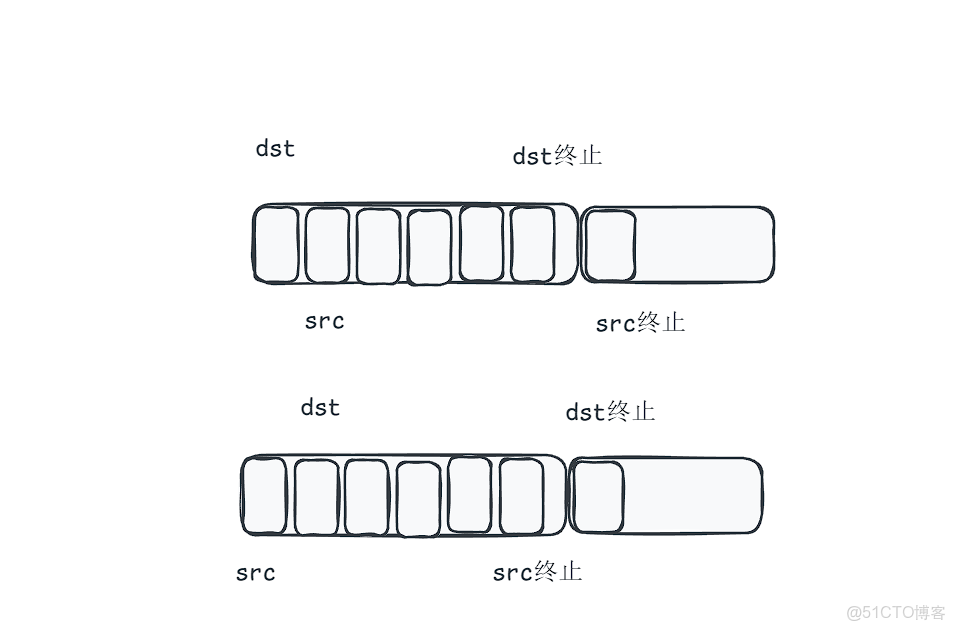
你看第一張圖是符合memcpy(不會出現問題)但是你看第二張圖很明顯出了問題,為什麼呢?
其實我們根據代碼可以知道,我們是用src取賦值給dst,但是如果你dst在src前面就會導致一個問題,我src把第一格的內容給了dst(src下一格)那麼我在取下一格不就是src上一格的內容嗎,因此就會導致問題,而這個問題就叫內存重疊。
我們知道了memcpy當dst在src前面的時候會出現內存重疊,但是在前面多少不會出現內存重疊呢?
其實就是保證dst不會觸碰到src的地址,即dst起點>src終點。
六.memmove
memmove的出現就是為了解決內存重疊的問題的
void* memmove(void* dst, const void* src, size_t count)
{
void* ret = dst;
char* dst1 = (char*)dst;
const char* src1 = (const char*)src;
if (dst1 < src1 || dst1 > src1 + count)//確保元素修改後不在使用
{
while (count--)
{
*dst1 = *src1;
dst1 ++;
src1 ++;
}
}
else
{
dst1 = dst1 + count - 1;
src1 = src1 + count - 1;
while (count--)
{
*dst1 = *src1;
dst1 --;
src1 --;
}
}
return ret;
}從代碼中可以看出,memmove 的解決方案體現在 else 語句塊中。讓我們分析這段代碼的具體作用吧。
memcpy 之所以會出現內存重疊問題,是因為 src 可能將自身資源複製到 src+n 的位置。這樣後續操作時,src 可能會再次訪問這個位置。要解決這個問題,關鍵在於避免 src 將資源複製到自己將要訪問的位置。
解決方案很簡單:讓 src 把已複製的內容全部放在目標位置之後。這樣就能確保 src 不會重複處理同一個內容。
這次我講的是面試高頻率考的函數實現,希望能給大家帶來幫助,如果有誤可以評論我,我們抓緊修改的,希望能大家一起進步,我的一些解釋採用了AI潤色,希望和它的幫助下能給大家帶來簡潔明瞭的解釋