
因特殊業務場景,如大促、秒殺活動與突發熱點事情等業務流量在短時間內劇增,形成巨大的流量毛刺,數據流入的速度遠高於數據處理的速度,對流處理系統構成巨大的負載壓力,如果不能正確處理,可能導致集羣資源耗盡最終集羣崩潰,因此有效的反壓機制(backpressure)對保障流處理系統的穩定至關重要。
Storm和Spark Streaming都提供了反壓機制,實現各不相同
對於開啓了acker機制的storm程序,可以通過設置conf.setMaxSpoutPending參數來實現反壓效果,如果下游組件(bolt)處理速度跟不上導致spout發送的tuple沒有及時確認的數超過了參數設定的值,spout會停止發送數據,這種方式的缺點是很難調優conf.setMaxSpoutPending參數的設置以達到最好的反壓效果,設小了會導致吞吐上不去,設大了會導致worker OOM;有震盪,數據流會處於一個顛簸狀態,效果不如逐級反壓;另外對於關閉acker機制的程序無效;
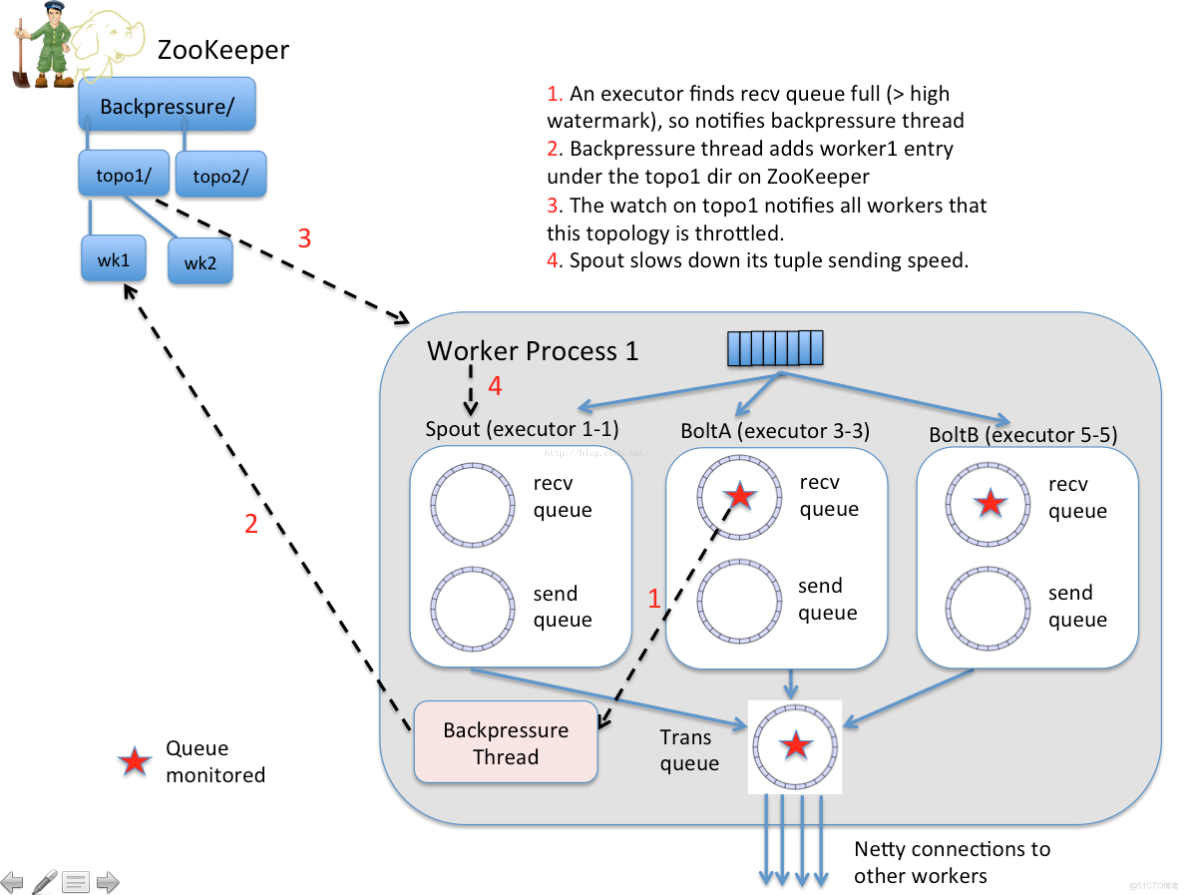
新的storm自動反壓機制(Automatic Back Pressure)通過監控bolt中的接收隊列的情況,當超過高水位值時專門的線程會將反壓信息寫到 Zookeeper ,Zookeeper上的watch會通知該拓撲的所有Worker都進入反壓狀態,最後Spout降低tuple發送的速度。具體實現:
Spark Streaming程序中當計算過程中出現batch processing time > batch interval的情況時,(其中batch processing time為實際計算一個批次花費時間,batch interval為Streaming應用設置的批處理間隔),意味着處理數據的速度小於接收數據的速度,如果這種情況持續過長的時間,會造成數據在內存中堆積,導致Receiver所在Executor內存溢出等問題(如果設置StorageLevel包含disk, 則內存存放不下的數據會溢寫至disk, 加大延遲),可以通過設置參數spark.streaming.receiver.maxRate來限制Receiver的數據接收速率,此舉雖然可以通過限制接收速率,來適配當前的處理能力,防止內存溢出,但也會引入其它問題。比如:producer數據生產高於maxRate,當前集羣處理能力也高於maxRate,這就會造成資源利用率下降等問題。為了更好的協調數據接收速率與資源處理能力,Spark Streaming 從v1.5開始引入反壓機制(back-pressure),通過動態控制數據接收速率來適配集羣數據處理能力
Spark Streaming Backpressure: 根據JobScheduler反饋作業的執行信息來動態調整Receiver數據接收率。通過屬性"spark.streaming.backpressure.enabled"來控制是否啓用backpressure機制,默認值false,即不啓用
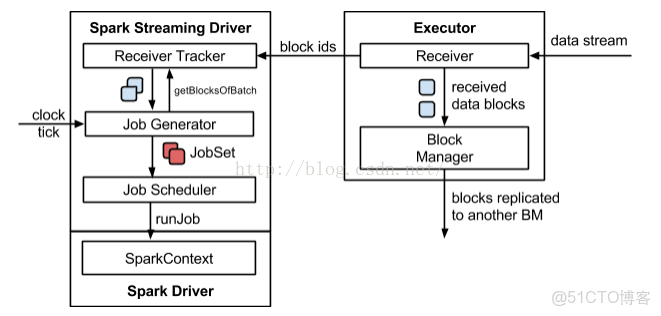
Streaming架構如下圖所示:
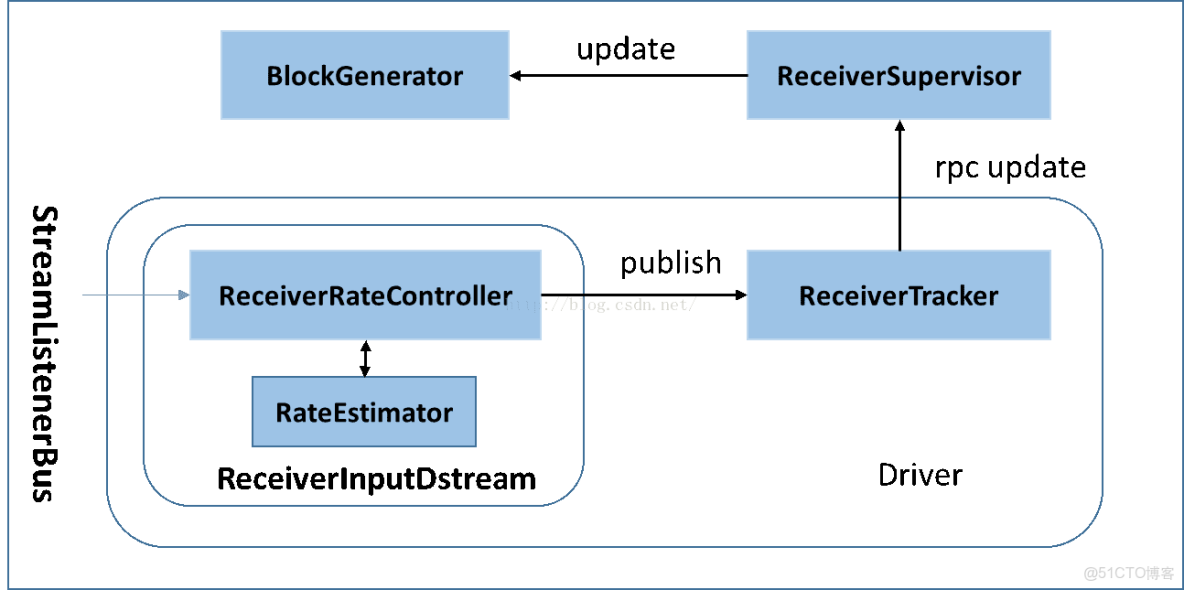
BackPressure執行過程如下圖所示:
本文轉至:
3.1 RateController類體系
RatenController 繼承自StreamingListener. 用於處理BatchCompleted事件。核心代碼為:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 |
|
3.2 RateController的註冊
JobScheduler啓動時會抽取在DStreamGraph中註冊的所有InputDstream中的rateController,並向ListenerBus註冊監聽. 此部分代碼如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 |
|
3.3 BackPressure執行過程分析
BackPressure 執行過程分為BatchCompleted事件觸發時機和事件處理兩個過程
3.3.1 BatchCompleted觸發過程
對BatchedCompleted的分析,應該從JobGenerator入手,因為BatchedCompleted是批次處理結束的標誌,也就是JobGenerator產生的作業執行完成時觸發的,因此進行作業執行分析。
Streaming 應用中JobGenerator每個Batch Interval都會為應用中的每個Output Stream建立一個Job, 該批次中的所有Job組成一個Job Set.使用JobScheduler的submitJobSet進行批量Job提交。此部分代碼結構如下所示
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 |
|
其中,sumitJobSet會創建固定數量的後台線程(具體由“spark.streaming.concurrentJobs”指定),去處理Job Set中的Job. 具體實現邏輯為:
|
1
2
3
4
5
6
7
8
9
10 |
|
其中JobHandler用於執行Job及處理Job執行結果信息。當Job執行完成時會產生JobCompleted事件. JobHandler的具體邏輯如下面代碼所示:
+ View Code
當Job執行完成時,向eventLoop發送JobCompleted事件。EventLoop事件處理器接到JobCompleted事件後將調用handleJobCompletion 來處理Job完成事件。handleJobCompletion使用Job執行信息創建StreamingListenerBatchCompleted事件並通過StreamingListenerBus向監聽器發送。實現如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 |
|
3.3.2、BatchCompleted事件處理過程
StreamingListenerBus將事件轉交給具體的StreamingListener,因此BatchCompleted將交由RateController進行處理。RateController接到BatchCompleted事件後將調用onBatchCompleted對事件進行處理。
|
1
2
3
4
5
6
7
8
9
10 |
|
onBatchCompleted會從完成的任務中抽取任務的執行延遲和調度延遲,然後用這兩個參數用RateEstimator(目前存在唯一實現PIDRateEstimator,proportional-integral-derivative (PID) controller, PID控制器)估算出新的rate併發布。代碼如下:

/**
* Compute the new rate limit and publish it asynchronously.
*/
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}

其中publish()由RateController的子類ReceiverRateController來定義。具體邏輯如下(ReceiverInputDStream中定義):

/**
* A RateController that sends the new rate to receivers, via the receiver tracker.
*/
private[streaming] class ReceiverRateController(id: Int, estimator: RateEstimator)
extends RateController(id, estimator) {
override def publish(rate: Long): Unit =
ssc.scheduler.receiverTracker.sendRateUpdate(id, rate)
}

publish的功能為新生成的rate 藉助ReceiverTracker進行轉發。ReceiverTracker將rate包裝成UpdateReceiverRateLimit事交ReceiverTrackerEndpoint
|
1
2
3
4
5
6 |
|
ReceiverTrackerEndpoint接到消息後,其將會從receiverTrackingInfos列表中獲取Receiver註冊時使用的endpoint(實為ReceiverSupervisorImpl),再將rate包裝成UpdateLimit發送至endpoint.其接到信息後,使用updateRate更新BlockGenerators(RateLimiter子類),來計算出一個固定的令牌間隔。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 |
|
其中RateLimiter的updateRate實現如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 |
|
setRate的實現 如下:
|
1
2
3
4
5
6
7
8
9
10 |
|
到此,backpressure反壓機制調整rate結束。
4.流量控制點
當Receiver開始接收數據時,會通過supervisor.pushSingle()方法將接收的數據存入currentBuffer等待BlockGenerator定時將數據取走,包裝成block. 在將數據存放入currentBuffer之時,要獲取許可(令牌)。如果獲取到許可就可以將數據存入buffer, 否則將被阻塞,進而阻塞Receiver從數據源拉取數據。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 |
|
其令牌投放採用令牌桶機制進行, 原理如下圖所示:
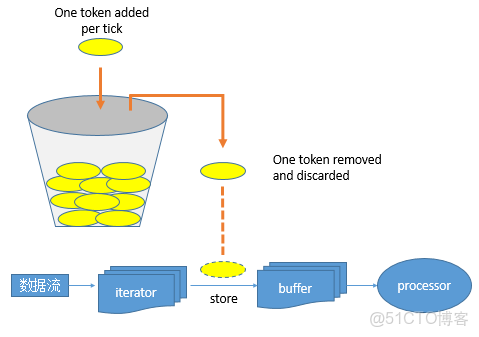
令牌桶機制: 大小固定的令牌桶可自行以恆定的速率源源不斷地產生令牌。如果令牌不被消耗,或者被消耗的速度小於產生的速度,令牌就會不斷地增多,直到把桶填滿。後面再產生的令牌就會從桶中溢出。最後桶中可以保存的最大令牌數永遠不會超過桶的大小。當進行某操作時需要令牌時會從令牌桶中取出相應的令牌數,如果獲取到則繼續操作,否則阻塞。用完之後不用放回。
Streaming 數據流被Receiver接收後,按行解析後存入iterator中。然後逐個存入Buffer,在存入buffer時會先獲取token,如果沒有token存在,則阻塞;如果獲取到則將數據存入buffer. 然後等價後續生成block操作。