
簡介
文章探討了RAG應用中文檔拆分與檢索的衝突問題,提出瞭解決方案:一是拆分子文檔塊並檢索父文檔塊,保留完整上下文;二是將文檔拆分為較大塊和小塊,索引小塊但檢索返回較大塊。文章詳細介紹了使用LangChain中的ParentDocumentRetriever實現這兩種策略的方法,並提供了代碼示例,幫助開發者優化檢索效果,平衡檢索準確性與上下文完整性。
一、拆分文檔與檢索的衝突
在 RAG 應用開發中,文檔拆分 和 文檔檢索 通常存在相互衝突的願望,例如:
- 我們可能希望擁有小型文檔,以便它們的嵌入可以最準確地反映它們的含義,如果太長,嵌入/向量沒法記錄太多文本特徵。
- 但是又希望文檔足夠長,這樣能保留每個塊的上下文。
這個時候就可以考慮通過拆分子文檔塊,檢索 父文檔塊的策略來實現這種平衡,即在檢索中,首先獲取小塊,然後再根據小塊元數據中存儲的 id,使用 id 來查找這些塊的父文檔,並返回那些更大的文檔,該策略適合一些不是特別能拆分的文檔,或者是文檔上下文關聯性很強的場景。
請注意,這裏的“父文檔”指的是小塊來源的文檔,可以是整個原始文檔,也可以是切割後比較大的文檔塊。
子文檔->父文檔的運行流程也非常簡單,其實和 多向量檢索器 一模一樣,如下:
在這裏插入圖片描述
除了使用 MultiVectorRetriever 來實現該運行流程,在 LangChain 中,還封裝了ParentDocumentRetriever,可以更加便捷地完成該功能,使用技巧也非常簡單,傳遞 向量數據庫、文檔數據庫 和 子文檔分割器 即可。
代碼示例:
import dotenvimport weaviatefrom langchain.retrievers import ParentDocumentRetrieverfrom langchain.storage import LocalFileStorefrom langchain_community.document_loaders import UnstructuredFileLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_weaviate import WeaviateVectorStorefrom weaviate.auth import AuthApiKeydotenv.load_dotenv()# 1.創建加載器與文檔列表,並加載文檔loaders = [ UnstructuredFileLoader("./電商產品數據.txt"), UnstructuredFileLoader("./項目API文檔.md"),]docs = []for loader in loaders: docs.extend(loader.load())# 2.創建文本分割器text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50,)# 3.創建向量數據庫與文檔數據庫vector_store = WeaviateVectorStore( client=weaviate.connect_to_wcs( cluster_url="https://mbakeruerziae6psyex7ng.c0.us-west3.gcp.weaviate.cloud", auth_credentials=AuthApiKey("xxxxxxxxxxxxxxxxxxxxxxxxxxxx"), ), index_name="ParentDocument", text_key="text", embedding=OpenAIEmbeddings(model="text-embedding-3-small"),)store = LocalFileStore("./parent-document")# 4.創建父文檔檢索器retriever = ParentDocumentRetriever( vectorstore=vector_store, byte_store=store, child_splitter=text_splitter,)# 5.添加文檔retriever.add_documents(docs, ids=None)# 6.檢索並返回內容search_docs = retriever.invoke("分享關於LLMOps的一些應用配置")print(search_docs)print(len(search_docs))輸出內容會返回完整的文檔片段,而不是拆分後的片段(但是在向量數據庫中存儲的是分割後的片段)
[Document(metadata={'source': './項目API文檔.md'}, page_content='LLMOps 項目 API 文檔\n\n應用 API 接口統一以 JSON 格式返回,並且包含 3 個字段:code、data 和 message,分別代表業務狀態碼、業務數據和接口附加信息。\n\n業務狀態碼共有 6 種,其中只有 success(成功) 代表業務操作成功,其他 5 種狀態均代表失敗,並且失敗時會附加相關的信息:fail(通用失敗)、not_found(未找到)、unauthorized(未授權)、forbidden(無權限)和validate_error(數據驗證失敗)。\n\n接口示例:\n\njson\n{\n "code": "success",\n "data": {\n "redirect_url": "https://github.com/login/oauth/authorize?client_id=f69102c6b97d90d69768&redirect_uri=http%3A%2F%2Flocalhost%3A5001%2Foauth%2Fauthorize%2Fgithub&scope=user%3Aemail"\n },\n "message":...')]二、父文檔檢索器檢索較大塊
在上面的示例中,我們使用拆分的文檔塊檢索數據原文檔,但是有時候完整文檔可能太大,我們不希望按原樣檢索它們。在這種情況下,我們真正想要做的是先將原始文檔拆分成較大的塊(例如 1000-2000 個 Token),然後將其拆分為較小塊,接下來索引較小塊,但是檢索時返回較大塊(非原文檔)。
運行流程變更如下
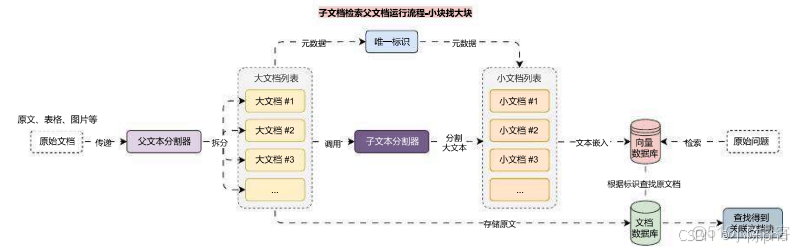
在這裏插入圖片描述
在 ParentDocumentRetriever 中,只需要傳遞多一個 父文檔分割器 即可,其他流程無需任何變化,更新後的部分代碼如下
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)child_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)retriever = ParentDocumentRetriever( vectorstore=vector_store, byte_store=store, parent_splitter=parent_splitter, child_splitter=child_splitter,)本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。