
本博文的主要內容:
1、Hash Shuffle徹底解密
2、Shuffle Pluggable解密
3、Sorted Shuffle解密
4、Shuffle性能優化
一:到底什麼是Shuffle?
Shuffle中文翻譯為“洗牌”,需要Shuffle的關鍵性原因是某種具有共同特徵的數據需要最終匯聚到一個計算節點上進行計算。
二:Shuffle可能面臨的問題?
運行Task的時候才會產生Shuffle(Shuffle已經融化在Spark的算子中了)。
1、 數據量非常大;【幾千甚至上萬台機器進行Shuffle的數據量會很大,從其他各台機器上收集過來數據的時候,網絡傳輸量會很恐怖】
2、 數據如何分類,即如何Partition,Hash、Sort、鎢絲計算;【不同的Partition的不同實現,他會影響集羣規模的大小,會影響內存的使用,會影響性能等等方面,也就有了Shuffle幾個不同的淨化階段】
3、 負載均衡(數據傾斜);【因為採用不同的Shuffle的方式對數據進行不同的分類,而分類之後數據又分到不同的節點上進行計算,如果Shuffle分類不恰當,會導致負載均衡,也就是數據傾斜】
4、 網絡傳輸效率,需要在壓縮和解壓縮之間做出權衡,序列化和反序列也是要考慮的問題;【如果壓縮,則需要解壓縮,解壓縮需要消耗CPU,所以需要衡量帶寬和CPU解壓的時間,做出正確的權衡】
説明:具體的Task進行計算的時候盡一切最大可能使得數據具備Process Locality的特性
【因為這是它運行最快的方式,數據在內存中,也就是默認採取的方式,如果迫不得已,數據不能全部放在內存中,從實際生成角度講(即不具備內存本地性)】;退而求次是增加數據分片,減少每個Task處理的數據量
【導致任務運行的批次更多,任務更多】。
【1,cache本身具有風險,Memory溢出風險,它被其他計算佔用掉內存的風險,導致重新計算,除非計算特別複雜,計算鏈條特別長,可能有必要為了容錯,為了再次數據複用,來進行中間結果的持久化,否則的話,尤其是持久化到disk時,還不如在內存中直接計算,這樣的速度有可能比從磁盤中讀取曾經計算結果來的更快2,度磁盤I/O是一個高風險的動作,讀內存分享會降低很多。
在一個Stage內部,不持久化中間結果,數據丟失重新計算依賴的RDD;但是在產生Shuffle的時候,會產生網絡通信,這是需要持久化。
持久化默認情況下放在磁盤中,也可以調整Spark的框架,將數據放在內存中,現在一般放在Local FileSystem上面,也可以放在Tachyon中,這些都可以通過調整Spark的配置和改造Spark源碼來實現。】
三:Hash Shuffle徹底解密
1、key不能是Array;
【key如果是Array,則就無法非常友好的計算具體的hashcode值】
2、 Hash Shuffle不需要排序
【使得速度很快,其工作機制根據Shuffle的前面的Stage的最後一個final RDD,依據Partition把數據分成不同的類,按照Key的hashcode,然後按照一定的業務邏輯規則(例如,假如下一個Stage有3個並行任務,最簡單的就是取模3運算,分成3種類型的數據)無需排序,性能很好】,此時從理論上講就節省了Hadoop MapReduce中進行Shuffle需要排序時候的時間浪費,因為實際生產環境有大量的不需要排序的Shuffle類型;
思考:不需要排序的Hash Shuffle是否一定比需要排序的Sorted Shuffle速度更快?不一定!如果數據規模比較小的情形下,Hash Shuffle會比Sorted Shuffle速度快(很多)!但是如果數據量大,此時Sorted Shuffle一般都會比Hash Shuffle快(很多)
【數據量大的情況下,Sorted Shuffle比Hash Shuffle快的原因:如果數據規模比較 大,可能Hash Shuffle無法處理,因為hash的方式時會有key和句柄之類,還有許 多小文件,此時,磁盤的性能會成為瓶頸,內存也會變成瓶頸。Sorted Shuffle會極 大地節省磁盤、內存的訪問,更有利於更大規模的數據運算】
3、每個ShuffleMapTask會根據key的哈希值計算出當前的key需要寫入的Partition,然後把決定後的結果寫入當單獨的文件,此時會導致每個Task產生R(指下一個Stage的並行度)個文件,如果當前的Stage中有M個ShuffleMapTask,則會M*R個文件!!!
注意:Shuffle操作絕大多數情況下都要通過網絡,如果Mapper和Reducer在同一台機器上,此時只需要讀取本地磁盤即可。
【每個任務都產生R個小文件,由於其需要將數據分成幾種不同類型,就是下一個Stage的具體的Task會讀取的與自己相關的數據,因為已經分好類了,此時會產生M*R個小文件,那麼下一個Stage就會通過網絡根據Driver的註冊信息(由於上一個Stage寫過的內容會註冊給Driver),然後詢問Driver上一個Stage具體的輸出在哪裏,以及哪些屬於該Stage的部分,通過網絡讀取數據;同時Shuffle的數據不一定都需要通過網絡(有可能在同一台機器上)】
Hash Shuffle的兩大死穴:第一:Shuffle前會產生海量的小文件於磁盤之上,此時會產生大量耗時低效的IO操作;第二:內存不共用!!!由於內存中需要保存海量的文件操作句柄和臨時緩存信息,如果數據處理規模比較龐大的話,內存不可承受,出現OOM等問題!
Hash-based Shuffle另一説法
1、 Spark Shuffle在最開始的時候只支持Hash-based Shuffle:默認Mapper階段會為Reducer階段的每一個Task單獨創建一個文件來保存該Task中要使用的數據。
優點:就是操作數據簡單。
缺點:但是在一些情況下(例如數據量非常大的情況)會造成大量文件(M*R,其中M代表Mapper中的所有的並行任務數量,R代表Reducer中所有的並行任務數據)大數據的隨機磁盤I/O操作且會形成大量的Memory(極易造成OOM)。
2、Hash-based Shuffle產生的問題:
第一:不能夠處理大規模的數據
第二:Spark不能夠運行在大規模的分佈式集羣上!
3、Consolidate機制:
後來的改善是加入了Consolidate機制來將Shuffle時候產生的文件數量減少到C*R個(C代表在Mapper端,同時能夠使用的cores數量,R代表Reducer中所有的並行任務數量)。但是此時如果Reducer端的並行數據分片過多的話則C*R可能已經過大,此時依舊沒有逃脱文件打開過多的厄運!!!Consolidate並沒有降低並行度,只是降低了臨時文件的數量,此時Mapper端的內存消耗就會變少,所以OOM也就會降低,另外一方面磁盤的性能也會變得更好。
Spark在引入Sort-Based Shuffle之前,適合中小型數據規模的大數據處理!
四: Sorted Shuffle解密
為了改善上述的問題(同時打開過多文件導致Writer Handler內存使用過大以及產生過度文件導致大量的隨機讀寫帶來的效率極為低下的磁盤IO操作),Spark後來推出了Consalidate機制,來把小文件合併【根據TaskId進行合併】,此時Shuffle時文件產生的數量為cores*R,對於ShuffleMapTask的數量明顯多於同時可用的並行Cores的數量的情況下,Shuffle產生的文件會大幅度減少,會極大降低OOM的可能;【consalidate機制減少了文件,同時也減少了文件句柄的數量;但對於並行度非常高時,及R值特別大時,還是很麻煩。】
【在接口ShuffleManager中:registerShuffle:由Driver註冊源數據中的信息,系統默認情況下其有HashBasedShuffle和SortedBasedShuffle兩種情況。getReader和getWriter:獲取怎麼在Shuffle的時候寫本地數據,獲取下一個Stage讀取上一個Stage的具體數據的閲讀器。unregisterShuffle:刪除掉本地的Shuffle的源數據。Stop:停止ShuffleManager】
為此Spark推出了Shuffle Pluggable開放框架,方便系統升級的時候定製Shuffle功能模塊,也方便第三方系統改造人員根據實際的業務場景來開放具體最佳的Shuffle模塊;核心接口ShuffleManager,具體默認實現有HashShuffleManager、SortShuffleManager等,Spark 1.6.0/Spark 1.5.2中具體的配置如下:
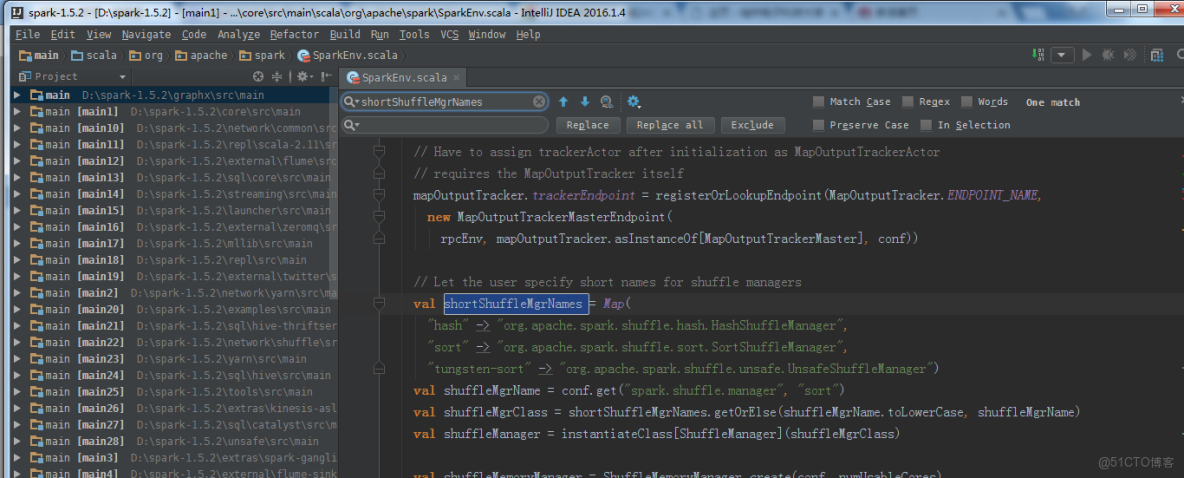
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.unsafe.UnsafeShuffleManager")默認採取SortedBasedShuffle的方式。
Sort是如何解決內存不夠、小文件過多的問題?
採用Hash的方式的適用場景是數據規模相對比較小,而且不需要排序。Hadoop的MapReduce進行排序,使得處理數據規模更大,集羣規模更大。
Consalidate一定程度上解決了該問題,但仍不徹底,SortedBasedShuffle更好的解決了該問題。首先,每個ShuffleMapTask不會為每個Reducer生成一個單獨的文件,它護肩所有的結果寫到一個文件裏,同時生成一個Index索引文件,每個Reducer可以根據這個Index索引文件取得它所需要處理的數據,這樣就避免產生大量文件,沒有了大量文件,也就沒有了大量的文件句柄,節省了內存;同時由於磁盤上文佳變少了,而且有Index索引,不用隨機的去讀寫,而是順序的disk I/O,帶來了低延遲,節省了內存;另一方面,減少了GC風險和頻率,而減少具體的文件數量可以避免同時些多個文件是給系統帶來的壓力,這就是優勢所在。
具體的實現:ShuffleMapTask會按照Key相應的Partition的ID進行Sort,如果屬於同一個Partition的Key,本身不進行Sort,因此對不需要sort的操作來説,如果內存不夠用,他就會把那些已經排序的內容寫到外部disk,結束的時候再進行歸併排序(merge-sort)
為高效讀取這些file Seagate,它有一個Index文件,會記錄不同的Partition的位置信息,BlockManager也會對它的尋址算法進行優化性的實現。歸併排序最優是打開10-100個文件。
最後生成文件時需要同時生成Index索引文件。
對具體的ShuffleMapTask,它外部有具體的歸併排序方式,mergeSort,sort之後會產生兩個文件,這兩個文件其中一個是Index索引文件,一個是存放具體的Task的輸出內容,在Reducer端讀取數據的時候,其實首先訪問Index,具體在工作的時候,BlockManager首先訪問Index,通過Index去定位具體文件內容。避免了大量文件句柄,節省內存。
採用Sort方式集羣的規模和數據的計算規模就不受限制了。
Sort-Based Shuffle的另一説法
1、為了讓Spark在更大規模的集羣上更高性能處理更大規模的數據,於是就引入了Sort-based Shuffle!從此以後(Spark1.1版本開始),Spark可以勝任任何規模(包括PB級別及PB以上的級別)的大數據的處理,尤其是鎢絲計劃的引入和優化,Spark更快速的在更大規模的集羣處理更海量的數據的能力推向了一個新的巔峯!
2、Spark1.6版本支持最少三種類型Shuffle:
實現ShuffleManager接口可以根據自己的業務實際需要最優化的使用自定義的Shuffle實現;
3、Spark1.6默認採用的就是Sort-based Shuffle的方式:
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")上述源碼説明,你可以在Spark配置文件中配置Spark框架運行時要使用的具體的ShuffleManager的實現。可以在conf/spark-default.conf加入如下內容:
spark.shuffle.manager SORT 配置Shuffle方式是SORT
4、 Sort-based Shuffle的工作方式如下:Shuffle的目的就是:數據分類,然後數據聚集
1) 首先每個ShuffleMapTask不會為每個Reducer單獨生成一個文件,相反,Sort-based Shuffle會把Mapper中每個ShuffleMapTask所有的輸出數據Data只寫到一個文件中。因為每個ShuffleMapTask中的數據會被分類,所以Sort-based Shuffle使用了index文件存儲具體ShuffleMapTask輸出數據在同一個Data文件中是如何分類的信息!!
2) 基於Sort-base的Shuffle會在Mapper中的每一個ShuffleMapTask中產生兩個文件:Data文件和Index文件,其中Data文件是存儲當前Task的Shuffle輸出的。而index文件中則存儲了Data文件中的數據通過Partitioner的分類信息,此時下一個階段的Stage中的Task就是根據這個Index文件獲取自己所要抓取的上一個Stage中的ShuffleMapTask產生的數據的,Reducer就是根據index文件來獲取屬於自己的數據。
涉及問題:Sorted-based Shuffle:會產生 2*M(M代表了Mapper階段中並行的Partition的總數量,其實就是ShuffleMapTask的總數量)個Shuffle臨時文件。
Shuffle產生的臨時文件的數量的變化一次為:
Basic Hash Shuffle: M*R;
Consalidate方式的Hash Shuffle: C*R;
Sort-based Shuffle: 2*M;
在集羣中動手實戰Sort-based Shuffle
在Sorted-based Shuffle中Reducer是如何獲取自己需要的數據呢?具體而言,Reducer首先找Driver去獲取父Stage中的ShuffleMapTask輸出的位置信息,根據位置信息獲取index文件,解析index,從解析的index文件中獲取Data文件中屬於自己的那部分內容;
Sorted-based Shuffle與排序沒有關係,Sorted-based Shuffle並沒有對內容進行排序,Sorted-based Shuffle是對Shuffle進行Sort,對我們具體要執行的內容沒有排序。
Reducer在什麼時候去fetch數據?
當parent Stage的所有ShuffleMapTasks結束後再fetch。等所有的ShuffleMapTask執行完之後,邊fetch邊計算。
通過動手實踐確實證明了Sort-based Shuffle產生了2M個文件。M是並行Task的數量。
Shuffle_0_0_0.data
shuffle_0_3_0.index
從上可以看出index文件和data文件數量是一樣的。
Sorted Shuffle Writer源碼:
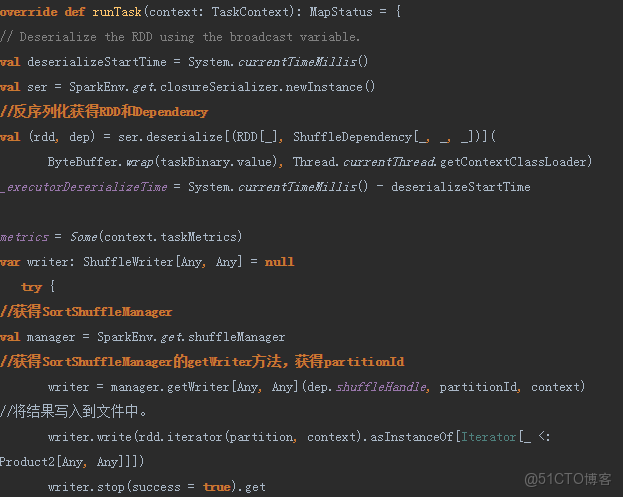
- ShuffleMapTask的runTask方法
反序列化RDD和Dependency
調用SortShuffleManager的getWriter方法。
Writer方法寫入結果。
2. SortShuffleManager複寫了ShuffleManager中的getWriter方法,源碼如下:

3. SorShuffleWriter的write方法源碼如下:
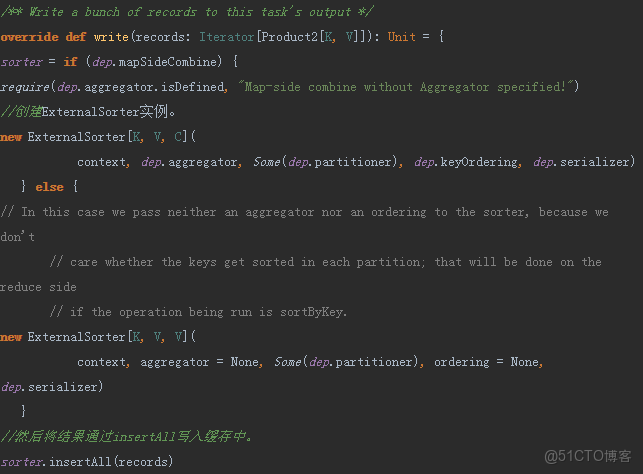

其中ShuffleBlockId記錄shuffleId和mapId獲得Block。

- 其中writeIndexFileAndCommit方法:
用於在Block的索引文件中記錄每個block的偏移量,其中getBlockData方法可以根據ShuffleId和mapId讀取索引文件,獲得前面partition計算之後,,將結果寫入文件中的偏移量和結果的大小。
/**
* Write an index file with the offsets of each block, plus a final offset at the end for the
* end of the output file. This will be used by getBlockData to figure out where each block
* begins and ends.
*
* It will commit the data and index file as an atomic operation, use the existing ones, or
* replace them with new ones.
*
* Note: the `lengths` will be updated to match the existing index file if use the existing ones.
* */
def writeIndexFileAndCommit(
shuffleId: Int,
mapId: Int,
lengths: Array[Long],
dataTmp: File): Unit = {
val indexFile = getIndexFile(shuffleId, mapId)
val indexTmp = Utils.tempFileWith(indexFile)
val out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(indexTmp)))
Utils.tryWithSafeFinally {
// We take in lengths of each block, need to convert it to offsets.
var offset = 0L
out.writeLong(offset)
for (length <- lengths) {
offset += length
out.writeLong(offset)
}
} {
out.close()
}
val dataFile = getDataFile(shuffleId, mapId)
// There is only one IndexShuffleBlockResolver per executor, this synchronization make sure
// the following check and rename are atomic.
synchronized {
val existingLengths = checkIndexAndDataFile(indexFile, dataFile, lengths.length)
if (existingLengths != null) {
// Another attempt for the same task has already written our map outputs successfully,
// so just use the existing partition lengths and delete our temporary map outputs.
System.arraycopy(existingLengths, 0, lengths, 0, lengths.length)
if (dataTmp != null && dataTmp.exists()) {
dataTmp.delete()
}
indexTmp.delete()
} else {
// This is the first successful attempt in writing the map outputs for this task,
// so override any existing index and data files with the ones we wrote.
if (indexFile.exists()) {
indexFile.delete()
}
if (dataFile.exists()) {
dataFile.delete()
}
if (!indexTmp.renameTo(indexFile)) {
throw new IOException("fail to rename file " + indexTmp + " to " + indexFile)
}
if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) {
默認Sort-based Shuffle的幾個缺陷:
- 如果Mapper中Task的數量過大,依舊會產生很多小文件,此時在Shuffle傳遞數據的過程中到Reducer端,reduce會需要同時打開大量的記錄來進行反序列化,導致大量的內存消耗和GC的巨大負擔,造成系統緩慢甚至崩潰!
2.如果需要在分片內也進行排序的話,此時需要進行Mapper端和Reducer端的兩次排序!!!
優化:
可以改造Mapper和Reducer端,改框架來實現一次排序。
頻繁GC的解決辦法是:鎢絲計劃!!