
隨着業務規模的不斷擴大,需要選擇合適的方案去應對數據規模的增長,以應對逐漸增長的訪問壓力和數據量。
數據庫的擴展方式主要包括:業務分庫、主從複製,數據庫分表。
1、業務分庫
業務分庫指的是按照業務模塊將數據分散到不同的數據庫服務器。例如,一個簡單的電商網站,包括用户、商品、訂單三個業務模塊,我們可以將用户數據、商品數據、訂單數據分開放到三台不同的數據庫服務器上,而不是將所有數據都放在一台數據庫服務器上。這樣的就變成了3個數據庫同時承擔壓力,系統的吞吐量自然就提高了。
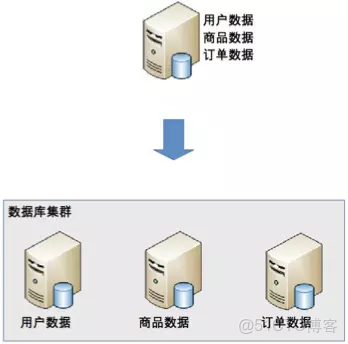
雖然業務分庫能夠分散存儲和訪問壓力,但同時也帶來了新的問題,接下來我進行詳細分析。
- join 操作問題
- 業務分庫後,原本在同一個數據庫中的表分散到不同數據庫中,導致無法使用 SQL 的 join 查詢。
- 事務問題
- 原本在同一個數據庫中不同的表可以在同一個事務中修改,業務分庫後,表分散到不同的數據庫中,無法通過事務統一修改。
- 成本問題
- 業務分庫同時也帶來了成本的代價,本來 1 台服務器搞定的事情,現在要 3 台,如果考慮備份,那就是 2 台變成了 6 台。
2、主從複製和讀寫分離
讀寫分離的基本原理是將數據庫讀寫操作分散到不同的節點上。讀寫分離的基本實現是:
- 數據庫服務器搭建主從集羣,一主一從、一主多從都可以。
- 數據庫主機負責讀寫操作,從機只負責讀操作。
- 數據庫主機通過複製將數據同步到從機,每台數據庫服務器都存儲了所有的業務數據。
- 業務服務器將寫操作發給數據庫主機,將讀操作發給數據庫從機。
需要注意的是,這裏用的是“主從集羣”,而不是“主備集羣”。“從機”的“從”可以理解為“僕從”,僕從是要幫主人幹活的,“從機”是需要提供讀數據的功能的;而“備機”一般被認為僅僅提供備份功能,不提供訪問功能。所以使用“主從”還是“主備”,是要看場景的,這兩個詞並不是完全等同。
3、數據庫分表
將不同業務數據分散存儲到不同的數據庫服務器,能夠支撐百萬甚至千萬用户規模的業務,但如果業務繼續發展,同一業務的單表數據也會達到單台數據庫服務器的處理瓶頸。例如,淘寶的幾億用户數據,如果全部存放在一台數據庫服務器的一張表中,肯定是無法滿足性能要求的,此時就需要對單表數據進行拆分。
單表數據拆分有兩種方式:垂直分表和水平分表。示意圖如下:
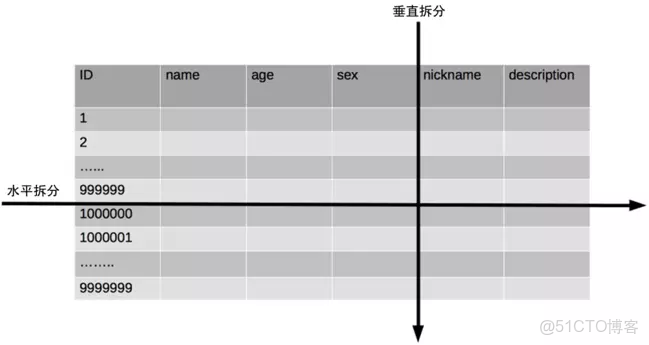
單表進行切分後,是否要將切分後的多個表分散在不同的數據庫服務器中,可以根據實際的切分效果來確定。如果性能能夠滿足業務要求,是可以不拆分到多台數據庫服務器的,畢竟我們在上面業務分庫的內容看到業務分庫也會引入很多複雜性的問題。分表能夠有效地分散存儲壓力和帶來性能提升,但和分庫一樣,也會引入各種複雜性:
垂直分表
垂直分表適合將表中某些不常用且佔了大量空間的列拆分出去。
例如,前面示意圖中的 nickname 和 description 字段,假設我們是一個婚戀網站,用户在篩選其他用户的時候,主要是用 age 和 sex 兩個字段進行查詢,而 nickname 和 description 兩個字段主要用於展示,一般不會在業務查詢中用到。description 本身又比較長,因此我們可以將這兩個字段獨立到另外一張表中,這樣在查詢 age 和 sex 時,就能帶來一定的性能提升。
水平分表
水平分表適合錶行數特別大的表,有的公司要求單錶行數超過 5000 萬就必須進行分表,這個數字可以作為參考,但並不是絕對標準,關鍵還是要看錶的訪問性能。對於一些比較複雜的表,可能超過 1000 萬就要分表了;而對於一些簡單的表,即使存儲數據超過 1 億行,也可以不分表。
但不管怎樣,當看到表的數據量達到千萬級別時,作為架構師就要警覺起來,因為這很可能是架構的性能瓶頸或者隱患。
水平分表相比垂直分表,會引入更多的複雜性,例如數據id:
下面是幾種ID生成策略
主鍵自增
以最常見的用户 ID 為例,可以按照 1000000 的範圍大小進行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此類推。
複雜點:分段大小的選取。分段太小會導致切分後子表數量過多,增加維護複雜度;分段太大可能會導致單表依然存在性能問題,一般建議分段大小在 100 萬至 2000 萬之間,具體需要根據業務選取合適的分段大小。
優點:可以隨着數據的增加平滑地擴充新的表。例如,現在的用户是 100 萬,如果增加到 1000 萬,只需要增加新的表就可以了,原有的數據不需要動。
缺點:分佈不均勻,假如按照 1000 萬來進行分表,有可能某個分段實際存儲的數據量只有 1000 條,而另外一個分段實際存儲的數據量有 900 萬條。
Hash
同樣以用户 ID 為例,假如我們一開始就規劃了 10 個數據庫表,路由算法可以簡單地用 user_id % 10 的值來表示數據所屬的數據庫表編號,ID 為 985 的用户放到編號為 5 的子表中,ID 為 10086 的用户放到編號為 6 的字表中。
複雜點:初始表數量的選取。表數量太多維護比較麻煩,表數量太少又可能導致單表性能存在問題。
優點:表分佈比較均勻。
缺點:擴充新的表很麻煩,所有數據都要重分佈。
雪花算法:分佈式ID生成器
雪花算法是由Twitter公佈的分佈式主鍵生成算法,它能夠保證不同表的主鍵的不重複性,以及相同表的主鍵的有序性。
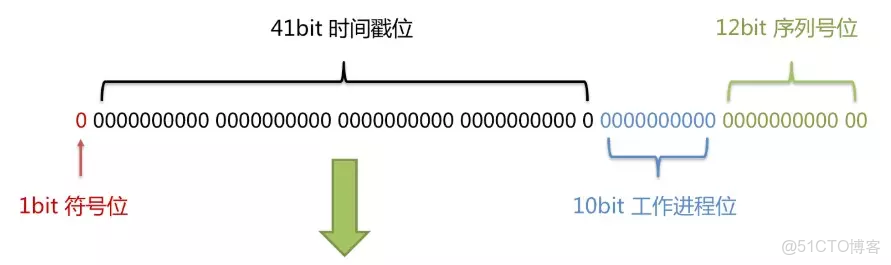
長度共64bit(一個long型)。
首先是一個符號位,1bit標識,由於long基本類型在Java中是帶符號的,最高位是符號位,正數是0,負數是1,所以id一般是正數,最高位是0。
41bit時間截(毫秒級),存儲的是時間截的差值(當前時間截 - 開始時間截),結果約等於69.73年。
10bit作為機器的ID(5個bit是數據中心,5個bit的機器ID,可以部署在1024個節點)。
12bit作為毫秒內的流水號(意味着每個節點在每毫秒可以產生 4096 個 ID)。
優點:整體上按照時間自增排序,並且整個分佈式系統內不會產生ID碰撞,並且效率較高。