
空間計算作為融合物理世界與數字世界的發展方向之一,已經有自動駕駛和虛擬現實的兩大領域支撐。然而,海量三維空間數據的實時處理帶來了巨大的算力與功耗問題。 存算一體(Computing-in-Memory, CIM)通過將計算單元與存儲單元融合,從根本上減少了數據搬運,本文將從硬件設計、底層算力架構及能效比三個維度,深入探討存算一體如何賦能空間計算,並結合英偉達(NVIDIA)的cosmos模型、世界模型及車載雷達等前沿實例,展望其廣闊應用前景。
空間計算的核心定義在於將數字信息無縫地集成到我們所處的物理世界。藉助空間計算,用户得以在三維空間中與數據和虛擬對象進行交互。要實現這一願景,離不開幾項關鍵技術的支撐:感知與定位,通過即時定位與地圖構建(SLAM)及攝像頭、激光雷達(LiDAR)等傳感器融合技術,賦予設備理解自身空間位置與姿態的能力;三維重建與渲染,要求系統能實時構建並渲染3D環境與對象,同時展示數字內容與現實場景;多模態交互,支持手勢、語音或眼動追蹤等符合人類直覺的交互方式,改變人機協作的傳統形態。

圖一 空間計算概念示意圖,通過控制視角展示3D交互
這些功能的技術落地還有一定距離,因為空間計算應用,像”世界模型”(World Model)這樣的前沿概念對硬件性能提出了非常高的要求。在算力方面,世界模型作為AI對環境的內部模擬與預測系統,構建和實時渲染一個可交互的3D世界需要處理幾何、紋理和物理狀態等數據,幾乎只有大型企業服務器可以支持;在時效方面,空間計算的許多應用場景有很高的實時性要求,例如車載雷達系統、眼動體感系統。傳統馮·諾依曼架構已然成為制約空間計算性能與能效的核心瓶頸。
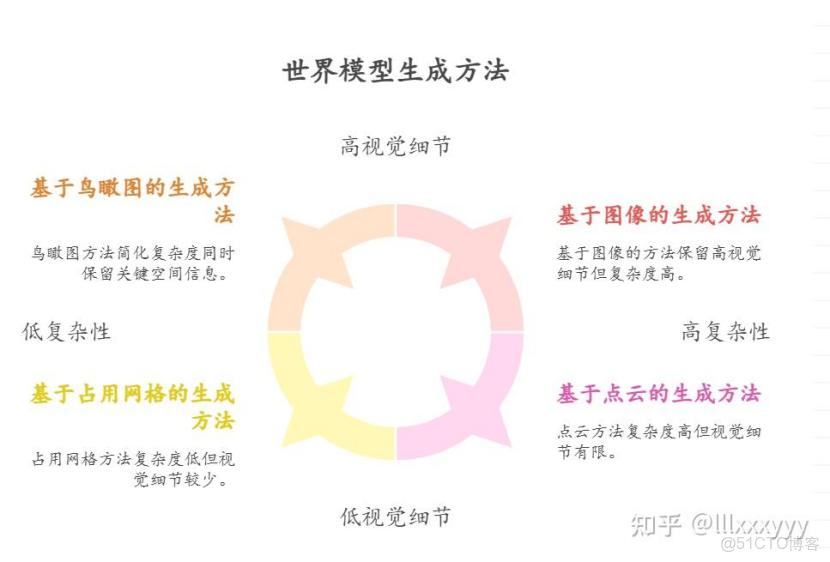
圖二 世界模型生成方法在複雜度與視覺細節上的權衡
為了嘗試打破困局,業界正在探索新的硬件結構,例如NVIDIA Cosmos這類物理AI模型已經可以為世界模型構建硬件基礎。NVIDIA Cosmos平台通過對物理世界進行大規的模擬渲染,可以加速機器人和自動駕駛汽車等物理AI的開發進程。然而,儘管NVIDIA Cosmos的傳統GPU平台在並行計算方面表現強大,但在處理海量模擬數據時,依舊面臨着能耗和數據帶寬問題。在此背景下,存算一體(Computing-in-Memory, CIM)架構通過將計算單元與存儲單元深度融合,有望為下一代物理AI模型提供更高效的硬件。通過在內存中直接處理數據,存算一體架構消除了大部分數據搬運的瓶頸,能夠顯著加速模型的訓練推理,為真正的空間計算時代指出了一條道路。
空間計算應用的底層算法均為大規模的矩陣向量運算,即矩陣乘加(Multiply-Accumulate, MAC)操作,包括實時三維渲染、即時定位與地圖重構以及環境建模等。在傳統架構中執行MAC運算需要將數據集從內存加載到GPU的高速緩存中,計算完成後再將結果寫回內存。”取數-計算-存數”的循環導致功耗延遲開銷很大,而存算一體架構利用存儲器陣列將存儲單元(如SRAM、DRAM)本身轉變為兼具數據存儲和並行計算能力的處理單元。
在空間計算領域中已有多個可行的研究方向,隨着國內新能源汽車的高速發展,“世界模型”(World Model)已經成為當前具身智能車載應用領域的研究核心。不同於側重統計學習的傳統視頻生成模型,如Sora,先進的世界模型如WoW(World-Omniscient World Model)可以負責物理精確和因果推理,能夠模擬摩擦、碰撞、流體等複雜的動力學過程並作出對應決策。在自動駕駛和高級駕駛輔助系統(ADAS)中,世界模型收集來自攝像頭、車載雷達和運動傳感器等多方面信息,實現精確環境感知,其工作流程對實時性和可靠性有很高要求。
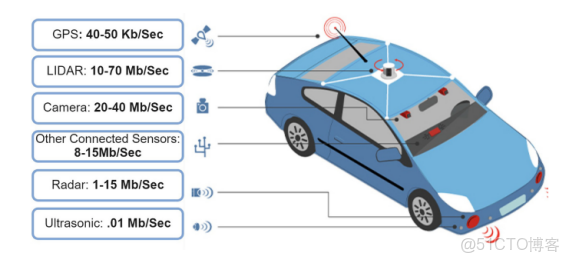
圖三 自動駕駛傳感器產生的數據
按照計算任務和場景區分,空間計算可以分為延遲不敏感的雲端計算和延遲敏感的邊緣計算。在空間計算的雲端,訓練能夠模擬真實世界複雜動態的”世界模型”成為核心任務之一。麻省理工學院的相關研究表明,構建一個理想的世界模型其計算量遠超傳統的語言或圖像模型。在處理AI任務時,數據搬運所消耗的能量甚至佔到了總能耗的60%以上。當算力需求呈指數級增長時,數據中心的能耗也隨之增長,導致IT巨頭甚至需要規劃自建電網來滿足能源需求。例如近日,Intel持有了大量NVIDIA的計算卡卻找不到合適的場地鋪設服務器機房和電力線路,無奈向美國政府求助劃分地權。
如果説雲端的挑戰在於能源成本與供給,那麼在空間計算的邊緣側,功耗則決定了產品的實用性。以智能駕駛為例,自動駕駛汽車依賴於攝像頭、激光雷達、毫米波雷達等多種傳感器,在行駛過程中會產生峯值接近1TB/s的數據量,處理數據過程會產生額外的整車功耗。一個用於感知和視覺應用的高性能GPU自身功耗可達到300-350瓦時/百公里,這種算力功耗影響了電動車的續航里程,也對車輛的散熱系統和硬件穩定性提出了更多的要求。
近年來,以後摩智能、知存科技為代表的創新企業,已經成功將存算一體技術從理論推向量產,並在空間計算、世界模型等領域取得突破。後摩智能推出的面向智能駕駛的存算一體芯片鴻途®H30基於12nm工藝,在35W的典型功耗下,能夠提供256TOPS的算力。其SoC能效比達到7.3 TOPS/W,展示了在有限功率預算內滿足高階自動駕駛算力需求的潛力。當前,即便是輕量級的空間感知或交互模型,也大多需要在雲端進行處理。而藉助存算一體芯片數十倍的能效提升,未來在智能手機、AR眼鏡甚至更小型的IoT設備上,直接運行百億參數級別的”世界模型”或空間感知大模型將成為可能。

圖四 後摩智能H30
在人工智能算力需求持續井噴的宏觀背景下,存算一體技術不僅能降低數據中心的碳排放,助力實現”碳中和”目標,也能延長邊緣設備的電池壽命,減少電子廢棄物。在追求更高、更快、更強的計算能力的同時,存算一體技術確保了AI的發展是可持續的、對環境友好的,符合全球向綠色經濟轉型的長期趨勢。