
之前介紹的StringIndexer是針對單個類別型特徵進行轉換,倘若所有特徵都已經被組織在一個向量中
,又想對其中某些單個分量進行處理時,Spark ML提供了VectorIndexer類來解決向量數據集中的類別
性特徵轉換。通過為其提供maxCategories超參數,它可以自動識別哪些特徵是類別型的,並且將原始
值轉換為類別索引。它基於不同特徵值的數量來識別哪些特徵需要被類別化,那些取值可能性最多不超
過maxCategories的特徵需要會被認為是類別型的。在下面的例子中,我們讀入一個數據集,然後使用
VectorIndexer訓練出模型,來決定哪些特徵需要被作為類別特徵,將類別特徵轉換為索引,這裏設置
maxCategories為10,即只有種類小10的特徵才被認為是類別型特徵,否則被認為是連續型特徵:
#導入相關的類庫
from pyspark.ml.feature import VectorIndexer
from pyspark.sql import SparkSession
#創建SparkSession對象,配置spark
spark = SparkSession.builder.master('local').appName('VectorIndexerDemo').getOrCreate()
#讀入數據集
data = spark.read.format('libsvm').load('file:///usr/local/spark/data/mllib/sample_libsvm_data.txt')
#創建VectorIndexer對象,
indexer = VectorIndexer(inputCol='features', outputCol='indexed',maxCategories=10)
#生成訓練模型,訓練數據
indexerModel = indexer.fit(data)
categoricalFeatures = indexerModel.categoryMaps
indexerData = indexerModel.transform(data)
indexerData.show()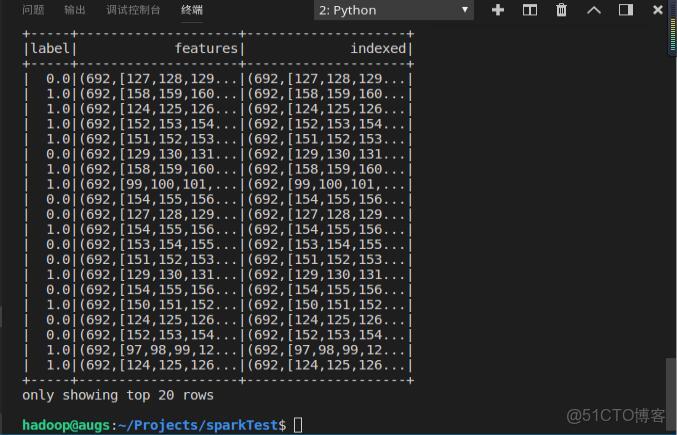
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。