
(Python 3.10 + PyCharm 環境 · 無需顯卡 · 支持 PDF/Word/Excel/圖片 · 含圖形界面、windows10 TLSC)
第一章:環境準備(30分鐘)
步驟 1:安裝 Tesseract OCR(10分鐘)
• 下載安裝包
• 打開瀏覽器訪問:https://github.com/UB-Mannheim/tesseract/wiki
• 點擊 tesseract-ocr-w64-setup-5.3.0.20221222.exe 下載(64位系統)
• 運行安裝
• 雙擊下載的安裝包 •
在 "Select Additional Language Data" 界面:
• 勾選 Chinese (Simplified)
• 勾選 English
• 其他選項保持默認,點擊 "Next" 直到完成
• 配置環境變量
• 按 Win + R 輸入 sysdm.cpl 回車
• 切換到 "高級" 選項卡 → 點擊 "環境變量"
• 在 "系統變量" 區域找到 Path → 點擊 "編輯"
• 點擊 "新建" → 輸入:
C:\Program Files\Tesseract-OCR(按照實際路徑修改)
• 點擊 "確定" 保存所有窗口
驗證安裝
• 按 Win + R 輸入 cmd 回車
• 在命令行輸入:
tesseract --list-langs·確認輸出中包含 chi_sim 和 eng
步驟 2:創建項目虛擬環境(5分鐘)
• 打開 PyCharm
• 啓動 PyCharm
• 頂部菜單:File → New Project
• 位置(Location):G:\PythonProject\spark_local_rag(建議修改為你自己的路徑)
• Python 解釋器:選擇已安裝的 Python 3.10
• 勾選 ✔️ Create a virtual environment
• 虛擬環境名稱:spark_env • 點擊 "Create"
• 激活虛擬環境
• 在 PyCharm 底部找到 Terminal 標籤頁(或按 Alt + F12)
• 輸入命令驗證:
pip --version確認輸出路徑包含 spark_env(例如:G:\PythonProject\spark_local_rag\spark_env\Scripts\pip.exe)
步驟 3:安裝依賴包(15分鐘)
在 Terminal 中逐行執行(複製粘貼每行後按回車):
pip install langchain==0.1.17
pip install langchain-community
pip install chromadb==0.4.24
pip install pypdf
pip install python-docx
pip install pillow pytesseract
pip install gradio==4.20.0
pip install websocket-client
pip install pandas openpyxl xlrd第二章:創建項目結構(5分鐘)
在 PyCharm 左側 Project 面板中:
• 右鍵點擊項目根目錄 → New → Directory
• 名稱:knowledge_base(存放知識文件)
• 右鍵點擊項目根目錄 → New → Python File
創建以下 4 個文件:
• xinghuo_llm.py
• document_loader.py
• rag_pipeline.py
• main.py
第三章:編寫核心代碼(逐行操作)
文件 1:xinghuo_llm.py(訊飛星火集成)
- 在 PyCharm 中打開
xinghuo_llm.py - 複製以下完整代碼到文件中:
# xinghuo_llm.py
import base64
import datetime
import hashlib
import hmac
import json
import threading
from urllib.parse import urlencode
from langchain_core.language_models.llms import LLM
from websocket import create_connection
# ====== 訊飛星火認證配置 ======
APPID = "你自己的"
APIKey = "你自己的"
APISecret = "你自己的"
SPARK_URL = "wss://你自己的"
def create_url():
"""生成帶鑑權信息的WebSocket URL"""
host = "spark-api.xf-yun.com"
path = "/v1/x1"
now = datetime.datetime.now(datetime.timezone.utc)
date = now.strftime("%a, %d %b %Y %H:%M:%S GMT")
# 構造簽名原文
signature_origin = f"host: {host}\ndate: {date}\nx-date: {date}\nGET {path} HTTP/1.1"
# 生成HMAC-SHA256簽名
signature_sha = hmac.new(
APISecret.encode("utf-8"),
signature_origin.encode("utf-8"),
digestmod=hashlib.sha256,
).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode("utf-8")
# 生成authorization頭
authorization_origin = (
f'api_key="{APIKey}", algorithm="hmac-sha256", '
f'headers="host date x-date request-line", signature="{signature_sha_base64}"'
)
authorization = base64.b64encode(authorization_origin.encode("utf-8")).decode("utf-8")
# 拼接請求參數
params = {
"authorization": authorization,
"date": date,
"x-date": date,
"host": host
}
return SPARK_URL + "?" + urlencode(params)
class SparkX1LLM(LLM):
"""訊飛星火X1-32K模型的LangChain封裝"""
def _call(self, prompt: str, stop=None, **kwargs) -> str:
"""同步調用模型"""
url = create_url()
result = []
try:
# 創建WebSocket連接
ws = create_connection(url)
# 構造請求payload
payload = {
"header": {"app_id": APPID},
"parameter": {
"chat": {
"domain": "x1", # 必須是x1(對應/v1/x1接口)
"temperature": 0.5,
"max_tokens": 2048
}
},
"payload": {
"message": {
"text": [{"role": "user", "content": prompt}]
}
}
}
# 發送請求
ws.send(json.dumps(payload))
# 接收響應
while True:
message = ws.recv()
data = json.loads(message)
# 檢查錯誤
header = data.get("header", {})
code = header.get("code")
if code != 0:
error_msg = data.get("message", "未知錯誤")
raise RuntimeError(f"訊飛API錯誤[{code}]: {error_msg}")
# 提取文本內容
choices = data.get("payload", {}).get("choices", {})
text_content = choices.get("text", [{}])[0].get("content", "")
status = choices.get("status")
result.append(text_content)
# 檢查是否結束
if status == 2:
break
# 關閉連接
ws.close()
return "".join(result)
except Exception as e:
raise RuntimeError(f"WebSocket調用失敗: {str(e)}")
@property
def _llm_type(self) -> str:
return "spark-x1"文件 2:document_loader.py(多格式文件加載)
• 打開 document_loader.py
• 複製以下完整代碼:
# document_loader.py
import os
import pandas as pd
from langchain_core.documents import Document
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader
from PIL import Image
import pytesseract
def excel_to_text(filepath: str) -> str:
"""將Excel文件轉換為結構化文本"""
try:
xls = pd.ExcelFile(filepath)
full_text = f"文件: {os.path.basename(filepath)}\n\n"
for sheet_name in xls.sheet_names:
# 讀取工作表,空值轉為空字符串
df = pd.read_excel(filepath, sheet_name=sheet_name, dtype=str).fillna("")
if df.empty:
continue
full_text += f"工作表: {sheet_name}\n"
# 獲取列名(假設第一行為標題)
headers = df.columns.tolist()
# 遍歷每一行
for idx, row in df.iterrows():
row_items = []
for col in headers:
val = str(row[col]).strip()
if val: # 只添加非空值
row_items.append(f"{col}={val}")
if row_items: # 只添加非空行
full_text += f"第{idx+1}行: " + "; ".join(row_items) + "\n"
full_text += "\n"
return full_text.strip()
except Exception as e:
return f"Excel文件解析失敗 ({os.path.basename(filepath)}): {str(e)}"
def load_documents_from_folder(folder_path: str):
"""從文件夾加載所有支持類型的文檔"""
documents = []
# 遍歷文件夾中所有文件
for filename in os.listdir(folder_path):
filepath = os.path.join(folder_path, filename)
try:
# PDF文件處理
if filename.lower().endswith(".pdf"):
loader = PyPDFLoader(filepath)
docs = loader.load()
for doc in docs:
doc.metadata["source"] = filename
documents.extend(docs)
# Word文件處理
elif filename.lower().endswith((".docx", ".doc")):
loader = Docx2txtLoader(filepath)
docs = loader.load()
for doc in docs:
doc.metadata["source"] = filename
documents.extend(docs)
# 圖片文件處理
elif filename.lower().endswith((".png", ".jpg", ".jpeg", ".bmp")):
text = pytesseract.image_to_string(
Image.open(filepath),
lang="chi_sim+eng"
)
doc = Document(
page_content=text,
metadata={"source": filename}
)
documents.append(doc)
# Excel文件處理
elif filename.lower().endswith((".xlsx", ".xls")):
text = excel_to_text(filepath)
doc = Document(
page_content=text,
metadata={"source": filename}
)
documents.append(doc)
except Exception as e:
print(f"⚠️ 加載 {filename} 失敗: {str(e)}")
print(f"✅ 共加載 {len(documents)} 個文檔片段")
return documents文件 3:rag_pipeline.py(RAG核心邏輯)
- 打開
rag_pipeline.py - 複製以下完整代碼:
# rag_pipeline.py
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from .xinghuo_llm import SparkX1LLM
from .document_loader import load_documents_from_folder
import os
class LocalRAG:
def __init__(self, knowledge_dir="knowledge_base", persist_dir="vector_db"):
self.knowledge_dir = knowledge_dir
self.persist_dir = persist_dir
self.vector_db = None
self.qa_chain = None
# 創建知識庫目錄(如果不存在)
os.makedirs(knowledge_dir, exist_ok=True)
# 初始化嵌入模型(完全離線)
self.embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'}
)
def rebuild_knowledge_base(self):
"""重建知識庫(加載文檔 + 創建向量庫)"""
print("🔄 正在加載文檔...")
documents = load_documents_from_folder(self.knowledge_dir)
if not documents:
raise ValueError(f"知識庫目錄 {self.knowledge_dir} 中沒有找到有效文檔!")
print("✂️ 正在分割文本...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""]
)
splits = text_splitter.split_documents(documents)
print("🧠 正在創建向量數據庫...")
self.vector_db = Chroma.from_documents(
documents=splits,
embedding=self.embeddings,
persist_directory=self.persist_dir
)
self.vector_db.persist() # 保存到磁盤
print("🔗 正在初始化問答鏈...")
llm = SparkX1LLM() # 使用訊飛星火
self.qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=self.vector_db.as_retriever(
search_type="similarity",
search_kwargs={"k": 3}
),
return_source_documents=True
)
print("✅ 知識庫重建完成!")
def query(self, question: str):
"""執行問答"""
if not self.qa_chain:
raise RuntimeError("請先重建知識庫!")
print(f"\n❓ 用户問題: {question}")
response = self.qa_chain.invoke({"query": question})
# 提取引用來源
sources = []
for doc in response["source_documents"]:
source = doc.metadata["source"]
if source not in sources:
sources.append(source)
return {
"answer": response["result"],
"sources": sources
}文件 4:main.py(圖形界面)
- 打開
main.py - 複製以下完整代碼:
# main.py
import gradio as gr
from rag_pipeline import LocalRAG
import os
import shutil
# 初始化RAG系統
rag_system = LocalRAG()
def upload_files(files):
"""處理上傳的文件"""
saved_files = []
for file in files:
dest_path = os.path.join(rag_system.knowledge_dir, os.path.basename(file.name))
shutil.copy(file.name, dest_path)
saved_files.append(os.path.basename(file.name))
return f"✅ 已上傳 {len(saved_files)} 個文件: {', '.join(saved_files)}"
def rebuild_knowledge_base():
"""重建知識庫"""
try:
rag_system.rebuild_knowledge_base()
return "✅ 知識庫重建成功!現在可以提問了。"
except Exception as e:
return f"❌ 重建失敗: {str(e)}"
def answer_question(question):
"""回答問題"""
try:
if not rag_system.qa_chain:
return "請先重建知識庫!", []
result = rag_system.query(question)
sources = "\n".join([f"• {source}" for source in result["sources"]])
return result["answer"], sources
except Exception as e:
return f"生成回答時出錯: {str(e)}", ""
# 創建Gradio界面
with gr.Blocks(title="本地知識助手 - 訊飛星火版") as demo:
gr.Markdown("# 🧠 本地知識助手 (訊飛星火版)")
gr.Markdown("### 支持 PDF / Word / Excel / 圖片文件 · 完全離線運行")
with gr.Tab("上傳文件"):
file_upload = gr.Files(label="選擇文件(支持 PDF/Word/Excel/圖片)")
upload_btn = gr.Button("上傳文件")
upload_status = gr.Textbox(label="上傳狀態", interactive=False)
upload_btn.click(upload_files, inputs=file_upload, outputs=upload_status)
rebuild_btn = gr.Button("重建知識庫", variant="primary")
rebuild_status = gr.Textbox(label="重建狀態", interactive=False)
rebuild_btn.click(rebuild_knowledge_base, outputs=rebuild_status)
with gr.Tab("問答"):
question = gr.Textbox(label="輸入你的問題", placeholder="例如:文檔中提到的關鍵技術是什麼?")
ask_btn = gr.Button("獲取答案", variant="primary")
with gr.Row():
answer = gr.Textbox(label="回答", lines=10)
sources = gr.Textbox(label="參考來源", lines=5)
ask_btn.click(answer_question, inputs=question, outputs=[answer, sources])
# 啓動應用
if __name__ == "__main__":
demo.launch(server_name="127.0.0.1", server_port=7860)項目結構
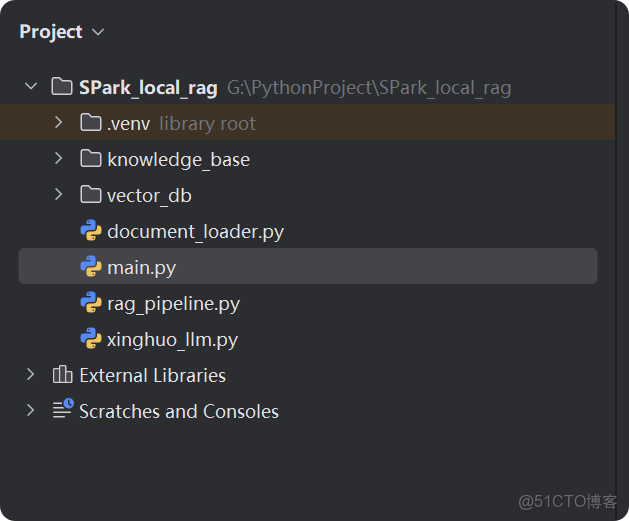
第四章:測試運行(10分鐘)
步驟 1:準備測試文件
- 在項目目錄中找到
knowledge_base文件夾 - 放入以下測試文件(可自行創建):
測試文檔.pdf(含一段中文文字)員工信息.xlsx(內容如下):
|
姓名
|
部門
|
工齡
|
|
張三
|
技術部
|
3年
|
|
李四
|
市場部
|
5年
|
步驟 2:啓動應用
• 在 PyCharm 中右鍵點擊 main.py
• 選擇 Run 'main'
• 等待控制枱出現:
Running on local URL: http://127.0.0.1:7860
步驟 3:使用圖形界面
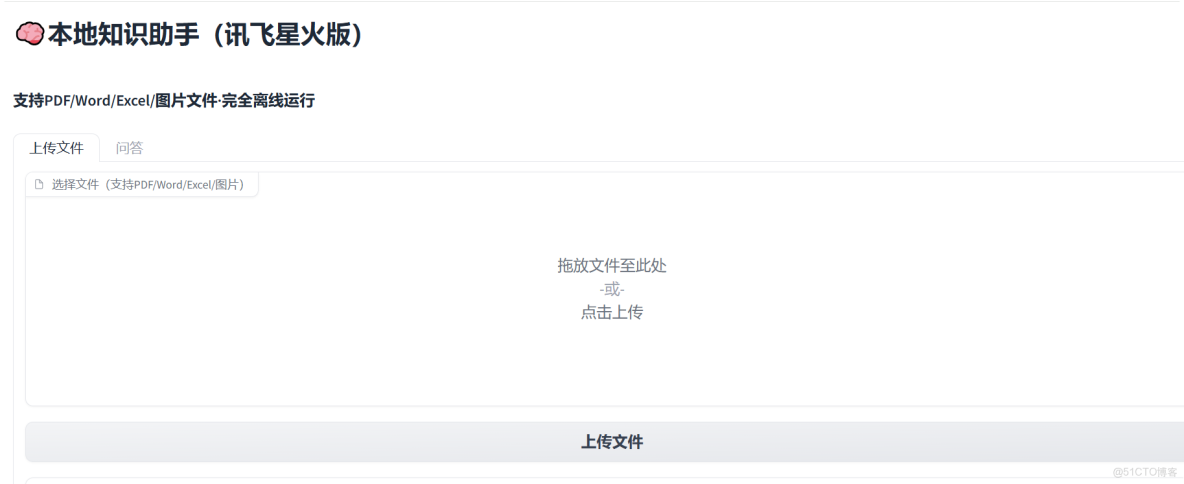
- 自動打開瀏覽器(或手動訪問 http://127.0.0.1:7860)
- 切換到 "上傳文件" 標籤頁:
- 點擊 "選擇文件" 按鈕
- 選擇
測試文檔.pdf和員工信息.xlsx - 點擊 "上傳文件" → 顯示上傳成功
- 點擊 "重建知識庫" → 等待 1-2 分鐘(首次較慢)
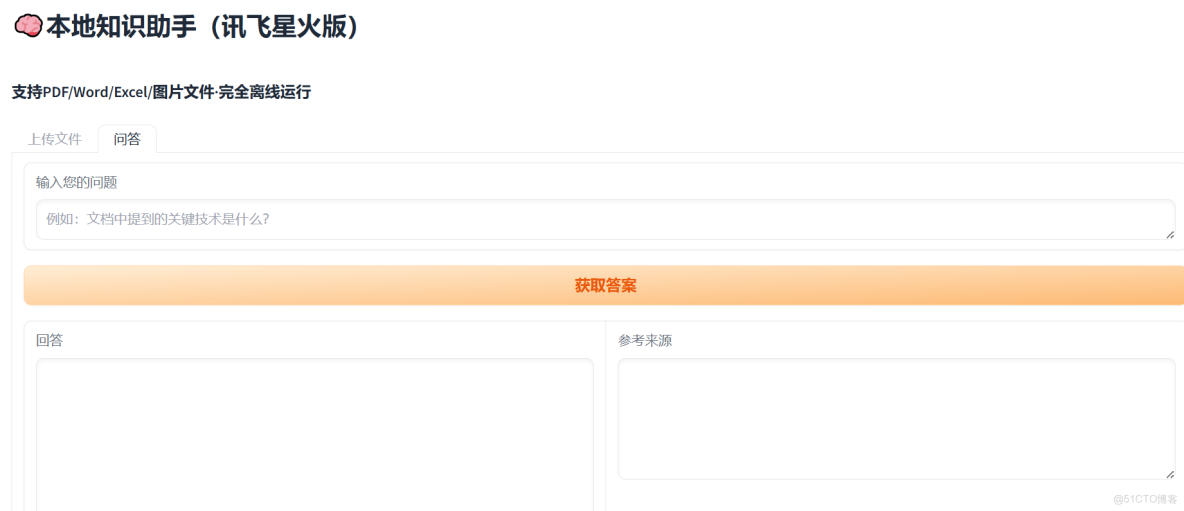
- 切換到 "問答" 標籤頁:
- 輸入問題:
張三在哪個部門? - 點擊 "獲取答案"
- 預期結果:
- 回答區域:
張三在技術部工作。
最終界面
不過經本人親測,回答的結果五花八門,距離理想目標還差太遠,不過權當是練手了,瞭解以下過程。