
MobileNet v2是對MobileNet v1的改進,也是一個輕量化模型。
MobileNet v1遺留下的問題
1)結構問題
MobileNet v1的結構非常簡單,是一個直筒結構,這種結構的性價比其實不高,後續一系列的ResNet,DenseNet等結構已經證明通過複用圖像特徵,使用Concat/Eltwise+等操作進行特徵融合,能極大提升網絡的性價比。
Concat(張量拼接):比如26*26*128,26*26*256經過拼接(Concat)之後得到(26*26*384)
Eltwise有三個操作:product(點乘),sum(相加減)和max(取最大值),其中sum是默認操作
2)Depthwise Convolution的潛在問題
Depthwise Convolution確實是降低了計算量,而在NxN Depthwise + 1x1 Pointwise的結構在性能上也接近NxN Conv。在實際使用中發現,Depthwise的部分kernel比較容易訓廢掉:訓練完之後發現Depthwise訓出來的kernel有不少是空的。當時我們認為,Depthwise每個kernel dim相對於普通Conv要小得多,過小的kernel_dim,加上ReLU的激活影響下,使得神經元輸出很容易變為0,所以學廢了。ReLU對於0的輸出梯度為0,所以一旦陷入0輸出,就沒法恢復了。我們還發現,這個問題在定點化低精度的時候會進一步放大。
MobileNet v2的創新點
1. Inverted residuals,通常的residuals block(殘差塊)是先經過1*1的Conv layer,把feature map的通道數"壓"下來,再經過3*3Conv layer,最後經過一個1*1的Conv layer,將feature map通道數再"擴展"回去。即先"壓縮",最後"擴張"回去。
而Inverted residuals就是先"擴張",最後"壓縮",後面會有介紹。
2. Linear bottlenecks,為了避免ReLU對特徵的破壞。
MobileNet v2和v1之間的區別
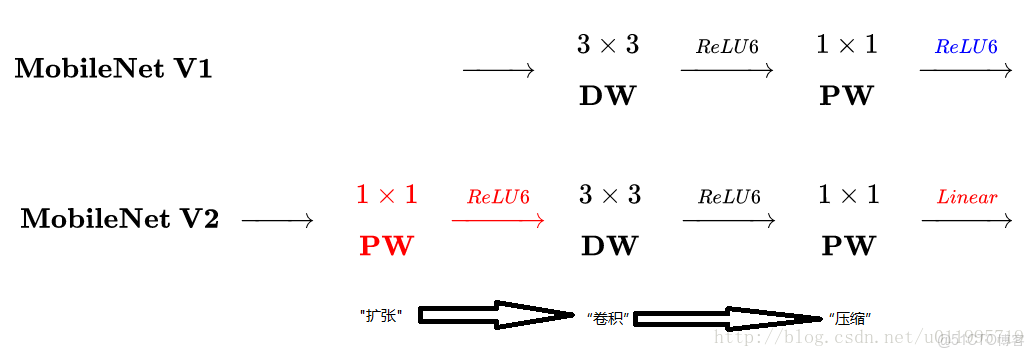
主要是兩點:
1. Depthwise convolution之前多了一個1*1的"擴張"層,目的是為了提升通道數,獲得更多特徵
2. 最後不採用ReLU,而是linear,目的是防止ReLU破壞特徵
MobileNet v2的網絡結構
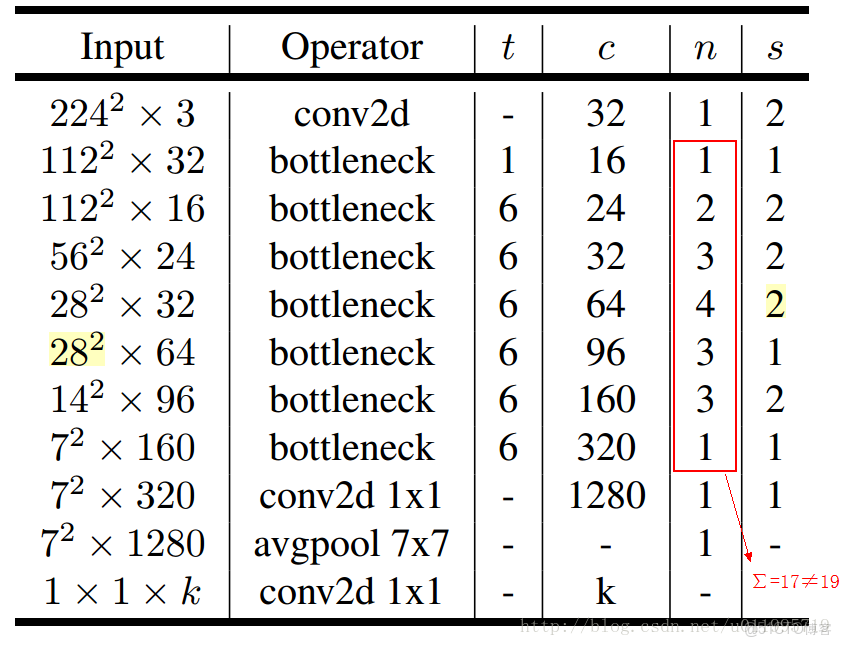
其中: t 表示"擴張倍數",c 表示輸出通道數,n 表示重複次數,s 表示步長stride
有兩點錯誤:
1. 第五行,也就是第7~10個bottleneck,stride = 2,分辨率應該從28降低到14,如果不是分辨率出錯,那就應該是stride=1
2. 文中提到共計採用19個bottleneck,但是這裏只有17個
一個bottleneck有如下三個部分組成:

stride = 1和stride = 2,在結構上稍微有點不同。在stride=2時,不採用shortcut。我們對MobileNet v1和MobileNet v2進行比較如下圖:
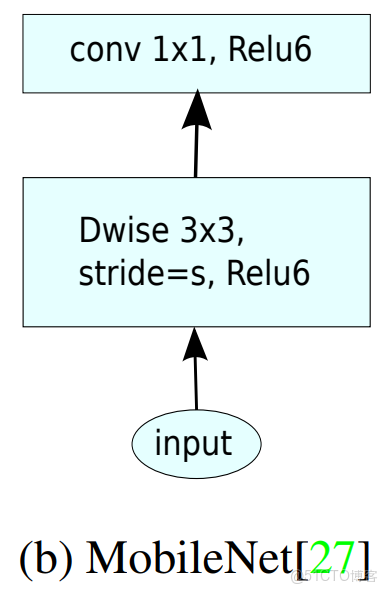
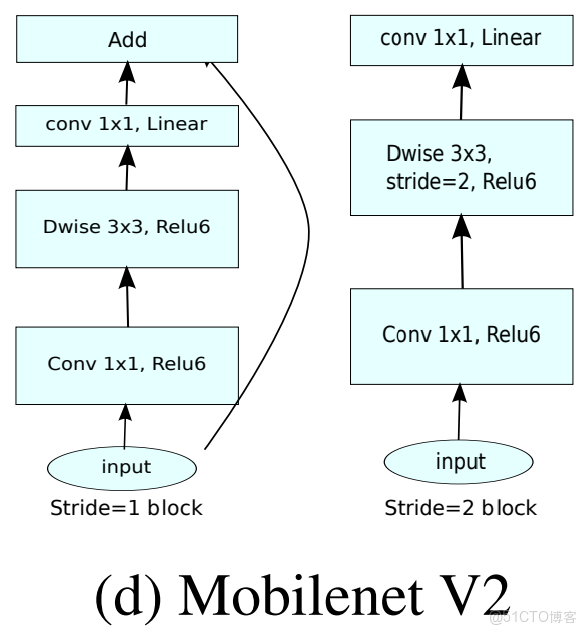
注意:除了最後的avgpool,整個網絡並沒有採用pooling進行下采樣,而是採用stride=2來下采樣。