
基於 Transformer 架構的基礎模型,已在自然語言處理與計算機視覺等領域引發深刻變革,推動技術從「一事一模型」的定製範式,邁向通用化的新階段。然而,當這類模型進入科學研究領域時,卻遭遇了明顯的水土不服。科學觀測數據來源多樣、格式不一,且常包含各類觀測噪聲,使得數據呈現出顯著的「複雜異質性」。這一現實使得科學數據分析陷入兩難: 若僅處理單一類型數據,則難以充分挖掘其潛在價值;若依賴人工設計的跨模態融合方案,又難以靈活適配多樣的觀測場景。
在眾多科學領域中,天文學恰為這類模型提供了一個理想的試驗場。其海量公開觀測數據為模型訓練提供了充足「養料」;同時,觀測手段極為豐富,涵蓋星系成像、恆星光譜、天體測光等多種方式,這種多維度的數據形態天然契合多模態技術研發的需求。
事實上,已有研究嘗試構建天文學多模態模型,但這些嘗試仍存在明顯侷限:大多聚焦於超新星爆發等單一現象,依賴「對比目標(contrastive objectives)」作為核心技術,導致模型既難以靈活應對任意模態組合,也難以捕捉模態之間除淺層關聯之外的關鍵科學信息。
為突破這一瓶頸,來自加州大學伯克利分校、劍橋大學、牛津大學等全球十餘所科研機構的團隊聯合攻關,推出了首個面向天文學的大規模多模態基礎模型家族 AION-1(天文全模態網絡,AstronomIcal Omni-modal Network) ,通過統一的早期融合骨幹網絡,將圖像、光譜和星表數據等異質觀測信息進行集成建模,不僅在零樣本場景下表現優異,其線性探測準確率也可媲美針對特定任務專門訓練的模型。
相關研究成果以「AION-1: Omnimodal Foundation Model for Astronomical Sciences」為題,已收錄於 NeurIPS 2025。
研究亮點:
-
提出 AION-1 模型家族,這是一系列基於 token 的多模態科學基礎模型,參數規模覆蓋 3 億至 31 億,專門設計用於處理高度異質的天文觀測數據,支持任意模態組合。
-
開發了定製化的 Tokenization 方法,能夠將來源多樣、格式不一的天文數據轉化為統一表徵,構建出單一連貫的數據語料庫,有效克服了科學數據中常見的異質性、儀器噪聲和來源差異等問題。
-
AION-1 在廣泛的科學任務中表現優異。即便僅通過簡單的前向探測,其性能即可達到 SOTA 水平,在低數據量場景下更是顯著優於有監督基線。這一特性使下游研究人員無需進行復雜微調即可直接高效使用。
-
AION-1 通過系統解決數據異質性、噪聲和儀器多樣性等核心挑戰,為天文學乃至其他科學領域提供了可行的多模態建模範式。
論文地址:
https://openreview.net/forum?id=6gJ2ZykQ5W
關注公眾號,後台回覆「AION-1」獲取完整 PDF
更多 AI 前沿論文:
https://hyper.ai/papers
AION-1 預訓練基石:MMU 數據集與多類型天文數據 Tokenization 方案
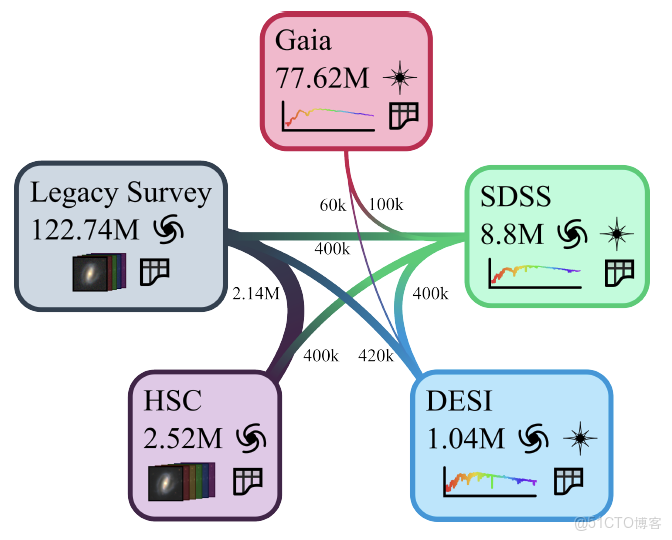
AION-1 的預訓練基於多模態宇宙(Multimodal Universe, MMU)數據集。 如下圖所示,這是一個專為機器學習任務構建的公開天文數據集合,整合了來自 5 大巡天項目的多樣化觀測信息。
具體包括:由超新星相機(HSC)和遺產成像巡天提供的星系圖像;來自暗能量光譜儀(DESI)和斯隆數字巡天(SDSS)的高分辨率光譜及對應天體的距離信息;以及蓋亞衞星(Gaia)記錄的低分辨率光譜,同時包含銀河系恆星的高精度測光與位置數據。
::: hljs-center
訓練數據混合體
:::
為實現對這些多來源、多格式數據的統一處理,AION-1 提出了一種通用的 Tokenization 方案(Universal Tokenization)。該方案能夠將圖像、光譜、數值等不同形式的天文數據,轉換為模型可識別和處理的統一表示形式, 從而有效應對天文數據來源多樣、格式不一的核心挑戰。Tokenization 過程為每種數據類型設計了專用的轉換器,使其能夠適配不同儀器的數據輸出,確保同類數據在語義上對齊,同時避免針對同一類型的不同來源數據重複訓練模型。
對於多波段成像數據(Multiband imaging data), 針對星系圖像在分辨率、通道數量、波長覆蓋和噪聲表現等方面的差異,圖像 tokenizer 採用了靈活的通道嵌入設計,既能適應不同通道數的輸入,也能在表示中融入望遠鏡來源等信息。其核心網絡基於改進的 ResNet 結構,配合一種有限取值的量化技術,使得單一模型能夠統一處理來自多個觀測流程的圖像數據。訓練過程中,模型採用了一種考慮噪聲權重的損失評價方法,充分利用成像過程中已知的噪聲信息以提高重建質量。
對於光譜數據(Spectroscopic Data), 不同儀器在信號強度、波長範圍和分辨能力上的差異,通過將其統一標準化並映射到共享的波長網格上來解決,從而實現對多儀器、多目標光譜的聯合處理。該 tokenizer 基於 ConvNeXt V2 網絡結構,採用一種無需預設編碼的量化技術,並同樣使用加權噪聲損失函數來融合不同巡天的噪聲特性。
在表格/標量數據(Tabular/Scalar Data)的處理上, AION-1 放棄了傳統難以適應大數值範圍的連續表示方法,轉而採用基於數據分佈統計的分段離散化策略。這種方法使得數值分佈更為均勻,並在信息集中的區域最大限度地減少了轉換誤差。
除了常規的測光圖像,模型還為分割圖(Segmentation Maps)、物理屬性圖(Property Maps)等空間分佈的數值場數據設計了專用 tokenizer。它適用於取值範圍在 0 到 1 之間的標準化圖像,基於卷積網絡構建,採用與圖像tokenizer 相似的量化技術,並使用灰度星系圖像及對應的分割圖進行訓練。
對於用於天體定位的橢圓邊界框數據(Bounding Ellipses, 每個目標由位置座標、橢圓形狀和大小共 5 個參數描述),Tokenization 過程通過將座標映射到最近像素點並對橢圓屬性進行量化來實現。為處理圖像中目標數量不定的情況,所有檢測目標被轉化為一個序列,並按照距離圖像中心的遠近進行排序,從而形成一個統一且規範的表示結構。
AION-1:面向天文科學的多模態基礎模型
AION-1 的架構借鑑了當前主流的早期融合多模態模型思路,並特別採用了 4M 模型(蘋果與 EPFL 合作開發的多模態 AI 訓練框架)提出的可擴展掩碼建模方法(scalable multimodal masked modeling scheme)。其核心思路是: 將所有類型的數據轉換為統一的 token 表示後,隨機遮蓋其中一部分內容,再由模型學習恢復被遮蓋的部分。通過這種方式,模型能夠從圖像、光譜、數值等不同形式的數據中自動發現它們之間的內在關聯。
具體來説,每個訓練樣本包含 M 種不同類型的數據序列。 模型在訓練過程中會從中隨機選擇 2 部分:一部分作為輸入信息,另一部分作為需要重建的目標。由於這兩部分都是從全部數據中隨機選取的,使得模型既能掌握每種數據自身的特徵,又能理解不同數據類型之間的對應關係。
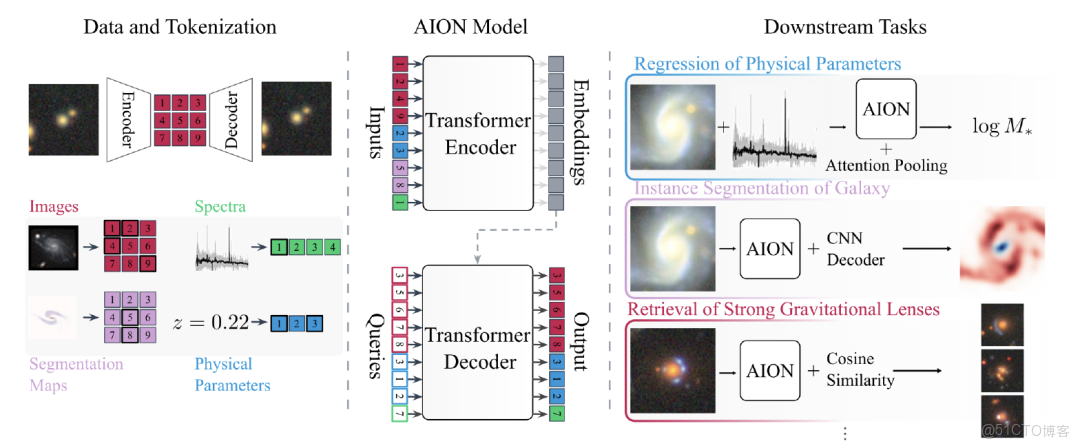
在技術實現上,如下圖所示,AION-1 採用了專為多任務設計的 Transformer 編碼器-解碼器結構。 除了標準的編碼器和解碼器外,其創新之處在於為每種數據類型設計了獨特的嵌入機制。對於每一種數據類型,模型都會配備專門的轉換函數、可學習的類型標識參數和位置參數。
::: hljs-center
AION-1 的 Transformer 框架
:::
特別值得一提的是,模型為每種數據類型與每個數據來源的組合都分配了獨立的類型標識。即使是同為圖像數據,只要來自不同的觀測設備,就會被賦予不同的標識。這樣的設計讓模型能夠識別數據的來源特徵,而這些來源信息往往隱含着數據質量、分辨率等重要屬性。
模型的訓練效率在很大程度上取決於如何合理選擇需要遮蓋的數據內容。研究發現,原先 4M 模型採用的採樣方法在處理長度差異大的數據時效果不佳,容易產生大量無效訓練樣本。為此,AION-1 提出了一種更高效的簡化策略: 在確定輸入內容時,先設定一個總數上限,然後隨機選擇一種數據類型並從中選取部分內容,不足的部分再從其他數據類型中補充。在確定需要重建的目標內容時,則採用偏向小規模的採樣方式來確定每種數據類型需要重建的數量。這種方法既減少了每個訓練樣本的計算量,又確保了訓練過程與實際使用場景的一致性。
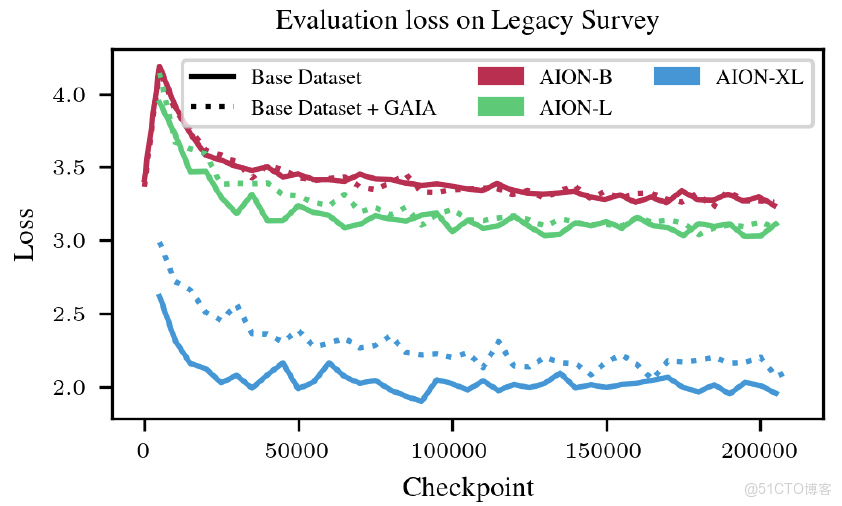
為了全面評估模型性能,研究團隊訓練了 3 個不同規模的 AION-1 版本:基礎版(3 億參數)、大型版(8 億參數)和超大型版(30 億參數)。 訓練過程採用 AdamW 優化器,設置了相應的學習參數,總共訓練 20.5 萬步。學習率的調整採用先升温後衰減的策略。如下圖所示,該研究展示了不同模型規模以及是否包含 Gaia 衞星數據對效果的影響,為後續模型選擇提供了參考。
::: hljs-center
不同模型規模基於 Legacy 巡天的 AION-1 測試損失
:::
經過完整訓練後,AION-1 具備了多種實用的生成功能,支持從數據補全到跨設備數據轉換等任務。其核心優勢在於能夠理解所有數據類型之間的整體關聯,因此即使在只有部分觀測數據的情況下,也能生成物理屬性一致的其他類型數據樣本。
實驗結果:紅移精度提升 16 倍,多模態天文 AI 性能大幅突破
AION-1 的突破性在於能夠直接生成具備明確物理意義且不受數據類型限制的通用表徵,無需依賴針對特定任務設計的複雜監督流程。基於這一機制,模型在跨模態生成(Cross-Modal Generation)與標量參數估計(Scalar Posterior Estimation)兩大關鍵場景中表現優異。
在跨模態生成方面, AION-1 實現了高維數據的條件生成,有效支持跨設備數據轉換與觀測質量提升。最具代表性的應用是利用 Gaia 衞星的低分辨率數據生成高分辨率 DESI 光譜:如下圖所示,儘管前者數據稀疏度高出 50-100 倍,但模型仍能精準還原光譜的譜線中心、寬度和振幅等特徵。這一進展使得基於廣泛可得的低分辨率數據開展精細天體分析成為可能,對降低研究成本、提升數據利用率具有重要意義。
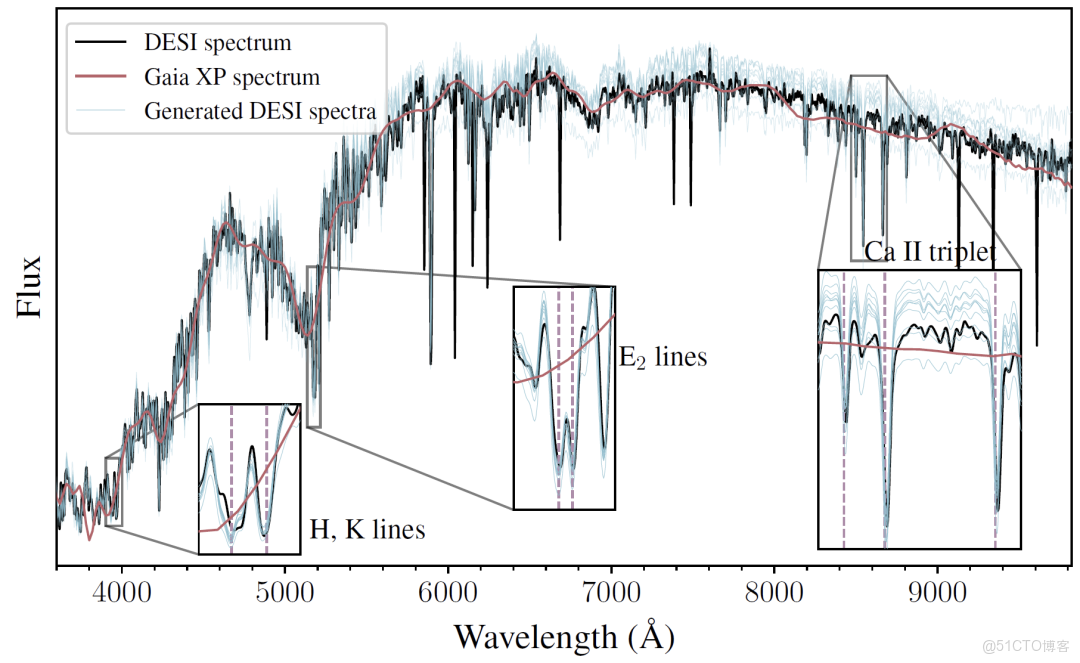
::: hljs-center
AION-1 生成高分辨率光譜
:::
在參數估計方面, AION-1 能夠直接推斷量化標量的取值分佈。以紅移估計(Redshift Posterior Estimation)為例,如下圖所示,典型星系在三種信息量遞增條件下的結果:僅使用基礎測光數據時分佈較分散;加入多波段成像後明顯收斂;進一步引入高分辨率光譜後,估計精度顯著提升,表明模型能有效融合多源信息優化估計結果。
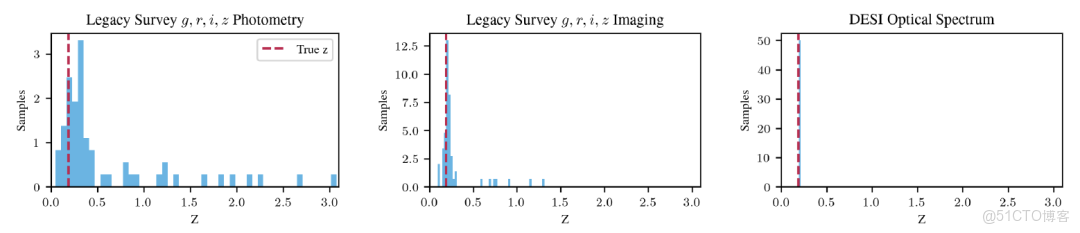
::: hljs-center
AION-1 的紅移估計
:::
為系統驗證模型能力,研究團隊還從 4 個方向展開實驗:
- 物理屬性估計(Physical Property Estimation)
針對星系恆星質量、恆星表面温度等通常需要高分辨率觀測才能推導的參數,研究探索使用 AION-1 從低分辨率數據中直接估計。在 12 萬個星系樣本上的測試表明,其表現優於或匹配專用監督模型;在 24 萬顆恆星樣本的測試中,甚至在「基於 Gaia 低分辨率數據預測高分辨率參數」任務上超越了專門優化的基線模型。
- 基於專家標註的語義學習(Learning from Semantic Human Labels)
在星系形態分類任務中(8,000 個標註樣本),AION-1 的準確率不僅高於從零訓練的專用模型,還可與使用數十倍標註數據訓練的先進模型媲美。在星系結構語義分割任務中(2,800 個樣本),其生成結果與人工標註重合度高,性能超過簡單全卷積基線。
- 低數據量場景性能(Performance in Low-Data Regime)
針對天文研究中常見標註稀缺的問題,實驗表明 AION-1 在數據有限時的優勢更加明顯,其表現可匹配甚至超越需要多一個數量級訓練數據的監督模型。
- 稀有目標檢索(Similarity-Based Retrieval)
面對強引力透鏡等稀有天體(佔比約 0.1%)、缺乏足夠標註的挑戰,AION-1 通過表徵空間相似度檢索,在旋渦星系、合併星系和強透鏡候選體三類目標上均表現優異,檢索效果超越其他先進自監督模型。
這些實驗結果共同表明,AION-1 為多模態天文數據分析提供了統一而高效的解決方案,特別是在數據稀缺和跨模態推理場景中展現出顯著優勢。
多模態 AI 賦能天文研究,學界與產業界的協同突破
近年來,「多模態 AI 驅動天文研究」已成為全球學術界與工業界共同關注的焦點,一系列突破性成果正在重塑天文數據的處理與應用模式。
在學術界,研究者致力於將多模態融合能力與具體天文問題緊密結合。例如,麻省理工學院媒體實驗室在 2025 年公佈的空間探索計劃中,將多模態 AI 與擴展現實技術相結合,開發出面向月球駐留任務的智能分析系統。 該系統能夠融合衞星遙感圖像、環境傳感器讀數與設備運行狀態等多源信息,為模擬月球基地的資源管理與風險預警提供實時決策支持。
與此同時,牛津大學等機構的研究團隊構建了一款基於深度學習的篩選工具,可從數千個數據警報中精準識別出源自超新星爆發的有效信號,將天文學家所需處理的數據量降低約 85%。該虛擬研究助理僅需 1.5 萬個訓練樣本和普通筆記本電腦的算力,即可完成訓練, 並將日常人工篩查工作轉為自動化流程。最終模型在保持高識別準確率的同時,將誤報率控制在 1% 左右,顯著提升了科研效率。
論文標題: The ATLAS Virtual Research Assistant
論文鏈接: https://iopscience.iop.org/article/10.3847/1538-4357/adf2a1
產業界則通過產品化路徑推動多模態 AI 在天文領域的實際部署。英偉達於 2024 年與歐洲南方天文台(ESO)合作,將其 AI 推理優化技術集成至甚大望遠鏡的光譜數據處理流程中。 藉助 TensorRT 對多模態融合模型的加速,遙遠星系的光譜分類效率提升達三倍。
IBM 在 2025 年進一步與 ESO 合作,利用多模態 AI 優化 VLT 的觀測調度系統。通過綜合氣象預測、天體亮度變化與設備負載等多元信息,實現觀測計劃的動態調整,使對變星等時域目標的捕獲成功率提高 30%。
此外,Google DeepMind 與 LIGO 及 GSSI 合作,提出名為「深度環路整形」的控制方法,以提升引力波探測器的控制精度。該控制器在真實 LIGO 系統中進行了驗證,其實際性能與仿真結果高度一致。相比原有系統,新技術將噪聲控制能力提高了 30 至 100 倍, 並首次徹底消除了系統中最不穩定、最難抑制的反饋迴路噪聲源。
論文標題: Improving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
論文地址: https://www.science.org/doi/10.1126/science.adw1291
可以看出,構建多模態通用表徵已成為天文與人工智能交叉領域的明確趨勢。學術界通過深入科學問題持續打磨技術內核,工業界則憑藉工程化能力推動技術落地與規模化應用。兩者的協同推進,正逐步打破高成本觀測與複雜數據處理對天文研究的傳統制約,使更多研究者能夠藉助人工智能探索宇宙更深處的奧秘。
參考鏈接:
1.https://www.media.mit.edu/groups/space-exploration/updates/
2.https://www.eso.org/public/news/eso2408/
3.https://www.eso.org/public/news/eso2502/