
在機器翻譯領域,傳統的高性能模型往往面臨兩個核心難題。對於主流語言,閉源商業模型效果出眾但調用成本高,模型參數量動輒百億級別,需要高昂的算力支持,難以在手機等消費級設備上部署。另一方面,對於數據稀缺的低資源小語種,以及包含專業術語、文化特定表達的文本,模型翻譯質量常常不佳,容易出現幻覺問題或語義偏差。這導致用户在日常和移動場景下,常常在高質量、高成本的雲端服務與本地化、輕量化但效果不足的方案之間難以抉擇。
基於此,騰訊混元團隊近日正式開源了全新翻譯模型 HY-MT1.5。 本次開源包含兩個參數規模的版本:專為移動端設計的 Tencent-HY-MT1.5-1.8B 和麪向高性能場景的 Tencent-HY-MT1.5-7B,支持 33 個語種的互譯及 5 種中國少數民族語言/方言與漢語的互譯, 除中、英、日等常見語種外,涵蓋捷克語、冰島語等多個小語種。
HY-MT1.5-1.8B
經過量化後,該模型僅需約 1GB 內存即可在手機等端側設備流暢運行,支持離線實時翻譯。模型效率突出,處理 50 tokens 的平均耗時僅 0.18 秒,在 Flores200 等權威測試集上,其效果全面超越中等尺寸開源模型和主流商用 API,達到頂尖閉源模型的 90 分位水平。
HY-MT1.5-7B:
該模型是騰訊此前在 WMT25 國際翻譯比賽中斬獲 30 個語種冠軍的升級版,重點提升了翻譯準確率,並大幅減少了譯文夾帶無關注釋或語種混雜的問題。
具體而言,HY-MT1.5 的創新性在於通過獨創的技術方案,有效解決了「輕量化部署」與「高精度翻譯」之間的矛盾。其採用了 「On-Policy Distillation(大尺寸模型蒸餾)」策略,即令效果更強的 7B 模型作為「教師」,在訓練過程中實時引導參數規模為 1.8B 的「學生」模型,糾正其預測偏差,從而讓小模型從錯誤中學習,而非死記硬背。這使得小參數模型獲得了超越自身規模的翻譯能力。
目前,「HY-MT1.5-1.8B:多語言神經機器翻譯模型」已上線 HyperAI 官網(hyper.ai)的教程版塊,快來體驗極速翻譯吧~
HyperAI超神經還為大家準備了算力福利,新用户註冊後使用兑換碼「HY-MT」即可獲得 2 小時 NVIDIA GeForce RTX 5090 使用時長, 數量有限,快來領取吧!
在線運行:https://go.hyper.ai/I0pdR
Demo 運行
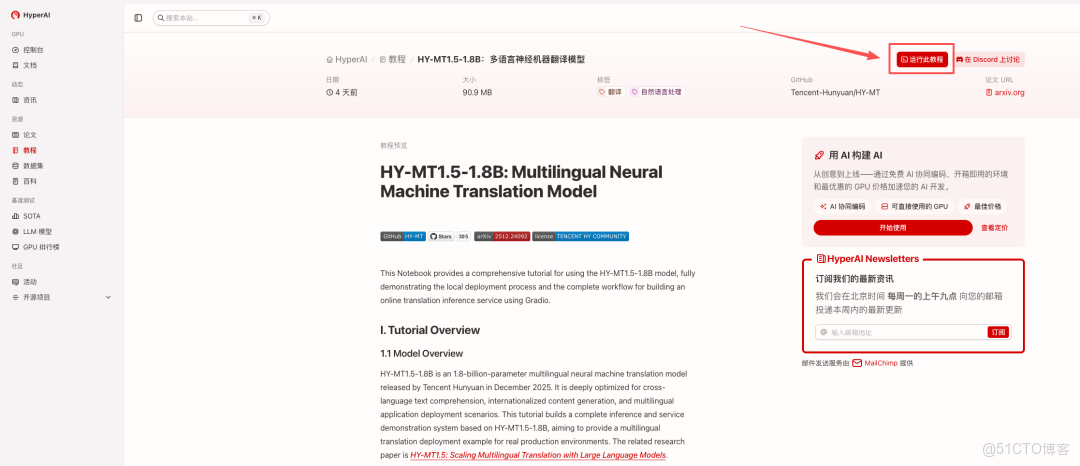
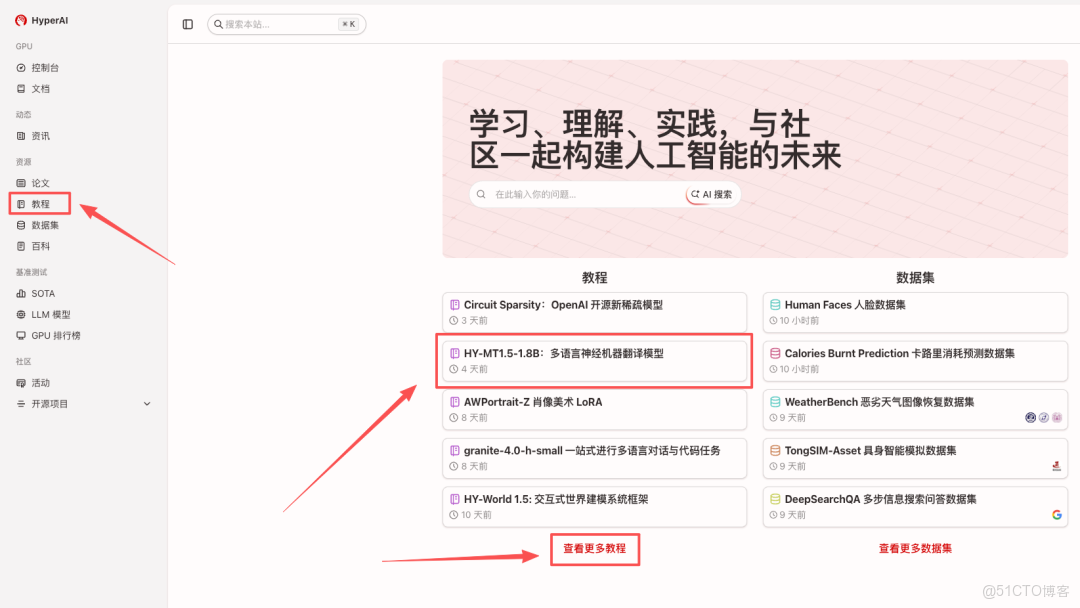
1.進入 hyper.ai 首頁後,選擇「HY-MT1.5-1.8B:多語言神經機器翻譯模型」,或進入「教程」頁面選擇。頁面跳轉後,點擊「在線運行此教程」。
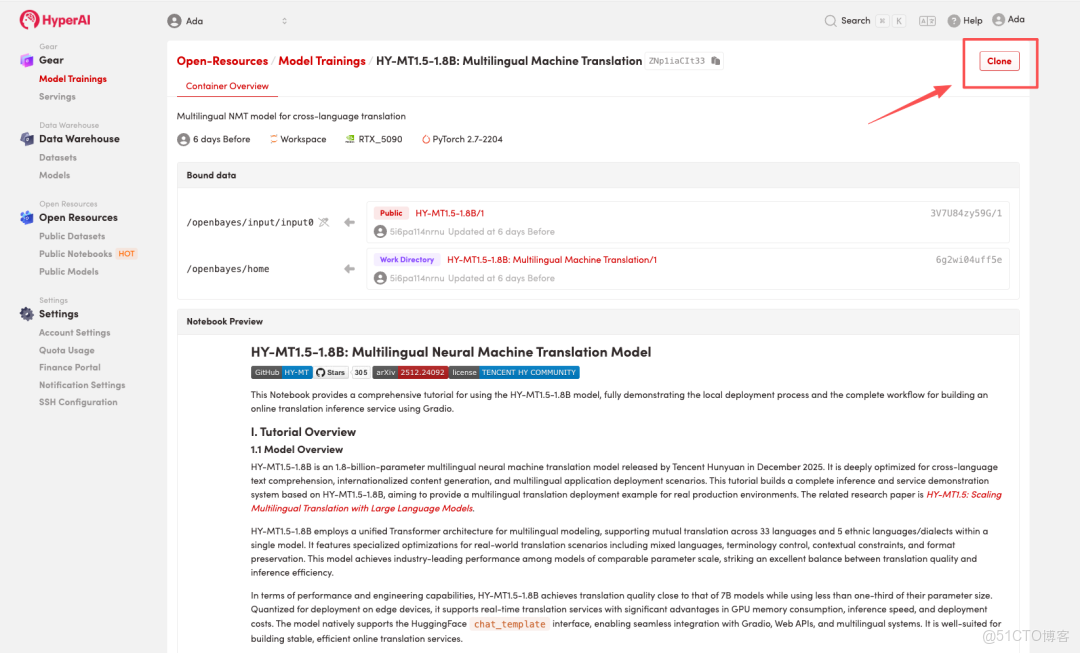
2.頁面跳轉後,點擊右上角「克隆」,將該教程克隆至自己的容器中。
注:頁面右上角支持切換語言,目前提供中文及英文兩種語言,本教程文章以英文為例進行步驟展示。
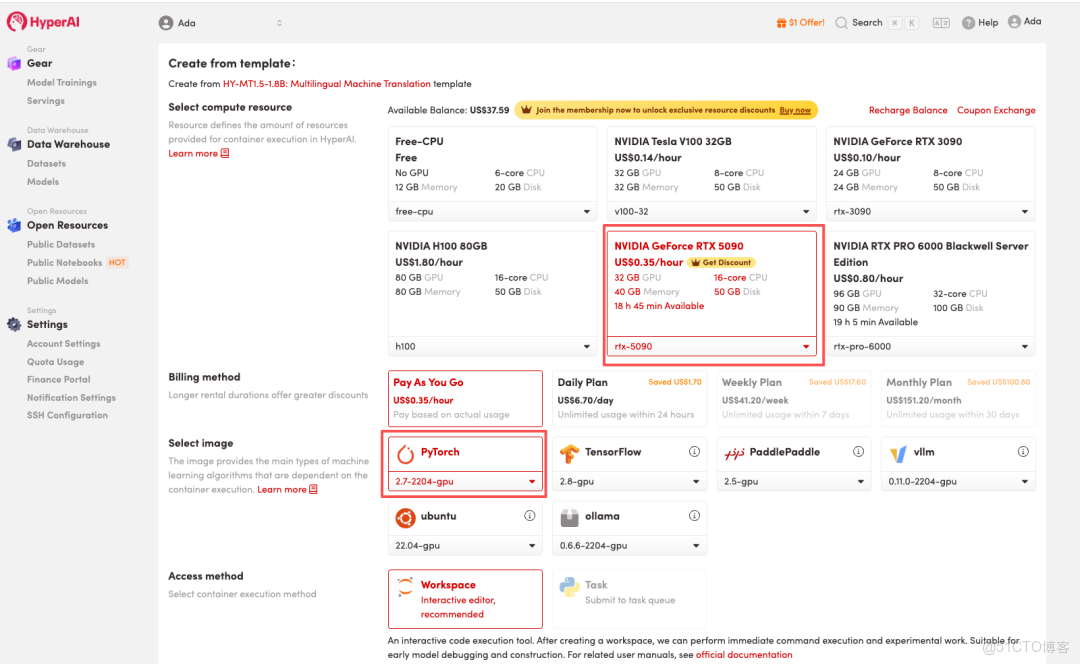
3.選擇「NVIDIA GeForce RTX 5090」以及「PyTorch」鏡像,按照需求選擇「Pay As You Go(按量付費)」或「Daily Plan/Weekly Plan/Monthly Plan(包日/周/月」,點擊「Continue job execution(繼續執行)」。
HyperAI 為新用户準備了註冊福利,僅需 $1,即可獲得 20 小時 RTX 5090 算力(原價 $7),資源永久有效。
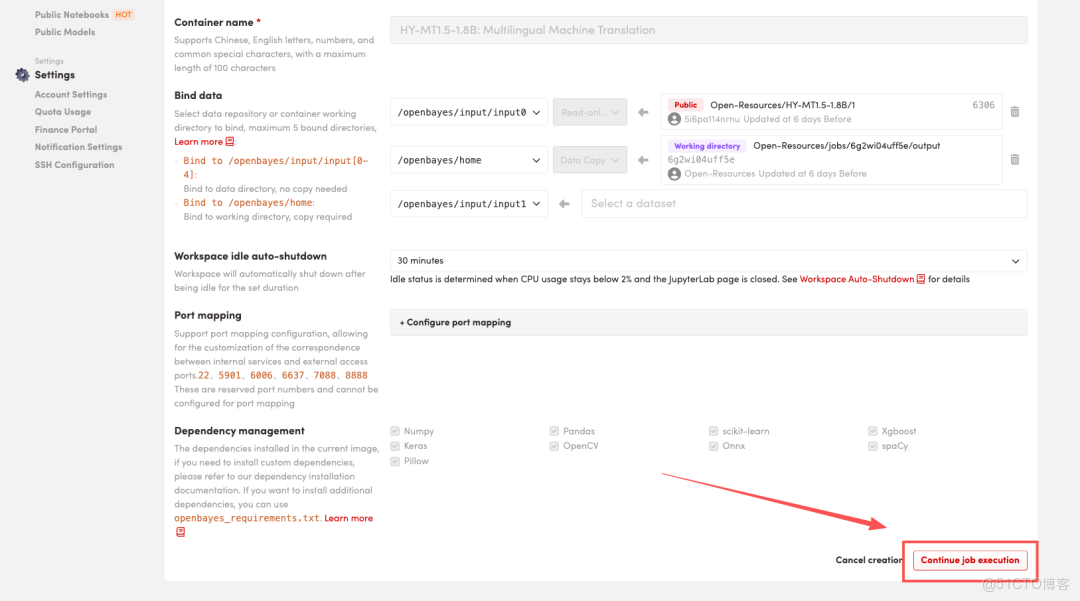
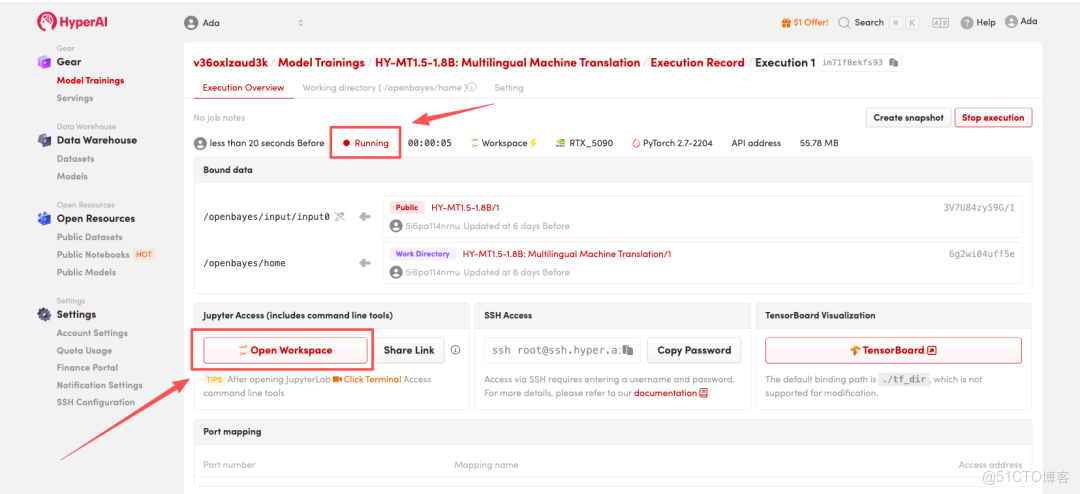
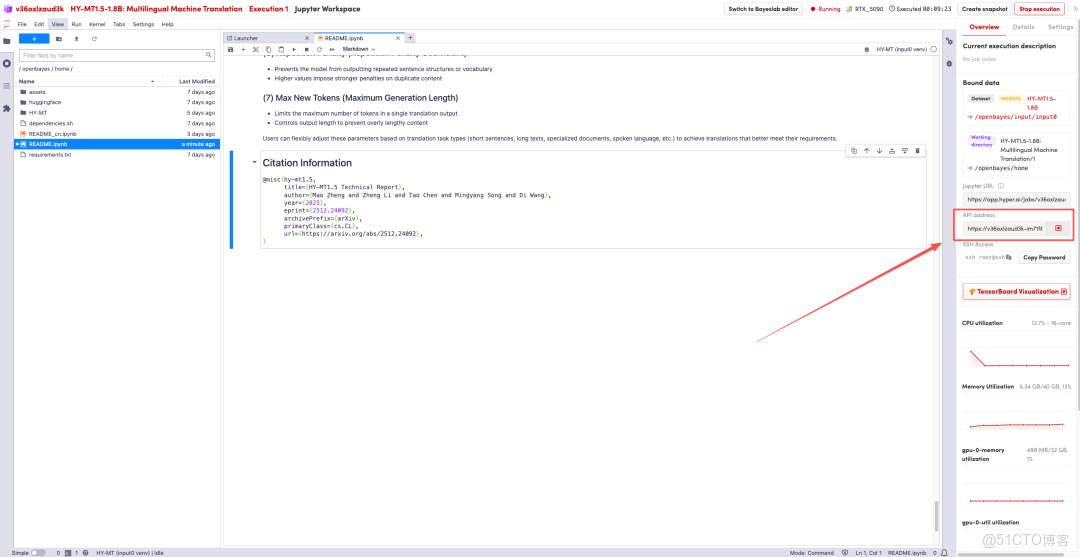
4.等待分配資源,當狀態變為「Running(運行中)」後,點擊「Open Workspace」進入 Jupyter Workspace。
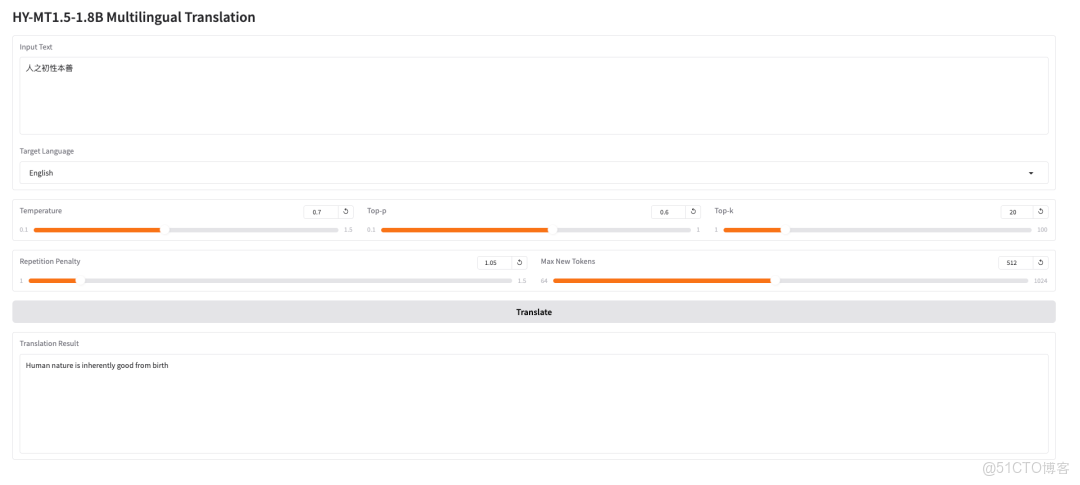
效果演示
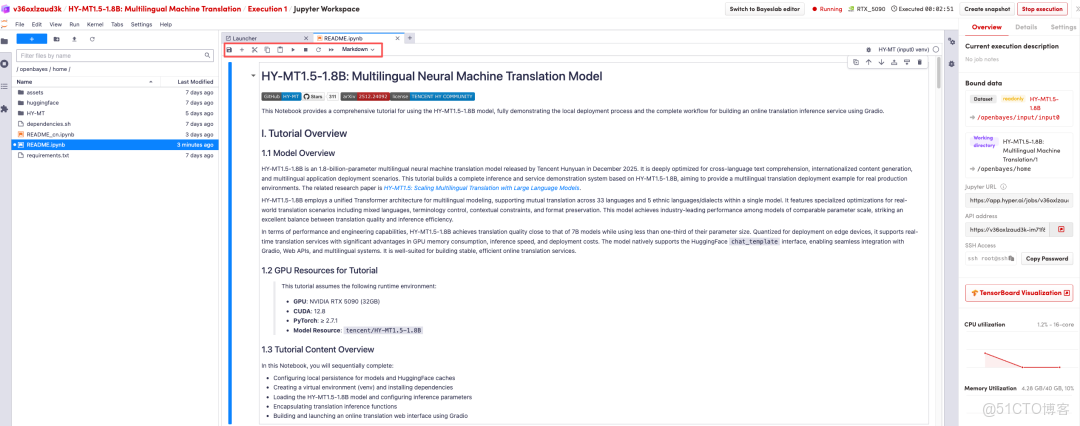
頁面跳轉後,點擊左側 README 頁面,進入後點擊上方 Run(運行)。
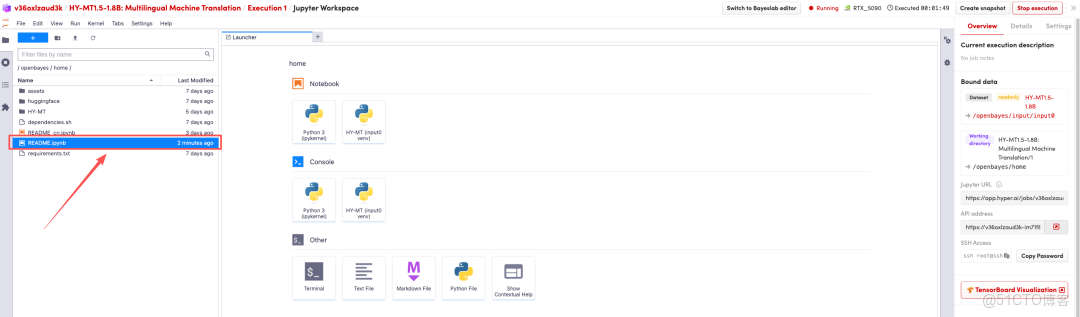
待運行完成,即可點擊右側 API 地址跳轉至 demo 頁面
教程鏈接:https://go.hyper.ai/I0pdR