

很多人第一次接觸各家大模型時,都會覺得它們的回答能帶來意想不到的驚喜,但有時,AI回答又怪怪的、囉嗦、甚至有點危險。
這背後,其實就是一個核心問題:對齊(Alignment)。
預訓練讓模型會“説話”,但對齊訓練,才讓模型更符合人類偏好:更有用、更安全、更有温度。在當下的大模型時代,有三種常被提到的對齊方法:PPO、DPO和KTO。
本期,LLaMA-Factory Online將用盡量通俗的方式,幫你搞懂它們的底層邏輯。
一、PPO:造一個“裁判”,再用強化學習調教模型
PPO(Proximal Policy Optimization,近端策略優化)最經典的應用就是:RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學習)。
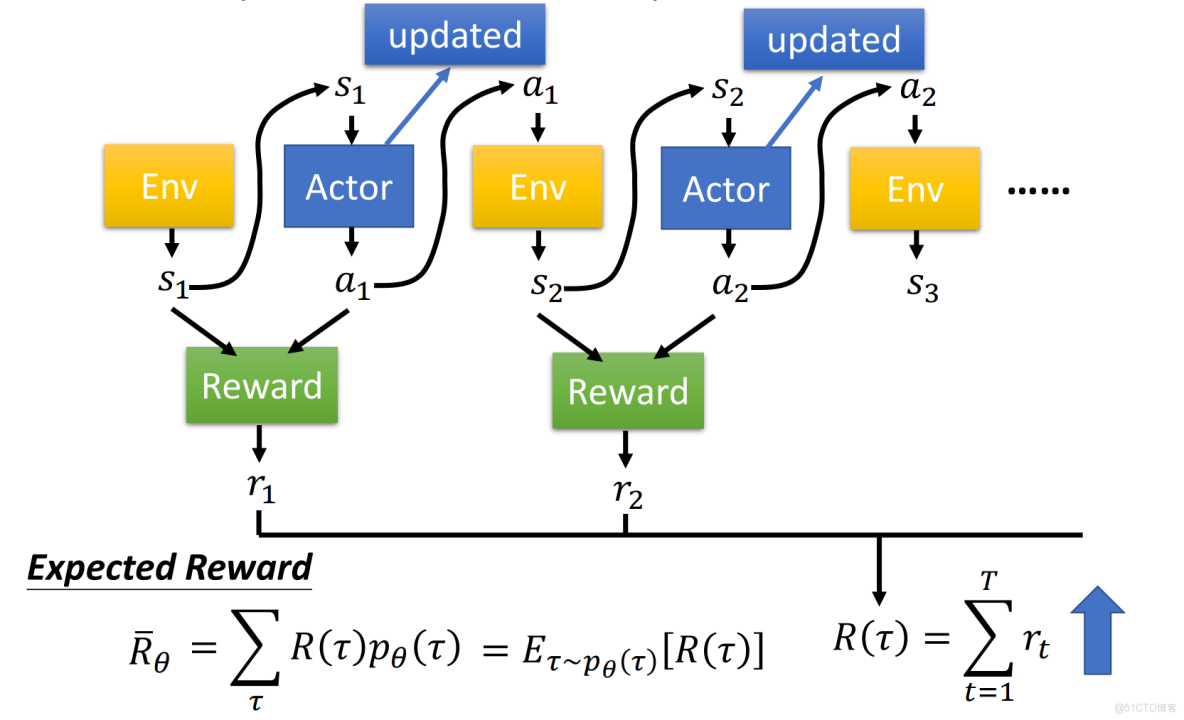
它的思路是“三件套”:
● 先由“SFT老師”教模型基礎禮儀
用高質量指令-回答數據,把預訓練模型變成一個基本聽話的聊天助手
● 再訓練一個“閲卷老師RM”初步打分
讓人類對一批迴答打偏好,用這些偏好去訓練一個專門“打分”的模型,以後看到一個回答,這個打分模型就會判斷:“這個 0.9 分” 或 “這個只有 0.2 分”
● 最後用PPO算法,讓模型按閲卷老師給的分數改進回答
先讓模型生成回答,高分回答方向上的參數被獎勵模型“鼓勵”,低分回答方向被“懲罰”。每次更新,又會用 PPO 的“裁剪機制”限制更新幅度,防止模型突然學偏
為什麼大家愛用 PPO?又為什麼很多團隊逐漸“逃離”它?
優點:
● 上限高,通用性強:有了獎勵模型,你可以把任意“主觀偏好”變成一個可學習的分數。模型的回答是否符合事實、是否禮貌、是否安全、是否有條理等要素,都可以揉進一個獎勵裏,PPO 按這個總分來優化,想象空間很大。
● 理論成熟,工業驗證充分:ChatGPT、Claude 早期版本等,都用 PPO+RLHF 這套路線走起來的,對大廠來説,這是“保險方案”。
缺點:
● 流程複雜、成本高:至少要維護兩個大模型(基座 + RM),訓練管線複雜、顯存壓力巨大,對中小團隊來説,非常“肉疼”。
● 容易被“誤導獎勵”:裁判是模型,它也會“犯蠢”:比如誤把“長篇大論”當成高質量,結果你看到的就是:回答變得又長又囉嗦,但不一定更有用。
● 對長推理任務不友好:很多數學/代碼題,只在“最終答案對不對”這裏給獎勵,中間推理過程沒標註。價值函數不好學,PPO 更新就會非常不穩定。這也是後來 GRPO、GSPO 等新算法誕生的重要原因。
如果你手頭只有幾張 GPU,還想用 PPO+RM 跑一套完整 RLHF 流程,大概率會被現實猛猛教育一下。
但如果你有技術、有精力,可以在LLaMA-Factory Online中,以平民價用H卡訓練市面上各種強大模型,享受優惠的同時,性能絕不縮水。

二、DPO:直接教學生分好壞
DPO(Direct Preference Optimization,直接偏好優化)的出發點很簡單:既然人類已經告訴我們 A 比 B 好,為什麼還要多繞一步去訓一個獎勵模型?直接用這對偏好數據更新大模型本身不就行了?
所以,DPO 直接跳過獎勵模型RM的訓練流程,用一個特殊的損失函數,讓模型滿足這樣的目標:在同樣的輸入下,提高“偏好回答”的生成概率,降低“非偏好回答”的生成概率。
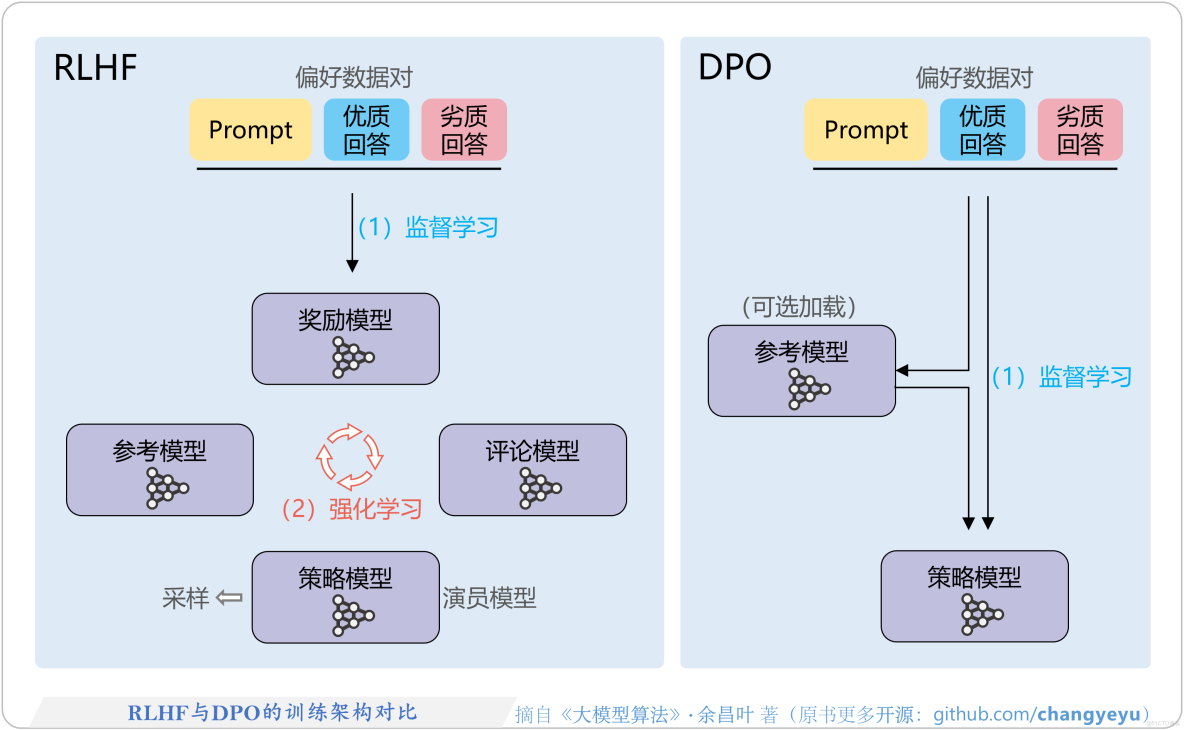
一條典型 DPO 樣本是這樣的結構:
{
輸入:用户問題 x
偏好回答: y_preferred
非偏好回答: y_dispreferred
}我們可以發現,和PPO相比,DPO中間整整省掉了一整個模型和一套管線。
DPO 的優缺點:典型的“中量級選手”
優點:
● 不用獎勵模型,算力成本與工程複雜度驟降,比 PPO 至少少一大截,對中小團隊、開源社區尤其友好。
● 訓練穩定,沒有價值函數、優勢估計這些“強化學習坑點”,訓練過程更像普通 SFT。
● 效果可觀,在很多對話任務上,適當規模的成對偏好數據 + DPO就能把一個 SFT 模型拉到接近GPT-3.5的體驗。
缺點:
● 非常依賴偏好數據質量。如果標註員的標準不統一、甚至本身理解有誤,模型就會學錯偏好,而且很難通過“獎勵模型分析”把問題拆出來。
● 對複雜、多維度目標支持較弱。比如代碼生成,你同時在意:正確性、效率、可讀性,但單純的偏好往往很難覆蓋所有維度,不如 PPO+RM 那麼靈活可控。
● 標註成本仍不低。成對偏好數據畢竟需要兩個候選回答,再由人類比較、選擇哪個更好。相比“單條打好/壞”,還是貴不少——這就給 KTO 留出了舞台。
三、KTO:好與壞的極簡判斷
KTO(Kahneman–Tversky Optimization)名字裏的兩位,就是諾獎得主卡尼曼和特沃斯基——他們提出了著名的前景理論:人類對“損失”的敏感度,遠遠大於對“收益”的敏感度,例如撿 100 塊錢沒有你丟 100 塊錢那麼“疼”。
KTO 把這個想法搬到了模型訓練裏,核心有兩點:
● 不再需要成對數據,只要給每個回答一個標籤:
可取 / Desirable:+1
不可取 / Undesirable:-1
● 對“壞回答”懲罰更重,對“好回答”獎勵更細膩
生成壞回答 → 懲罰力度大
沒生成好回答 → 也會被“温柔地懲罰一下”
讓模型學會:“少犯錯,比偶爾超常發揮重要得多。”
和 DPO 的成對數據比,KTO 的數據格式非常樸素:
{
"input_x": "計算 2 + 3 × 4 的結果",
"response": "2 + 3 = 5,5 × 4 = 20。",
"desirability_label": -1 // 壞
}{
"input_x": "計算 2 + 3 × 4 的結果",
"response": "2 + 3 = 5,5 × 4 = 20。",
"desirability_label": -1 // 壞
}人類標註任務從“二選一”降維到“單條打分”:看到一個回答 → 點👍 / 👎即可。
在實際平台中,這和我們給機器人“好評 / 差評”的交互方式非常接近,可以利用大量弱標註數據,快速積累樣本。
KTO 的優缺點:極度節省,換來的是“粗粒度”
優點:
● 標註成本極低,不需要成對比較,大部分人只要有“常識+審美”,就能給出好/壞評價,非常適合從線上用户反饋中直接挖掘訓練數據。
● 訓練流程簡單、計算開銷小,本質上是一個帶特殊損失函數的“帶標籤微調”,沒有價值函數、羣體對比這種 RL 元素,工程實現很友好。
● 對“不平衡場景”特別有用。比如醫療場景中:錯誤回答的危害遠超過正確回答帶來的“驚喜”。使用 KTO,可以重點懲罰那些危險、錯誤、消極的回答,讓模型優先減少災難性輸出。
缺點:
● 只能學“好/壞”,難學“細微偏好”,比如兩條回答都正確,一條詳細帶例子,一條簡潔乾脆,這時你想讓模型傾向其中一種風格,單一好/壞標籤表達力就不夠了。
● 對標籤質量敏感,若打標籤的人並不專業,甚至情緒化,模型容易學到稀奇古怪的偏好。
● 缺少“事實性約束”,只要標註員沒把事實錯誤當“壞”,模型就可能把“圓滑但不一定對”的回答學成“好風格”。
四、PPO、DPO、KTO,不同團隊怎麼選?
最後,把這三位主角拉到一張決策表上:
|
維度 |
PPO(RLHF) |
DPO |
KTO |
|
訓練流程 |
最複雜:SFT + 獎勵模型 + RLHF |
類 SFT:直接用偏好對訓練 |
類 SFT:用好/壞標籤訓練 |
|
數據要求 |
成對偏好 + 獎勵模型訓練數據 |
成對偏好數據 |
單條好/壞標籤 |
|
算力 & 工程 |
★★★★★ |
★★★ |
★★ |
|
對齊精細程度 |
★★★★★(可多維度綜合) |
★★★★(對話/任務效果很好) |
★★(粗粒度好/壞) |
|
典型適用場景 |
通用大模型、追求 SOTA 的大廠 |
垂直問答、領域助手、開源模型 |
安全防護、粗對齊、低預算項目 |
如果用一句話給不同類型團隊提建議:
● 大廠 / 研究機構
有工程團隊、有算力、有大量標註資源:優先採用 PPO+RM,在此基礎上再探索 GRPO、GSPO 等更前沿算法。
● 中小型團隊 / 垂直應用
有一定數據 & 預算,希望在一個細分領域做出體驗不錯的模型,DPO就是非常務實的首選:成本可控、效果明顯、社區實踐多、工具鏈成熟(如 HuggingFace TRL)。
● 個人開發者 / 極度預算敏感項目
手裏只有少量“好/壞”反饋,或者主要依賴線上用户點擊、評分:從 KTO 起步,把最差的回答先“擋下去”,再視情況逐步升級到 DPO。
但事實上,大量開源優質數據都可以在LLaMA-Factory Online上輕鬆獲得,你也可以在這個平台直接用高算力顯卡落地你的想法,所以從DPO起步是完全可以的。
LLaMA-Factory Online已經把過去需要專業工程團隊才能搭起來的流水線,做成了一個開箱可用的在線一站式平台:
● 無配置負擔——瀏覽器打開即可訓練,無需寫腳本、配環境、調依賴
● 支持全流程訓練:SFT、DPO、KTO、PPO、LoRA、QLoRA 全套都能跑
● 高性價比算力——H20、A100、4090 等多種 GPU 即開即用
● 兼容 HuggingFace / OpenAI 接口,訓練後的模型可直接部署上線
● 支持主流大模型:Llama、Qwen、Baichuan、Gemma、Mistral……想訓就訓
你不再需要幾十萬的集羣成本,也不用自己搭 RLHF 訓練框架,一個瀏覽器 + 一點訓練數據,你就能和大廠同款技術體系賽跑。對於想快速驗證想法、打造垂直領域智能體、或在真實業務中使用大模型的團隊來説,這就是實打實的生產力提升。