

僅用1.6萬張醫學影像,我們讓大模型學會了“看片子”。
患者提問:“請使用中文詳細描述這張圖像並給出你的診斷結果。”
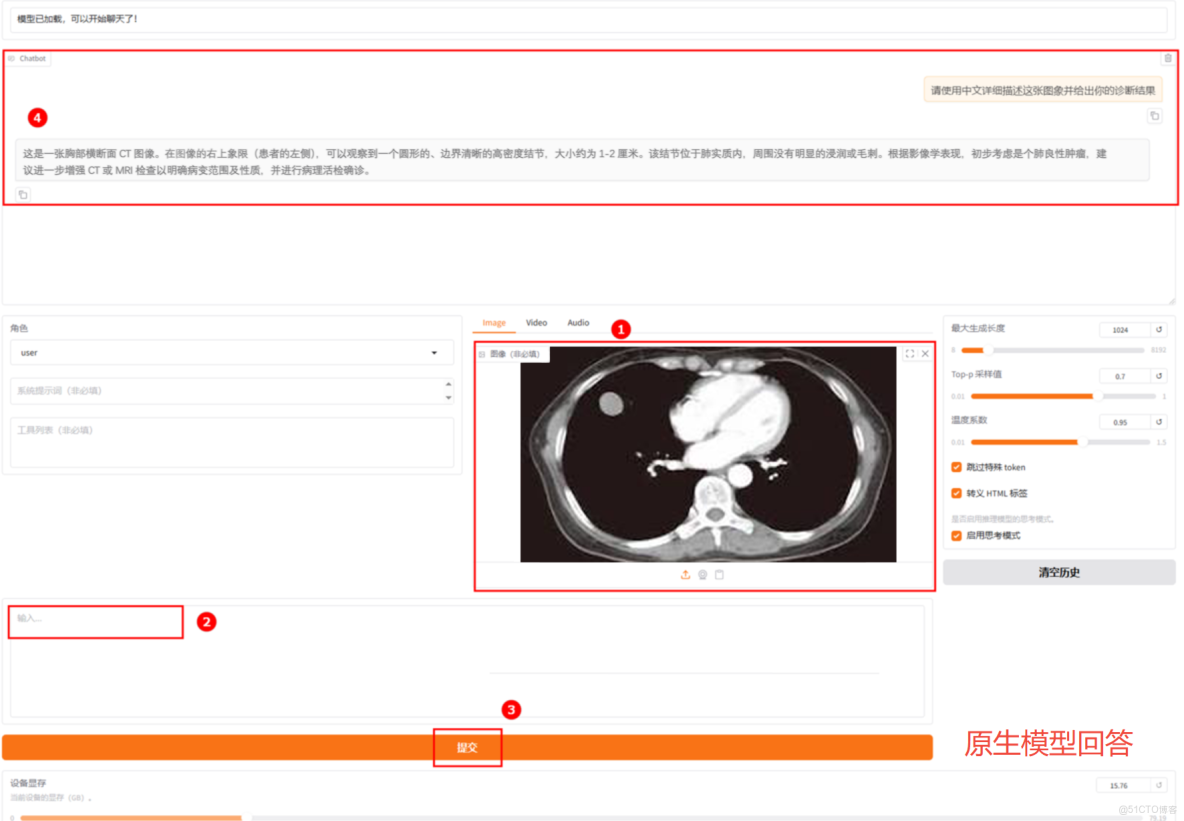
這是微調前模型的回答。雖然能夠識別出基本病變,但其分析存在明顯不足,描述過於簡略,僅關注單一病灶而忽略了圖像中實際存在的雙肺多發性結節,且診斷結論過於武斷,直接定性為"良性腫瘤",缺乏嚴謹的鑑別診斷思路,臨牀參考價值有限。
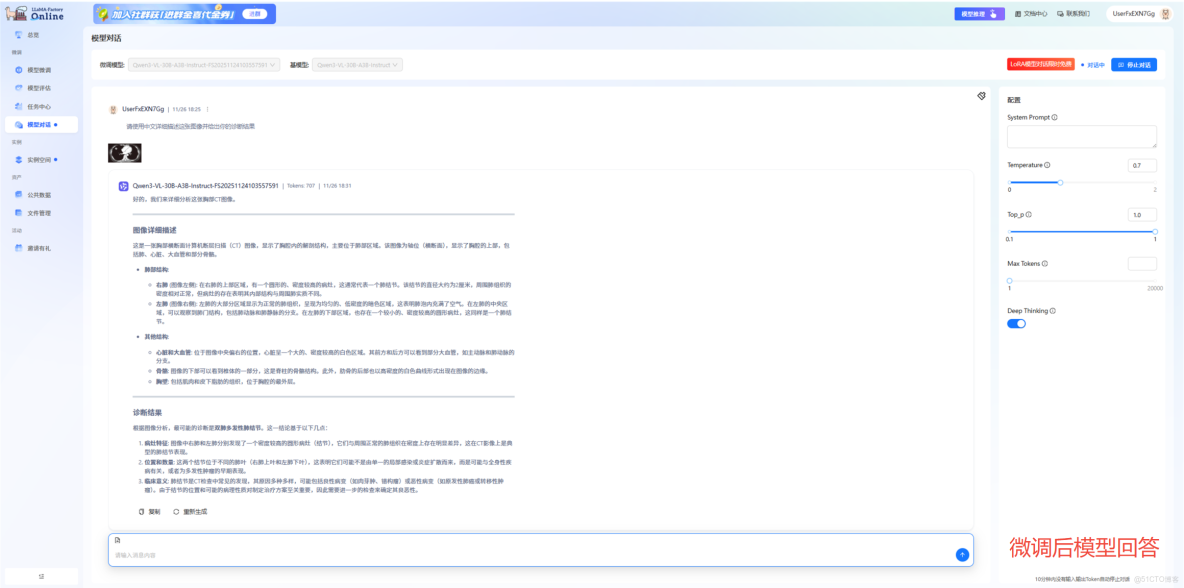
這是微調後模型的回答。它成功化身為“嚴謹的放射科醫生”,不僅準確定位雙肺病灶,系統分析肺部結構、心臟大血管和骨骼關係,更能從病灶特徵、位置分佈和臨牀意義多個維度進行專業解讀,提供完整的鑑別診斷思路,其描述精準、邏輯嚴密、術語規範,已達到輔助醫生進行臨牀決策的實用水平。
通過以上對比可以直觀地看到,經過高質量數據微調後的模型,成功地從一位“門外漢”進化為了可靠的“AI放射科醫生”。
一、項目背景:打破醫療AI的“不可能三角”
當前,通用視覺大模型在醫療影像場景中存在三大瓶頸:
● 細節捕捉弱:難以看懂高分辨率(CT/MR)影像中的微小病灶
● 顯存佔用高:動輒數十GB的顯存需求,邊緣設備跑不動,難以臨牀部署;
● 專業表述差:生成內容缺乏臨牀術語,可信度低,難以支撐臨牀實時分析需求。
今天,我們將完整揭秘:如何基於LLaMA-Factory Online,僅用 1.6萬條數據,在Qwen3-VL-30B-A3B模型上,訓練出一個真正的“醫療影像專家”。我們不僅會講“怎麼練”,更會用實測數據告訴你“怎麼用”——單張RTX 4090就能部署!
二、方案設計:稀疏激活 + 高效微調
在醫療場景下,我們面臨着“既要馬兒跑,又要馬兒少吃草”的悖論:
● 要精度: 必須看懂高分辨率CT/MR,參數量不能小(30B級別)
● 要成本: 醫院邊緣設備顯存有限,跑不動龐然大物
我們在LLaMA-Factory Online上選擇了Qwen3-VL-30B-A3B-Instruct,正是因為它採用了“稀疏激活(Active 3B)”架構。它擁有300億參數的知識儲備,但推理時僅激活30億參數——這為低成本落地埋下了伏筆。
|
配置參數 |
配置項 |
説明 |
|
模型 |
Qwen3-VL-30B-A3B-Instruct |
稀疏激活架構,僅激活3B參數,支持高分辨率動態切換,極大節約計算資源 |
|
數據集 |
MedTrinity-25M (16k樣本子集) |
選取的數據集是MedTrinity-25M子集中的其中一個(16163張圖片),MedTrinity-25M是當前規模最大的公開醫學影像-文本對數據集,涵蓋超過2500萬張圖像,涉及CT、MR、X-Ray等多種模態,併為65多種疾病提供了多層次的註釋 |
|
GPU |
H800 * 4(推薦) |
模型規模較大,建議配置足夠顯存以確保穩定高效訓練 |
|
微調方法 |
LoRA |
顯著降低計算與存儲成本,實現大模型的高效輕量化微調 |
三、訓練實戰:從數據到可對話的醫療專家
1、數據加工:把“醫學教材”餵給AI
高質量、格式規範的數據集是成功的關鍵。我們通過以下流程將原始醫學數據轉化為模型可理解的“教材”:
● 下載數據:從MedTrinity-25M數據集中精選1.6萬條高質量影像-文本對
● 格式轉換:使用定製Python腳本,將原始數據轉換為LLaMA-Factory Online支持的 ShareGPT多模態對話格式
● 質量驗證:通過隨機抽樣與基線模型測試驗證數據有效性。
💡核心代碼詳解:我們提供了完整的數據格式轉換腳本,將原始Parquet數據轉換為模型可訓練的格式。
#多模態數據格式轉換代碼
import os
import json
import random
from tqdm import tqdm
import datasets
def save_images_and_json(ds, ratio=0.1, output_dir="mllm_data"):
"""
保存數據集中的圖像,並且構建多模態訓練集和驗證集。
參數:
ds: 數據集對象,包含圖像和描述。
ratio: 驗證集比例,默認為 0.1。
output_dir: 輸出目錄,默認為 "mllm_data"。
"""
# 創建輸出目錄
os.makedirs(output_dir, exist_ok=True)
all_train_data = [] # 多模態訓練數據
all_val_data = [] # 多模態驗證數據
total_samples = len(ds)
val_index = set(random.sample(range(total_samples), int(ratio * total_samples)))
# 遍歷數據集中的每個項目
for idx, item in tqdm(enumerate(ds), total=total_samples, desc="Processing"):
img_path = os.path.join(output_dir, f"{item['id']}.jpg")
image = item["image"]
# 保存圖像
image.save(img_path)
sample = {
"messages": [
{
"role": "user",
"content": "<image>圖片中的診斷結果是怎樣?"
},
{
"role": "assistant",
"content": item["caption"] # 從數據集中獲取的描述
}
],
"images": [img_path] # 圖像文件路徑
}
if idx in val_index:
all_val_data.append(sample)
else:
all_train_data.append(sample)
# 將數據保存到 JSON 文件
train_json_path = os.path.join(output_dir, "mllm_train_data.json")
val_json_path = os.path.join(output_dir, "mllm_val_data.json")
with open(train_json_path, "w", encoding="utf-8") as f:
json.dump(all_train_data, f, ensure_ascii=False, indent=2)
with open(val_json_path, "w", encoding="utf-8") as f:
json.dump(all_val_data, f, ensure_ascii=False, indent=2)
if __name__ == "__main__":
# 加載數據集
ds = datasets.load_dataset("parquet", data_files="../dataset/data_sft/train-00000-of-00010.parquet")["train"]
# 保存圖像並構建多模態訓練/驗證集
save_images_and_json(
ds,
ratio=0.2,
output_dir="/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data"
)轉換後的數據示例如下:
[
{
"messages": [
{
"role": "user",
"content": "<image>圖片中的診斷結果是怎樣?"
},
{
"role": "assistant",
"content": "這是一張非增強腦部計算機斷層掃描(CT)圖像,圖中未見任何醫療設備。位於圖像中央的興趣區域可見密度改變,提示腦內出血。該異常區域與周圍腦組織分界清晰,可能為腦實質內血腫或出血。其位置及表現可能與鄰近腦組織存在關聯,進而產生佔位效應或導致顱內壓升高。"
}
],
"images": [
"/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data/8031efe0-1b5c-11ef-8929-000066532cad.jpg"
]
},
{
"messages": [
{
"role": "user",
"content": "<image>圖片中的診斷結果是怎樣?"
},
{
"role": "assistant",
"content": "這是一張腦部非增強計算機斷層掃描(CT)圖像,顯示雙側大腦半球,圖中無醫療器械。感興趣區域位於腦中央偏下方,約佔圖像面積的 1.1%,表現異常,提示可能存在病變:其密度或紋理改變符合顱內出血特徵。該區域與周圍腦結構緊鄰,可能對鄰近組織產生壓迫,或受鄰近組織影響,提示病變可能正在擴展,並可能影響周邊組織功能。"
}
],
"images": [
"/workspace/user-data/codelab/Qwen3-VL/dataset/mllm_data/803201d1-1b5c-11ef-bba0-000066532cad.jpg"
]
},
]2、模型訓練:找到醫療影像的“學習密碼”
訓練一個專業模型,不僅是“跑起來”,更要“學得好”。參數調優就是尋找最佳“學習方案”的過程。我們通過嚴謹的對比實驗,揭示了影響醫療影像學習效果的關鍵因素。
(1)DeepSpeed Stage選擇是性能關鍵
在微調30B級別大模型時,很多人的第一反應是無腦開DeepSpeed Stage 3以節省顯存。但在醫療影像這種需要極高精度的任務中,我們通過實戰驗證了一個殘酷的真相:
● 誤區(DeepSpeed Stage 3): 雖然顯存佔用低,但在醫療細粒度特徵上,Loss 下降緩慢。原因在於Stage 3的“參數延遲+梯度噪聲”機制,干擾了模型對微小病灶的學習
● 正解(DeepSpeed Stage 2): 雖然顯存佔用稍高,但loss曲線如絲般順滑,收斂更徹底
❤️獨家心法:在LLaMA-Factory Online配置時,若顯存允許(如使用 H800),請果斷選擇Stage 2。如果必須用Stage 3,請務必配合“放大Global Batch Size+拉長Warmup”的組合拳來彌補性能損失。
(2)參數配置對比實驗與分析
為驗證上述發現,在任務模式下,我們對模型進行了兩組微調實驗(參數一和參數二),以評估不同配置的效果。兩組實驗的變量僅為 per_device_train_batch_size(32,4)和DeepSpeed(3,2)參數,其他條件完全相同。具體參數差異如下表所示:
|
配置參數 |
參數説明 |
參數一 |
參數二 |
|||
|
基礎配置 |
||||||
|
model |
訓練用的基模型 |
Qwen3-VL-30B-A3B-Instruct |
Qwen3-VL-30B-A3B-Instruct |
|||
|
dataset |
訓練使用的數據集名稱 |
mllm_train_data |
mllm_train_data |
|||
|
stage |
訓練方式 |
sft |
sft |
|||
|
finetuning_type |
微調方法 |
lora |
lora |
|||
|
進階配置 |
||||||
|
LR Scheduling Type |
動態調整學習率的方式 |
cosine |
cosine |
|||
|
Max Gradient Norm |
梯度裁剪的最大範數,用於防止梯度爆炸 |
1.0 |
1.0 |
|||
|
訓練配置 |
|
|||||
|
Learning Rate |
學習率 |
5e-05 |
5e-05 |
|||
|
Epochs |
訓練輪數 |
2 |
2 |
|||
|
per_device_train_batch_size |
單GPU批處理大小 |
32 |
4 |
|||
|
Gradient Accumulation |
梯度累計,將一個完整批次的梯度計算拆分為多個小批次,逐步累積梯度,最後統一更新模型參數 |
8 |
8 |
|||
|
Save steps |
訓練過程中每隔多少個訓練步保存一次模型 |
200 |
200 |
|||
|
Warmup Ratio |
將學習率從零增加到初始值的訓練步數比例 |
0 |
0 |
|||
|
Chat Template |
基模型的對話模版,訓練和推理時構造prompt的模版 |
qwen3 |
qwen3 |
|||
|
效率與性能配置 |
||||||
|
Mixed Precision Train |
混合精度訓練,模型在訓練或推理時所使用的數據精度格式,如 FP32、FP16或BF16 |
bf16 |
bf16 |
|||
|
分佈式配置 |
||||||
|
DeepSpeed |
Deepspeed Stage是DeepSpeed中ZeRO(Zero Redundancy Optimizer)優化技術的階段參數,其範圍是none、2、3。參數越大,意味着模型狀態的分片程度越高,每個GPU的內存佔用越少,但同時通信開銷也可能越大 |
3 |
2 |
|||
|
數據參數配置 |
||||||
|
Max Sample Size |
每個數據集的最大樣本數:設置後,每個數據集的樣本數將被截斷至指定的max_samples |
100000 |
100000 |
|||
|
Cutoff Length |
輸入的最大token數,超過該長度會被截斷 |
2048 |
2048 |
|||
|
Preprocess Workers |
預處理時使用的進程數量 |
32 |
32 |
|||
|
日誌配置 |
||||||
|
Logging Steps |
日誌打印步數 |
5 |
5 |
|||
|
LoRA配置 |
||||||
|
LoRARank |
LoRA微調的本徵維數 r,r 越大可訓練的參數越多 |
8 |
8 |
|||
|
LoRAScalling Factor |
LoRA縮放係數。一般情況下為 lora_rank * 2 |
16 |
16 |
|||
|
Random dropout |
LoRA微調中的dropout率 |
0 |
0 |
|||
|
LoRAModules |
Lora作用模塊 |
all |
all |
|||
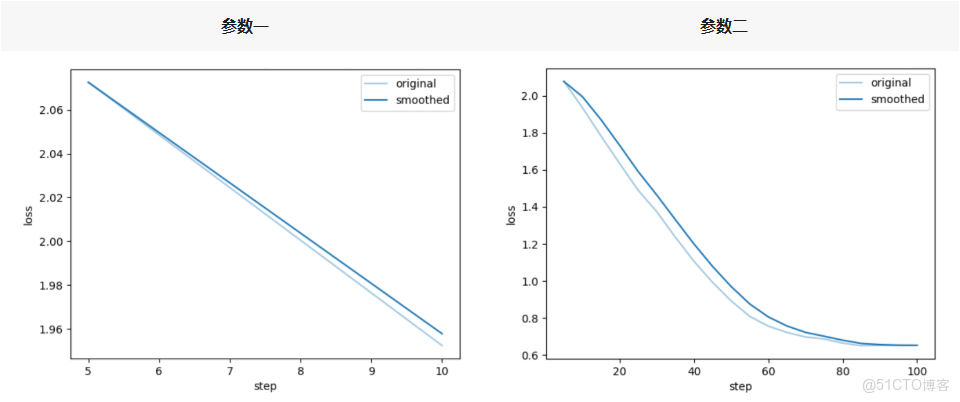
通過任務模式完成兩組參數配置的模型微調後,從loss對比結果來看,相同硬件與數據集條件下,deepseed 3(參數一)方案訓練速度更快,但微調階段loss顯著上升;deepseed 2(參數二)方案雖訓練速度略有下降,卻能更有效地壓低loss。具體來看:
● deepseed 3訓練速度的提升,核心得益於 “小塊通訊 + 微批次自動放大” 帶來的帶寬優化;
● deepseed 3微調loss上漲的本質,是 “參數延遲 + 梯度噪聲” 導致模型收斂效果變差;
⭐選型建議:若顯存充足,優先選擇deepseed 2方案以追求更優指標;若顯存不足需使用deepseed 3,則需同步通過放大global batch、拉長 warmup時長、降低學習率(lr)的方式彌補收斂性能。
通過反覆實驗,我們總結出了一套適用於Qwen3-VL醫療微調的參數心法:
● LR Scheduler(學習率調度): 放棄Linear!在多模態圖文對齊任務中,Linear衰減表現平平。請選擇 Cosine + Warmup,它能更好地適配視覺特徵的學習節奏
● Epoch(訓練輪數):在16k數據場景下,3個Epoch是性能拐點;第4個Epoch起訓練Loss仍降,但驗證指標不再上升,屬於典型過擬合;5k 小數據場景下可拉到6~8Epoch
● LoRARank:醫療影像細節極多(如微小結節、毛刺徵),低Rank(如8以下)表達能力不足。Rank 32是效果與成本的性價比拐點
● Alpha值: 死磕公式Alpha = Rank×2,穩定性最佳
● dropout:數據量 ≤ 10k時,設置dropout=0.05 可有效防過擬合;數據 > 10k:可直接設為0
3、效果驗證:從“業餘”到“專業”的飛躍
經過精心的微調,模型的性能實現了質的飛躍。我們通過量化指標和定性分析,全方位評估其提升效果。
(1)指標對比:數十倍至上千倍的提升
下面的數據清晰地展示了模型在微調前後的巨大變化。其中,參數二(DeepSpeed Z2方案)在各項文本生成質量指標上達到了最優水平。
|
評估指標 |
微調前(原生模型) |
參數一微調後 (Z3方案) |
參數二微調後(Z2方案) |
|
BLEU-4 |
0.806 |
27.653 |
92.375 |
|
ROUGE-1 |
2.778 |
38.069 |
96.114 |
|
ROUGE-2 |
0.006 |
16.363 |
94.036 |
|
ROUGE-L |
2.013 |
20.695 |
94.286 |
指標解讀:
● BLEU-4衡量生成文本與專業參考答案在詞組和表達上的匹配度
● ROUGE-1/2/L綜合評估生成內容的關鍵詞覆蓋、短語搭配和句法連貫性
結論一目瞭然:採用Z2方案微調的模型(參數二),其生成質量遠超原生模型和Z3方案,在專業術語、句式結構和臨牀邏輯上都與標準醫學描述高度一致。
(2)生成質量:從“無法使用”到“專業優秀”
● 微調前(原生模型):各項指標極低,生成內容與參考答案關聯性微弱,邏輯混亂,完全無法滿足專業場景需求
● 微調後(參數二模型):
○ BLEU-4高達92.37,意味着模型能精準復現醫學報告中的專業詞彙與表達
○ ROUGE系列指標均超過94,代表其在關鍵詞捕捉、專業短語運用和長篇報告的連貫性上表現出色
○ 生成文本的質量已達到優秀級別,具備臨牀應用的潛力
(3)效率提升:速度與精度的雙重勝利
除了生成質量,推理效率也得到顯著優化。
|
評估指標 |
微調前(原生模型) |
參數一微調後 (Z3方案) |
參數二微調後(Z2方案) |
|
predict_samples_per_second |
0.773 |
0.057 |
0.194 |
|
predict_steps_per_second |
0.048 |
0.002 |
0.048 |
|
predict_runtime |
4179.834 |
56431.560 |
16668.369 |
微調不僅解決了原生模型生成質量“不可用”的核心問題,更在效率上實現了超越。最終得到的模型在專業性、準確性和響應速度上取得了完美平衡,可立即投入醫學影像報告生成、輔助診斷等嚴肅多模態場景。
4、實戰對話:真正的“AI放射科醫生”
模型性能的最終檢驗標準在於實戰。我們對比了參數一(Z3方案)與參數二(Z2方案)微調後的模型對同一張胸部CT影像的分析,結果顯示兩者均達到專業水準,但在分析的全面性、細緻程度和診斷深度上存在顯著差異。
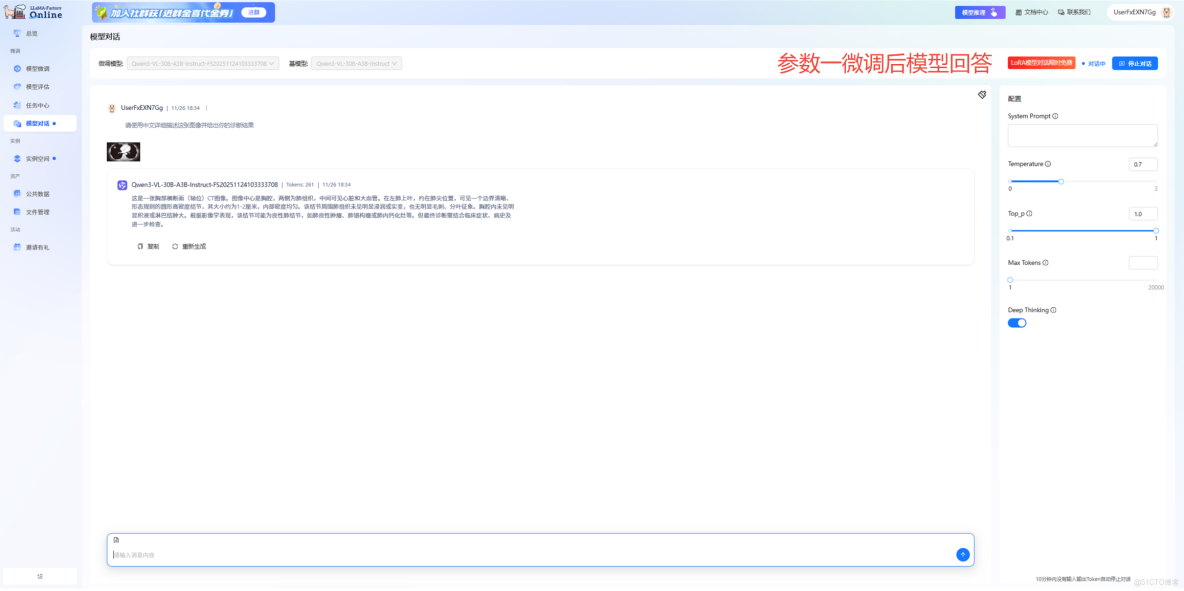
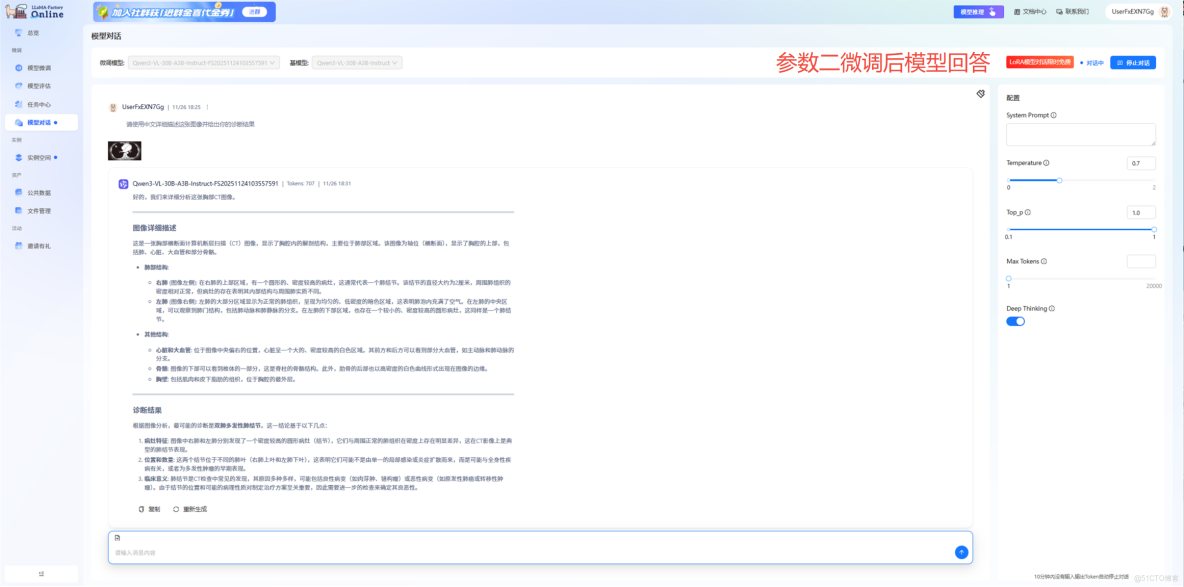
通過對比分析,我們驗證了一個重要結論,參數二(Z2方案)在以下方面表現顯著更優:
● 觀察敏鋭度:能夠發現圖像中的多個病灶,避免漏診
● 分析系統性:提供從解剖結構到病變特徵的完整分析框架
● 診斷嚴謹性:基於醫學證據進行推理,給出合理的鑑別診斷
● 臨牀實用性:回答具有直接臨牀參考價值
這一結果與我們之前的實驗數據高度吻合——Z3方案雖然在訓練速度上稍慢,但能夠學習到更豐富的醫學知識結構和診斷邏輯,最終生成的影像報告更接近資深放射科醫生的專業水準。
通過Qwen3-VL-30B-A3B-Instruct與LLaMA-Factory Online,我們再次驗證了:即使是頂尖的通用大模型,在經過高質量的領域數據微調後,也能在高度專業的場景(如醫療影像分析)中展現出卓越性能。
技術的價值在於落地。無論是醫療、金融、法律還是教育,LLaMA-Factory Online 致力於將大模型微調的技術複雜性封裝起來,讓每一位開發者和企業都能輕鬆打造屬於自己的、安全可靠的“行業專家”。