

深夜十一點,李老師揉了揉發酸的眼睛,面前還有三十多篇作文等待批改。
這是無數語文教師的日常寫照——繁重的批改負擔、難以完全統一的標準、反饋到達學生手中時已失去時效性。
而在AI技術日新月異的今天,我們能否讓機器真正“理解”一篇作文的優劣?
答案是肯定的。基於Qwen3-VL-30B-A3B-Instruct大模型,我們成功打造了一款能夠深度理解中文作文的智能閲卷助手,讓作文批改走向自動化、標準化、即時化。
在這個項目中,我們對同一篇《知之·行之·思之》進行評分,兩者都能讀懂文章、給出評價,但風格和“老師味兒”差異非常明顯:
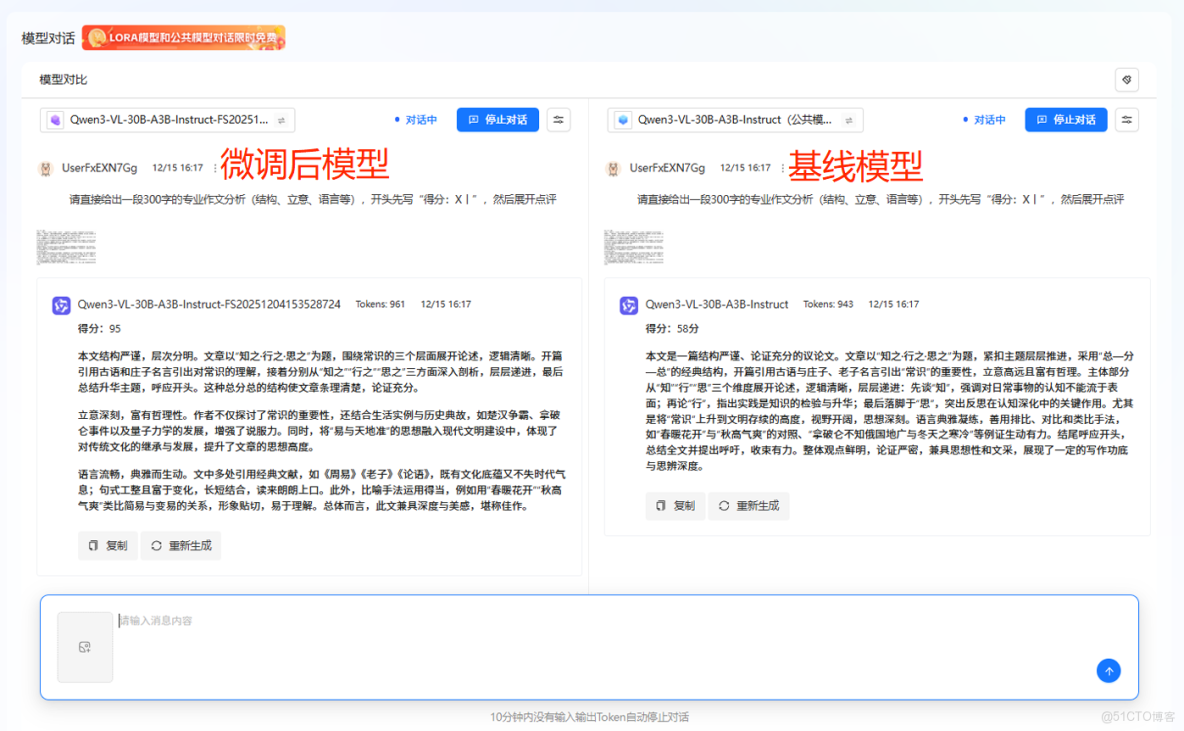
基線模型更偏向概括性、理論化的評析風格。雖然也提及“結構嚴謹、論證充分”,但表述較為籠統,未針對具體內容展開細析,整體語言偏向正式,結構較為平鋪直敍,更像一個概括性的“評審意見”。
微調後模型則呈現出清晰、結構化的語文教師批改風格。評語嚴格遵循“總評—分項分析—總結”的結構,從“結構”“立意”“語言”三個維度展開,每部分都結合原文內容進行具體説明,並引用文中實例(如“春暖花開”“秋高氣爽”的比喻),語言自然流暢,建議具體,貼近教學實際。
下面這張表就是兩者在關鍵維度上的對比,可以非常直觀地看到差別:
|
對比維度
|
基線模型效果
|
微調後模型效果
|
|
分形式
|
百分制,給出具體分數(如58分)
|
百分制,給出具體分數(如95分)
|
|
評語結構
|
整體概括為主,結構較鬆散,分點不明確
|
結構清晰,常按“結構—立意—語言”等維度展開,層次分明
|
|
語言風格
|
語言正式、概括,偏向書面評審
|
語言自然、具體,貼近教師日常用語,有親和力
|
|
關注重點
|
側重整體印象與理論判斷,較少展開細節
|
注重結合原文內容進行細部分析,舉例説明,指向明確
|
|
學生閲讀門檻
|
表述抽象,對學生的直接指導性較弱
|
表述具體,學生能清楚理解優點與可改進之處
|
|
教學適配度
|
適用於需要快速總體評價的場景
|
適用於日常批改、反饋指導,符合實際教學互動習慣
|
傳統自動化作文評分系統多基於規則和淺層特徵,而大模型帶來了根本性變革——它不再只是“檢查”,而是真正“理解”。我們選用的Qwen3-VL-30B-A3B-Instruct模型,通過300篇精選高中作文數據的指令在LLaMA-Factory Online上進行微調,深度對齊了中文作文的評分標準。模型不僅能評估語言表達的規範性,更能理解文章的邏輯結構、思想深度和情感價值——這些正是優秀作文的靈魂所在。
實戰路徑:從數據到智能的蜕變
數據準備和清洗
本項目選用了面向中國高中階段的中文作文數據集:AES-Dataset。這個數據集小而精,聚焦高中場景。
● 學生羣體:全部來自中國高中生,話題接近高考/模擬考作文
● 文體類型:以議論文、記敍文為主,需要一定邏輯推理與表達能力
● 數據規模:共300篇精選作文樣本,編號從A-0001至A-0300
雖然數量不大,卻非常適合做:小樣本微調、LoRA/QLoRA輕量化實驗、驗證教育垂直領域精調的“效果上限”。
數據結構:標準化設計,方便工程介入
● 元數據文件 scores.txt:記錄作文ID、標題、人工評分
● 作文文本 /essays 文件夾:每篇作文一個txt文件,天然保留文章結構信息
不同於常規文本處理,我們將作文轉化為圖片格式輸入模型。這一看似額外的步驟實則暗含深意:它完整保留了作文的版面結構、修改痕跡、書寫特色,讓模型能夠像人類教師一樣“看到”作文的全貌。
高效微調全流程
在LLaMA-Factory Online平台上,我們採用LoRA微調方法,僅用單張H800A GPU、45分鐘就完成了模型訓練,顯著降低了計算成本。關鍵配置參數如下:
|
配置參數
|
參數説明
|
參數
|
|
基礎配置
|
|
|
|
model
|
訓練用的基模型
|
Qwen3-VL-30B-A3B-Instruct
|
|
dataset
|
訓練使用的數據集名稱
|
aes_data
|
|
stage
|
訓練方式
|
sft
|
|
finetuning_type
|
微調方法
|
lora
|
|
進階配置
|
|
|
|
LR Scheduling Type
|
動態調整學習率的方式
|
cosine
|
|
Max Gradient Norm
|
梯度裁剪的最大範數,用於防止梯度爆炸
|
1.0
|
|
訓練配置
|
|
|
|
Learning Rate
|
學習率
|
5e-05
|
|
Epochs
|
訓練輪數
|
3
|
|
per_device_train_batch_size
|
單GPU批處理大小。
|
2
|
|
Gradient Accumulation
|
梯度累計,將一個完整批次的梯度計算拆分為多個小批次,逐步累積梯度,最後統一更新模型參數
|
4
|
|
Save steps
|
訓練過程中每隔多少個訓練步保存一次模型
|
200
|
|
Warmup Ratio
|
將學習率從零增加到初始值的訓練步數比例
|
0
|
|
Chat Template
|
基模型的對話模版,訓練和推理時構造prompt的模版
|
qwen3
|
|
效率與性能配置
|
|
|
|
Mixed Precision Train
|
混合精度訓練,模型在訓練或推理時所使用的數據精度格式,如 FP32、FP16 或 BF16
|
bf16
|
|
數據參數配置
|
|
|
|
Max Sample Size
|
每個數據集的最大樣本數:設置後,每個數據集的樣本數將被截斷至指定的 max_samples
|
100000
|
|
Cutoff Length
|
輸入的最大 token 數,超過該長度會被截斷
|
2048
|
|
Preprocess Workers
|
預處理時使用的進程數量
|
32
|
|
日誌配置
|
|
|
|
Logging Steps
|
日誌打印步數。
|
5
|
|
LoRA配置
|
|
|
|
Lora Rank
|
LoRA 微調的本徵維數 r,r 越大可訓練的參數越多
|
8
|
|
LoRA Scalling Factor
|
LoRA 縮放係數。一般情況下為 lora_rank * 2
|
16
|
|
Random dropout
|
LoRA 微調中的 dropout 率
|
0
|
|
LoRA Modules
|
Lora作用模塊
|
all
|
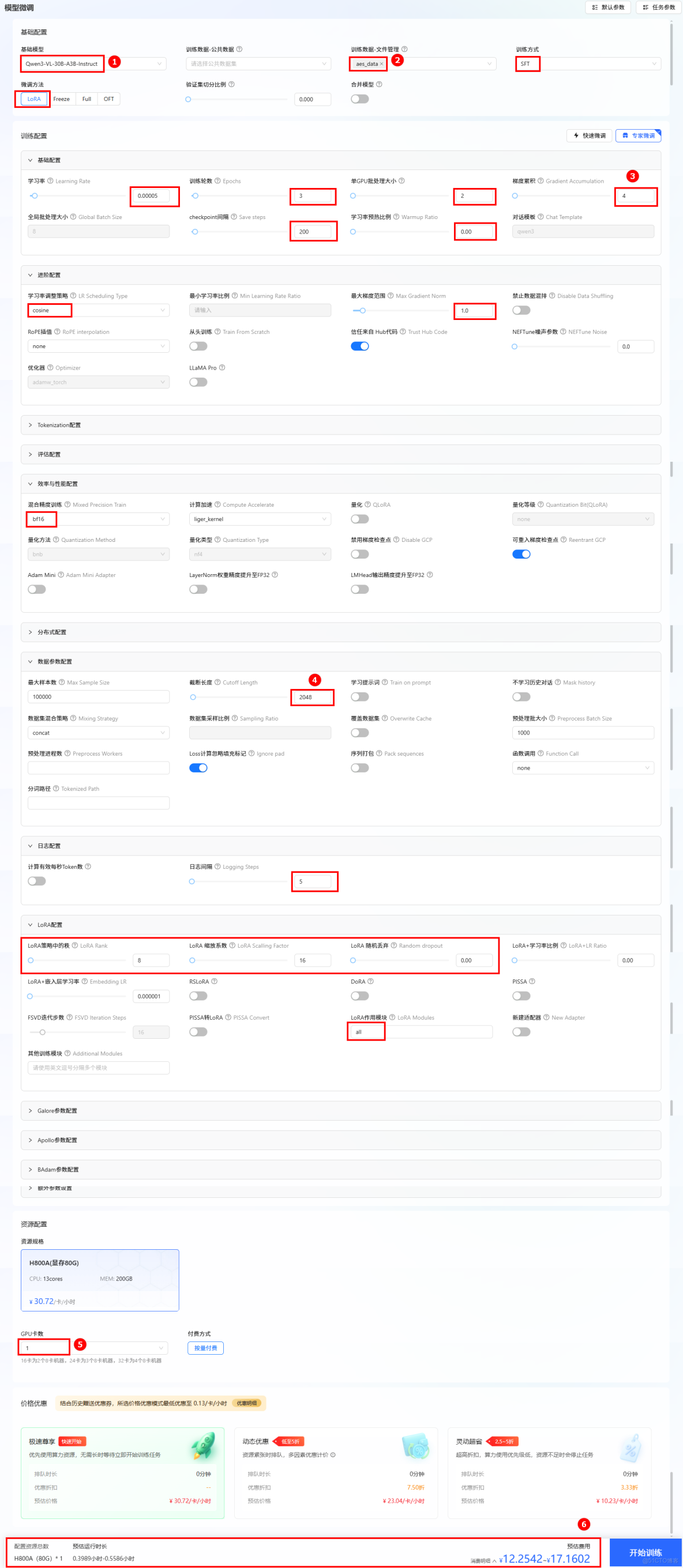
開始進行模型訓練,通過任務中心可以查看任務的詳細信息、超參數、訓練追蹤和日誌。
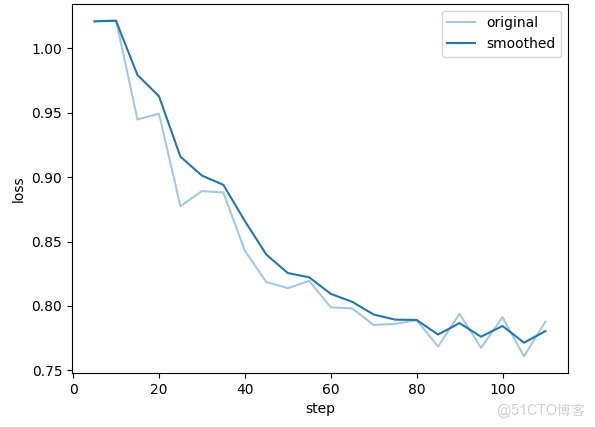
通過Loss曲線可以看出訓練有效且逐步收斂,但存在一定波動,可通過調整訓練策略(如增大 batch_size、微調學習率)進一步優化穩定性。
效果驗證:不只是打分更是理解
模型訓練完成後,我們進行模型評估,評估結果令人振奮:
● ROUGE-1/ROUGE-2指標表現不錯:説明生成內容在 “字詞、短語層面” 與參考文本的覆蓋度、匹配度較高
● BLEU-4處於中等水平:意味着生成文本與參考文本的長短語重合度還有提升空間
我們進行模型對話,模型生成的評語不再模板化,而是針對每篇作文的特點提供個性化反饋。
在實際對話測試中,模型展現了令人驚喜的“教學敏感度”。它生成的評語不再模板化,而是針對每篇作文的特點提供個性化反饋——既肯定優點,也指出不足,其給出的得分與作文的實際質量匹配度較高。這樣的反饋,已經接近資深教師的指導水平。
未來已來:智能閲卷的可實現性
基於Qwen3-VL大模型的智能閲卷助手,正悄然改變着一線教學的真實場景。它讓教師得以從深夜的案頭批改中抽身,將心力轉向更具創造性的教學設計;它讓學生的作文在提交後便能即刻獲得結構清晰、建議具體的專業點評,將漫長的反饋週期轉化為即時的成長對話。這一切,都依託於LLaMA-Factory Online平台所提供的“高效微調”與“即時對話”能力——複雜的大模型技術,由此變得簡單、可用、可落地。
這不僅僅是一個評分工具。它更是一個開始,一個以技術彌合教育資源差異、以智能放大教師專業價值的起點。未來,在LLaMA-Factory Online的持續迭代與賦能下,它可以從“評分”走向“診斷”與“個性化輔導”,更重要的是,隨着數據的不斷積累,模型將越來越“懂”教育,越來越“理解”每一篇文字背後的思考與情感,成為助力師生共同成長的可信賴夥伴。