

就在百度世界大會前夕,全球最具影響力的大模型評測平台LMArena發佈的最新排名,讓海外開發者社區發出了"Baidu is back?"的驚歎。這份發佈於2025年11月初的榜單顯示,國產大模型在中文競技場上實現了對國際頂尖模型的全面反超,這一突破性進展恰如其時地展現了中國AI技術的迅猛發展。
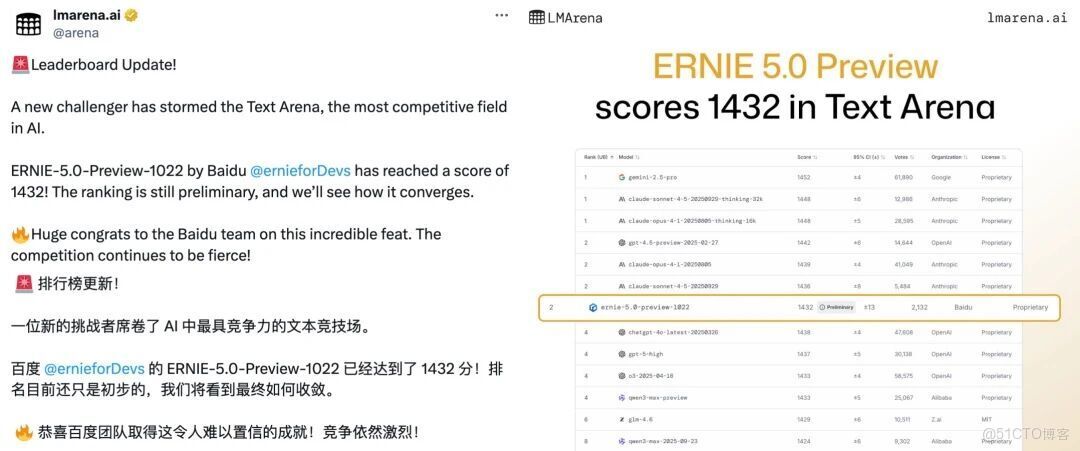
在LMArena最新發布的排名當中,文心全新模型ERNIE-5.0-Preview-1022首次上榜,就登上了文本排行榜全球並列第二、中國第一,超越了被寄予厚望的GPT-5-High。尤其在創意寫作、複雜長文本理解、指令遵循三項,得分亮眼。
LMArena:真實用户投票的"硬核"競技場
與傳統可以"刷分"的靜態基準測試不同,LMArena(Large Model Arena)是由伯克利大學團隊發起、LMSYS Org運營的全球大型語言模型公開評測平台。它採用獨特的"對戰"模式:用户同時與兩個匿名模型對話,僅根據回答內容投票選擇表現更好者。這種由真實用户驅動的眾包評測機制,使其已成為全球最具權威的 AI 模型排行榜與評測系統 之一,含金量不容小覷。因此,文心大模型5.0-Preview的成績,是其核心語言能力、創造力與用户體驗獲得全球範圍認可的證明。以下是LMArena官網的榜單地址:https://lmarena.ai/?mode=direct
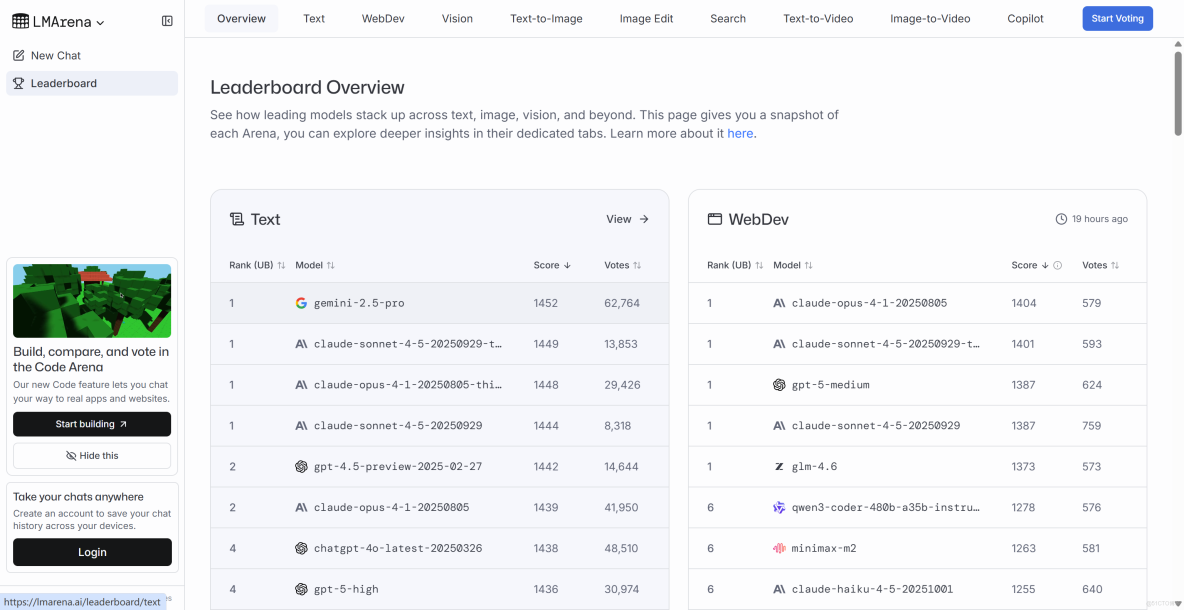
數據見證:中文榜單的格局重塑
根據2025年11月6日的最新中文榜數據,我們可以清晰地看到國產大模型的強勢表現。榜單顯示,累計投票數已達344,730次,涵蓋237個模型,樣本量已足夠支撐其權威性,前排的大致格局如下:
|
排名 |
模型名稱 |
Elo分數 |
投票數 |
團隊/平台 |
是否開源 |
|
1 |
gemini-2.5-pro |
1495±12 |
3237 |
|
否 |
|
2 |
Qwen3-max-preview |
1490±17 |
1304 |
阿里巴巴 |
否 |
|
3 |
GLM-4.6 |
1486±34 |
310 |
智譜AI |
是 |
|
4 |
deepseek-v3.1-thinking |
1473±21 |
872 |
DeepSeek |
是 |
|
5 |
deepseek-v3.1 |
1462±18 |
1115 |
DeepSeek |
是 |
|
6 |
deepseek-v3.2-exp-thinking |
1456±35 |
288 |
DeepSeek |
是 |
|
7 |
deepseek-r1-0528 |
1441±19 |
1,047 |
DeepSeek |
是 |
|
8 |
kimi-k2-0711-preview |
1448±16 |
1,592 |
Moonshot AI |
是 |
|
9 |
kimi-k2-0905-preview |
1438±23 |
664 |
Moonshot AI |
是 |
|
10 |
qwen3-235b-a22b-instruct-2507 |
1456±14 |
1,946 |
阿里巴巴 |
是 |
前10名中,國產模型強勢佔據8席,形成了壓倒性優勢。而曾經的現象級產品GPT-4 Turbo中文得分僅為1308±8分,排名跌至第99位左右,與頭部國產模型的差距超過150分。這一數據對比,清晰地勾勒出中文AI競技場的格局鉅變——GPT-4 Turbo已經從"天花板",變成了"上一代標杆"。
技術突破:從追趕到領跑的三重驅動
這一歷史性突破的背後,是國產大模型在技術上的多重突破。國產模型在訓練中注入海量中文對話和知識語料,在對齊策略上更貼閤中文的語氣、邏輯和文化語境。這種深度優化讓模型在理解中文用户意圖時表現更加精準自然,在涉及中國文化、習語和思維方式的對話中展現出明顯優勢。此外,開源策略成為國產模型崛起的重要推手。各大廠商推出的開源模型不僅在性能上表現出色,更為整個生態的技術迭代提供了堅實基礎。
|
模型 |
參數規模 |
上下文長度 |
開源協議 |
|
GLM-4.6 |
355B (MoE,32B激活) |
200K |
MIT |
|
DeepSeek-R1 |
671B |
128K |
MIT |
|
Kimi-K2 |
1T (32B激活) |
256K |
Modified MIT |
|
Qwen3-235B |
235B |
128K |
Apache 2.0 |
這些開源模型以極高的性價比提供接近閉源模型的性能,並支持企業私有化部署和二次微調,為產業應用提供了更多可能性。
大模型落地難題:從技術到應用的關鍵一躍
儘管大模型技術發展迅猛,但在實際落地過程中仍面臨三大"卡脖子"的難題:一模型輸出"AI味"過重,缺乏個性化和人情味;二是對金融、醫療等專業領域的複雜業務邏輯理解有限;三是理解力不足,執行復雜任務和智能編排的能力存在明顯短板。這些問題嚴重限制了AI技術在更廣泛場景中的應用潛力。而LLaMA-Factory Online恰好為上述難題提供了完善的解決方案。
LLaMA-Factory Online深度適配Qwen全系列、GLM系列、DeepSeek系列等上百個主流國產模型,為用户提供開箱即用的模型支持。無論是基於Qwen3打造智能客服系統,還是利用GLM-4.6構建行業專家助手,都能提供最便捷的實踐路徑。通過集成LoRA、QLoRA等先進微調技術,在保持基座模型強大能力的同時,顯著提升了模型的個性化表達和專業領域理解能力,大幅降低訓練成本,真正實現了大模型技術從"可用"到"好用"的關鍵跨越。
國產大模型在LMArena上的突破性表現,標誌着中文AI領域迎來了從量變到質變的關鍵轉折。從"追趕者"到"並行者",再到部分領域的"領跑者",這一轉變不僅體現了技術實力的提升,更展現了中國AI生態的蓬勃活力。
更值得關注的是,這一技術變革為開發者與企業帶來了實實在在的機遇。在中文應用場景下,國產大模型已從"備選"變為"首選",不僅在中文理解和文化適配方面表現更優,還能通過開源模式大幅降低使用成本,同時滿足企業數據安全的需求。
對於廣大開發者和企業而言,現在正是擁抱國產大模型、構建下一代AI應用的最佳時機。LLaMA-Factory Online作為大模型微調平台,將繼續為產業界提供最先進的技術支持和最完善的解決方案,與所有AI從業者共同開創中國人工智能的新篇章。
*本文數據來源於LMArena官方榜單。LLaMA-Factory Online持續跟蹤最新模型進展,為開發者提供最前沿的技術支持。



