
一、前言:科研文獻處理的痛點與AI工具的破局之道
上週三晚上十點,實驗室的燈還亮着。我對着電腦裏十幾篇待整理的英文論文,第5次打開 PDF 閲讀器、OCR 工具、Excel 表格來回切換 —— 剛把一篇多欄論文的摘要提取出來,格式就亂成了一團;公式識別錯誤導致數據核對返工,好不容易整理完的關鍵詞,還得手動複製粘貼到團隊共享表格裏。
作為一名科研工作者,文獻處理早已成了日常科研的 “隱形負擔”:每週至少8小時耗費在PDF轉文字、信息篩選、數據錄入上,遇到掃描版論文、複雜排版或小語種文獻,傳統OCR工具要麼識別不全,要麼格式錯亂,甚至連公式符號都會變成亂碼;彙總到飛書表格還得二次校對,往往一天下來 “幹活兩小時,整理大半天”。
相信不少科研人都有過類似的困擾:我們需要的是快速提取論文核心信息、高效沉澱研究數據,而不是在多工具切換和重複勞動中消耗精力。傳統工具的短板顯而易見 —— 無法適配學術論文的複雜版式,更難以實現 “解析 - 處理 - 同步” 的全鏈路自動化。
而這一切,正在被 AI 工具的組合創新改變。即使大模型在科研場景深度滲透,但高質量的文檔解析始終是釋放大模型能力的 “第一道門檻”。正是瞄準這一痛點,我用Coze+TextIn+飛書搭建了全自動論文處理AI工作流。
無需複雜編碼,僅通過可視化拖拽即可串聯工具,既能解決多格式論文的高精度解析難題,又能讓大模型快速處理提取的核心信息,最終自動同步到飛書表格實現數據沉澱。讓我們從繁瑣的文獻處理中解放出來,把時間真正用在核心研究上。
二、技術底層:為什麼是TextIn+Coze的工作流組合?
1.1 TextIn 大模型加速器:科研數據的 “高精度處理器”
在我看來,TextIn大模型加速器有三大優勢:
- 其一:首先在論文解析的核心環節,TextIn 大模型加速器展現出極強的場景適配能力 ,可以全面支持 PDF、圖片、Word 等十餘種常見學術文檔格式,且解析效率很高,百頁的長篇論文可實現秒級完成處理,遠超傳統OCR工具的處理速度。針對學術論文特有的多欄佈局、嵌套表格、複雜公式、圖表編號等結構化元素,TextIn 能實現精準識別與還原,避免了傳統工具解析後格式錯亂、信息缺失的問題。
- 其二是技術優勢,從 “字符提取” 升級為 “語義理解”,不僅能清晰區分標題、摘要、關鍵詞、正文、參考文獻等邏輯模塊,還能精準保留公式符號、段落結構等關係。
- 最後是科研適配:針對科研場景中多語言文獻混雜、排版格式多樣的痛點,TextIn提供了定製化的適配方案。其支持50+語種的精準識別,無論是英文、德文、日文等常見學術語種,還是小語種文獻,都能實現高效解析與信息提取。同時,面對模糊不清的老舊文獻、帶複雜水印的涉密論文等特殊素材,TextIn 的增強解析算法能有效過濾干擾信息,確保核心學術內容的完整提取。
1.2 Coze +飛書:低代碼搭建與高效協作的雙引擎
再説説 Coze 平台:它最核心的優勢在於提供了可視化的插件集成能力,這對非技術背景的科研人員尤為友好。我們無需掌握複雜的編程開發技能,僅通過拖拽、點選等簡單操作,就能快速將 TextIn 的解析能力與大模型的交互功能串聯起來 —— 從配置論文上傳的入口,到關聯 TextIn 的解析結果作為大模型的輸入源,整個流程都能在可視化界面中完成,大幅降低了自動化工作流的搭建門檻,讓科研人員能快速上手、按需調整流程。最後將識別結果能實時同步到飛書表格中,團隊成員可以直接在線編輯、批註文獻信息,無需反覆傳輸文件或手動彙總。
三、實戰教程:30 分鐘搭建全自動論文處理工作流
2.1 前期準備:工具與權限配置
首先我們需要登錄Coze平台,大家可以看看Coze的文檔中心,熟悉一下Coze的基本操作。
然後登錄合合信息的TextIn工作台平台,現在3000頁體驗喲。可以根據需要體驗一下TextIn的各類產品,比如當前比較熱門的通用文字識別、通用文檔解析等,這些也是待會我們要在Coze平台中要引入的插件功能。
2.2 三步搭建:從插件集成到流程跑通
接下來我們就來開始搭建Coze流程吧,我們搭建的可以算是通用Agent範例,不需要依賴Rag/分片策略等,主要可以分為三個核心步驟/環節:
- Coze 流程設計:新建工作流,添加 “TextIn 文檔解析” 插件,配置論文上傳入口(支持單篇 / 批量上傳)。
- 大模型交互配置:接入偏好大模型,設置 prompt 規則(如 “提取論文標題、摘要、關鍵詞、核心結論”),關聯 TextIn 解析結果作為輸入源。
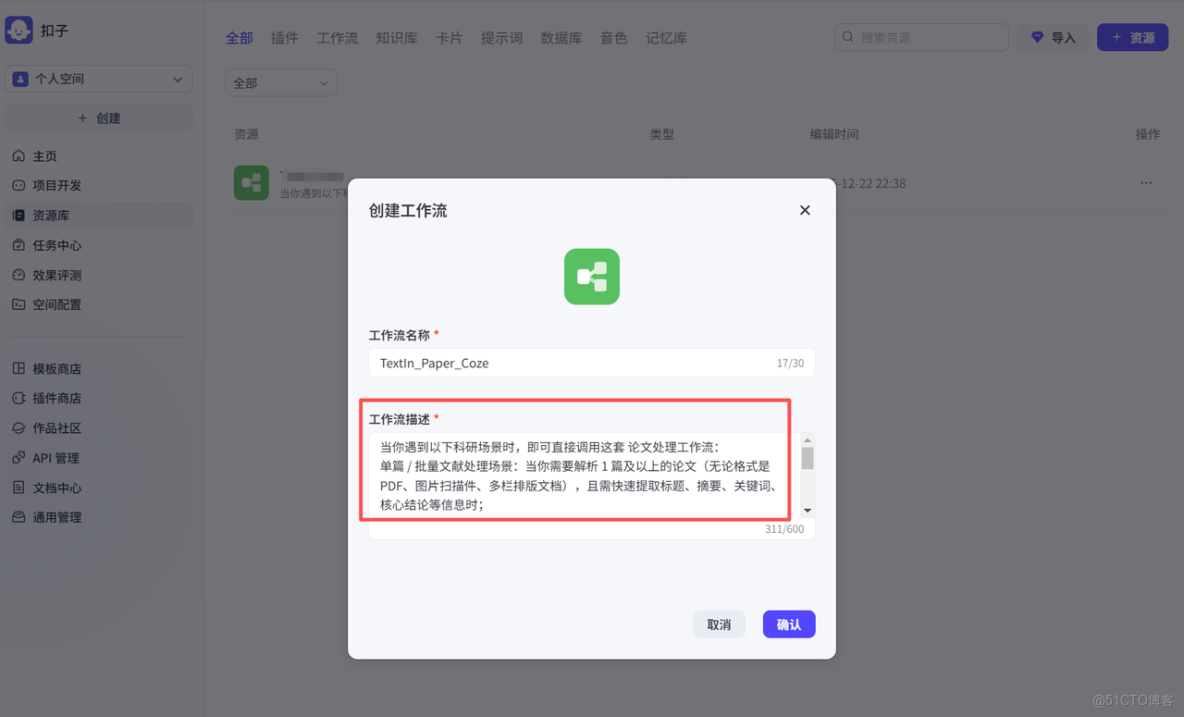
- 飛書表格輸出:添加 “飛書表格” 插件,映射解析字段(論文標題→A 列、論文關鍵詞→B 列等)。 首先我們點擊Coze創建工作流,然後進行直觀的工作流描述,這樣如果後面有搭建Agent智能體的需求,可以讓智能體知道在什麼場景下調用該工作流。
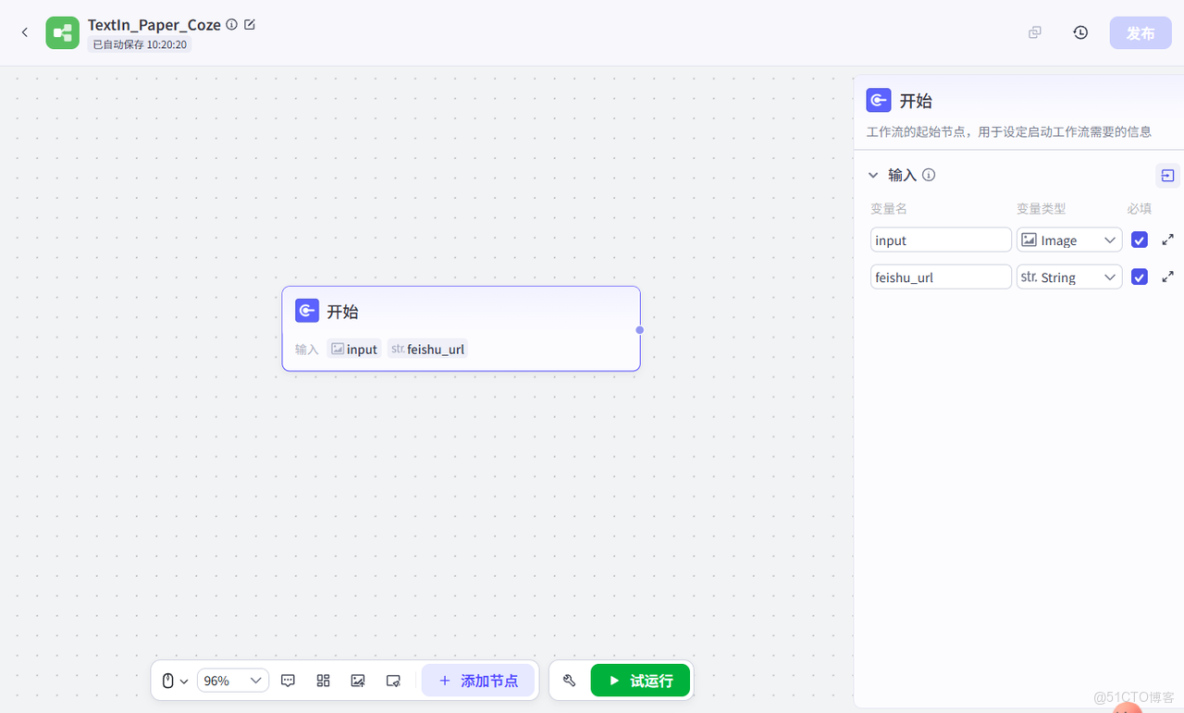
然後創建開始節點,開始節點中需要配置兩個輸入變量,我這裏設置的是image類型的論文圖片input,還有飛書的文檔鏈接URL,飛書的文檔URL後續解析完成之後的寫入過程需要用到。
然後我們添加合合信息的TextIn ParseX解析插件,這個插件是專門LLM下游任務設計的通用文檔解析服務,識別文檔或圖片中的文字信息,將文檔解析為Markdown格式,並按常見的閲讀順序進行還原,可以賦能下游各類大語言模型任務。
這個ParseX插件是我們整個Coze工作流的重點環節,就是用來做智能文檔解析處理功能的。
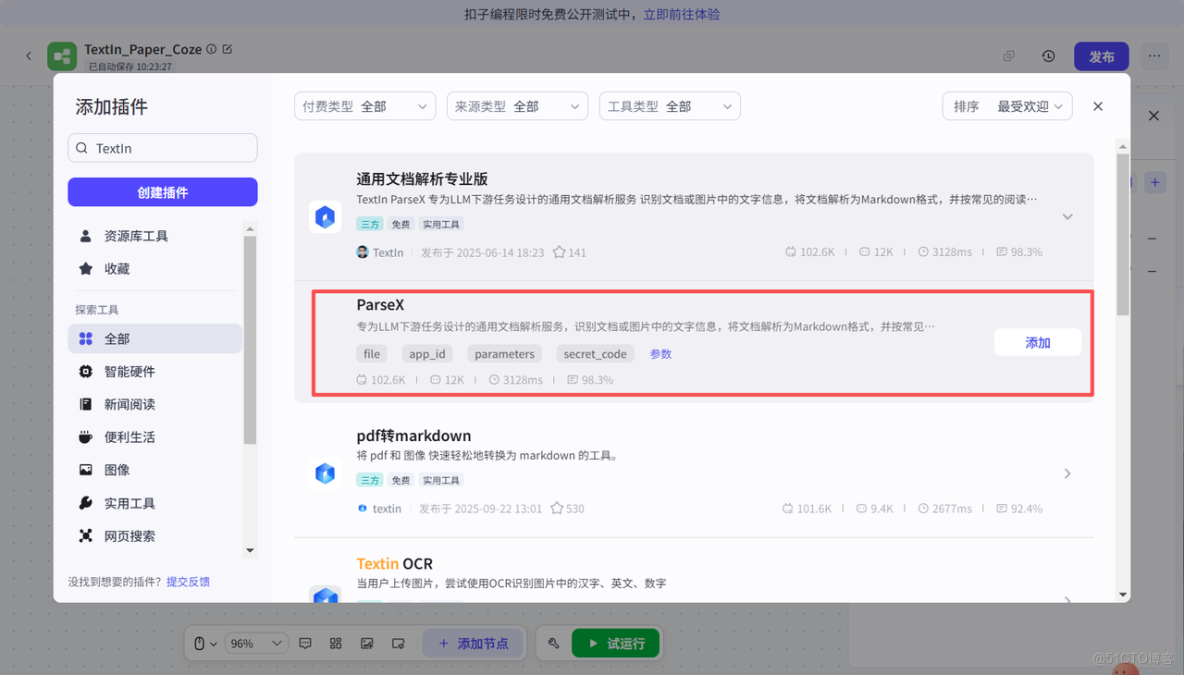
添加之後我們將開始節點和ParseX節點串聯起來,然後設置ParseX對應的輸入為圖片,這樣就可以識別到輸入的論文了。
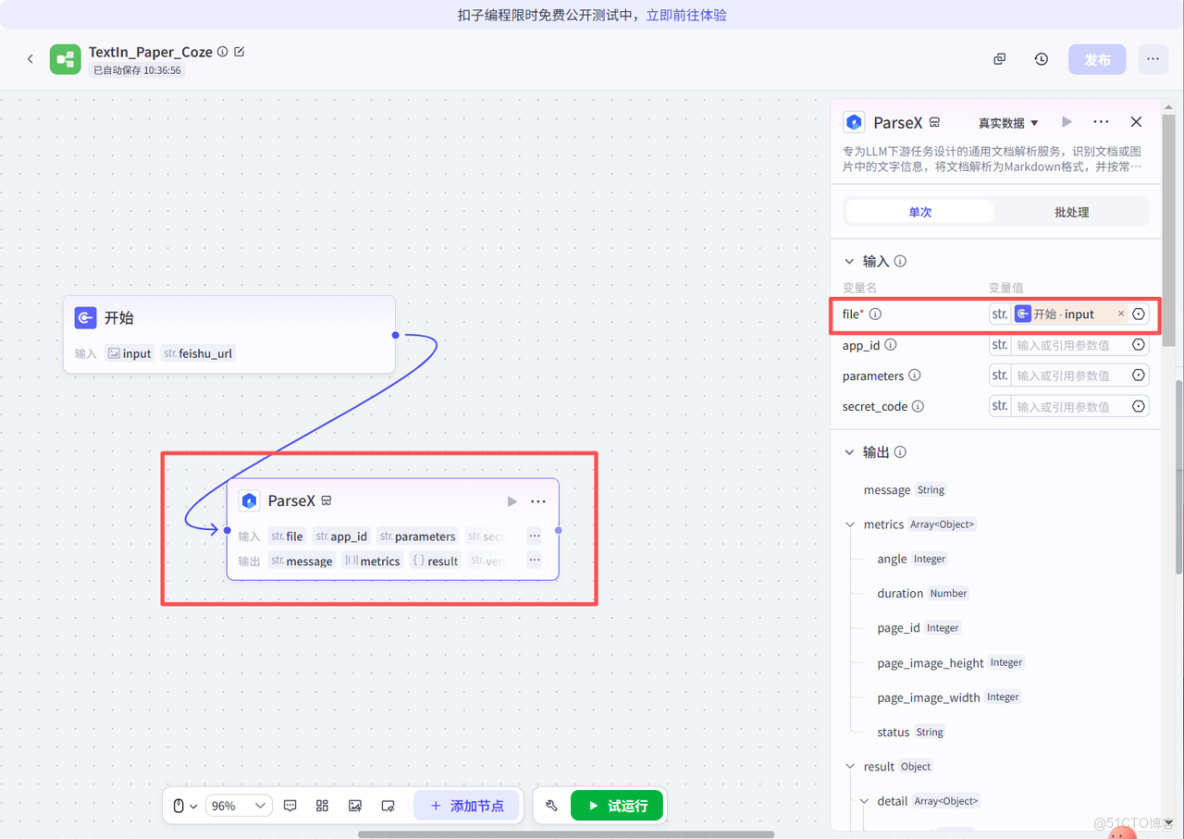
然後添加大模型節點,如圖所示,配置好對應的輸入、提示詞、用户提示詞即可。把ParseX識別的各類文字文本讓大模型進行對應的提取,並且按照規定好的格式輸出,比如按照Json格式輸出即可。
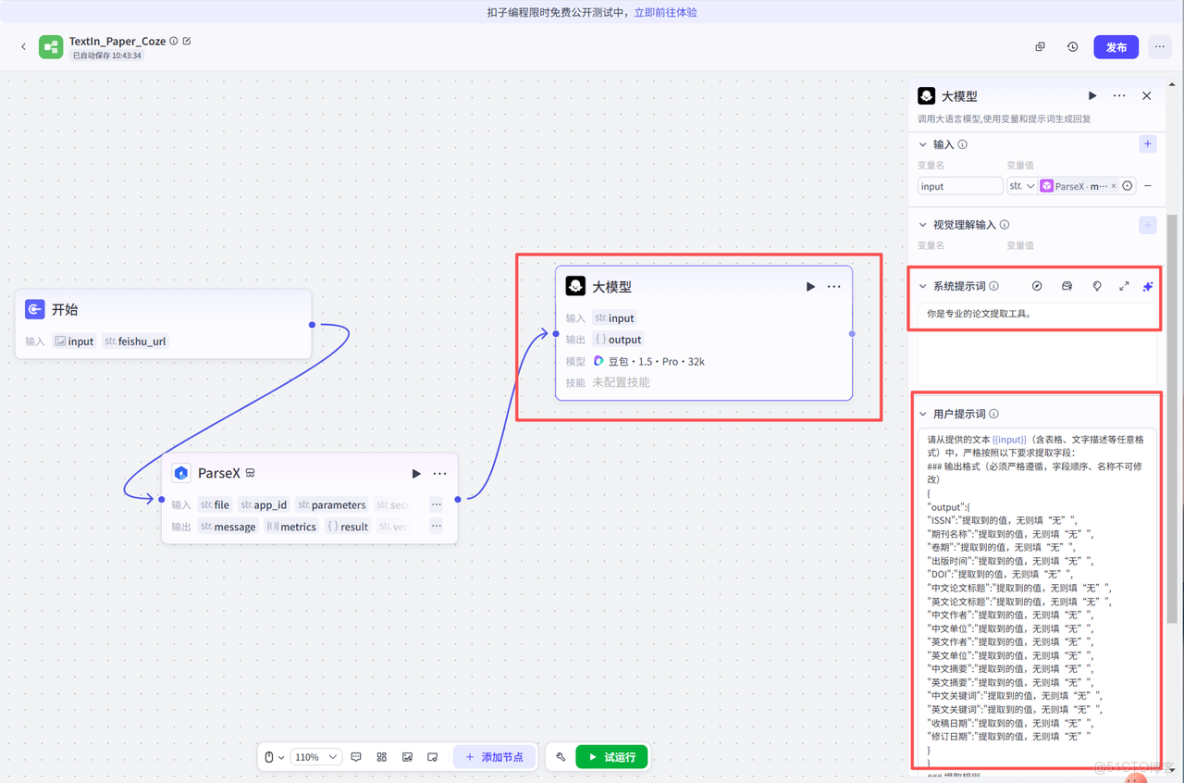
再接下來就是添加代碼節點,代碼節點的作用是獲取大模型的格式化輸出,設別嵌套的數據,然後進行對應的飛書字段映射,為後續寫入飛書文檔做鋪墊。
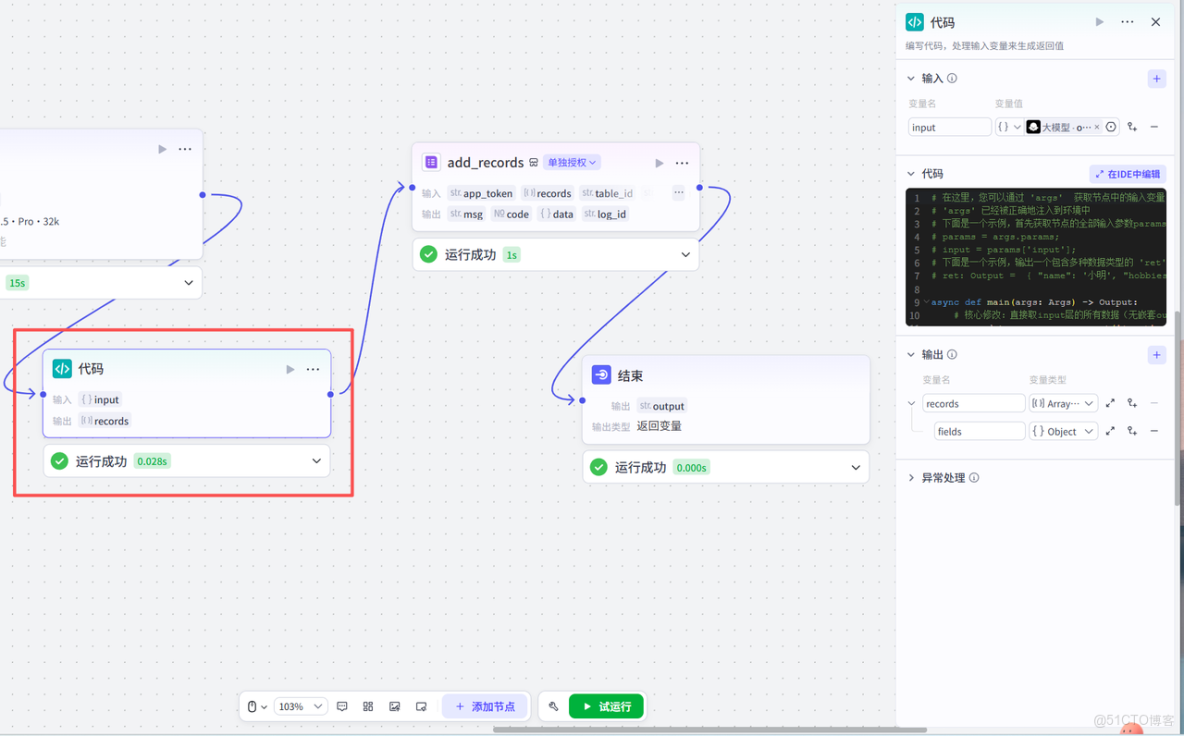
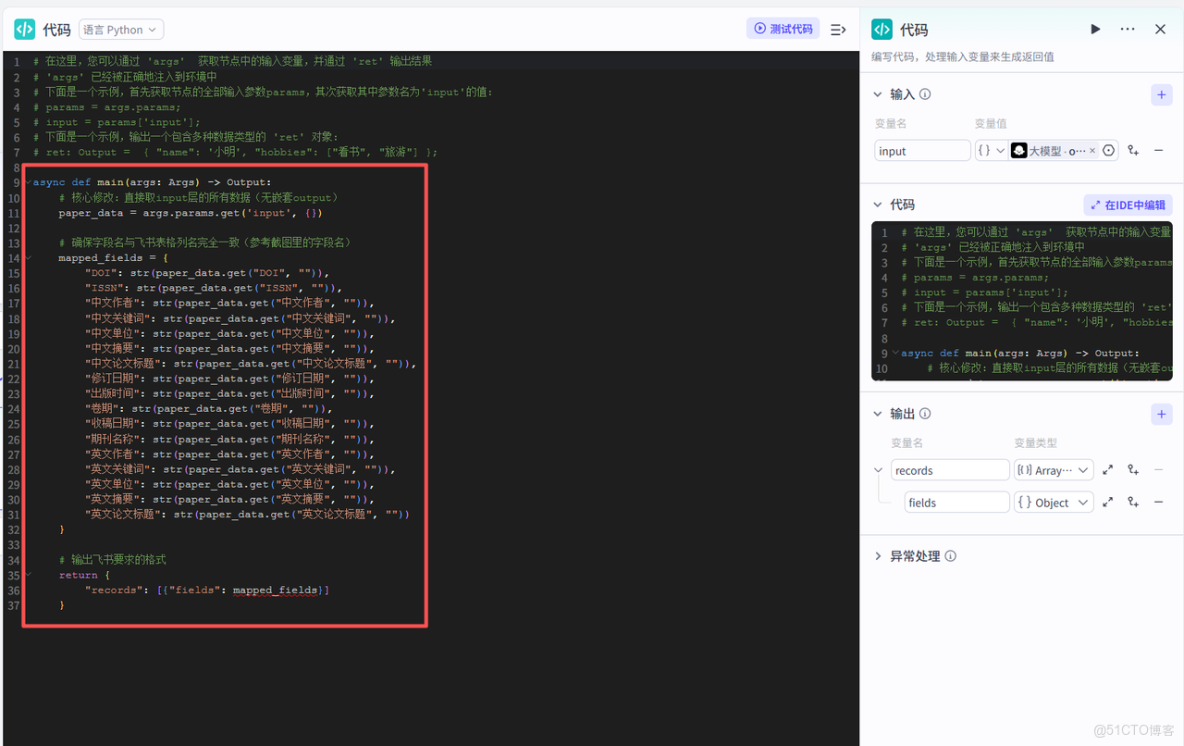
最後我們添加飛書多維表格插件節點,授權對應的飛書賬號之後,配置輸入與輸出,工作流就基本大功告成了!
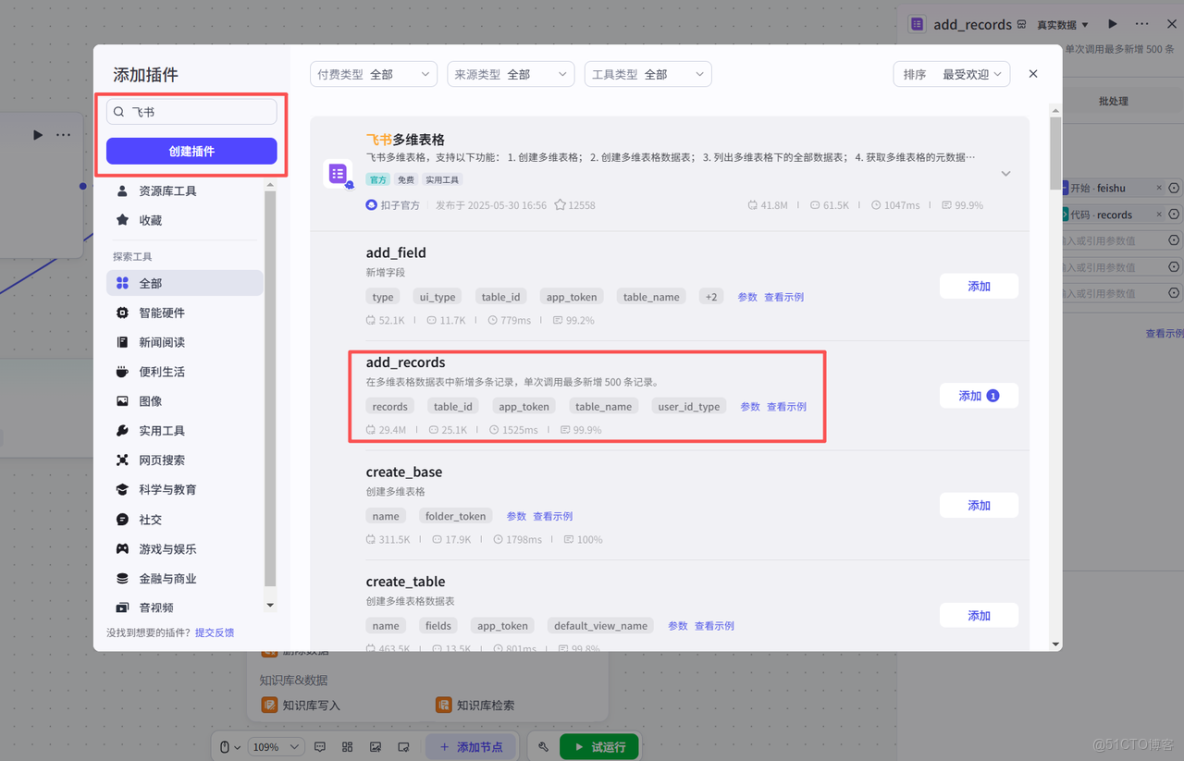
最後我們把結束節點配置一下,工作流就搭建好了!最終的鏈路效果如下所示~總結一下鏈路:
- 觸發:由 “開始” 節點接收對應輸入數據(即觸發信號),啓動整個流程;
- 解析:通過 “ParseX” 節點對輸入內容進行數據解析,完成信息提取;
- LLM 處理:解析結果傳入 “大模型” 節點(這裏我選用豆包1.5Pro版本),由大模型進行內容處理;
- 回寫:大模型輸出結果經 “代碼” 節點處理後,通過 “add_records” 節點回寫數據;
- 收尾:最終由 “結束” 節點完成流程閉環。
後續如果各位小夥伴想搭建Agent,只需要在Coze創建智能體Agent中把這個工作流鏈路配置給Agent即可~
2.3 測試與優化:確保流程穩定高效
接下來我們測試整個工作流,看看是否能夠運行通過。
首先在飛書文檔創建對應的表格,創建需要的表格列,注意列名需要跟剛剛我們的飛書添加數據節點中的Python代碼中的對應列名要對應上,比如下圖所示。
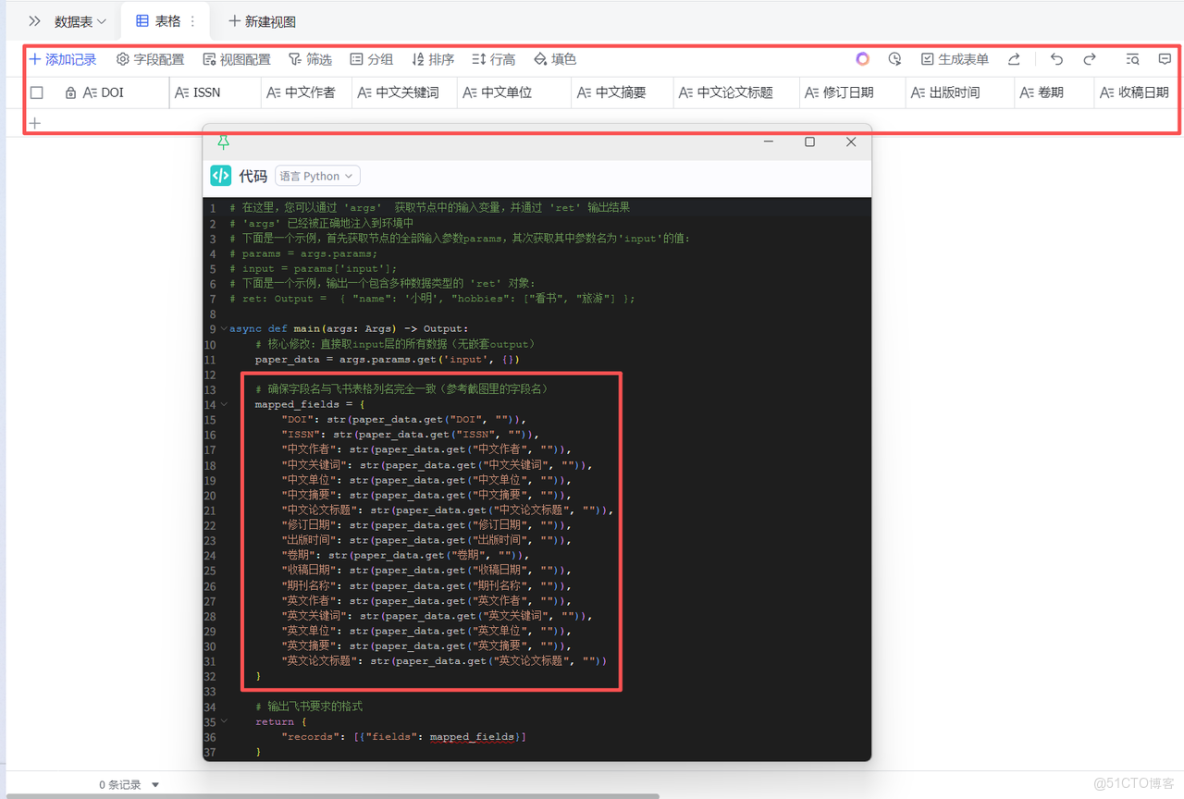
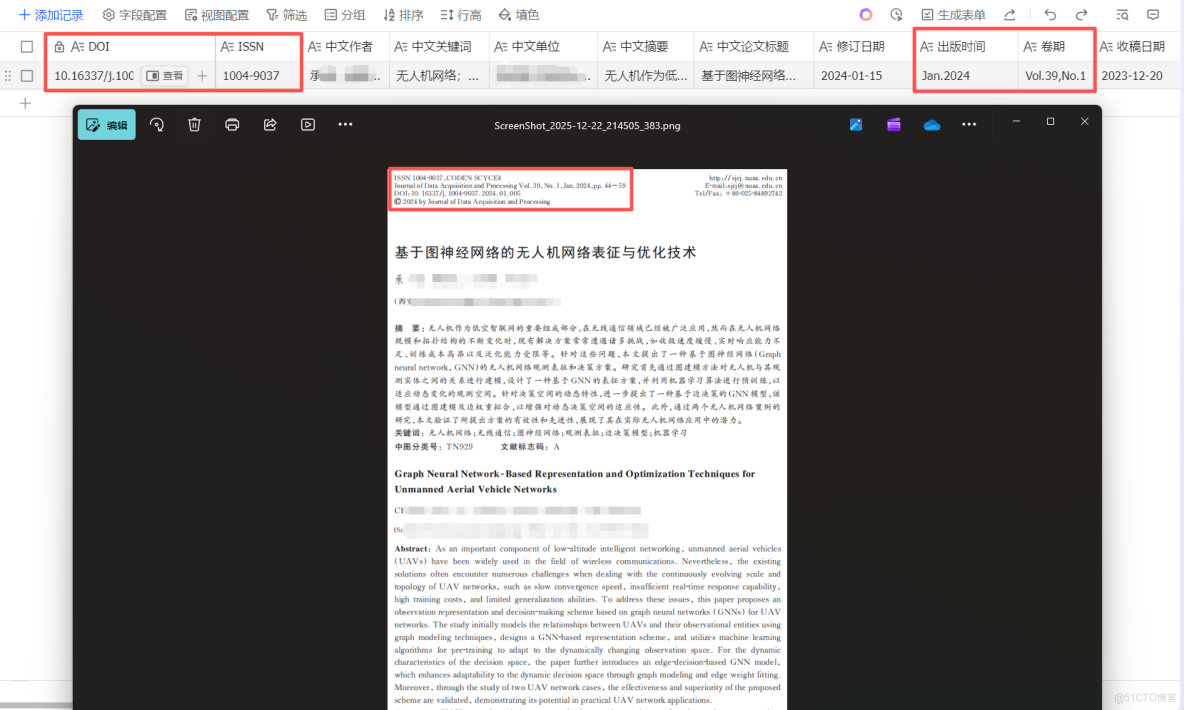
這裏我選擇了一篇論文作為工作流測試,選擇這張圖片作為輸入測試,能從場景覆蓋、功能驗證、實用性三個維度充分檢驗工作流的可靠性,具體我覺得可以概括如下:
(1)覆蓋了科研論文的典型複雜格式,驗證ParseX適配性:
- 多元素排版適配:包含多欄佈局、中英雙語標題 / 作者 / 摘要、嵌套關鍵詞列表、公式 / 縮寫(如 GNN)等學術論文常見元素,能測試 TextIn 對複雜排版的解析精度;
- 多信息模塊覆蓋:同時包含期刊元數據(ISSN、DOI、卷期)、作者單位、收稿 / 修訂日期等工作流需提取的全量字段,可一次性驗證所有目標字段的提取完整性。
(2)驗證工作流的核心能力與完整流程:
- OCR 解析能力測試:圖片包含印刷體、中英文混排、標點符號(分號、逗號)等,能檢驗 TextIn 對學術文本的字符識別準確率(避免亂碼、錯字);
- 結構化提取能力驗證:可驗證大模型節點是否能準確區分 “中文標題 / 英文標題”“中文摘要 / 英文摘要” 等同類字段,避免信息混淆;
- 端到端流程完整性:從圖片解析→字段提取→飛書表格輸出的全鏈路流程,能驗證 Coze 工作流的插件串聯、數據傳遞是否無斷點。

接着我們點擊開始節點,配置好飛書文檔URL鏈接和圖片之後,就可以點擊試運行了!
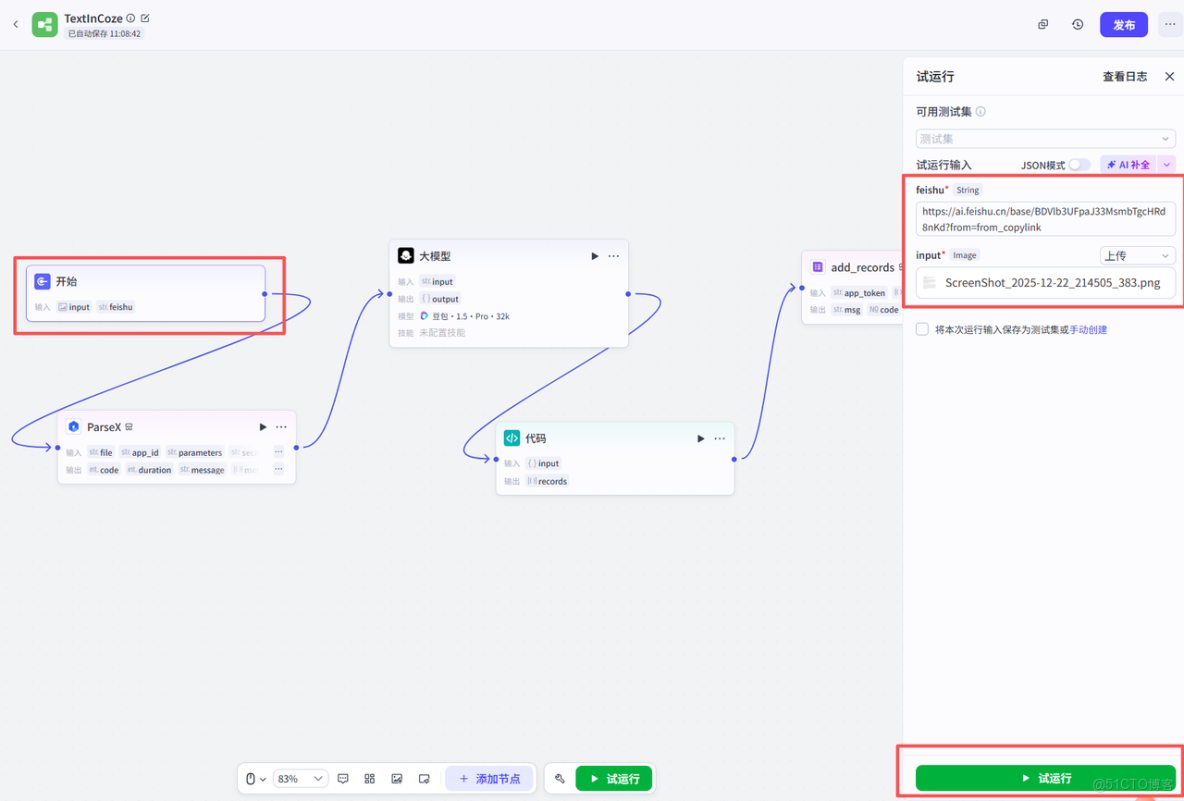
可以看到,整個過程大約5s左右就通過了整個流程,效率非常快,着實驚豔到我了,ParseX識別的數據也特別準確。後續找了其他論文多測了多次,大概發現P99處理耗時僅4.5s左右,效率可以説是遠超傳統OCR工具;同時從我個人的測試結果來看,ParseX的數據識別準確率是100%,單頁處理成本也非常低,可以説從耗時、精度到成本的全維度優勢,既刷新了流程效率的體驗,也讓這次自動化落地的效果着實驚豔。
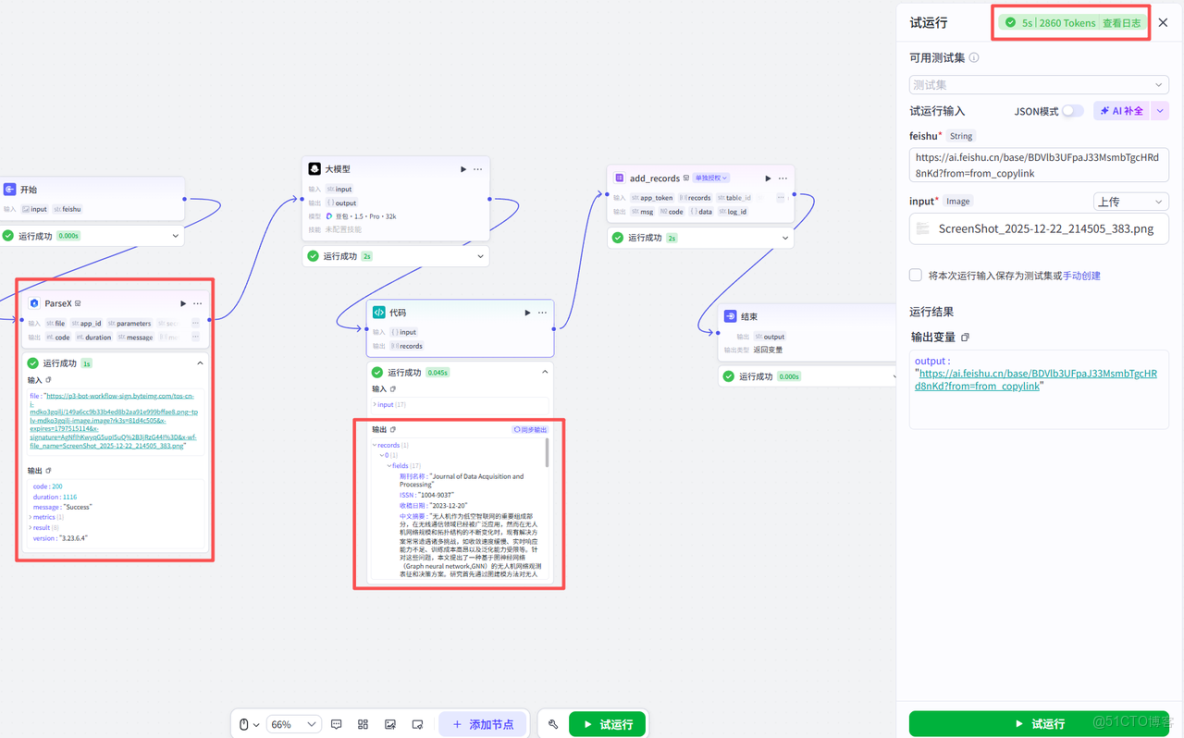
我們再打開飛書文檔,就可以看到已經自動幫我們新增好對應的數據了。準確率我核對了一下,百分百正確,比如圖中的左上角的很小的ISSN號,是完全能夠對得上的,這一點也印證了ParseX的功能強大之處,而且效率很高,比人為手動的去挨個複製添加好很多。
四、場景價值:TextIn+Coze重新定義科研文獻處理效率
對單槍匹馬做研究的科研人而言,文獻處理曾是繞不開的 “重複勞作”—— 從前處理一篇論文的基礎信息,要先手動複製 PDF 內容、逐行錄入關鍵詞,整套流程至少耗費大幾分鐘。
而 TextIn+Coze 的工作流徹底重構了這個過程:從上傳論文到提取完標題、摘要、關鍵詞等核心信息,全程僅需5秒鐘,效率直接提升幾十倍。按每天處理10篇文獻計算,原本要耗1-2小時的整理工作,現在差不多2分鐘就能完成,這些精力足以用來打磨實驗方案、深度分析數據,真正把重心放回科研創新本身。
總結:AI 驅動科研工作流的未來方向
總的來説,我覺得這套工作流的核心價值是TextIn的高精度解析補上了科研數據 “輸入質量” 的短板,Coze 低代碼能力拉低了自動化的上手門檻,飛書表格則打通了數據 “輸出協同” 的環節 —— 三者形成完整閉環,讓科研文獻處理的效率被重新定義。
現在隨着大模型與垂直工具的深度綁定,正在讓科研工作流跳出 “多工具拼接” 的零散模式,轉向 “全鏈路自動化”;未來更多重複勞動會被 AI 接管,科研人員終於能把精力集中在核心創新上。