
前言:從"能生成"到"能長期跑"的工程級大模型
大模型產業落地階段,工程交付穩定性與長時 Agent 運行效率成為核心衡量標準,GLM-4.7 與 MiniMax M2.1 作為國產模型兩條差異化成熟路線的代表,跳出單輪生成質量侷限,聚焦真實場景長期穩定運行能力。AI Ping 平台整合多供應商資源,實現兩款旗艦模型免費開放與統一調度,通過標準化測試、可視化看板與智能路由,為用户搭建從選型到落地的便捷橋樑。感興趣小夥伴可以去平台體驗AI Ping,目前註冊登錄送算力金(https://aiping.cn/#?channel_partner_code=GQCOZLGJ)
模型定位對比:GLM-4.7 vs MiniMax M2.1,工程路線有何不同?

GLM-4.7 主打複雜任務穩定交付,憑藉可控推理、工具協同與 200K 長上下文,可高效完成代理式編程、多技術棧方案落地等工程需求;MiniMax M2.1 依託高效 MoE 架構,強化 Rust/Go 等多語言生產級代碼能力,以高吞吐、低延遲與長鏈 Agent 穩定執行優勢,適配 AI-native 組織持續工作流。
面向真實工程的編碼能力
- GLM-4.7 強調複雜任務的穩定完成與工程交付
- MiniMax M2.1 系統強化 Rust/Go/Java/C++ 等多語言工程,服務真實生產代碼
Agent 與工具調用導向
- GLM-4.7 通過可控思考機制提升多步任務穩定性
- MiniMax M2.1 通過高效 MoE 與收斂推理路徑,適合連續編碼與長鏈 Agent 執行
長期運行下的效率與成本權衡
- GLM-4.7 支持推理強度按需調節,在準確率與成本間靈活取捨
- MiniMax M2.1 以低激活參數與長上下文優勢,提升吞吐與持續運行效率
GLM-4.7:面向複雜任務與 Agentic Coding 的旗艦模型
GLM-4.7 是智譜最新旗艦模型,GLM-4.7 面向 Agentic Coding 場景強化了編碼能力、長程任務規劃與工具協同,並在多個公開基準的當期榜單中取得開源模型中的領先表現。通用能力提升,回覆更簡潔自然,寫作更具沉浸感。在執行復雜智能體任務,在工具調用時指令遵循更強,Artifacts 與 Agentic Coding 的前端美感和長程任務完成效率進一步提升。
多供應商實測數據:吞吐、延遲與可靠性對比
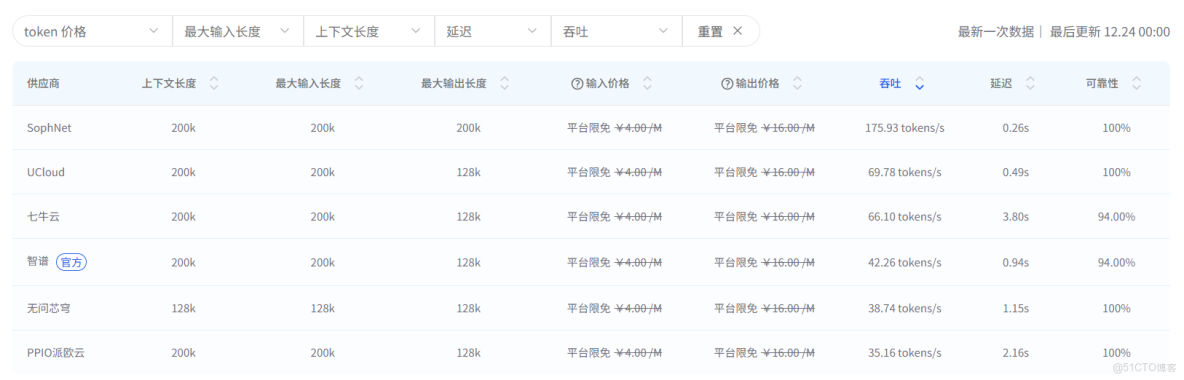
GLM-4.7 各供應商中,SophNet 的吞吐(175.93 tokens/s)與延遲(0.26s)表現最優,上下文 / 輸入 / 輸出長度均達 200k 且可靠性 100%;UCloud 吞吐、延遲次之;七牛雲、智譜(官方)可靠性略低(94%);無問芯穹上下文長度僅 128k 但可靠性拉滿,PPIO 派歐雲各項指標相對偏弱;當前平台均提供免費額度,輸入 / 輸出價格一致。
統一 API 與智能路由:自動選擇最優供應商
1、以此設置token價格、最大輸入長度、延遲、吞吐、智能路由策略
2、複製API示例代碼本地調用
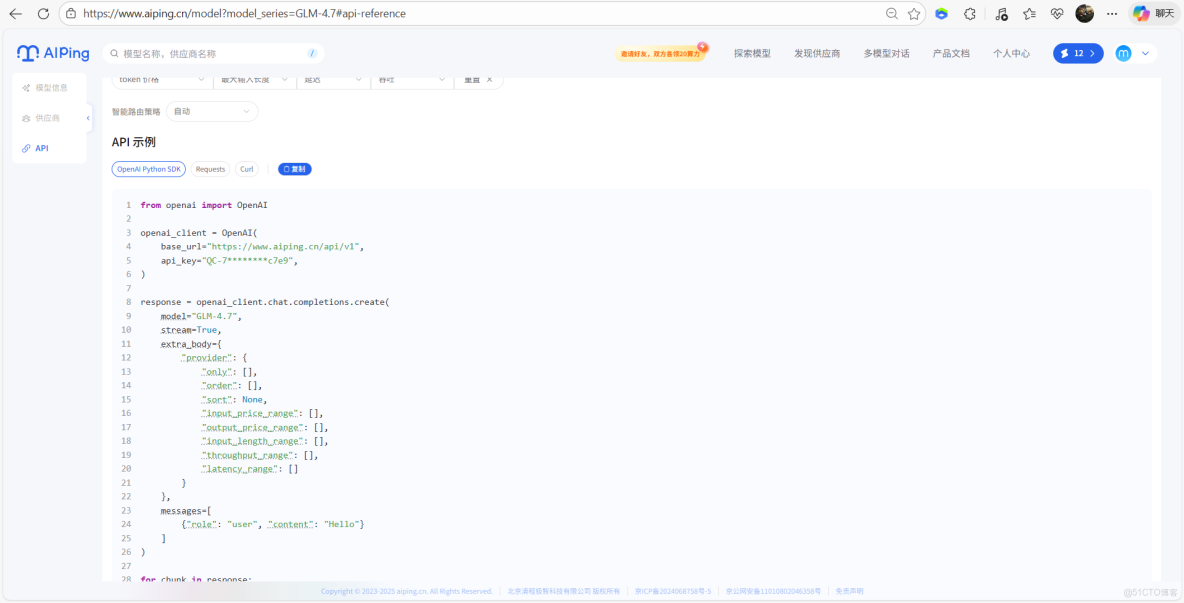
from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-759e8536f1db9d18ec4f3dcb1b90044d-a3629e8a3743d0b37cb56d677577c7e9",
)
response = openai_client.chat.completions.create(
model="GLM-4.7",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)3、優化多輪對話、持續運行
from openai import OpenAI
# 初始化客户端
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-759e8536f1db9d18ec4f3dcb1b90044d-a3629e8a3743d0b37cb56d677577c7e9",
)
# 維護對話上下文(多輪交互關鍵)
messages = []
print("GLM-4.7 對話助手(輸入 'exit' 退出):")
while True:
# 接收用户輸入
user_input = input("\n你:")
if user_input.lower() == "exit":
print("對話結束~")
break
# 把用户輸入加入上下文
messages.append({"role": "user", "content": user_input})
try:
# 發起流式調用
response = openai_client.chat.completions.create(
model="GLM-4.7",
stream=True,
extra_body={"provider": {"only": [], "order": [], "sort": None}},
messages=messages
)
print("GLM-4.7:", end="", flush=True)
# 接收並打印流式返回
for chunk in response:
if not getattr(chunk, "choices", None):
continue
# 打印思考過程(可選)
reasoning = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
# 打印核心回覆
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
# 把模型回覆加入上下文(多輪交互關鍵)
# 注:流式調用需拼接所有content後再加入,這裏簡化處理(實際需優化)
messages.append({"role": "assistant", "content": "(上述流式返回的完整內容)"})
except Exception as e:
print(f"\n調用出錯:{e}")
# 出錯時清空本輪輸入,避免上下文污染
messages.pop()
4、輸出結果

MiniMax-M2.1:高吞吐 MoE 架構下的多語言工程利器
強大多語言編程實力,全面升級編程體驗
多雲供應商實測:上下文、吞吐與延遲表現

MiniMax-M2.1 的兩家供應商官方、七牛雲均支持 200k 上下文 / 輸入長度、192k 輸出長度,可靠性均為 100% 且當前享平台免費額度;其中 MiniMax 官方的吞吐更優(78.08 tokens/s)、延遲略低(1.09s),七牛雲吞吐稍弱(69.56 tokens/s)、延遲微高(1.17s),二者性能差異較小,可按需切換。
統一 OpenAI 兼容接口:低成本完成模型接入
此處官方同樣提供了API 示例,本地和線上調用都非常方便和GLM-4.7使用方式相同這裏就不作相同展示了
from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-759e8536f1db9d18ec4f3dcb1b90044d-a3629e8a3743d0b37cb56d677577c7e9",
)
response = openai_client.chat.completions.create(
model="MiniMax-M2.1",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)VSCode Cline 中接入 AI Ping:模型直連開發流程
1、VSCode按照Cline插件,完成安裝後,可以在左側活動欄中看到Cline的圖標

2、AI Ping個人中心獲取API Key
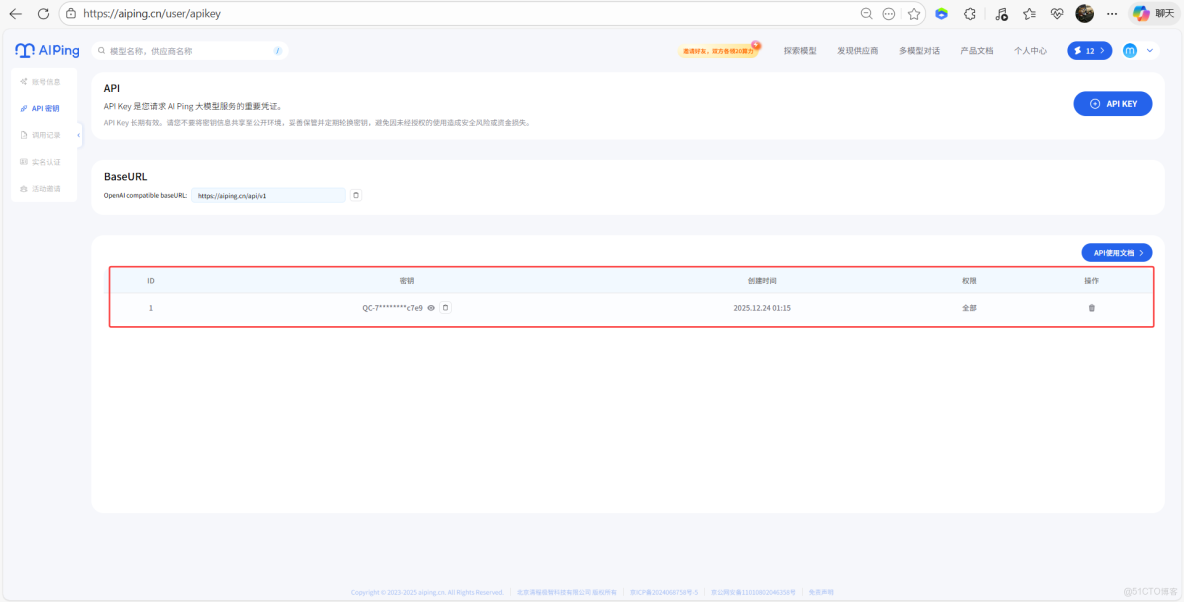
3、配置Cline
- 進入 Cline 的參數配置界面
- API Provider 選擇 “OpenAI Compatible”
- Base URL 輸入 “https://aiping.cn/api/v1”
- API Key -> 輸入在 AI Ping 獲取的 key
- 模型ID:MiniMax-M2.1
- 點擊右上角的 “Done”,保存配置

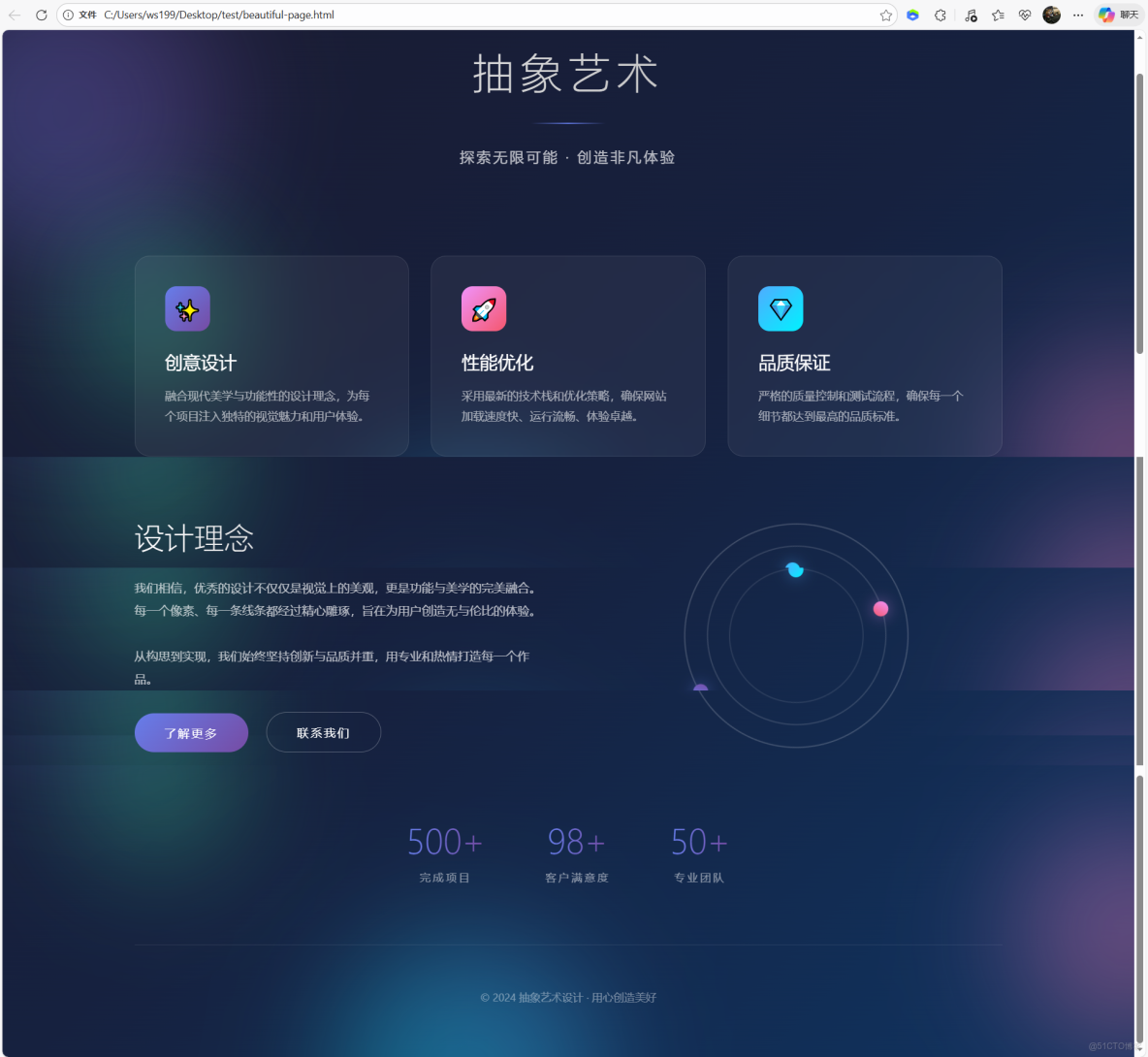
4、通過Cline編寫代碼
5、AI Ping後台查看可視化調用記錄與費用
總結:國產大模型工程化落地的兩種成熟路徑
AI Ping 平台本次上線的 GLM-4.7 與 MiniMax M2.1,是國產大模型在工程交付與長時 Agent 運行兩條路線上的代表性成果,前者以可控推理與工具協同實現複雜任務穩定交付,後者依託高效 MoE 架構強化多語言生產級代碼與長鏈 Agent 效率,二者均跳出單輪生成質量的侷限,聚焦真實業務場景的長期穩定運行。
通過 AI Ping 平台,用户可零門檻體驗兩款旗艦模型:平台整合多供應商資源,提供性能可視化看板、統一 OpenAI 兼容接口與智能路由策略,既支持按需篩選低延遲 / 高吞吐的供應商,也能通過簡單代碼實現流式交互、多輪對話等實用功能,甚至可結合 VSCode 插件直接嵌入開發流程,大幅降低模型接入與選型成本。