

新用户可獲得高達 200 美元的服務抵扣金
亞馬遜雲科技新用户可以免費使用亞馬遜雲科技免費套餐(Amazon Free Tier)。註冊即可獲得 100 美元的服務抵扣金,在探索關鍵亞馬遜雲科技服務時可以再額外獲得最多 100 美元的服務抵扣金。使用免費計劃試用亞馬遜雲科技服務,最長可達 6 個月,無需支付任何費用,除非您選擇付費計劃。付費計劃允許您擴展運營並獲得超過 150 項亞馬遜雲科技服務的訪問權限。
前言
數據安全與合規要求日益嚴格的今天,企業在處理敏感信息PII時必須確保全流程加密與可控訪問。本指南基於亞馬遜雲科技服務,展示如何結合 Glue DataBrew、KMS 和 Lambda,在 Athena 查詢中實現 PII 數據的動態解密,既保證了數據安全,又提升了分析效率,適合對數據安全和無服務器架構感興趣的開發者與運維人員參考實踐。
項目架構
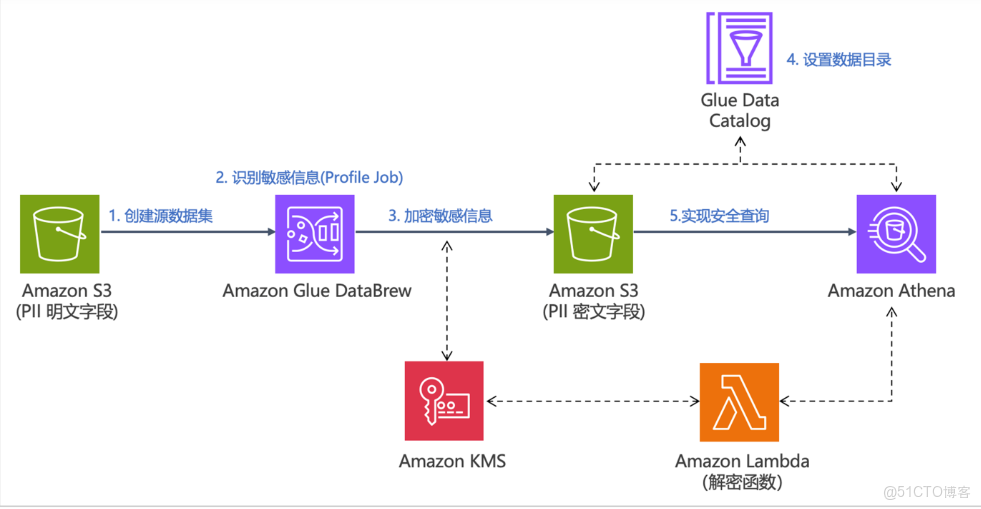
架構圖展示亞馬遜雲科技上對敏感信息 PII 的安全處理流程:S3 存儲明文數據 → Glue DataBrew 自動識別並調用 KMS 加密 → 加密數據回寫 S3 → 通過 Glue Catalog 管理 → Athena 查詢時由 Lambda 動態解密,實現全生命週期的數據安全訪問
數據安全:敏感數據在存儲和查詢中始終加密。
- 自動化識別:DataBrew 自動識別 PII 列,減少人工錯誤
- 按需解密:Athena 查詢時動態解密,避免明文長期存儲
- 可擴展性強:基於 Serverless 服務(S3、Athena、Lambda),無需管理服務器,輕鬆擴展數據規模
前提準備:亞馬遜雲科技註冊流程
Step.1 登錄官網
登錄亞馬遜雲科技官網,填寫郵箱和賬户名稱完成驗證(註冊亞馬遜雲科技填寫 root 郵箱、賬户名,驗證郵件地址,查收郵件填驗證碼驗證,驗證通過後設 root 密碼並確認)
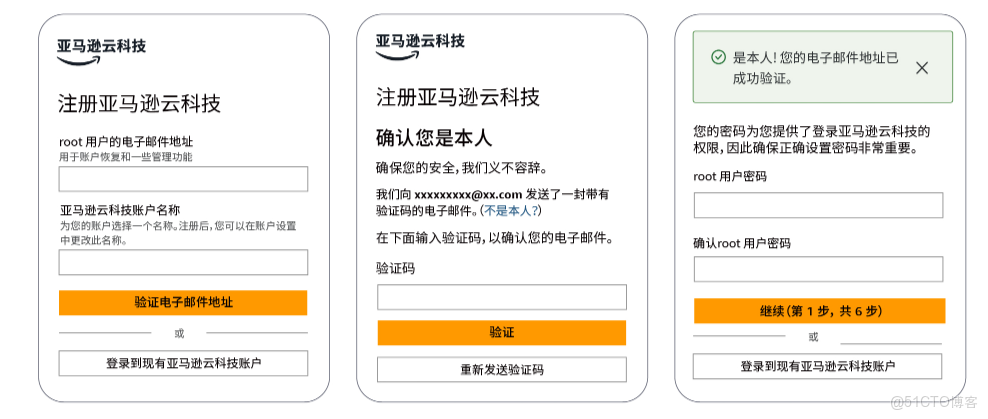
Step.2 選擇賬户計劃
選擇賬户計劃,兩種計劃,按需選"選擇免費計劃 / 選擇付費計劃"繼續流程
- 免費(6 個月,適合學習實驗,含$200抵扣金、限精選服務,超限額或到期可升級付費,否則關停)
- 付費(適配生產,同享$200 抵扣金,可體驗全部服務,抵扣金覆蓋廣,用完按即用即付計費)

Step.3 填寫聯繫人信息
填寫聯繫人信息(選擇使用場景,填聯繫人全名、電話,選擇所在國家地區,完善地址、郵政編碼,勾選同意客户協議,點擊繼續 進入下一步)

Step.4 綁定信息
綁定相關信息,選擇國家地區,點擊"Send code"收驗證碼填寫,勾選同意協議後,點擊"驗證並繼續"進入下一步

Step.5 電話驗證
電話驗證填寫真實手機號,選擇驗證方式,完成安全檢查,若選語音,網頁同步顯 4 位數字碼,接來電後輸入信息,再填收到的驗證信息,遇問題超 10 分鐘收不到可返回重試。
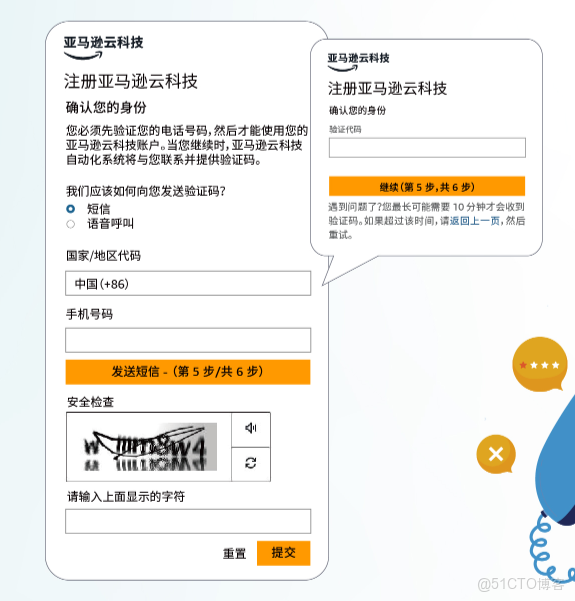
Step.6 售後支持
售後支持:免費計劃自動獲基本支持,付費計劃需選支持計劃(各計劃都含客户服務,可訪問文檔白皮書,按需選後點 "完成註冊",若需企業級支持可瞭解付費升級選項,確認選好即可完成整個註冊流程 )

Athena中Lambda解密DataBrew加密PII數據
1、準備源數據時,sensitive_data_input用於存放源數據,encrypted_data_output用於保存加密後的輸出文件,profile_job_out用於存放Profile作業的統計結果
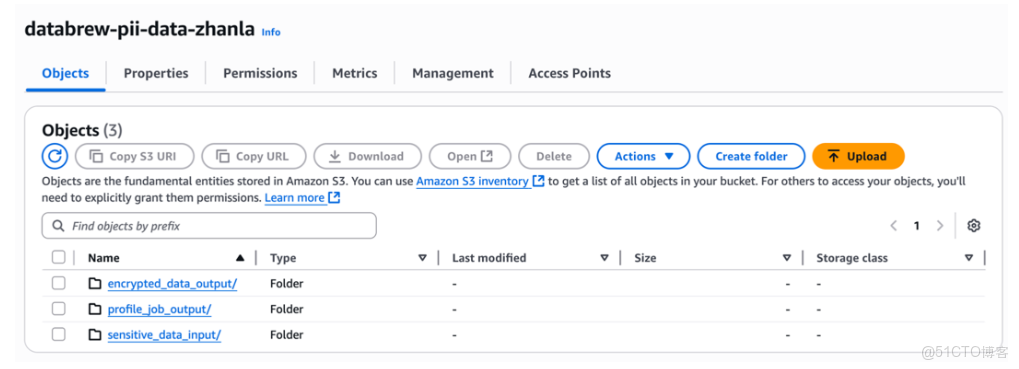
2、創建文件夾後,將文件sample-data.csv上傳到S3存儲桶的sensitive_data_input文件夾中,也可以通過運行CLI命令實現同樣的操作
# 創建 S3 存儲桶
aws s3 mb s3://databrew-pii-data-zhanla --region cn-northwest-1
# 創建必要的文件夾(前綴)
aws s3api put-object --bucket databrew-pii-data-zhanla --key sensitive_data_input/ --region cn-northwest-1
aws s3api put-object --bucket databrew-pii-data-zhanla --key profile_job_out/ --region cn-northwest-1
aws s3api put-object --bucket databrew-pii-data-zhanla --key encrypted_data_output/ --region cn-northwest-1
# 上傳樣例數據
aws s3 cp ./sample-data.csv s3://databrew-pii-data-zhanla/sensitive_data_input/sample-data.csv --region cn-northwest-13、識別敏感信息
上載數據後,我們需要創建DataBrew數據集,運行DataBrew Profile作業,來分析數據集中的PII敏感數據列
4、DataBrew控制枱中創建源數據集時,先在左側導航欄選擇DATASETS,點擊Connect new dataset,將數據集命名為data-pii-sample,數據源選擇Amazon S3,輸入文件路徑s3://databrew-pii-data-zhanla/sensitive_data_input/sample-data.csv,文件類型選擇CSV,並將首行設置為列標題
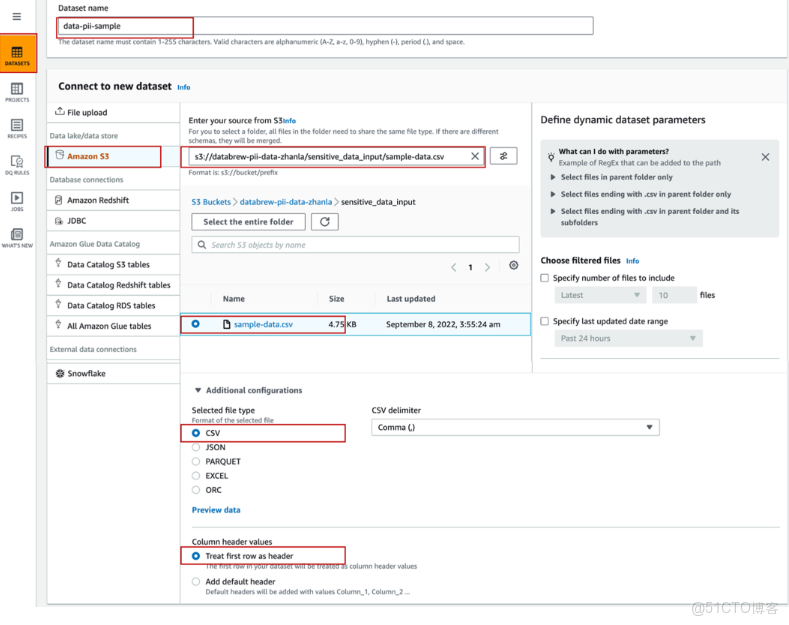
5、運行源數據集的Profile Job可以幫助分析數據的分佈、區間、極值、平均值和有效值,並識別是否包含PII數據。在DataBrew左側導航欄選擇DATASETS,找到已創建的數據集pii-sample,點擊Run data profile,在彈出窗口中選擇Create profile job創建並運行數據分析作業
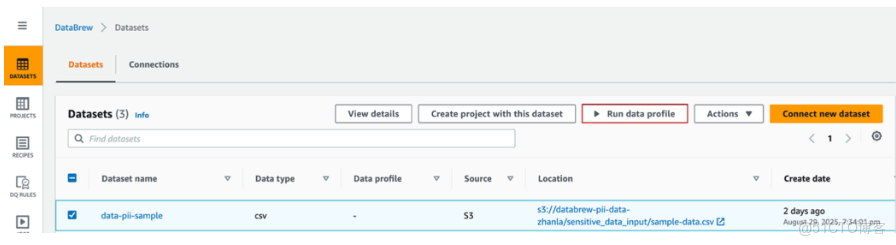
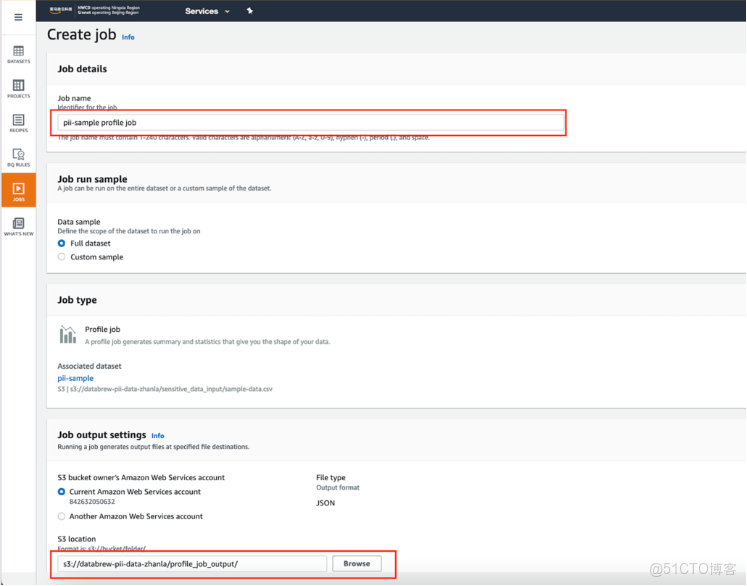
6、Create Job嚮導頁中,將作業名稱設置為pii-sample profile job,在Data Sample中選擇全部數據集Full dataset,在Job output settings中將S3輸出目錄設置為s3://databrew-pii-data-zhanla/profile_job_output/
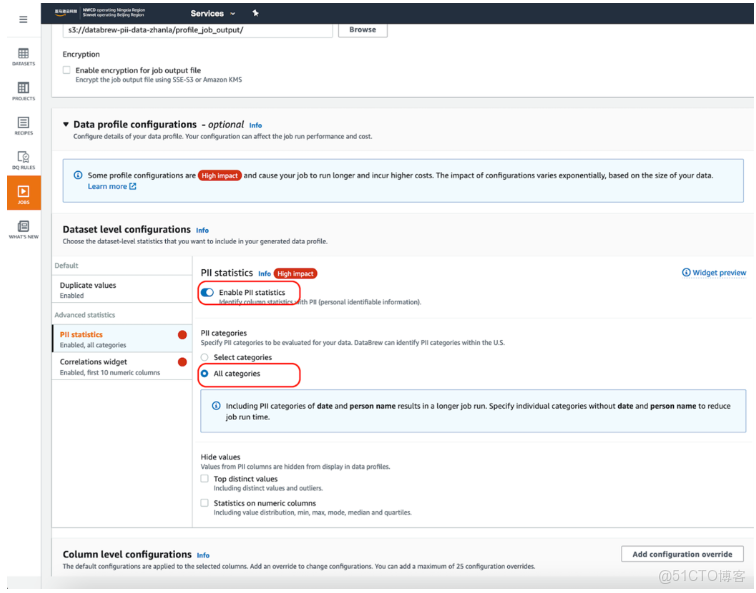
7、PII statistics中啓用Enable PII statistics,讓Profile Job識別數據集中的PII列。該選項默認關閉,需要手動開啓。對於PII categories,選擇All categories
8、保持其他設置為默認值,在Permissions選項中選擇Create New IAM Role,在new IAM role suffix中輸入PII-DataBrew-Role,系統會自動創建一個以PII-DataBrew-Role為後綴的Glue運行角色
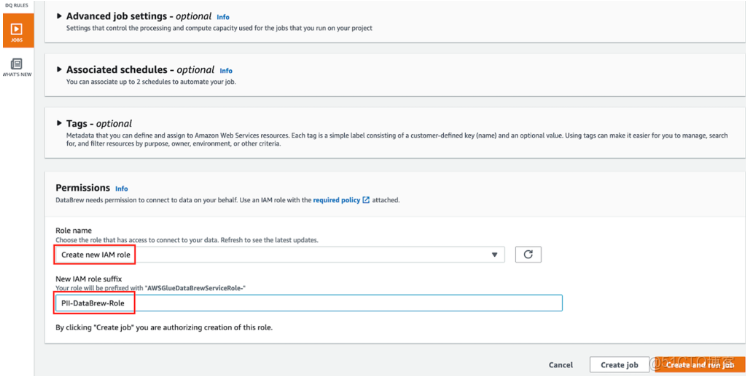
9、點擊Create and run job運行作業,待Profile Job完成後,可在數據集的Data profile overview選項卡查看數據概況。PII識別信息顯示在右側,包括被識別的PII列及其對應的PII統計類別
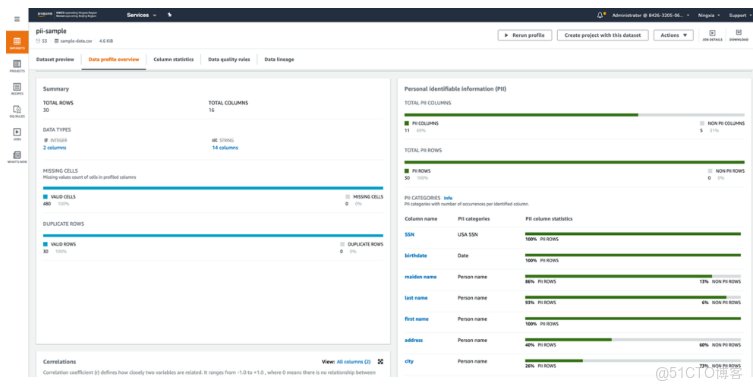
10、以上,通過運行數據集的Profile作業,對源數據Dataset進行初步的分析,識別出了存放PII的信息列,在接下的處理中,我們會對識別的PII列的數據進行加密
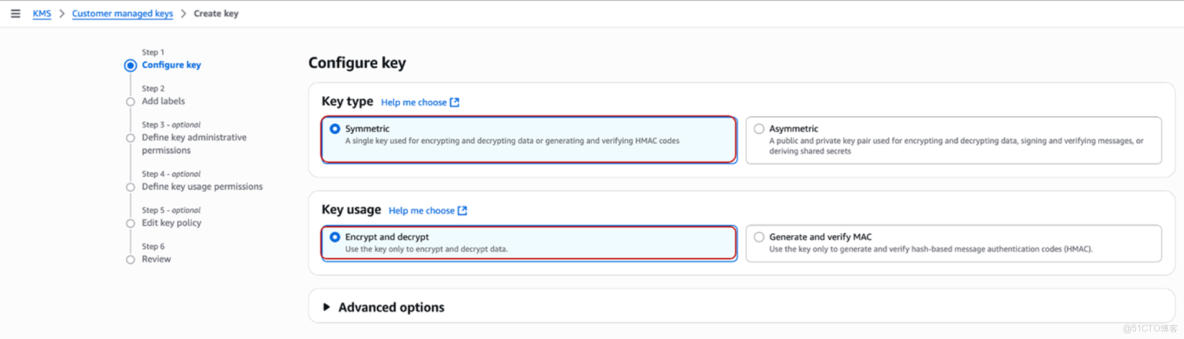
11、加密前,需要在Amazon KMS控制枱創建一個KMS Key。在Create a Key嚮導中,Configure Key步驟選擇Key類型為對稱Symmetric,Key用途選擇Encrypt and decrypt
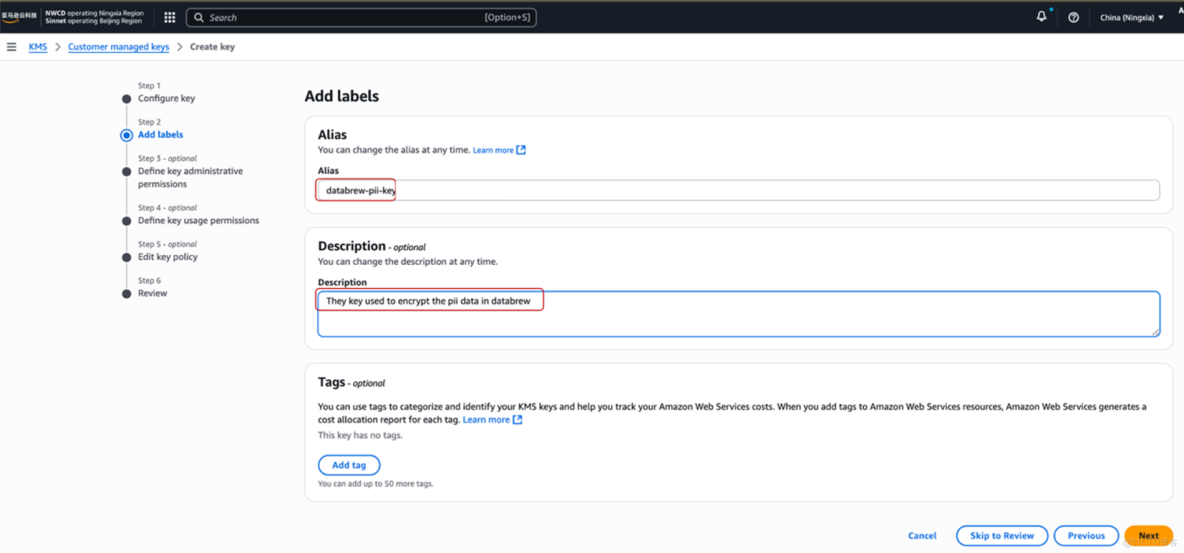
12、Add Labels步驟中,填寫Key別名為databrew-pii-key
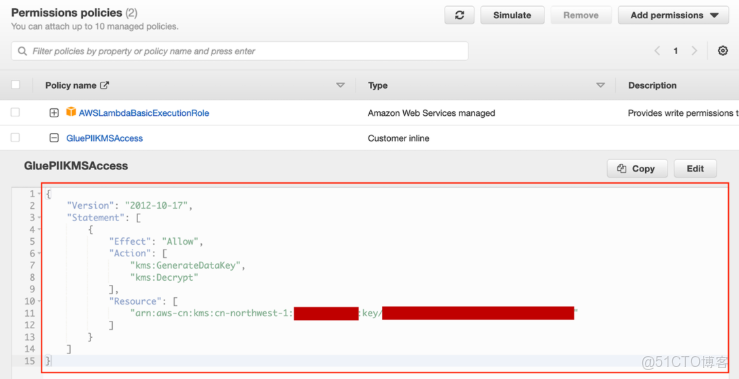
13、第3步選擇可以管理該Key的用户或角色,第4步賦權給運行DataBrew作業的角色,選擇之前自動創建的AmazonGlueDataBrewServiceRole-PII-DataBrew-Role
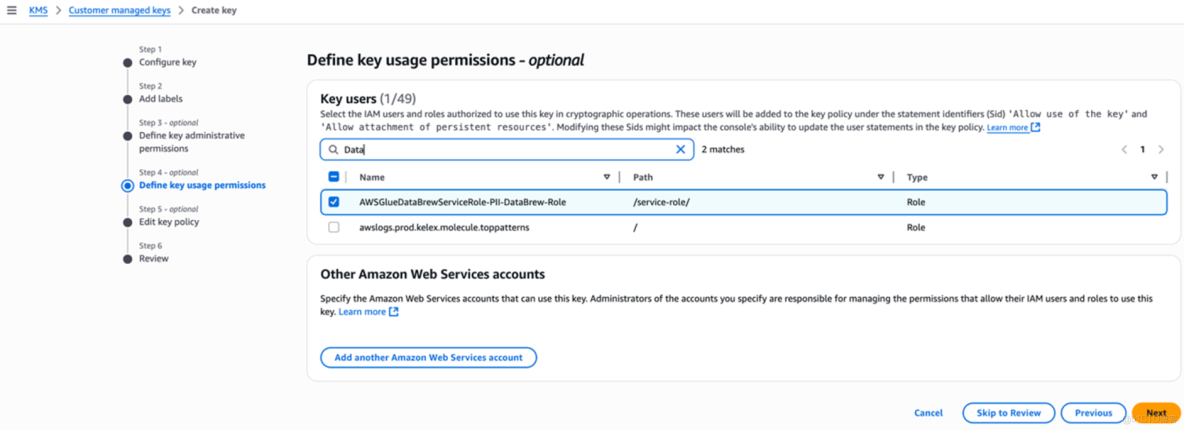
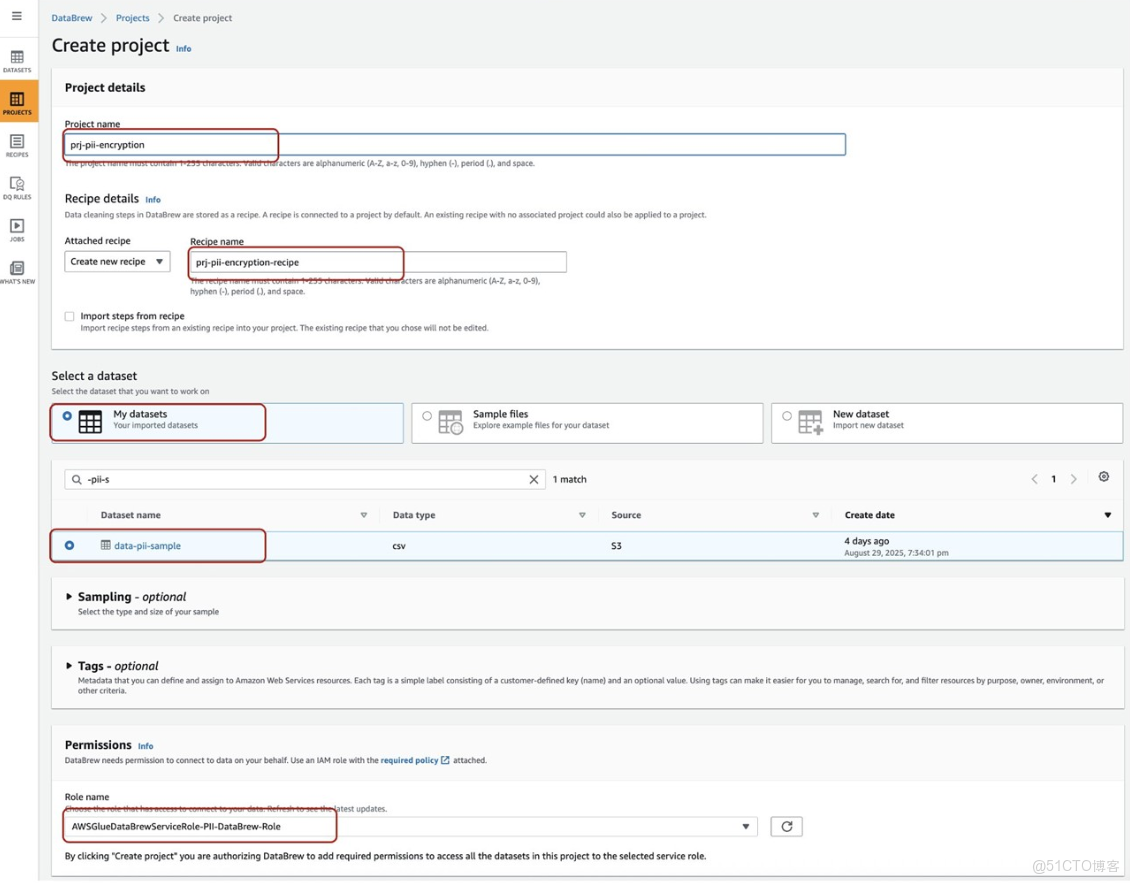
14、完成KMS Key創建並查看Key Profile以便Lambda授權。在DataBrew中創建項目prj-pii-encryption,自動生成Recipe Name為prj-pii-encryption-recipe,選擇數據集data-pii-sample,Permissions使用IAM角色AmazonGlueDataBrewServiceRole-PII-DataBrew-Role,並使用敏感轉換函數加密PII列
15、創建項目後加載數據集,在編輯器上選中SSN列,進入MORE→SENSITIVE
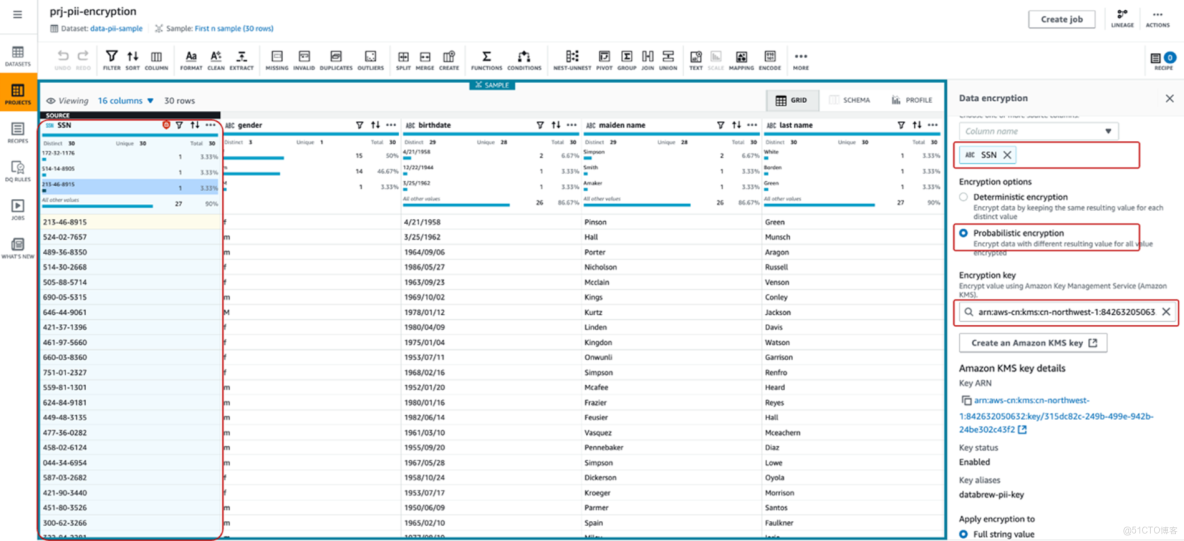
16、點擊Apply加密數據後,點擊Publish發佈Recipe。基於Recipe創建DataBrew作業,將變換邏輯應用到pii-sample數據集
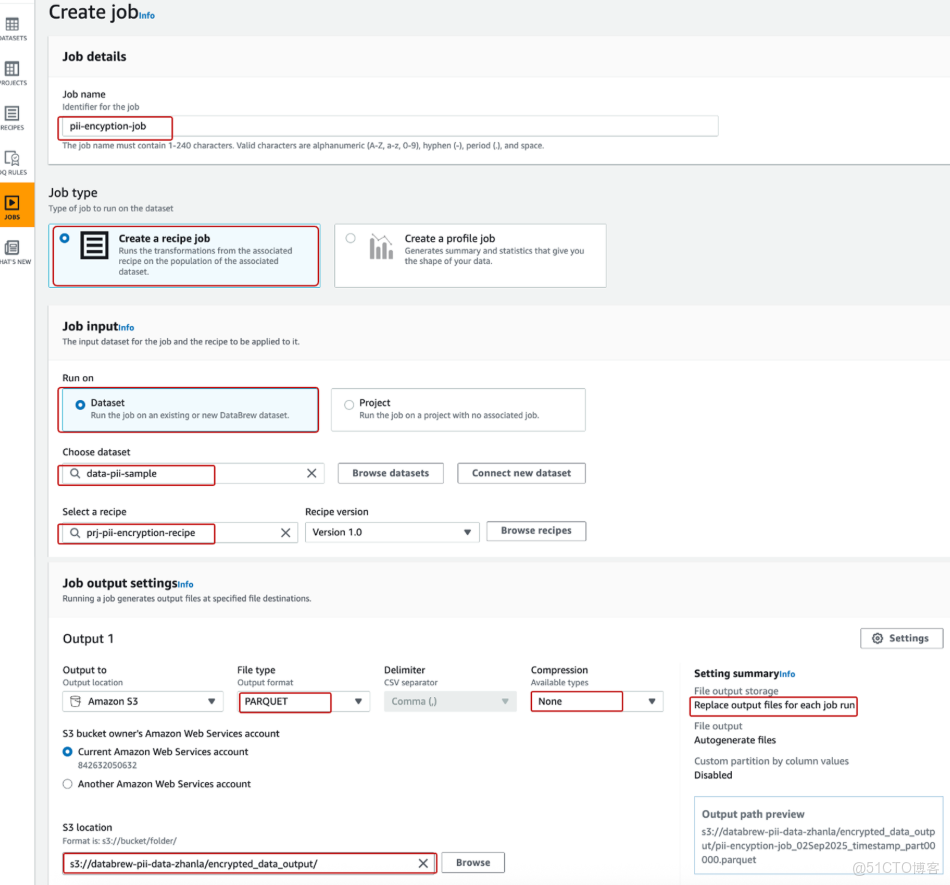
17、創建數據目錄
create database pii_sample_db
--Create table databrew_pii_sensitive_data from S3 file with csv format
CREATE EXTERNAL TABLE `databrew_pii_sensitive_data`(
`SSN` string,
`gender` string,
`birthdate` string,
`maidenname` string,
`lastname` string,
`firstname` string,
`address` string,
`city` string,
`state` string,
`zip` string,
`phone` string,
`email` string,
`cc_type` string,
`CCN` string,
`cc_cvc` string,
`cc_expiredate` string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION
's3://databrew-pii-data-zhanla/sensitive_data_input/'
TBLPROPERTIES ("skip.header.line.count"="1");
--Create table databrew_pii_encrypted_data from S3 file with Parquet format
CREATE EXTERNAL TABLE `databrew_pii_encrypted_data` (
`SSN` string,
`gender` string,
`birthdate` string,
`maidenname` string,
`lastname` string,
`firstname` string,
`address` string,
`city` string,
`state` string,
`zip` int,
`phone` string,
`email` string,
`cc_type` string,
`CCN` string,
`cc_cvc` int,
`cc_expiredate` string
)
STORED AS PARQUET
LOCATION 's3://databrew-pii-data-zhanla/encrypted_data_output/'18、創建解密Lambda函數
package com.mycompany.tools.athena;
import java.util.*;
import java.util.Base64.*;
import java.nio.charset.StandardCharsets;
import java.util.Map;
import org.apache.commons.lang3.StringUtils;
import com.amazonaws.athena.connector.lambda.handlers.UserDefinedFunctionHandler;
import com.amazonaws.encryptionsdk.AwsCrypto;
import com.amazonaws.encryptionsdk.CommitmentPolicy;
import com.amazonaws.encryptionsdk.CryptoResult;
import com.amazonaws.encryptionsdk.kmssdkv2.KmsMasterKey;
import com.amazonaws.encryptionsdk.kmssdkv2.KmsMasterKeyProvider;
/**
* Athena PII 數據解密用户定義函數 (UDF)
*
* 功能:在 Amazon Athena 中解密由 Amazon Glue DataBrew 加密的 PII 敏感數據字段
* 用途:通過 Lambda 函數實現 Athena UDF,支持在 SQL 查詢中直接解密加密字段
* 加密方式:使用 Amazon KMS 密鑰和 Amazon Encryption SDK 進行數據加密/解密
*/
public class AthenaPIIUDF extends UserDefinedFunctionHandler
{
/** UDF 源類型標識 */
private static final String SOURCE_TYPE = "MyCompany";
/** Base64 解碼器,用於解碼加密數據 */
private static Decoder base64Decoder = Base64.getDecoder();
/** KMS 主密鑰提供者 */
private static KmsMasterKeyProvider keyProvider = null;
/** 靜態緩存映射,存儲不同 KMS 密鑰 ARN 對應的密鑰提供者,避免重複創建 */
private static Map<String, KmsMasterKeyProvider> staticMap = new HashMap<String, KmsMasterKeyProvider>();
/**加密 SDK 客户端,配置為禁止加密但允許解密 */
private static final AwsCrypto crypto = AwsCrypto.builder()
.withCommitmentPolicy(CommitmentPolicy.ForbidEncryptAllowDecrypt)
.build();
/**
* 構造函數
* 初始化 Athena UDF 處理器
*/
public AthenaPIIUDF() {
super(SOURCE_TYPE);
}
/**
* 解密函數 - Athena UDF 主要功能
*
* @param ciphertext 加密的密文(Base64 編碼)
* @param keyArn KMS 密鑰 ARN,用於解密
* @return 解密後的明文字符串
* @throws IllegalStateException 當使用錯誤的密鑰時拋出異常
*/
public static String decrypt(String ciphertext, String keyArn) {
// 檢查輸入密文是否為空
if (StringUtils.isBlank(ciphertext)) {
return ciphertext;
}
// 移除字符串兩端的引號(如果存在)
if(ciphertext.startsWith("\"")){
ciphertext = ciphertext.substring(1,ciphertext.length() - 1);
}
// 從緩存中獲取或創建 KMS 密鑰提供者
if(staticMap.containsKey(keyArn)){
keyProvider = staticMap.get(keyArn);
}else{
// 創建新的 KMS 密鑰提供者並緩存
keyProvider = KmsMasterKeyProvider.builder().buildStrict(keyArn);
staticMap.put(keyArn, keyProvider);
}
// Base64 解碼密文
byte[] byteContent = base64Decoder.decode(ciphertext);
// 使用 Amazon Encryption SDK 解密數據
final CryptoResult<byte[], KmsMasterKey> decryptResult = crypto.decryptData(keyProvider, byteContent);
// 驗證解密使用的密鑰是否正確
if (!decryptResult.getMasterKeyIds().get(0).equals(keyArn)) {
throw new IllegalStateException("Wrong key id!");
}
// 將解密結果轉換為 UTF-8 字符串返回
return new String(decryptResult.getResult(), StandardCharsets.UTF_8);
}
19、Amazon Athena中通過UDF調用Lambda函數
USING EXTERNAL FUNCTION decrypt(t1 varchar, t2 varchar)
RETURNS varchar
LAMBDA 'athena-udf-gluepii'
SELECT
decrypt(ssn, 'arn:aws-cn:kms:<region>:<account-id>:key/<key-id>') ssnplaintext,*
FROM databrew_pii_encrypted_data20、運行結果如下圖所示,密文經過UDF調用Amazon Lambda 被解密出來
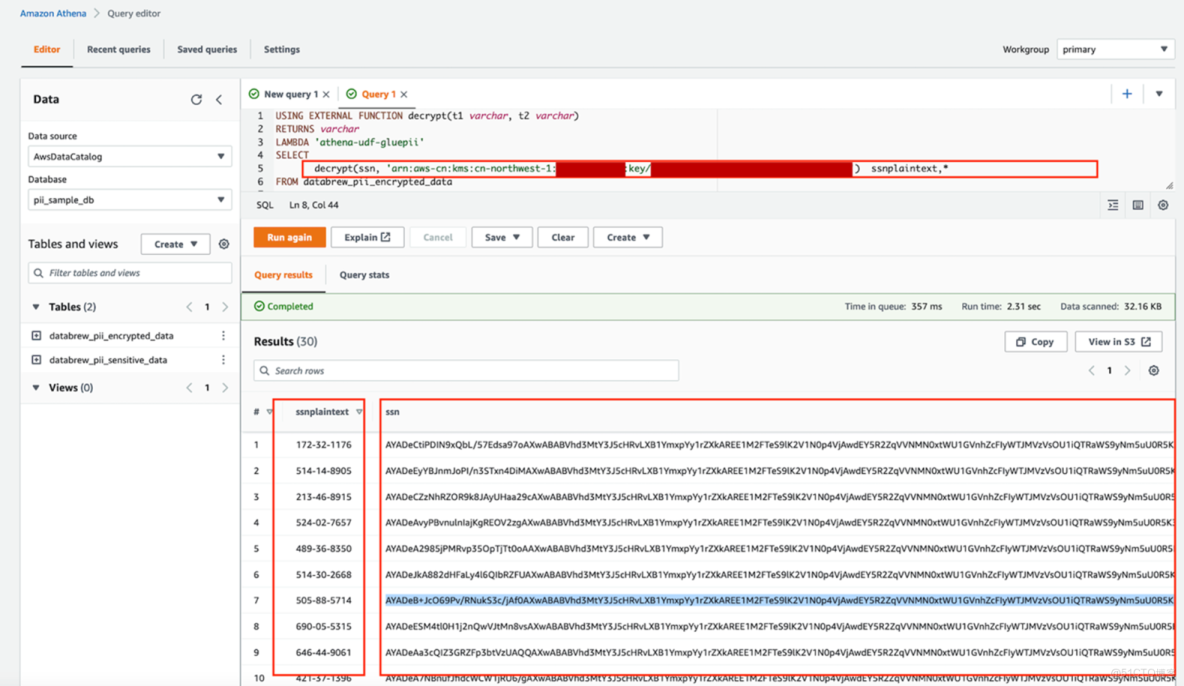
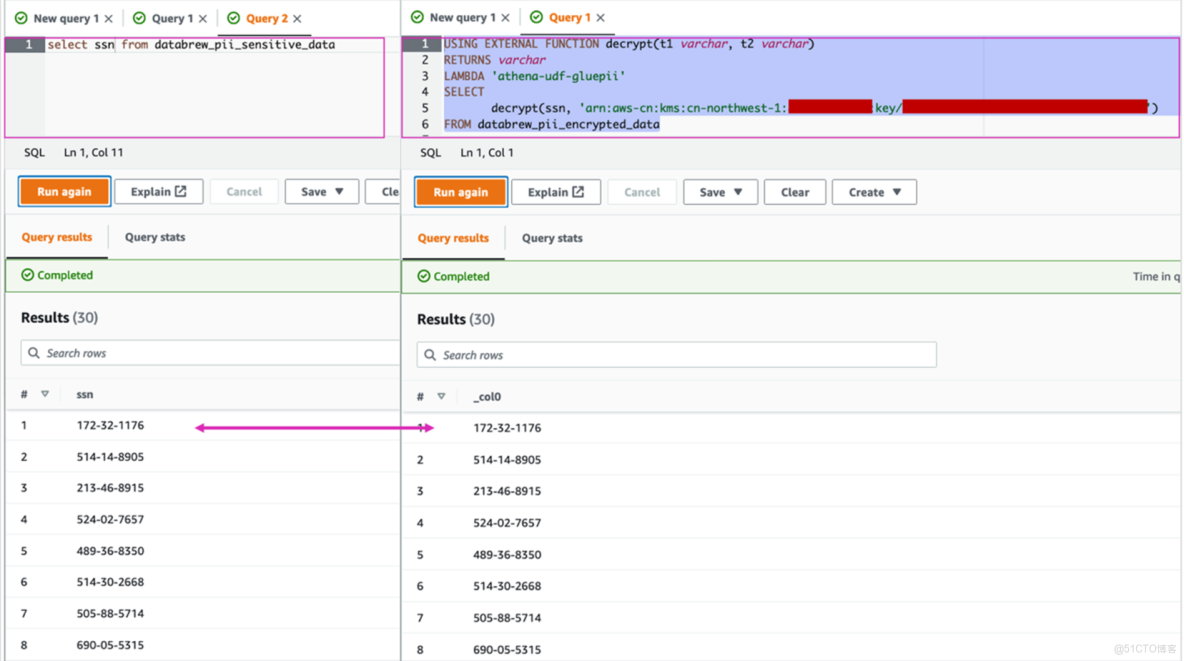
21、比較原PII數據和解密後的數據
總結
通過本實戰案例,我們展示了從源數據識別、PII 加密、數據目錄管理,到 Athena 查詢中基於 Lambda 的動態解密的完整流程。該方案實現了敏感數據全生命週期保護,避免明文長期存儲,同時利用 Serverless 架構提高了擴展性與操作效率,為企業在雲端安全處理敏感數據提供了可落地的實踐參考。
以上就是本文的全部內容啦。最後提醒一下各位工友,如果後續不再使用相關服務,別忘了在控制枱關閉,避免超出免費額度產生費用~