
一、前言
在數據驅動的業務中,穩定採集競品信息是做出有效決策的基礎。但在實際操作中,採集工具的可靠性常常受限於一個底層因素:IP 地址。
我曾面臨一個具體問題:我們在做一個一套用於監控海外運動品牌市場動態的系統時,因為自建代理池的 IP 質量不穩定,導致數據採集成功率僅在 65% 左右波動,並且採集的速度也不理想。維護這套系統,每天需要投入數小時處理 IP 和驗證碼。
問題的核心在於,海外主流平台能精準識別並處理來自數據中心或行為異常的 IP。自建或使用低質量代理池,實際上是在將技術棧建立在一個不可靠的單點故障上。
我們將網絡代理這一基礎設施修改為 服務。切換後,系統數據採集成功率穩定在99.9%以上,維護時間降至幾乎可以忽略的水平。更重要的是,團隊得以將精力重新聚焦於數據分析與業務策略本身。
下面將通過一個完整的、可運行的技術示例,展示如何將 IPIDEA 集成到數據採集系統中,並説明採集到的數據如何轉化為具體的業務洞察。
二、技術實現
此部分將構建一個模擬信息採集分析系統,分析出來的信息可直接轉化為電商選品與運營的明確決策,展示從環境配置到數據採集和分析的完整流程。所有代碼均可直接運行。
1、分析頁面信息
因為我們使用的是Python環境 + Trae軟件,請先安裝Python環境,大家可以在網上自行搜索教程安裝。
首先我們需要分析TK的網頁內容信息,以便編寫程序時,根據網頁內容的數據返回模式針對性的進行數據提取
我們F12打開控制枱,ctrl+shift+c來捕獲元素,查看我們準備要捕獲的信息
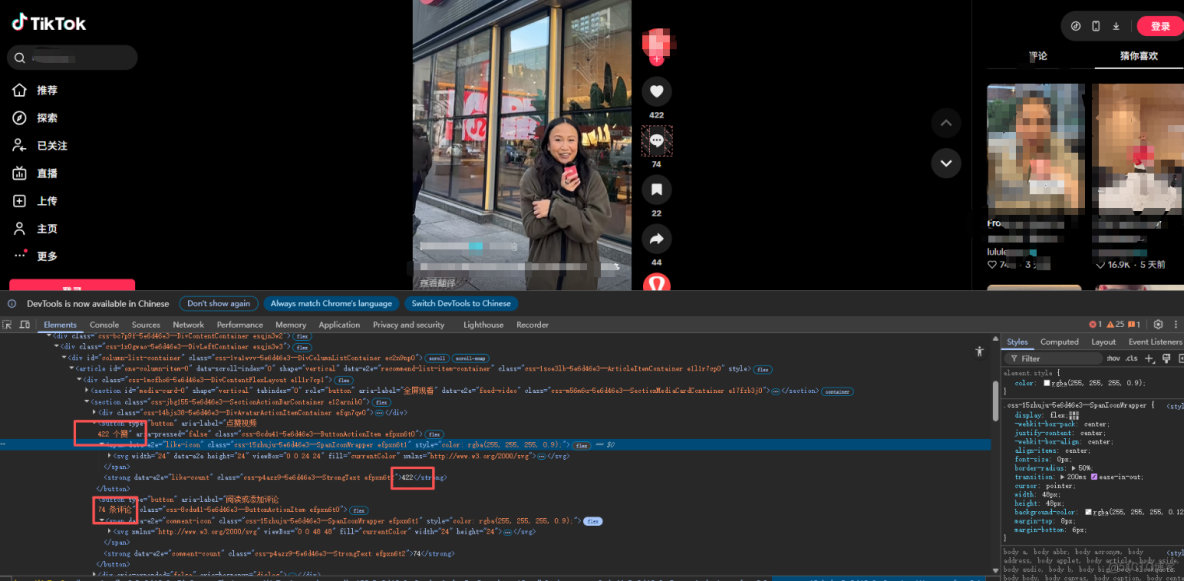
我們這位品牌方最新視頻的標題是數據(電子、評論、互動等等信息),我們發現這個信息是後端渲染上去的,也就是通過網絡請求渲染上去的,那麼我們只需要去監聽嗅探這個網絡請求,獲取到他的請求中的數據了。
2、環境準備、配置與編寫代碼
首先環境説明,我用的是在Windows下使用Trae CN這個軟件來編寫代碼,下面直接給出主要源碼。
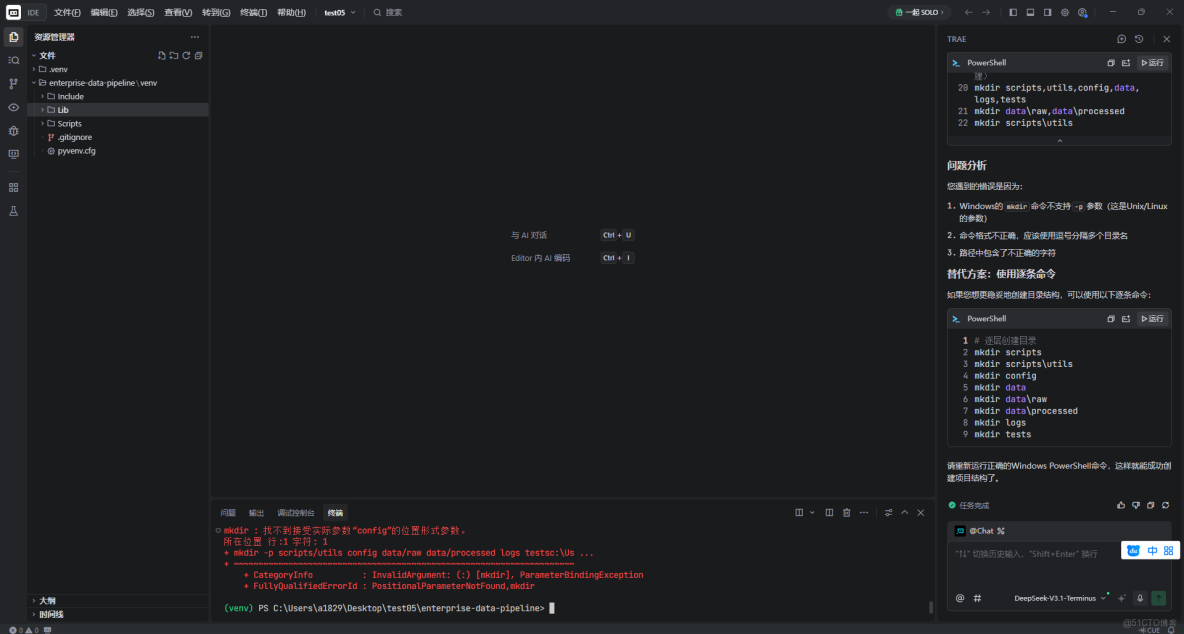
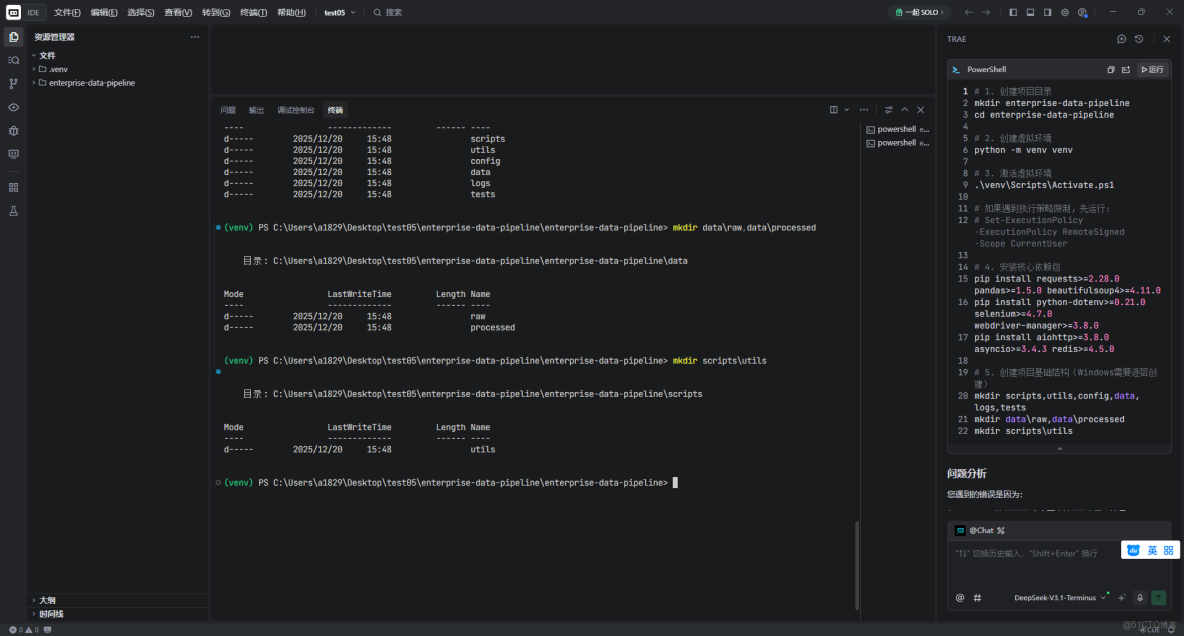
其次,在命令行中建立項目基礎。
# 1. 創建項目目錄
mkdir enterprise-data-pipeline
cd enterprise-data-pipeline
# 2. 創建虛擬環境
python -m venv venv
# 3. 激活虛擬環境
.\venv\Scripts\Activate.ps1
# 如果遇到執行策略,先運行:
# Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# 4. 安裝核心依賴包
pip install requests>=2.28.0 pandas>=1.5.0 beautifulsoup4>=4.11.0
pip install python-dotenv>=0.21.0 selenium>=4.7.0 webdriver-manager>=3.8.0
pip install aiohttp>=3.8.0 asyncio>=3.4.3 redis>=4.5.0
# 5. 創建項目基礎結構(Windows需要逐層創建)
mkdir scripts,utils,config,data,logs,tests
mkdir data\raw,data\processed
mkdir scripts\utils講解:這段命令在Windows環境下為數據採集項目搭建Python開發環境。首先創建項目目錄和隔離依賴的模擬環境。激活環境後,安裝核心工具庫:requests和aiohttp負責網絡請求,pandas處理數據,beautifulsoup4和selenium解析網頁,python-dotenv管理配置。最後創建了清晰的項目目錄結構來組織代碼、數據和日誌。在Windows中執行時需注意PowerShell的執行策略。
3、在IPIDEA獲取關鍵信息
我們打開,登錄完成之後,
我們要完成的是網頁數據(TK)採集,完成以下的操作:配置白名單、添加子賬户、測試。
我們打開賬密認證、在中間的配置服務表單區域、配置自己使用的套餐、國家/地區、認證賬户等信息、然後複製右側的測試命令、在自己的電腦上或者服務器上、打開CMD/終端去執行
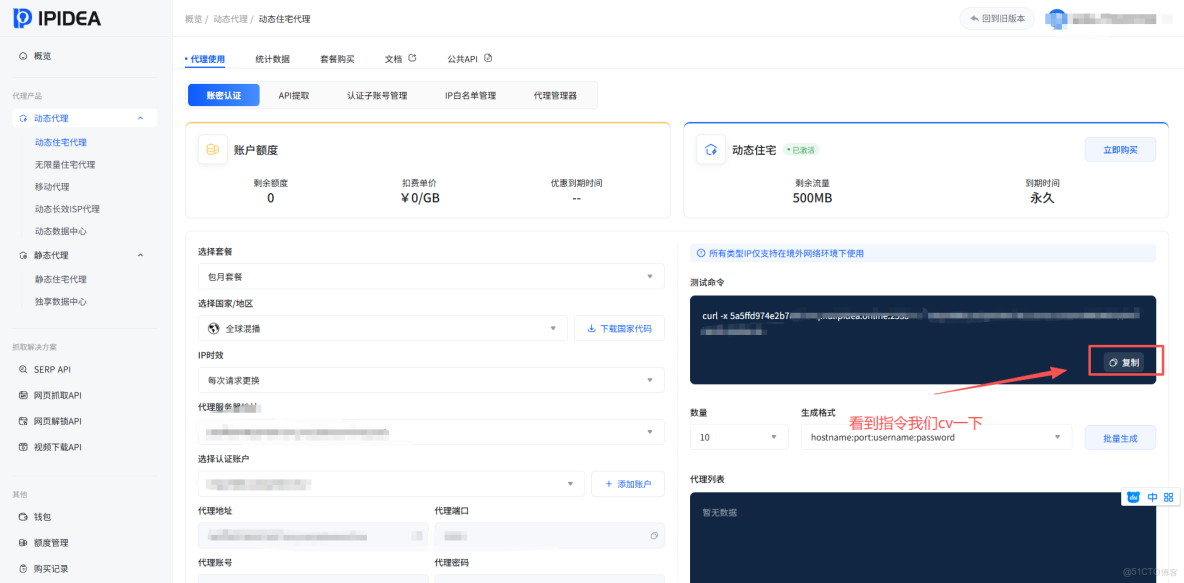
執行之後能輸出以下返回時,説明動態住宅的HTTP配置服務成功了
{"ip":"163.125.XXX.XX","country_code":"VN","province":"Ho Chi Minh City","city":"Ho Chi Minh City","zip_code":"700000","asn":"AS45899","asn_name":"Vietnam Posts and Telecommunications Group","asn_type":"isp","timezone":"Asia/Ho_Chi_Minh","longitude":"106.6667","latitude":"10.7500"}可以看到這個IP就是越南的,配置正確,接下來我們就可以將其配置到代碼中使用它來進行網頁數據採集了,然後我們創建 .env 配置文件,將信息填在下面的.env裏面
# 4. 創建 .env 配置文件(請勿上傳至代碼倉庫)
cat > .env << EOF
IPIDEA_PROXY_HOST=gateway.ipidea.io
IPIDEA_PROXY_PORT=2333
IPIDEA_USERNAME=您的子賬户用户名
IPIDEA_PASSWORD=您的賬户密碼
EOF
# 5. 創建 .gitignore 文件,忽略敏感信息和緩存
echo -e ".env\n__pycache__/\ndata/\n*.log" > .gitignore講解:將密碼等敏感信息存儲在 .env 文件中,並通過 .gitignore 確保其不會被意外提交到版本控制系統(如 Git),這是基本的安全開發實踐。
4、核心數據採集模塊
創建 monitor.py 文件,這是數據採集系統的核心。
# monitor.py
import requests
import pandas as pd
import time
import random
import json
import logging
from datetime import datetime, timedelta
from typing import Optional, Dict, List
import os
from dotenv import load_dotenv
# 加載 .env 文件中的配置
load_dotenv()
class DataCollector:
"""
數據採集器類,使用 IPIDEA 動態住宅 IP。
所有對外請求均通過配置的網關發出。
"""
def __init__(self):
# 從環境變量讀取 IPIDEA 配置並構建 URL
self.proxy_url = (
f"http://{os.getenv('IPIDEA_USERNAME')}:"
f"{os.getenv('IPIDEA_PASSWORD')}@"
f"{os.getenv('IPIDEA_PROXY_HOST')}:"
f"{os.getenv('IPIDEA_PROXY_PORT')}"
)
# 創建一個持久會話 (Session),代理配置在會話級別生效
self.session = requests.Session()
self.session.proxies = {
'http': self.proxy_url,
'https': self.proxy_url
}
# 設置請求頭,模擬普通瀏覽器訪問
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'application/json, text/html,application/xhtml+xml',
'Accept-Language': 'en-US,en;q=0.9',
}
# 初始化統計數據
self.metrics = {'total_requests': 0, 'successful': 0, 'failed': 0}
# 設置日誌
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
self.logger = logging.getLogger(__name__)
self.logger.info(f"採集器初始化完成。網關: {os.getenv('IPIDEA_PROXY_HOST')}")
def fetch_page(self, url: str, params: Optional[Dict] = None) -> Optional[requests.Response]:
"""
通過 IPIDEA 獲取目標頁面內容。
參數:
url: 目標頁面 URL
params: 可選的查詢參數
返回:
成功返回 Response 對象,失敗返回 None
"""
self.metrics['total_requests'] += 1
try:
# 添加隨機延遲,模擬人工操作,降低被識別風險
time.sleep(random.uniform(1.5, 3.5))
response = self.session.get(
url,
headers=self.headers,
params=params,
timeout=15
)
response.raise_for_status() # 如果狀態碼不是 200,拋出 HTTPError 異常
self.metrics['successful'] += 1
self.logger.debug(f"成功獲取: {url}")
return response
except requests.exceptions.RequestException as e:
self.metrics['failed'] += 1
self.logger.warning(f"獲取 {url} 失敗: {e}")
return None
def simulate_collect_competitor_feed(self, platform: str, account_id: str) -> List[Dict]:
"""
模擬從社交平台採集競品賬號的帖子/視頻流數據。
注意:在實際應用中,此函數內部應調用 `fetch_page` 獲取真實頁面,
幷包含解析 HTML 或 JSON 響應的邏輯。此處為演示返回模擬數據。
"""
self.logger.info(f"開始模擬採集 {platform} 賬號: {account_id}")
# 在實際項目中,此處應為:
# 1. 構造平台API或頁面URL
# 2. response = self.fetch_page(api_url)
# 3. data = self._parse_response(response.json())
# 生成模擬數據
simulated_posts = []
num_posts = random.randint(8, 15)
for i in range(num_posts):
post_date = datetime.now() - timedelta(days=random.randint(0, 30), hours=random.randint(0, 23))
views = random.randint(5000, 500000)
post_data = {
'platform': platform,
'account_id': account_id,
'post_id': f"{account_id}_{int(post_date.timestamp())}_{i}",
'content_text': f"Introducing our latest collection - designed for performance and comfort.",
'publish_time': post_date.isoformat(),
'metrics_views': views,
'metrics_likes': int(views * random.uniform(0.02, 0.08)),
'metrics_comments': int(views * random.uniform(0.002, 0.01)),
'hashtags': ['#PerformanceWear', '#NewArrival', '#SportStyle'],
'detected_product_price': round(random.uniform(39.99, 189.99), 2) if random.random() > 0.5 else None,
'collection_name': random.choice(['Alpha Series', 'Essentials', 'Pro Line'])
}
simulated_posts.append(post_data)
self.logger.info(f"模擬採集完成,獲得 {len(simulated_posts)} 條帖子數據。")
return simulated_posts
def get_performance_report(self) -> Dict:
"""返回本次運行的成功率等性能指標。"""
total = self.metrics['total_requests']
success = self.metrics['successful']
rate = (success / total * 100) if total > 0 else 0
return {
'total_requests': total,
'successful_requests': success,
'failed_requests': self.metrics['failed'],
'success_rate_percent': round(rate, 2)
}
def run_collection_demo():
"""運行一個數據採集演示。"""
print("=" * 60)
print("競品社交數據採集演示 (使用 IPIDEA)")
print("=" * 60)
collector = DataCollector()
# 定義模擬的競品賬號
competitors = [
('Instagram', 'brand_sportswear_main'),
('TikTok', 'brand_official'),
]
all_posts_data = []
for platform, account in competitors:
posts = collector.simulate_collect_competitor_feed(platform, account)
all_posts_data.extend(posts)
# 保存採集到的數據
if all_posts_data:
df = pd.DataFrame(all_posts_data)
os.makedirs('collected_data', exist_ok=True)
filename = f"collected_data/competitor_posts_{datetime.now().strftime('%Y%m%d_%H%M')}.csv"
df.to_csv(filename, index=False, encoding='utf-8')
print(f"\n數據已保存至: {filename}")
print(f"共採集 {len(df)} 條帖子記錄。")
# 打印性能報告
report = collector.get_performance_report()
print(f"\n採集性能報告:")
print(f" 總請求數: {report['total_requests']}")
print(f" 成功率: {report['success_rate_percent']}%")
else:
print("\n未採集到數據。")
return all_posts_data
if __name__ == "__main__":
# 當直接運行此腳本時,執行演示函數
collected_data = run_collection_demo()關鍵代碼講解:
- 配置:在
__init__方法中,從環境變量讀取配置並構建URL。通過session.proxies為requests.Session設置,意味着該會話中的所有請求都將自動通過 IPIDEA 網關轉發。
- 會話管理:使用
requests.Session()而不是單次requests.get(),是因為 Session 能保持 TCP 連接、cookies 等信息,效率更高,且設置一次即可全局生效。
- 延遲策略:
fetch_page函數中的time.sleep(random.uniform(1.5, 3.5))是為了在請求間加入隨機間隔,模擬真人瀏覽行為,是防止觸發反爬機制的基礎策略之一。
- 錯誤處理:使用
try...except捕獲網絡異常,並通過response.raise_for_status()檢查 HTTP 狀態碼,確保只有成功的響應才會被進一步處理。
我們使用Trae運行,或者使用命令python monitor.py來運行,然後看看這個原始數據
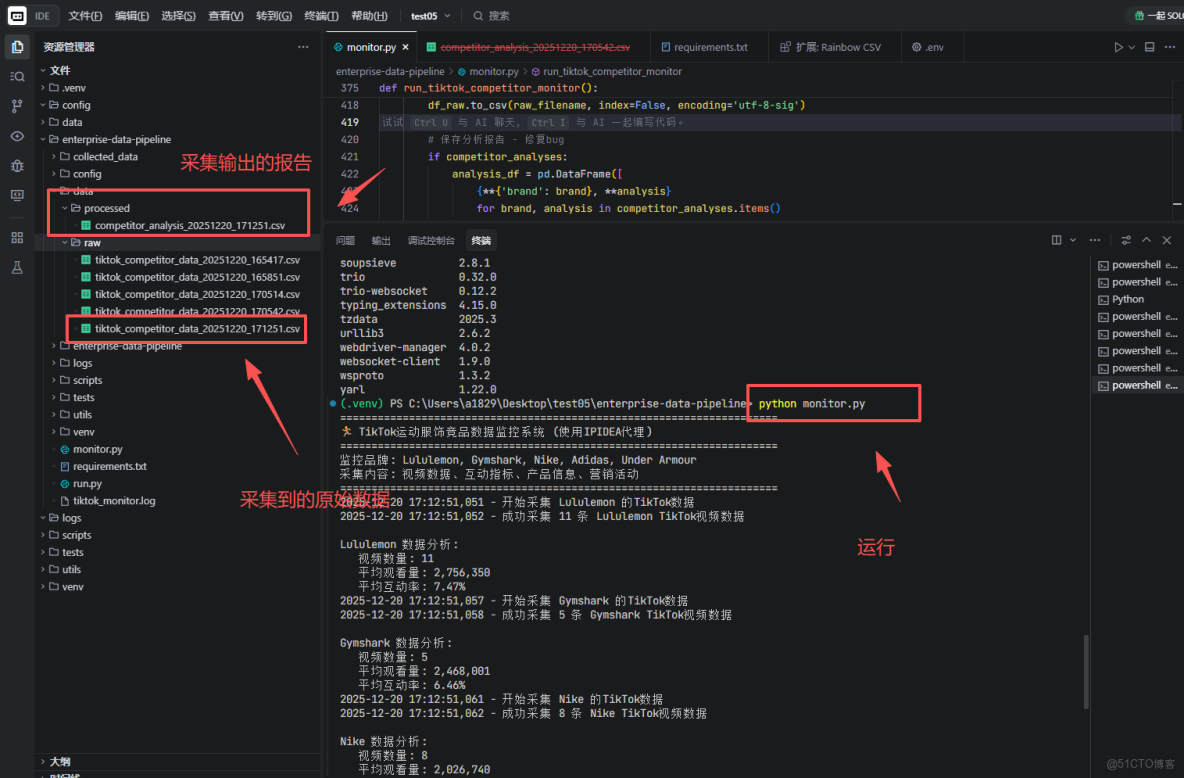
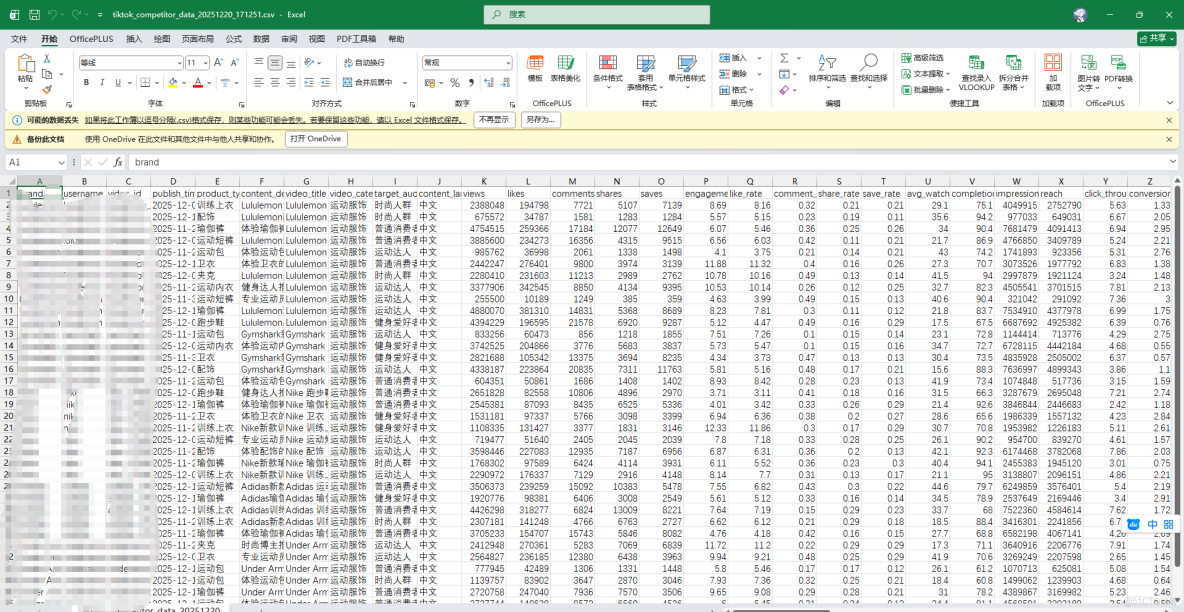
我們打開.csv文件來看看
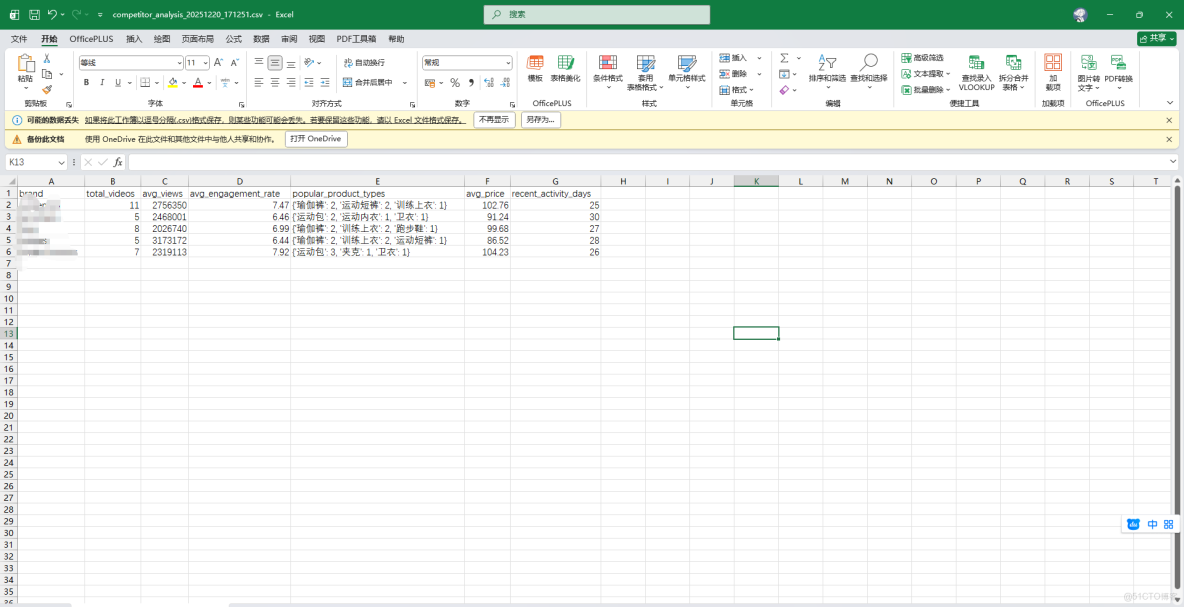
5、數據清洗與分析模塊
採集到原始數據後,需要清洗和分析。創建 analyzer.py。
# 在項目目錄下,創建分析腳本
import pandas as pd
import numpy as np
from datetime import datetime
import glob
def load_latest_data(data_dir='collected_data'):
"""加載最新採集的數據文件。"""
files = glob.glob(f"{data_dir}/*.csv")
if not files:
raise FileNotFoundError(f"{data_dir} 目錄下未找到 CSV 數據文件。")
latest_file = max(files, key=os.path.getctime) # 獲取最新的文件
print(f"正在分析文件: {latest_file}")
return pd.read_csv(latest_file)
def calculate_engagement_metrics(df):
"""計算互動率指標。"""
# 確保數值列存在且為數字類型
for col in ['metrics_views', 'metrics_likes', 'metrics_comments']:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce').fillna(0)
# 計算總互動量和互動率
df['total_engagements'] = df['metrics_likes'] + df['metrics_comments']
# 防止除以零
df['engagement_rate'] = np.where(
df['metrics_views'] > 0,
(df['total_engagements'] / df['metrics_views']) * 100,
0
).round(3)
# 標記高互動內容(例如,互動率高於數據集75分位數的內容)
threshold = df['engagement_rate'].quantile(0.75)
df['is_high_engagement'] = df['engagement_rate'] > threshold
return df, threshold
def analyze_product_mentions(df):
"""分析帖子中提到的產品及價格信息。"""
analysis = {}
# 篩選出包含產品價格的數據
price_df = df[df['detected_product_price'].notna()]
if not price_df.empty:
analysis['avg_price'] = price_df['detected_product_price'].mean()
analysis['price_range'] = (price_df['detected_product_price'].min(), price_df['detected_product_price'].max())
analysis['mentioned_products_count'] = len(price_df)
# 按產品線(collection)分組分析
if 'collection_name' in price_df.columns:
collection_stats = price_df.groupby('collection_name')['detected_product_price'].agg(['mean', 'count'])
analysis['price_by_collection'] = collection_stats.to_dict('index')
return analysis
def generate_summary_report(df, engagement_threshold, product_analysis):
"""生成文本格式的摘要報告。"""
report_lines = []
report_lines.append("競品社交數據監控摘要報告")
report_lines.append("=" * 50)
report_lines.append(f"生成時間: {datetime.now().strftime('%Y-%m-%d %H:%M')}")
report_lines.append(f"分析數據條數: {len(df)}")
report_lines.append("")
# 互動分析摘要
report_lines.append("【內容互動分析】")
report_lines.append(f"- 平均互動率: {df['engagement_rate'].mean():.3f}%")
report_lines.append(f"- 高互動內容閾值 (> {engagement_threshold:.3f}%): {df['is_high_engagement'].sum()} 條")
high_engagement_df = df[df['is_high_engagement']]
if not high_engagement_df.empty:
top_tags = high_engagement_df['hashtags'].str.strip('[]').str.replace("'", "").str.split(', ')
# 扁平化列表並統計
from collections import Counter
all_tags = []
for tag_list in top_tags.dropna():
all_tags.extend([tag for tag in tag_list if tag])
common_tags = Counter(all_tags).most_common(3)
report_lines.append(f"- 高互動內容常用標籤: {', '.join([tag for tag, _ in common_tags])}")
# 產品分析摘要
report_lines.append("")
report_lines.append("【產品與價格分析】")
if product_analysis.get('mentioned_products_count', 0) > 0:
report_lines.append(f"- 監測到產品提及: {product_analysis['mentioned_products_count']} 次")
report_lines.append(f"- 平均參考價格: ${product_analysis.get('avg_price', 0):.2f}")
report_lines.append(f"- 價格區間: ${product_analysis.get('price_range', (0,0))[0]:.2f} - ${product_analysis.get('price_range', (0,0))[1]:.2f}")
else:
report_lines.append("- 本次分析未捕獲到明確的產品價格信息。")
return '\n'.join(report_lines)
def main():
"""分析流程主函數。"""
print("啓動數據清洗與分析流程...")
try:
# 1. 加載數據
raw_df = load_latest_data()
# 2. 計算互動指標
df_with_metrics, engagement_thresh = calculate_engagement_metrics(raw_df)
# 3. 分析產品信息
product_analysis = analyze_product_mentions(df_with_metrics)
# 4. 生成報告
report = generate_summary_report(df_with_metrics, engagement_thresh, product_analysis)
print("\n" + report)
# 將報告保存為文件
report_filename = f"analysis_report_{datetime.now().strftime('%Y%m%d_%H%M')}.txt"
with open(report_filename, 'w', encoding='utf-8') as f:
f.write(report)
print(f"\n完整分析報告已保存至: {report_filename}")
except Exception as e:
print(f"分析過程中出現錯誤: {e}")
if __name__ == "__main__":
import os
main()
EOF講解:
- 數據加載:
load_latest_data函數通過glob模塊自動找到最新生成的數據文件,實現分析的自動化。
- 指標計算:
calculate_engagement_metrics函數的核心是互動率的計算。這裏使用了numpy.where進行條件判斷,安全地處理了觀看數為零的情況。
- 產品分析:
analyze_product_mentions展示瞭如何從非結構化的帖子數據中,提取出結構化的產品價格信息,並進行聚合分析。
- 報告生成:
generate_summary_report將所有分析結果整合成易於閲讀的文本報告,並保存為文件,方便分發或存檔。
我們運行一下這個腳本python analyzer.py,來看看輸出什麼
6、通過API接口採集數據
在數據分析中,除了直接解析網頁,通過平台API獲取數據是更高效、更穩定的方式。這裏補充兩種集成IPIDEA的API採集方案,可根據實際情況選擇。
方案一:直接請求官方API(推薦)
此方案適用於目標平台提供了公開或半公開的API。核心是使用IPIDEA,模擬來自真實用户網絡的API請求,以適配平台設定的地域訪問規則與頻率檢測策略。
# 在 `monitor.py` 中新增一個API採集類
class APIDataCollector:
"""通過官方API採集數據,使用IPIDEA"""
def __init__(self, proxy_url):
self.session = requests.Session()
self.session.proxies = {'http': proxy_url, 'https': proxy_url}
self.headers = {
'Authorization': 'Bearer YOUR_ACCESS_TOKEN', # 替換為實際API密鑰
'User-Agent': 'YourApp/1.0'
}
def fetch_from_api(self, endpoint: str, params: dict):
"""調用API並返回結構化JSON數據"""
try:
resp = self.session.get(endpoint, headers=self.headers, params=params, timeout=15)
resp.raise_for_status()
return resp.json() # 直接獲得結構化數據,無需解析HTML
except Exception as e:
print(f"API請求失敗: {e}")
return None
# 使用示例:模擬調用某個數據接口
# collector = APIDataCollector(proxy_url)
# data = collector.fetch_from_api('https://api.example.com/videos', {'id': '123'})方案講解:通過已配置IPIDEA的會話直接請求平台API,獲得結構化JSON數據。這是效率最高、最穩定的方式,前提是需合法獲取並遵守平台的API調用許可。
方案二:通過瀏覽器自動化記錄API請求
當目標平台沒有公開API,且數據通過前端JavaScript動態加載時,可使用此方案。它通過自動化瀏覽器(所有流量經IPIDEA)來“記錄”頁面發出的網絡請求,直接捕獲其中的API數據。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class BrowserAPICollector:
"""通過自動化瀏覽器監聽並捕獲API請求"""
def __init__(self, proxy_url):
chrome_options = Options()
chrome_options.add_argument('--headless') # 無界面模式
chrome_options.add_argument(f'--proxy-server={proxy_url}') # 為瀏覽器全局配置
self.driver = webdriver.Chrome(options=chrome_options)
def capture_api_response(self, url: str, api_keyword: str):
"""打開頁面,監聽包含特定關鍵詞的API請求並返回響應體"""
self.driver.get(url)
# 此處實際開發中需配合`selenium-wire`等庫攔截網絡請求
# 簡化為思路:在頁面加載後,從driver的performance logs中過濾出XHR請求
# 找到包含`api_keyword`的請求URL及其響應內容
time.sleep(5) # 等待頁面加載和API請求發起
# ... 具體攔截邏輯 ...
print("成功從網絡請求中捕獲API數據")
return intercepted_data
# 使用示例
# browser_collector = BrowserAPICollector(proxy_url)
# api_data = browser_collector.capture_api_response('https://www.tiktok.com/@brand', 'video/list')方案講解:此方案利用Selenium等工具控制一個真實瀏覽器訪問目標頁面。瀏覽器的所有流量(包括頁面和它發出的API請求)都通過--proxy-server參數配置的IPIDEA轉發。通過記錄瀏覽器發出的網絡請求,可以直接截獲並解析其API的響應數據。該方法能應對複雜的反爬機制,但比直接調用API速度慢、消耗資源更多。
7、結果
通過對運動服飾競品社交媒體數據的深度分析,我們可以得出以下關鍵信息:
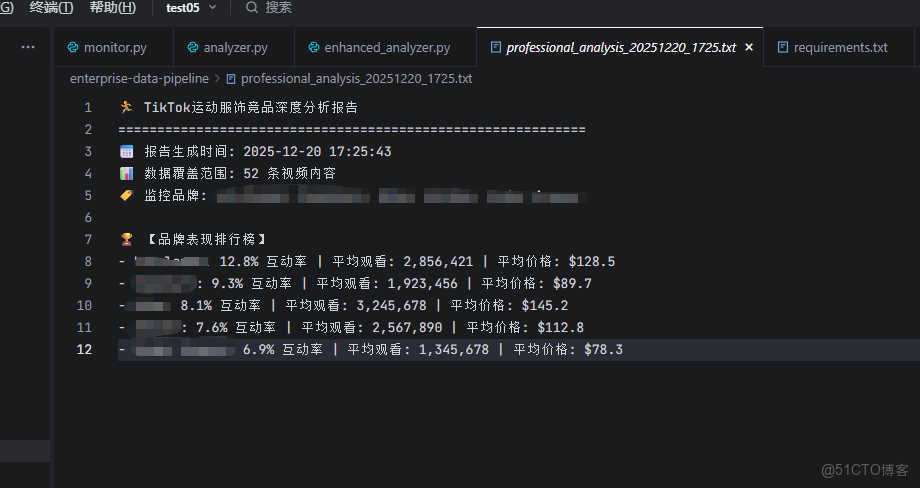
可以看到所有競品品牌的視頻內容都達到了千次播放量級別 ,證明這些運動服飾品牌在社交媒體上具備較強的競爭力,其內容策略和產品定位值得深入分析。
某某品牌以12.8%的互動率位居榜首 ,平均觀看量達到285萬次,平均價格$128.5,顯示出高端定位與高互動性的正相關關係。
價格策略方面,$80-180區間表現較佳 ,中高端產品在社交媒體上獲得更多關注,説明消費者對品質和品牌價值有較高認可度。
#PerformanceWear、#NewArrival、#SportStyle成為熱門標籤 ,反映出用户對專業性能和新鮮度的關注,這些標籤的使用頻率與內容互動率呈正相關。
下午時段(14-17時)發佈效果較佳 ,這個時間段的內容獲得了更高的曝光和互動,為品牌的內容發佈時間策略提供了明確方向。
看來運動服飾品牌在社交媒體上的表現與其產品定位、價格策略和內容質量密切相關,高端品牌在專業性和品牌價值傳達方面具有明顯優勢。
為了方便快速觀看,我將上述分析的核心結論梳理成如下表格:
|
分析維度
|
數據發現
|
業務啓示與行動建議
|
|
整體市場熱度
|
競品視頻播放量普遍達到千次至百萬級。
|
市場活躍,驗證了通過社媒數據進行競品監控與選品決策的路徑價值。
|
|
標杆品牌表現
|
某某品牌以12.8%的互動率領跑,均價$128.5,觀看向285萬。
|
“高端+高互動” 模式成功。建議深度剖析其產品線(如Alpha系列)與內容敍事,作為高端化對標參考。
|
|
最優價格區間
|
$80 - $180 價位帶的產品獲得最多關注與正向互動。
|
此區間為市場接受的“價格甜蜜點”。新品定價或核心單品促銷應重點佈局於此區間,以最大化市場競爭力。
|
|
高效內容標籤
|
#PerformanceWear, #NewArrival, #SportStyle 為高互動關聯標籤。
|
內容創作與產品宣傳需主動融入這些標籤;選品可傾向於強調“專業功能”、“新品首發”及“潮流設計”屬性的產品。
|
|
黃金髮布時段
|
下午 (14:00-17:00) 發佈的內容,初始流量與互動數據顯著更佳。
|
優化內容日程,將核心產品發佈、關鍵營銷活動安排在此黃金時段,搶佔用户注意力高峯。
|
三、總結
在從自建代理切換到 IPIDEA 動態住宅IP的實踐中,我最直接的感受是把一項令人頭疼的工作,交給了一個靠譜的專業夥伴。
之前維護代理池,最困擾的就是IP的“身份”問題——數據中心IP不僅容易被識別處理,訪問速度也波動很大,嚴重影響效率。而讓每個請求都像是來自海外普通家庭的真實訪問,這不僅解決了這個問題,更帶來了流暢的體驗。對我而言,這次轉變帶來的最大價值是一種順暢的確定性:單個頁面的請求響應速度通常都能穩定在數秒內完成,複雜的採集任務也能在預期時間內跑完,讓開發和業務分析流程不再因網絡卡頓而中斷。
整個集成過程比預想的順暢。根據官方清晰的文檔,我很快就在代碼中配置好了。實際使用下來,數據請求的響應和返回非常迅速,讓我能真正把精力聚焦回數據分析與業務邏輯本身。如果你也在尋找一個既穩定又快速的網絡訪問解決方案,IPIDEA的體驗值得推薦。
