

Hive操作語句整理
Apache Hive 是一個基於 Hadoop 的數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,並提供簡單的 SQL 查詢功能,可以將 SQL 語句轉換為 MapReduce 任務進行運行。本文將對常用的 Hive 操作語句進行整理,幫助初學者快速掌握 Hive 的基本使用方法。
1. 創建數據庫
在 Hive 中,可以通過以下命令創建數據庫:
CREATE DATABASE IF NOT EXISTS database_name
[COMMENT 'database_comment']
[LOCATION 'hdfs_path']
[WITH DBPROPERTIES (property_name=property_value, ...)];IF NOT EXISTS:如果數據庫已存在,則不會執行創建操作。COMMENT:給數據庫添加註釋。LOCATION:指定數據庫在 HDFS 上的存儲位置。WITH DBPROPERTIES:給數據庫添加屬性。

2. 刪除數據庫
刪除數據庫的命令如下:
DROP DATABASE [IF EXISTS] database_name [CASCADE | RESTRICT];IF EXISTS:如果數據庫不存在,則不會拋出錯誤。CASCADE:級聯刪除,即刪除數據庫及其所有表。RESTRICT(默認):如果數據庫中有表,則不允許刪除數據庫。
3. 創建表
創建表的基本語法如下:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)];EXTERNAL:創建外部表,刪除表時不會刪除數據。PARTITIONED BY:分區表,用於提高查詢效率。CLUSTERED BY:桶表,用於進一步優化查詢性能。ROW FORMAT:指定行格式。STORED AS:指定存儲格式。LOCATION:指定表在 HDFS 上的存儲位置。TBLPROPERTIES:給表添加屬性。
4. 刪除表
刪除表的命令如下:
DROP TABLE [IF EXISTS] table_name;IF EXISTS:如果表不存在,則不會拋出錯誤。
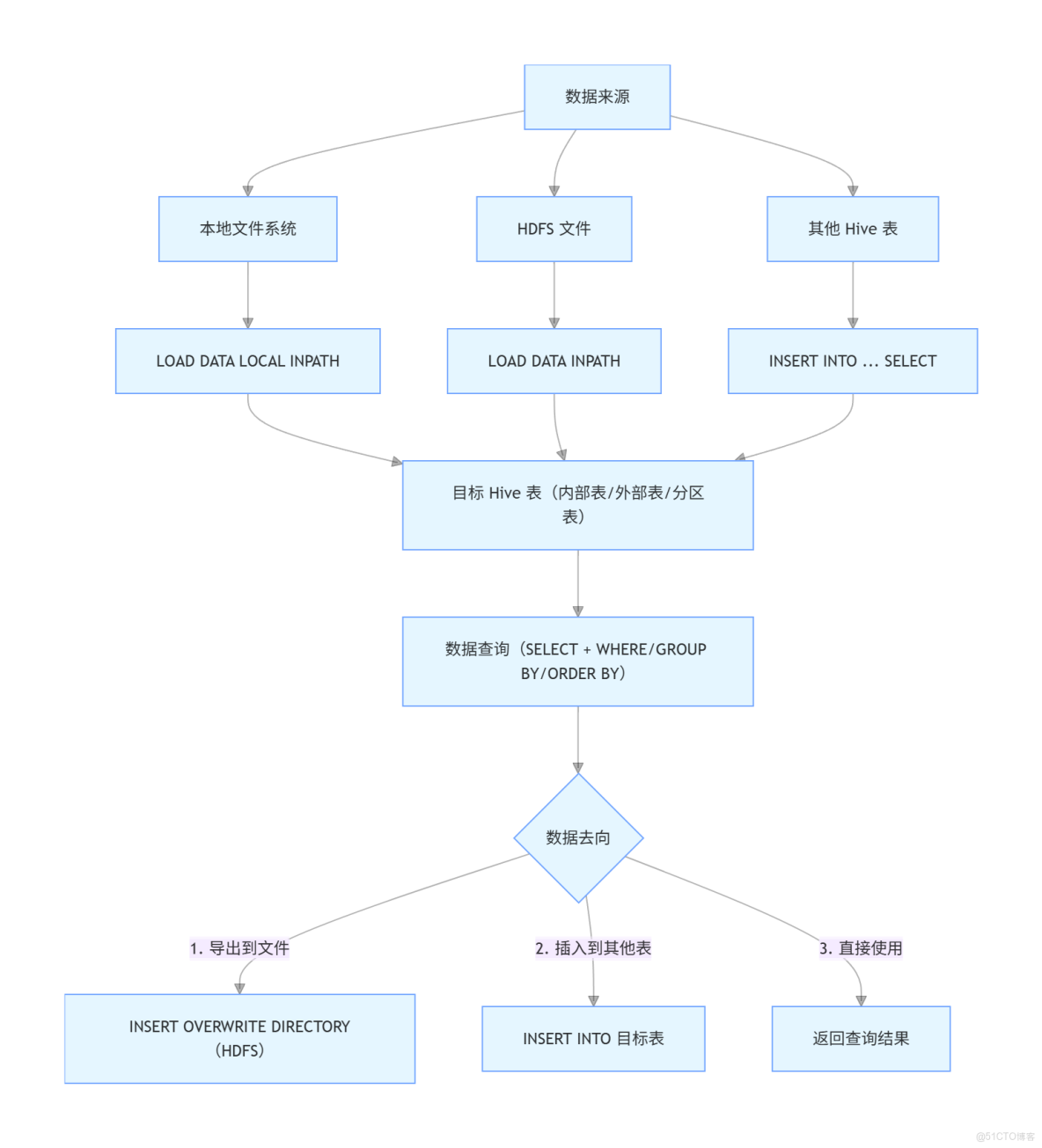
5. 加載數據
加載數據到表中的命令如下:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE table_name [PARTITION (partcol1=val1, partcol2=val2,...)];LOCAL:從本地文件系統加載數據。OVERWRITE:覆蓋表中已有的數據。PARTITION:指定分區信息。
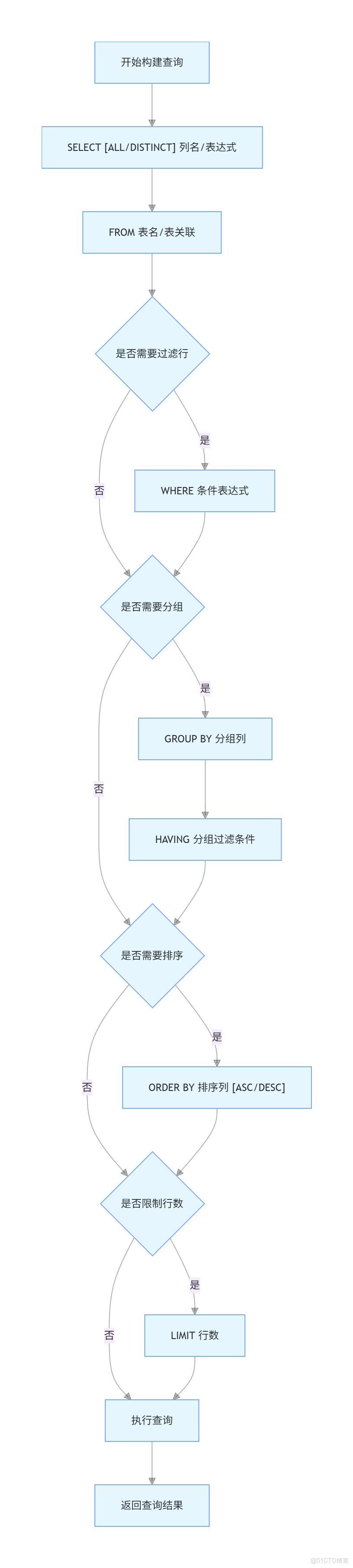
6. 查詢數據
查詢數據的基本語法如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE boolean_expression]
[GROUP BY col_list]
[HAVING boolean_expression]
[ORDER BY col_list [ASC | DESC]]
[LIMIT number];ALL(默認):返回所有匹配的行。DISTINCT:返回唯一不同的行。WHERE:指定查詢條件。GROUP BY:按指定列分組。HAVING:對分組後的結果進行過濾。ORDER BY:按指定列排序。LIMIT:限制返回的行數。
7. 插入數據
插入數據到表中的命令如下:
INSERT INTO TABLE table_name [PARTITION (partcol1=val1, partcol2=val2,...)]
VALUES (value1, value2, ...), (value1, value2, ...), ...;PARTITION:指定分區信息。
8. 修改表結構
修改表結構的命令如下:
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...);
ALTER TABLE table_name RENAME TO new_table_name;
ALTER TABLE table_name ADD PARTITION (partcol1=val1, partcol2=val2,...) LOCATION 'hdfs_path';
ALTER TABLE table_name DROP PARTITION (partcol1=val1, partcol2=val2,...);ADD COLUMNS:添加新列。RENAME TO:重命名錶。ADD PARTITION:添加分區。DROP PARTITION:刪除分區。
9. 查看錶信息
查看錶信息的命令如下:
DESCRIBE [EXTENDED|FORMATTED] table_name;
SHOW CREATE TABLE table_name;DESCRIBE:顯示錶的列信息。SHOW CREATE TABLE:顯示創建表的 SQL 語句。
10. 數據導出
將查詢結果導出到文件的命令如下:
INSERT OVERWRITE DIRECTORY 'hdfs_path'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT * FROM table_name;DIRECTORY:指定導出的目錄。ROW FORMAT DELIMITED:指定行格式。
Apache Hive 是一個基於 Hadoop 的數據倉庫工具,用於處理大規模數據集。下面是一些常見的 Hive 操作語句及其在實際場景中的應用示例。
1. 創建數據庫
在開始任何數據操作之前,通常需要創建一個數據庫來組織表和數據。
CREATE DATABASE IF NOT EXISTS sales;2. 使用數據庫
選擇要操作的數據庫。
USE sales;3. 創建表
創建一個表來存儲銷售數據。
CREATE TABLE IF NOT EXISTS sales_data (
sale_id INT,
product_id INT,
customer_id INT,
sale_date DATE,
quantity INT,
price DECIMAL(10, 2)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;4. 加載數據
將外部數據文件加載到表中。

LOAD DATA INPATH '/user/hadoop/sales_data.csv' INTO TABLE sales_data;5. 查詢數據
查詢表中的數據。
SELECT * FROM sales_data LIMIT 10;6. 過濾數據
根據條件過濾數據。
SELECT * FROM sales_data WHERE sale_date BETWEEN '2023-01-01' AND '2023-12-31';7. 分組和聚合
對數據進行分組並計算總銷售額。
SELECT product_id, SUM(quantity * price) AS total_sales
FROM sales_data
GROUP BY product_id
ORDER BY total_sales DESC;8. 連接表
假設有一個產品表 products,包含 product_id 和 product_name,我們可以將兩個表連接起來。
CREATE TABLE IF NOT EXISTS products (
product_id INT,
product_name STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 加載產品數據
LOAD DATA INPATH '/user/hadoop/products.csv' INTO TABLE products;
-- 連接表並查詢
SELECT p.product_name, s.total_sales
FROM (
SELECT product_id, SUM(quantity * price) AS total_sales
FROM sales_data
GROUP BY product_id
) s
JOIN products p ON s.product_id = p.product_id
ORDER BY s.total_sales DESC;9. 插入數據
向表中插入新數據。
INSERT INTO sales_data (sale_id, product_id, customer_id, sale_date, quantity, price)
VALUES (1001, 2001, 3001, '2023-01-01', 5, 100.00);10. 更新數據
更新表中的數據(Hive 不支持直接更新,但可以通過插入新數據來實現)。
INSERT OVERWRITE TABLE sales_data
SELECT sale_id, product_id, customer_id, sale_date,
CASE WHEN sale_id = 1001 THEN 10 ELSE quantity END AS quantity,
price
FROM sales_data;11. 刪除數據
刪除表中的數據(Hive 不支持直接刪除,但可以通過插入新數據來實現)。
INSERT OVERWRITE TABLE sales_data
SELECT sale_id, product_id, customer_id, sale_date, quantity, price
FROM sales_data
WHERE sale_id != 1001;12. 刪除表
刪除不再需要的表。
DROP TABLE IF EXISTS sales_data;
Apache Hive 是一個基於 Hadoop 的數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,並提供簡單的 SQL 查詢功能,可以將 SQL 語句轉換為 MapReduce 任務進行運行。下面是一些常用的 Hive 操作語句的整理和解釋:
1. 創建數據庫
CREATE DATABASE db_name;- 説明:創建一個新的數據庫
db_name。
2. 使用數據庫
USE db_name;- 説明:選擇當前操作的數據庫為
db_name。
3. 創建表
3.1 創建內部表(Managed Table)
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
) STORED AS file_format;- 説明:創建一個內部表
table_name,並指定列名和數據類型,以及存儲格式(如TEXTFILE,ORC,PARQUET等)。 - 特點:Hive 管理數據的生命週期,刪除表時會刪除數據。
3.2 創建外部表(External Table)
CREATE EXTERNAL TABLE table_name (
column1 datatype,
column2 datatype,
...
) LOCATION 'hdfs_path';- 説明:創建一個外部表
table_name,並指定列名和數據類型,以及數據在 HDFS 上的位置。 - 特點:數據不由 Hive 管理,刪除表時不會刪除數據。
4. 加載數據
4.1 從本地文件加載數據
LOAD DATA LOCAL INPATH 'local_path' INTO TABLE table_name;- 説明:從本地文件系統中加載數據到表
table_name中。
4.2 從 HDFS 加載數據
LOAD DATA INPATH 'hdfs_path' INTO TABLE table_name;- 説明:從 HDFS 中加載數據到表
table_name中。
5. 插入數據
5.1 插入單行數據
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);- 説明:向表
table_name中插入一行數據。
5.2 插入多行數據
INSERT INTO table_name (column1, column2, ...)
VALUES (value1_1, value1_2, ...),
(value2_1, value2_2, ...);- 説明:向表
table_name中插入多行數據。
5.3 從查詢結果插入數據
INSERT INTO table_name SELECT * FROM source_table WHERE condition;- 説明:將
source_table中滿足條件的數據插入到table_name中。
6. 查詢數據
SELECT column1, column2, ... FROM table_name WHERE condition;- 説明:從表
table_name中查詢滿足條件的數據。
7. 更新數據
Hive 不支持直接更新數據,但可以通過以下方式實現類似的效果:
INSERT OVERWRITE TABLE table_name
SELECT column1, column2, ...
FROM table_name
WHERE condition;- 説明:通過
INSERT OVERWRITE語句覆蓋表中的數據。
8. 刪除數據
Hive 不支持直接刪除數據,但可以通過以下方式實現類似的效果:
INSERT OVERWRITE TABLE table_name
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;- 説明:通過
INSERT OVERWRITE語句過濾掉不需要的數據。
9. 刪除表
DROP TABLE [IF EXISTS] table_name;- 説明:刪除表
table_name。如果表不存在且使用了IF EXISTS,則不會報錯。
10. 顯示錶信息
10.1 顯示所有表
SHOW TABLES;- 説明:顯示當前數據庫中的所有表。
10.2 顯示錶結構
DESCRIBE table_name;- 説明:顯示錶
table_name的結構信息。
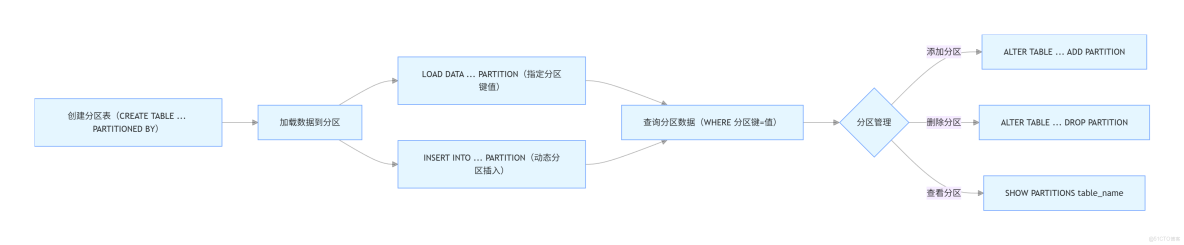
11. 分區表
11.1 創建分區表
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
)
PARTITIONED BY (partition_column datatype)
STORED AS file_format;- 説明:創建一個分區表
table_name,並指定分區列partition_column和存儲格式。
11.2 添加分區
ALTER TABLE table_name ADD PARTITION (partition_column='value');- 説明:為表
table_name添加一個新的分區。
11.3 刪除分區
ALTER TABLE table_name DROP PARTITION (partition_column='value');- 説明:刪除表
table_name中的一個分區。
12. 桶表
12.1 創建桶表
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
)
CLUSTERED BY (bucket_column) INTO num_buckets BUCKETS
STORED AS file_format;- 説明:創建一個桶表
table_name,並指定桶列bucket_column和桶的數量num_buckets。
13. 視圖
13.1 創建視圖
CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition;- 説明:創建一個視圖
view_name,視圖是基於查詢結果的虛擬表。
13.2 刪除視圖
DROP VIEW [IF EXISTS] view_name;- 説明:刪除視圖
view_name。
這些是 Hive 中常用的一些操作語句。希望這些內容對你有幫助!如果你有任何具體的問題或需要進一步的解釋,請隨時告訴我。