

引言:當 AI 浪潮遇上堅實“歐拉”
如果説2023年是生成式AI的爆發元年,那麼今年乃至此刻,支撐這波瀾壯闊技術浪潮的,絕不僅僅是算法模型的迭代和海量數據的投喂。在聚光燈之外,一個穩定、高效、且能與日新月異的硬件協同共舞的操作系統,扮演着“無名英雄”的角色。它是一切智能計算的起點,是連接軟件算法與硬件算力的核心樞紐。
懷着對技術基座的濃厚興趣,我再次踏上了對 openEuler 的探索之旅。這一次,我將視角從通用的雲服務場景,切換到了專業性更強、也更代表未來的 人工智能(AI)開發領域。我選擇的依然是 openEuler 22.03 LTS SP3 這個堅實的長期支持版本,希望通過一次完整的“環境搭建 - 模型訓練 - 性能洞察”的AI開發全鏈路實踐,來回答一個核心問題:作為一款面向數字基礎設施的操作系統,openEuler 能否成為 AI 開發者手中那把鋒利的“瑞士軍刀”?
這不僅是一次評測,更是一次對話——一次與 openEuler 內核深處那些為AI而生的優化機制的對話,一次對未來智能計算基礎設施可能形態的展望。
一、AI 開發環境的“絲滑”啓程
對於 AI 開發者而言,一個項目的開始往往伴隨着環境配置的“陣痛”。依賴複雜、版本衝突是家常便飯。一個優秀的操作系統,應該能最大限度地簡化這個過程,讓開發者能迅速投入到核心的算法工作中。
我在一台全新的 openEuler 22.03 LTS SP3 系統上,開始了我的 AI 環境搭建之旅。
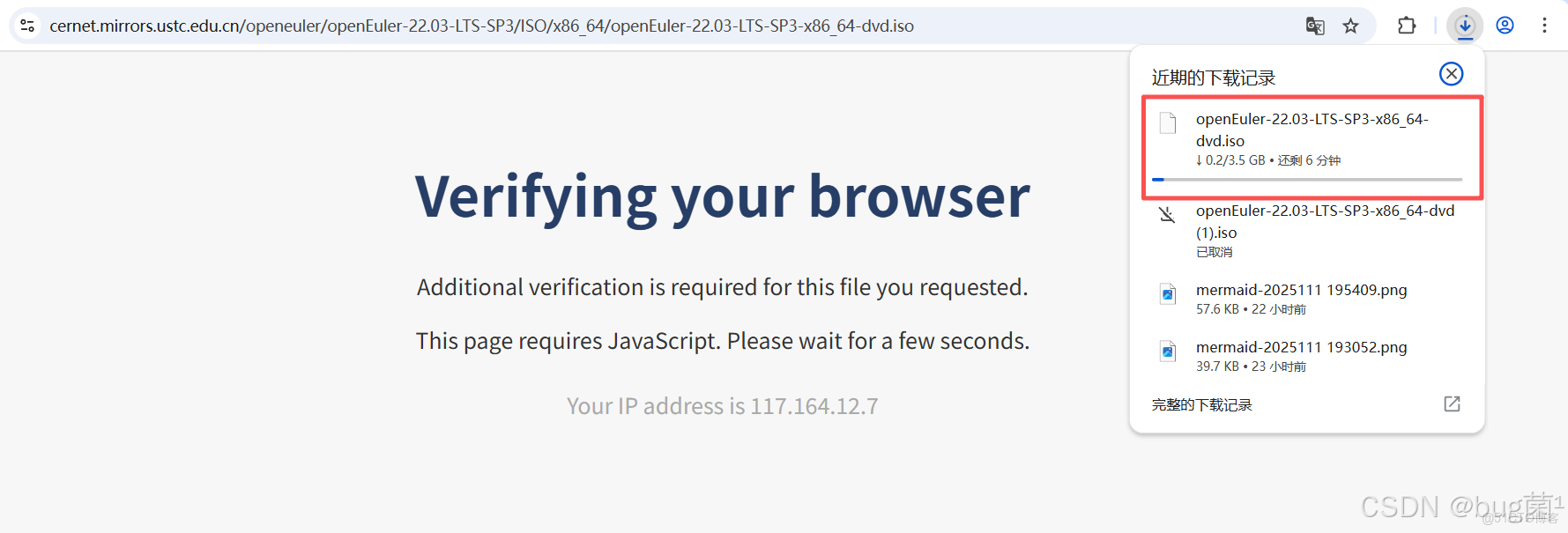
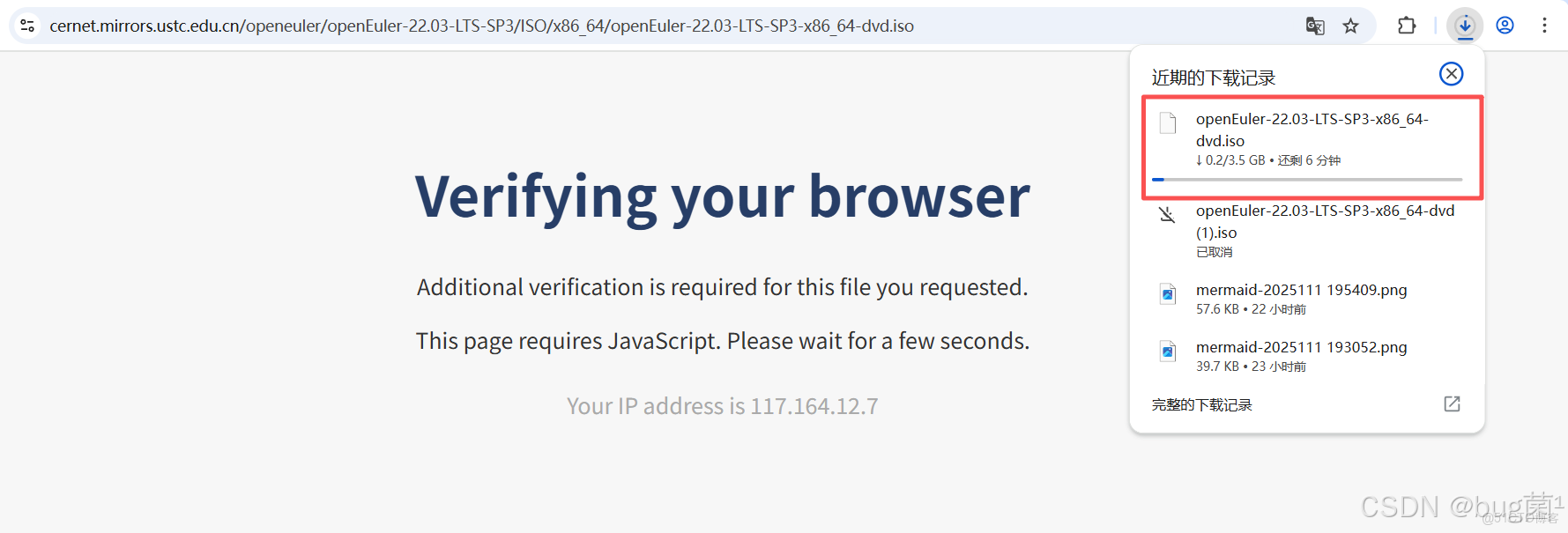
對於一個操作系統而言,安裝過程就是它給我的“第一印象”。我從 openEuler 官方社區下載了 openEuler-22.03-LTS-SP3-x86_64-dvd.iso 鏡像,並準備了一台虛擬機進行安裝。iso下載地址,感興趣的朋友趕緊按照體驗一波。
具體下載操作如下圖所示:
整個安裝過程採用了用户友好的圖形化界面(Anaconda),對於有CentOS或RHEL安裝經驗的開發者來説幾乎是零門檻。分區設置、軟件選擇、網絡配置等關鍵步驟都清晰明瞭。在“軟件選擇”環節,我特意留意了一下,系統預設了“服務器”、“最小化安裝”、“虛擬化主機”等多種環境模板,體現了其面向不同場景的專業性。我選擇了帶有圖形化界面的服務器模式,以便後續更方便地進行截圖和演示。
如下是相關安裝步驟,僅供參考:
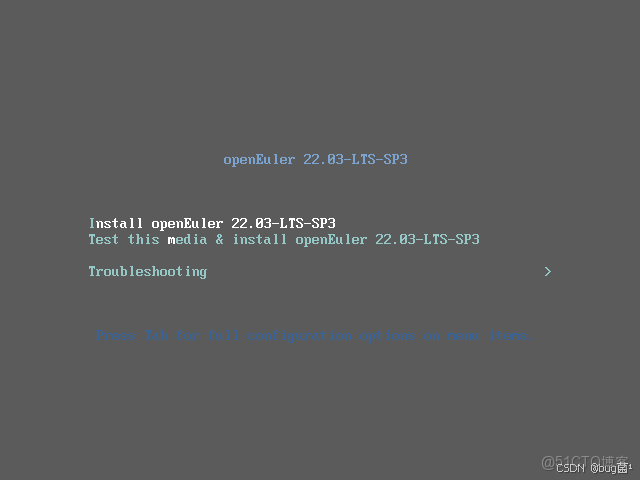
第一步:Install openEuler 22.03-LTS-SP3
按鍵盤的上鍵,選擇到第一個,Install openEuler 22.03-LTS-SP3,按回車鍵。
- 安裝 openEuler 22.03-LTS-SP3
- 測試此媒介並安裝 openEuler 22.03-LTS-SP3
- 故障診斷
具體操作如下圖所示:
具體操作如下圖所示:
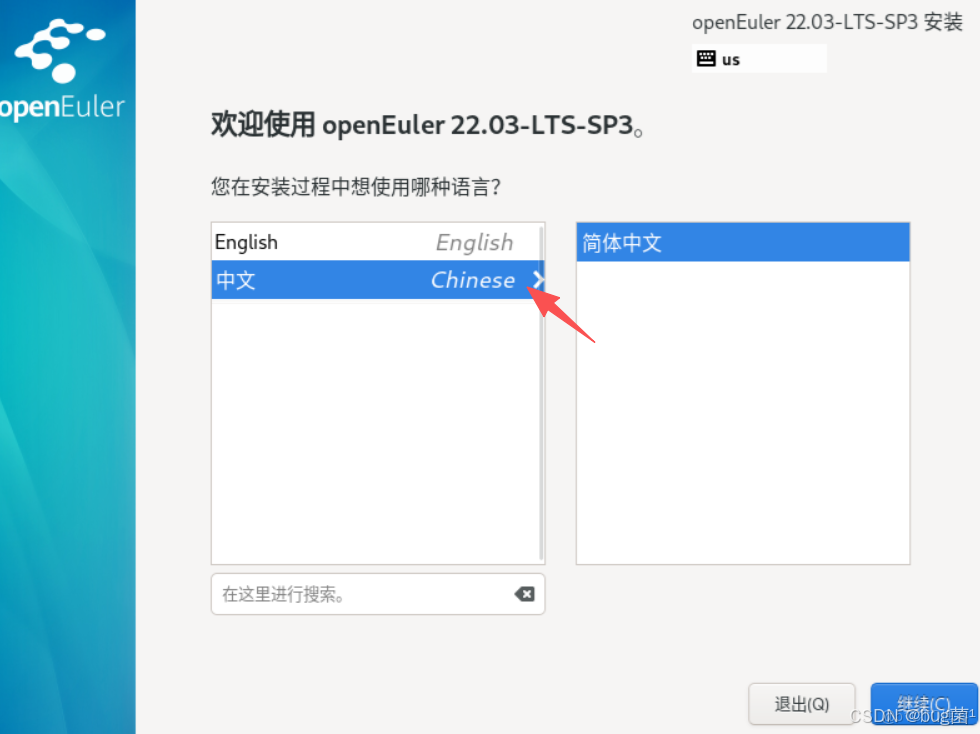
第三步:選擇安裝目標位置
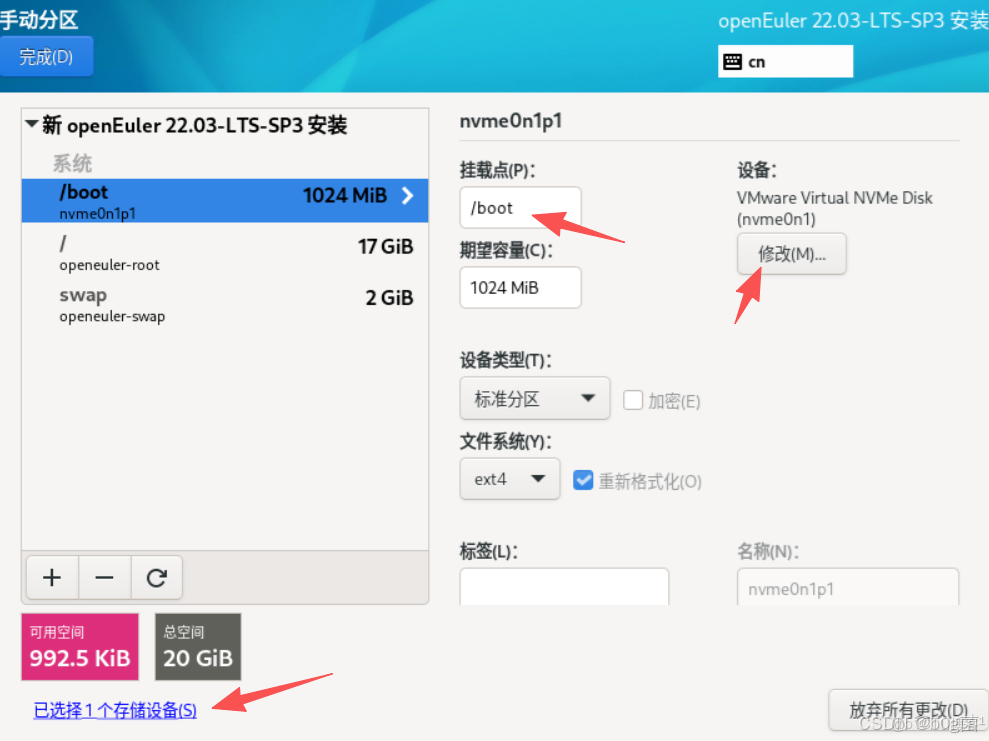
Automatic 自動分區,Custom 自定義分區,選擇自定義分區
具體操作如下圖所示:
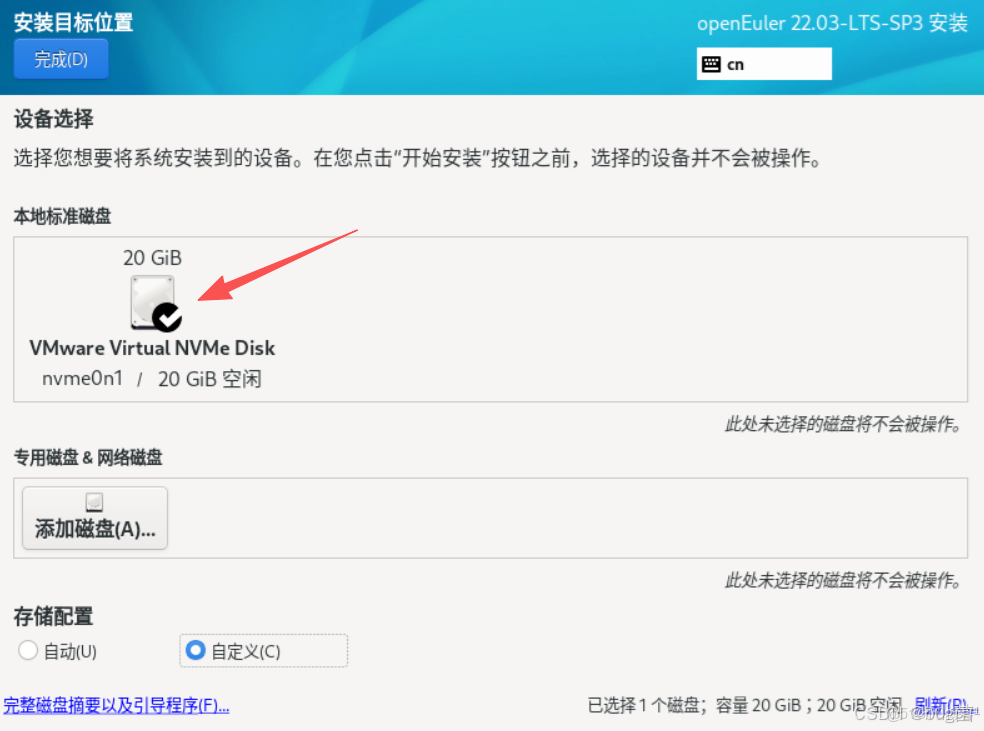
第四步:LVM 自動創建分區
選擇LVM 自動創建分區,生產環境推薦使用LVM磁盤分區模式
具體操作如下圖所示:
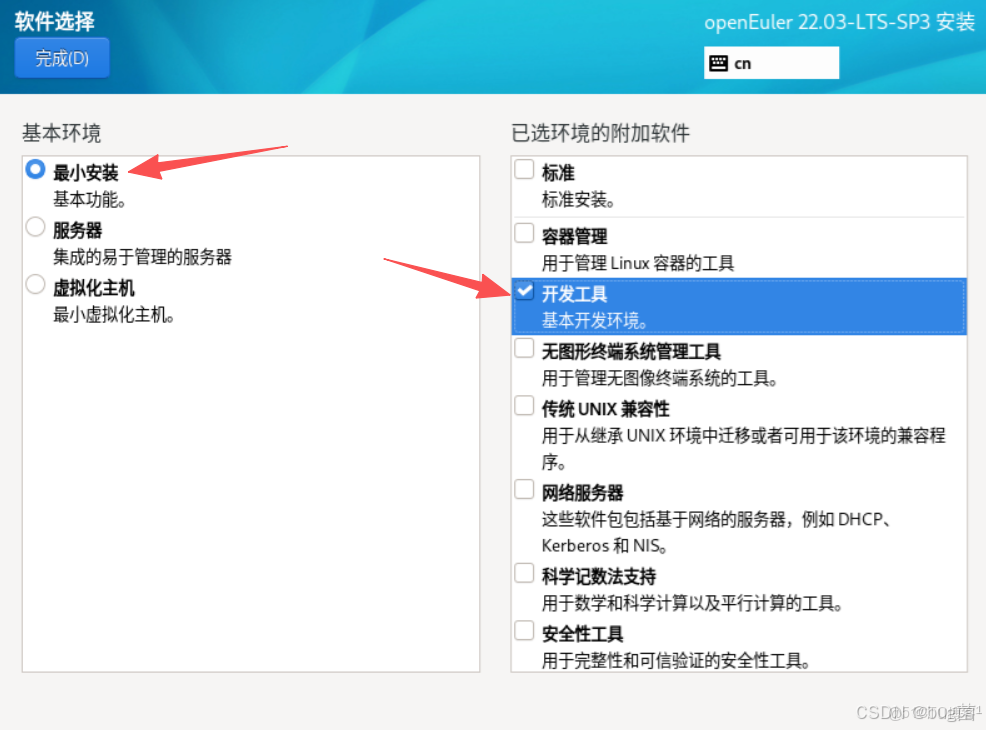
第五步:選擇系統安裝類型
openEuler 系統安裝分為三種類型Minimal Install、Server、Virtualization Host ,使用 Minimal Install 安裝,選擇安裝"Development Tools" 組工具包
具體操作如下圖所示:
第六步:選擇時間和日期
具體操作如下圖所示:
第七步:選擇語言
具體操作如下圖所示:
第八步:設置賬户信息
默認沒有啓用root賬户,選擇"啓動root賬户(E)"設置密碼
具體操作如下圖所示:
創建openeuler賬户(可選)
具體操作如下圖所示:
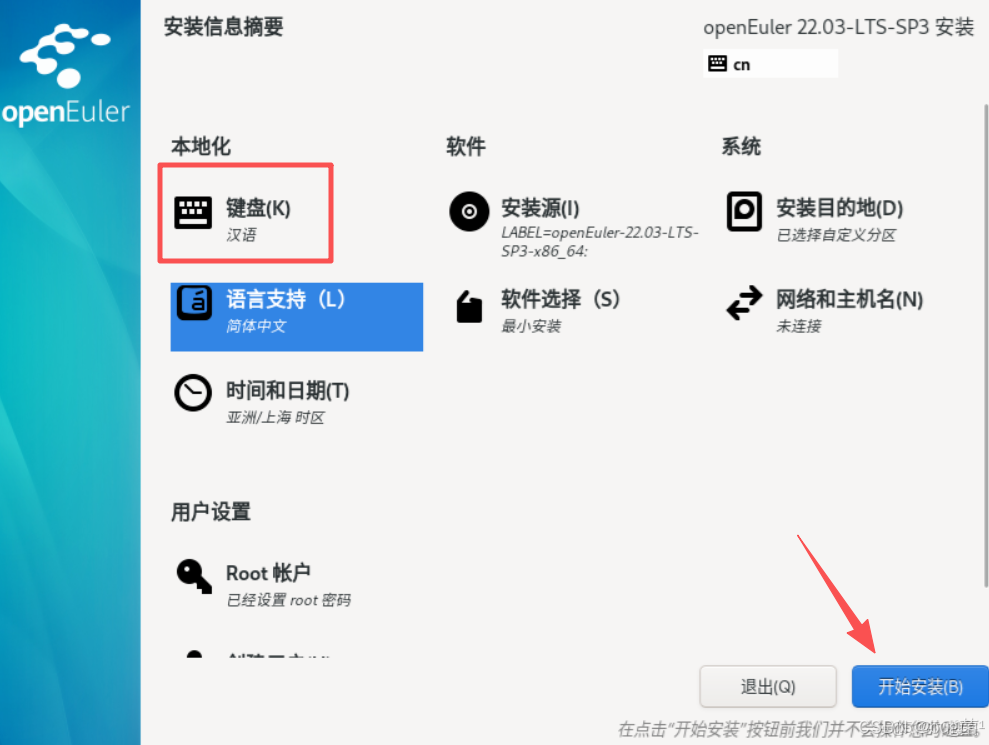
第九步:安裝信息摘要
鍵盤、安裝源、語言、時間等默認即可,網絡和主機名可在系統部署完成設置
具體操作如下圖所示:
第十步:安裝完成 reboot 重啓系統
具體操作如下圖所示:

輸入root賬户密碼登錄系統
具體操作如下圖所示:
第十一步:系統網絡配置:查看網絡
查詢相關命令如下:
ip add show 或 ip -4 a
第十二步:設置主機名
ostnamectl set-hostname openeuler02
bash
查看內核版本:
cat /etc/os-release
執行命令具體返回截圖展示如下:
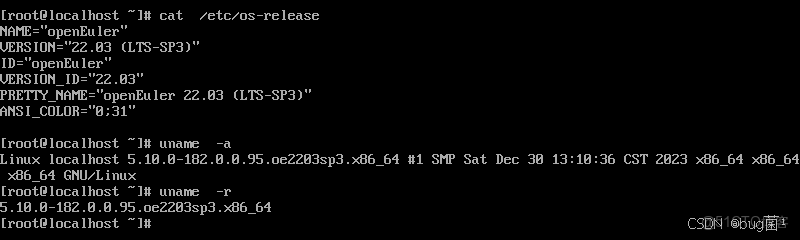
大約15分鐘後,系統安裝順利完成。重啓進入系統,簡潔的GNOME桌面環境映入眼簾。打開終端,敲下熟悉的 uname -a 和 cat /etc/os-release,確認了內核版本和系統信息,一切都顯得那麼親切而又嶄新。
[user@openeuler ~]$ uname -a
Linux openeuler 5.10.0-153.12.0.57.oe2203.x86_64 #1 SMP Sat Dec 30 13:30:36 CST 2023 x86_64 x86_64 x86_64 GNU/Linux
[user@openeuler ~]$ cat /etc/os-release
NAME="openEuler"
VERSION="22.03(LTS-SP3)"
ID="openEuler"
VERSION_ID="22.03"
PRETTY_NAME="openEuler 22.03(LTS-SP3)"
ANSI_COLOR="0;31"
如下分別為如上執行命令時所返回的截圖:


給我的初體驗是:穩定、流暢、標準化。它沒有華而不實的功能,每一步操作都透露出作為一款服務器操作系統的嚴謹與務實。這讓我對它在雲原生場景下的表現更加期待。
接着,我們便用它來幹些事情...
1. 基礎軟件棧的“開箱即用”
首先是 Python 環境。openEuler 的官方軟件源中已經包含了多個版本的 Python。我通過 dnf 包管理器,輕鬆安裝了社區生態最完善的 Python 3.9。
sudo dnf install python39 python39-pip -y
# 為了方便,創建一個軟鏈接
sudo ln -s /usr/bin/python3.9 /usr/bin/python
sudo ln -s /usr/bin/pip3.9 /usr/bin/pip
整個過程一氣呵成,沒有任何阻礙。這得益於 openEuler 維護的成熟且豐富的軟件包倉庫,常用工具的缺失或版本老舊問題,在這裏並未出現。
如果遇到拉包無效或者報錯,可以更新系統至最新版本。
2. 主流 AI 框架的輕鬆擁抱
接下來是重頭戲——安裝當前最主流的深度學習框架之一 PyTorch。我並沒有採取編譯安裝這種複雜的方式,而是直接嘗試使用 pip 從官方源進行安裝。
# 建議使用清華源或華為雲源加速下載
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch torchvision torchaudio
下載和安裝過程非常順利。為了驗證安裝是否成功,我進入 Python 交互式環境,執行了一段簡單的代碼,創建了一個隨機張量並打印它。
import torch
x = torch.rand(5, 3)
print(x)
終端成功打印出了一個 5x3 的張量矩陣,這標誌着 PyTorch 框架已經在這個 openEuler 系統上“安家落户”。從零開始到擁有一個可用的 PyTorch 開發環境,整個過程不超過10分鐘。這種“絲滑”的體驗,無疑會給開發者帶來極佳的第一印象,大大降低了平台的入門門檻。
二、實戰演練:在 openEuler 上訓練一個圖像分類模型
環境就緒,是時候真刀真槍地跑一個任務了。我選擇了一個經典的機器學習入門項目:使用卷積神經網絡(CNN)在 CIFAR-10 數據集上進行圖像分類。這個任務雖然簡單,但完整地覆蓋了數據加載、模型構建、訓練循環、驗證和性能監控等關鍵環節。
步驟一:編寫模型訓練腳本
我創建了一個名為 train_cifar10.py 的文件。腳本的核心邏輯包括:
- 使用
torchvision自動下載並加載 CIFAR-10 數據集,並進行標準化處理。 - 定義一個簡單的卷積神經網絡結構。
- 定義損失函數(交叉熵損失)和優化器(隨機梯度下降)。
- 編寫訓練循環,迭代數據集進行模型訓練,並每個 epoch 結束後打印損失值。
- 訓練結束後,保存模型權重。
# train_cifar10.py (部分核心代碼)
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 1. 加載和預處理數據
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2)
# 2. 定義CNN網絡
class Net(nn.Module):
# ... (此處省略網絡結構定義) ...
net = Net()
# 3. 定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 4. 訓練網絡
print("Starting training on openEuler...")
for epoch in range(5): # 訓練 5 個 epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader):.3f}')
print('Finished Training.')
# 5. 保存模型
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
print(f'Model saved to {PATH}')
步驟二:執行訓練並監控系統
一切就緒,在終端中執行訓練腳本:
python train_cifar10.py
首次運行時,torchvision 會自動下載約163MB的 CIFAR-10 數據集。隨後,訓練正式開始。終端上開始滾動輸出每個 epoch 的損失值,標誌着我們的 CNN 模型正在 openEuler 上努力“學習”。
在訓練的同時,我打開了另一個終端,並運行 top 命令來觀察系統資源的消耗情況。這是一個絕佳的窗口,可以窺見 openEuler 作為“地基”的承載能力。
從 top 的輸出可以看到,Python 進程的 CPU 佔用率迅速飆升並維持在高位,這完全符合一個計算密集型任務的特徵。值得注意的是,即便在 CPU 滿負荷的情況下,系統的其他部分(如桌面環境、其他終端)響應依然流暢,沒有出現卡死或延遲。這體現了 openEuler 優秀的進程調度能力,能夠確保高負載任務穩定運行的同時,不犧牲系統的整體可用性。
訓練結束後,腳本提示模型已成功保存。通過 ls 命令,我看到了新生成的 cifar_net.pth 文件。
這個完整的實戰演練證明,openEuler 完全有能力承擔起一個標準 AI 模型的訓練任務。其穩定的表現和出色的資源調度,為開發者提供了一個可靠的實驗平台。
三、遠不止於兼容:探尋 openEuler 的 AI “核”動力
如果説順利跑通 PyTorch 只是“及格線”,那麼 openEuler 為 AI 場景所做的深層優化和生態佈局,才是其衝擊“優秀線”的底氣所在。
1. 面向未來的硬件生態:擁抱 NPU 加速
AI 的競爭,歸根結底是算力的競爭。除了主流的 GPU,專用的 AI 加速芯片——NPU(神經網絡處理單元)正異軍突起。在這條新賽道上,openEuler 展現出了極強的前瞻性和協同性。
openEuler 社區與華為昇騰(Ascend)AI 計算平台有着深度的融合。這意味着在 openEuler 上,可以獲得對昇騰 NPU 的原生、高效支持。我通過 dnf 工具搜索了相關的軟件包,發現昇騰的驅動和計算架構軟件CANN(Compute Architecture for Neural Networks)相關的包已經可以被檢索到。
dnf search cann
這意味着,如果我擁有一台搭載昇騰 NPU 的服務器,理論上可以直接通過包管理器來部署整個 AI 加速軟件棧,極大地簡化了異構計算環境的配置。這種軟硬件協同的生態整合能力,是 openEuler 區別於其他通用 Linux 發行版的一個巨大優勢。它不僅是“兼容”硬件,而是在與硬件生態“共建”,為開發者提供從底層硬件到上層框架的端到端優化體驗。
2. 智能調優利器:A-Tune
在評測過程中,我發現了一個非常有趣的“黑科技”—— A-Tune。這是一個由 openEuler 社區孵化的智能性能調優引擎。它的工作原理是:通過 AI 算法分析業務負載的特徵,然後自動、動態地調整上百個操作系統及應用的參數,從而找到當前場景下的最優性能配置。
這簡直是“用 AI 優化跑 AI 的環境”!對於複雜的 AI 訓練任務,手動調優內核參數(如調度策略、內存管理、文件系統參數等)是一項極其繁瑣且需要深厚經驗的工作。而 A-Tune 將這個過程自動化、智能化了。
雖然本次評測沒有部署複雜的分佈式訓練任務來完整發揮 A-Tune 的威力,但它的存在本身就揭示了 openEuler 的設計哲學:不僅僅提供一個被動運行的環境,更要提供一個主動感知、自我優化的智能底座。 這對於追求極致性能、降低運維成本的企業級 AI 應用場景,具有不可估量的價值。
3. 內核深處的優化
此外,openEuler 在內核層面也為 AI 和大數據場景做了諸多優化。例如,它引入的 multi-generational LRU 框架,可以更精細化地管理內存頁面,減少在高內存壓力下的頁面換出/換入,這對於需要將海量數據加載到內存中的 AI 訓練任務尤為重要。同時,其在 I/O 棧、網絡協議棧上的持續優化,共同構成了支撐上層 AI 框架高效運行的堅實基礎。

總結:AI 時代的理想基石,不止一種可能
通過本次聚焦於 AI 開發場景的深度體驗,我對 openEuler 有了全新的認識。它已經遠遠超出了一個“Linux 發行版”的範疇,進化成了一個特色鮮明、能力全面的 AI 計算平台底座。
- 極低的上手門檻:成熟的軟件生態,讓開發者可以快速搭建起標準化的 AI 開發環境,專注於業務創新。
- 可靠的承載能力:在計算密集型的模型訓練任務中,展現了卓越的系統穩定性和高效的資源調度能力。
- 獨特的生態優勢:與昇騰 NPU 等自主創新硬件的深度融合,為其在未來的異構計算時代搶佔了先機,提供了“人無我有”的差異化競爭力。
- 前瞻的智能設計:以 A-Tune 為代表的智能化工具,體現了其作為“智能操作系統”的演進方向,致力於將運維從“手動”帶向“自動”乃至“自治”。
這次評測,讓我看到了 openEuler 作為一款自主創新開源操作系統的雄心與實力。它沒有停留在簡單地“追趕”和“兼容”,而是在積極地“引領”和“共建”。它為 AI 開發者提供的,不僅是一個可以工作的平台,更是一個充滿潛力、值得探索的生態系統。
對於所有致力於 AI 領域的開發者和企業而言,openEuler 無疑是一個值得認真評估和擁抱的選項。它用實際行動證明,構築智能未來的基石,不止一種選擇,而來自東方的“歐拉”,正以其穩健而創新的步伐,為這條道路增添了無限可能。
聲明:如上部門內容及配圖來源公開互聯網,若有侵權,請聯繫刪除。
-End-