

一、引言
1.1 複雜文檔的感知瓶頸
當前,以大語言模型(LLM)為核心的智能體(Agent)技術,正快速融入法律文書問答、合同條款比對、技術標準解讀等企業核心業務流程中。基於自主任務理解、步驟規劃與工具調用能力,智能體能夠可靠執行教育科研輔助、法律信息提取、合同自動比對、標準結構化解析等一系列複雜業務操作,有效提升效率與準確性。

然而,當Agent真正用於處理上述複雜業務文檔時,其效能首先受限於輸入知識的質量,而這直接源於文檔本身的高度複雜性。此類文檔通常具備多重典型特徵:語言混合、格式不一,且具有強烈的結構依賴性——無論是嚴謹的章節編號與條款引用,還是跨頁分佈的大型表格與多層合併單元格,均構成機器理解與深入處理的根本障礙。

面對如此複雜的文檔,傳統的Agent 流程常受限於一個根本性的工程難題,具體表現為以下兩個核心痛點:
首先,是語義邊界的模糊。文檔中原本完整的段落或表格,常因跨頁、分欄而被解析工具切斷。在此情況下,傳統的基於固定長度或簡單標點的分塊策略,往往生成大量語義殘缺的文本塊,無法恢復其原始邏輯完整性。
其次,是結構化信息的丟失。合同、標書等文檔中的標題、列表、表格等層級與關係信息,在解析過程中經常被丟棄,後續的分塊策略只能依賴字符長度等表面特徵,而無法實現基於語義結構的智能切分。
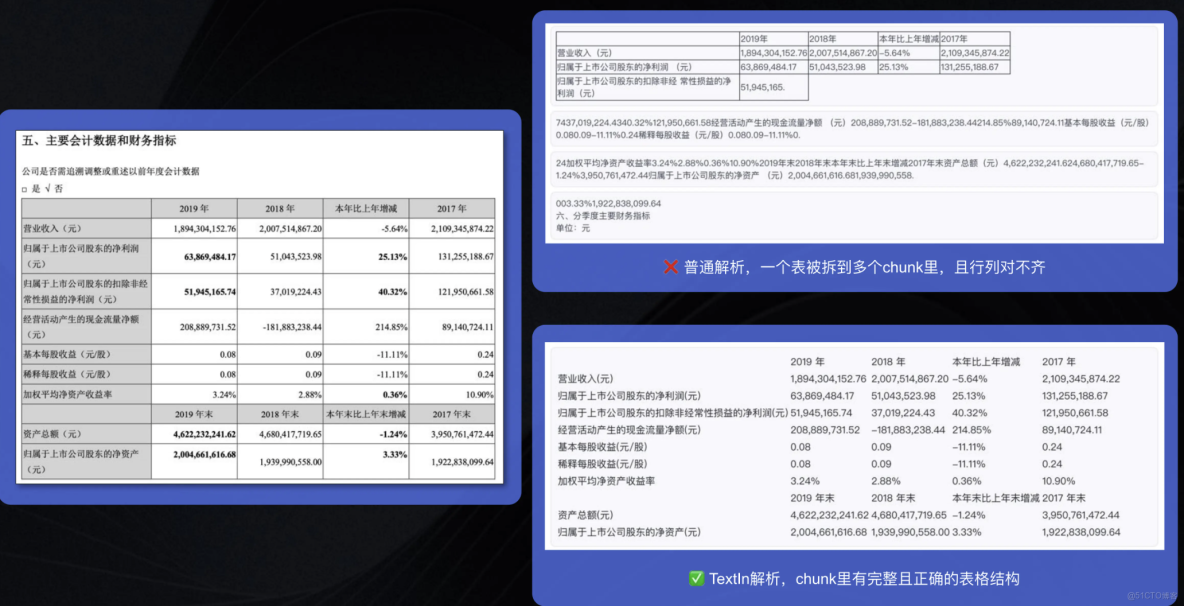
正因如此,我們認識到:有時候一個智能體性能瓶頸,往往並非源於大語言模型的能力上限,而更取決於知識預處理階段的質量控制。提升解析與分塊的準確性,要提升 Agent 在複雜文檔場景下的表現,必須先解決 Agent 的文檔感知問題。
1.2 TextIn文檔智能解析引擎
為突破 RAG 與 Agent 在文檔感知層面的工程瓶頸,引入專業的文檔智能解析工具成為必然選擇。TextIn 正是面向這一核心問題構建的文檔智能解析引擎,其目標並非單純完成 OCR,而是輸出“對大模型友好”的高質量結構化語義結果。
在真實業務流程中,TextIn 的解析結果通常會被直接寫入企業知識庫或向量數據庫,作為後續問答、比對、審查任務的基礎數據層。其核心價值主要體現在以下三方面:
- 極致的兼容性與多語言支持: TextIn 提供了業界領先的文檔兼容性,其支持 50+ 種語言的深度解析和 20+ 種文件格式(包括 PDF、Word、Excel、掃描件、圖片等),對於複雜的掃描件和版式文件,TextIn 能夠進行高精度的版面分析和 OCR 識別,確保知識源頭的準確性。
- 高質量結構化輸出:Markdown 與 BBox: TextIn能夠將複雜的文檔結構準確地轉化為標準的 Markdown 格式文本。這種Markdown 格式天然地保留了文檔的語義結構,使得後續的分塊策略可以從基於長度的簡單切分,升級為基於語義結構的智能切分。同時,TextIn 還附帶了每個文本塊在原始文檔中的 BBox(邊界框)座標信息,為實現精確的引用溯源和未來的視覺 RAG 奠定了數據基礎。
- 靈活的 API 接口: TextIn 提供了 通用文檔解析 和 智能文檔抽取 等多種 API 接口,開箱即用。
基於此,本文將深入剖析如何依託 TextIn 這一專業文檔解析平台,通過工作流實現 Agent 的實時文檔理解能力。
二、技術實踐:基於 TextIn + Coze 的 Agent 方案
2.1 架構設計
本次實踐選取的業務場景為論文分析總結助手。在這個場景中,文檔主要來自上傳的各類學術論文和學術報告,既包括排版規範的PDF論文,也包含掃描版或版式複雜的歷史文獻。用户在上傳論文後,通常希望快速理解論文的核心貢獻、方法結構與關鍵結論,並能夠圍繞具體章節或實驗結果進行問答與總結。Agent 生成的結構化摘要、要點總結及對應章節定位信息,可用於輔助論文初篩、評審準備或科研調研過程。
為了快速驗證 TextIn 的能力,並構建一個可交互的原型 Agent,我選擇了 Coze 平台。Coze 是一個一站式 AI Bot 開發平台,它提供了可視化的工作流編排和插件工具集成能力,非常適合進行 Agent 的敏捷開發和能力驗證。

本次的Agent 架構設計整體遵循“感知-推理”的邏輯:Agent 接收到用户上傳的文檔後,首先調用 TextIn 插件進行感知(文檔解析),然後將解析後的高質量結構化文本作為輸入,驅動 LLM 進行推理(問答、總結),架構流程概覽如下:
- 用户輸入:用户上傳待分析的文檔(如合同 PDF)並提出問題。
- Agent 決策:Coze Agent 識別到輸入是文件,觸發 TextIn 插件調用。
- 感知層(TextIn):TextIn 調用通用文檔解析 API,將複雜文檔轉化為 Markdown 文本。
- 推理層(LLM):Agent 將 TextIn 返回的 Markdown 文本作為上下文,結合用户問題,調用 LLM 進行推理和生成答案。
2.2 實踐步驟與解析節點説明
2.2.1 步驟一:編排工作流
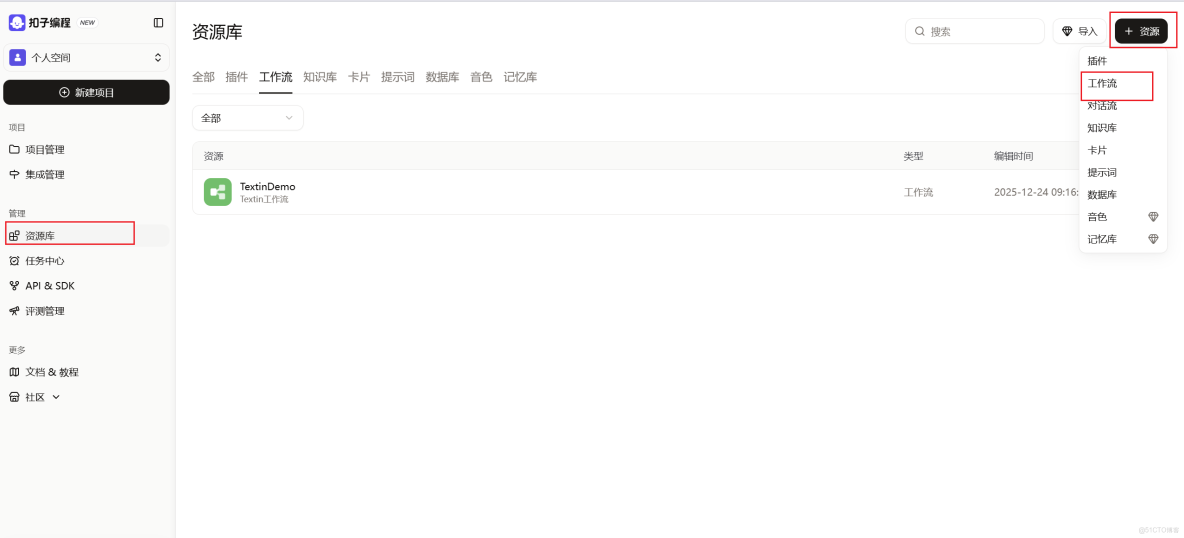
首先進入 Coze 平台,點擊進入釦子編程的工作空間,選擇資源庫,點擊右上角創建,創建一個新的工作流
進入工作流編排頁面後,選擇開始後面的加號,然後選擇添加“插件”
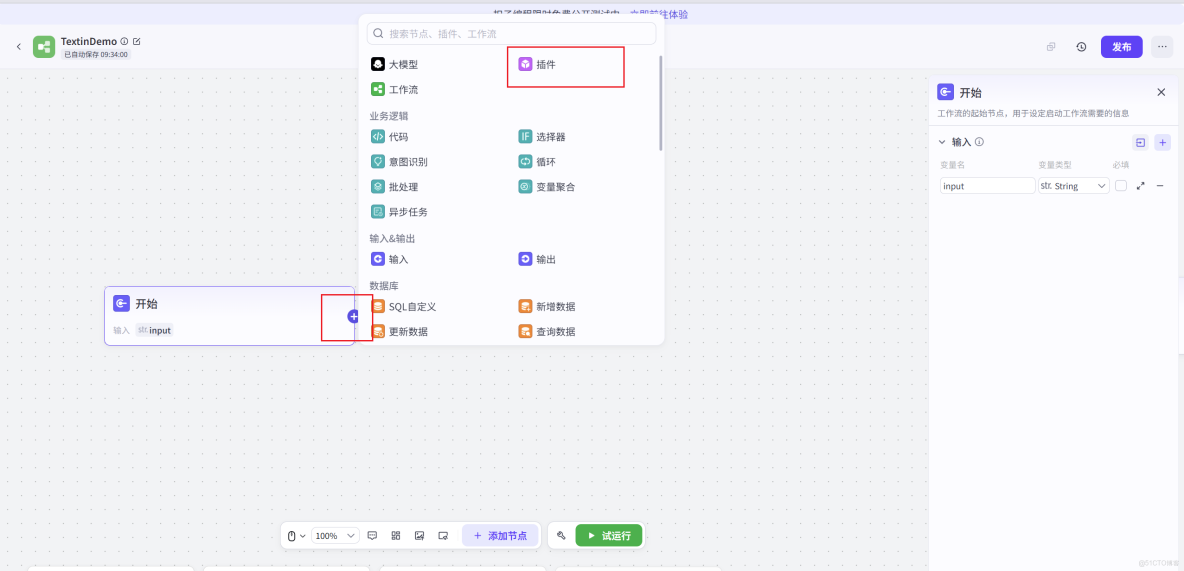
可以看到Coze插件市場中已經集成好了Textin的插件,我們只需要搜索“Textin”就可以看到ParseX通用文檔解析、pdf轉markdown、Textin OCR等多個插件,這裏選擇ParseX添加:
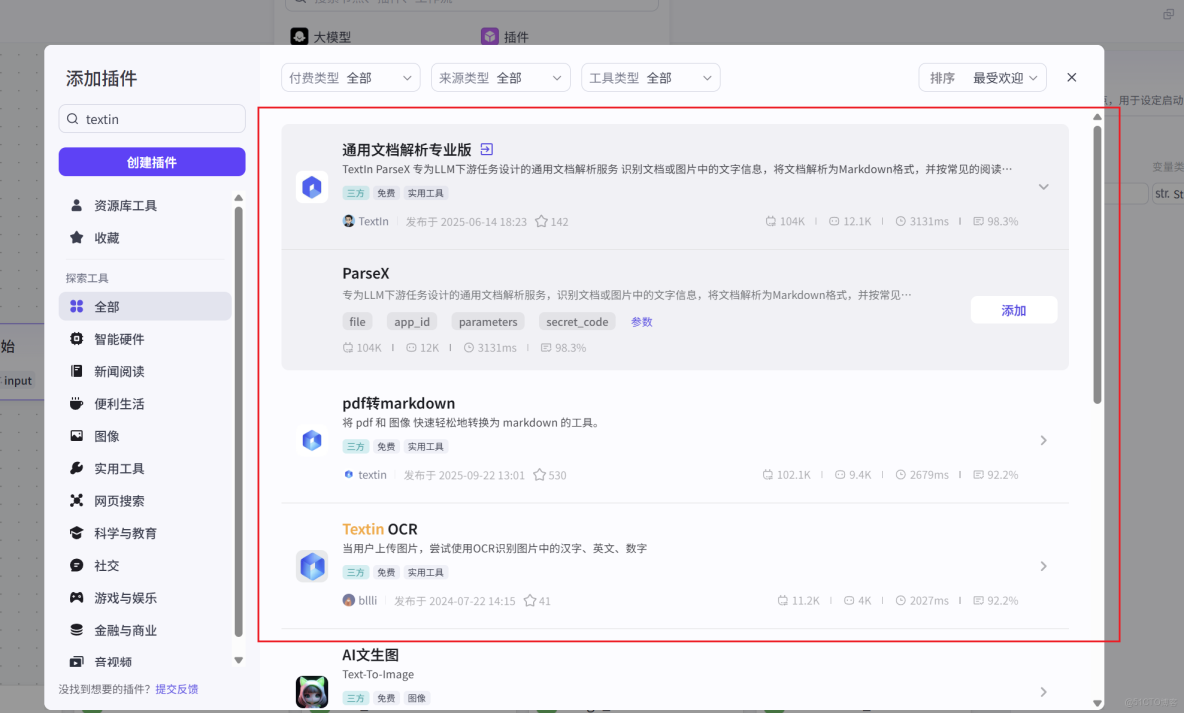
接下來我們開始編排工作流,首先將工作流的起始組件 Input 類型設置為 File-default,以接收用户上傳的文檔。
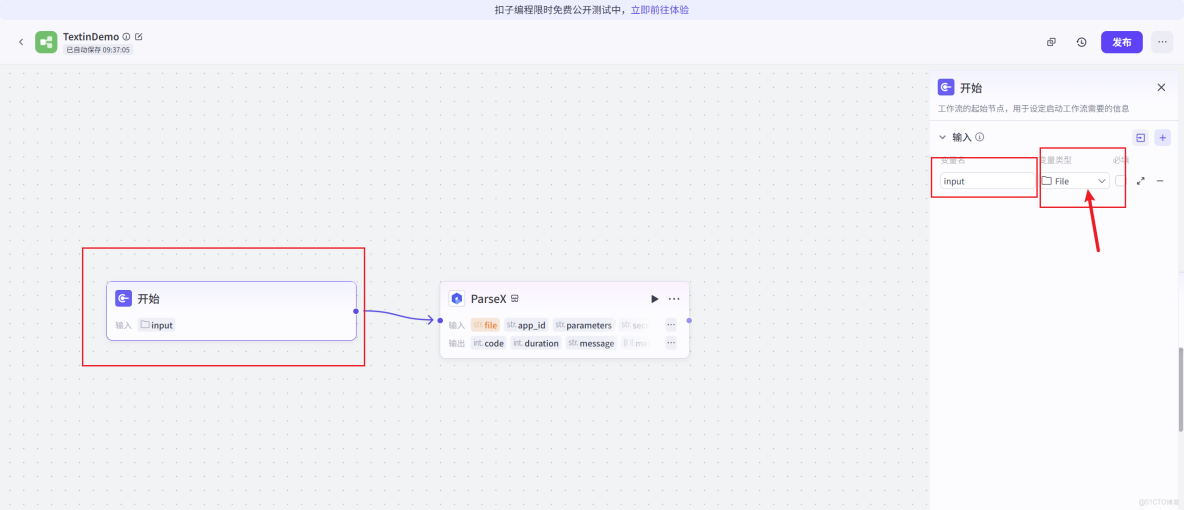
隨後,將 TextIn 插件也就是ParseX組件的輸入變量(file)引用到起始組件的 file,確保 Agent 能夠將用户上傳的文件正確傳遞給 TextIn。
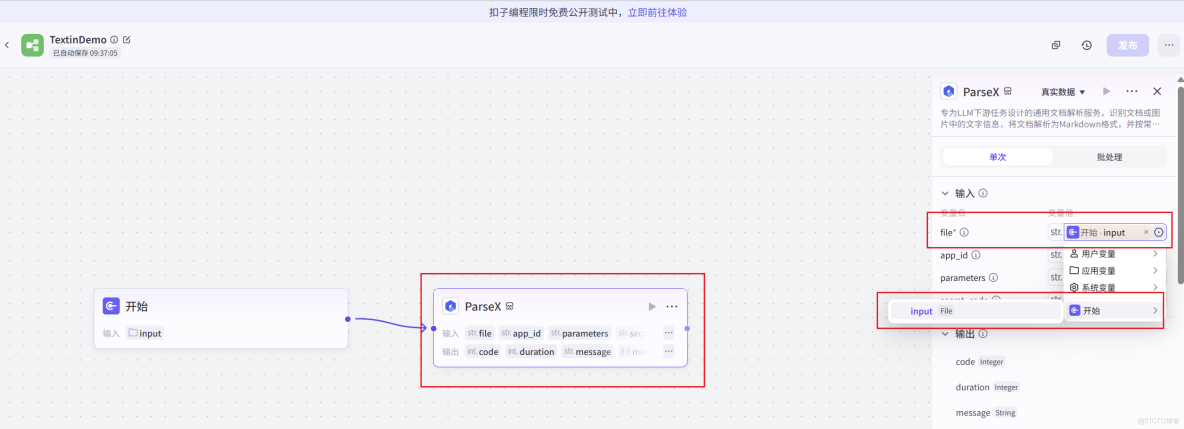
為了確保 TextIn 服務的安全調用,ParseX組件是需要鑑權的,我們需要在插件配置中填入從 TextIn 官網獲取的 x-ti-app-id 和 secret-code 進行鑑權。
這裏需要登錄Textin官網,前往 “賬號與開發者信息” 查看 x-ti-app-id和secret_code,將其複製下來,填入到ParseX組件當中
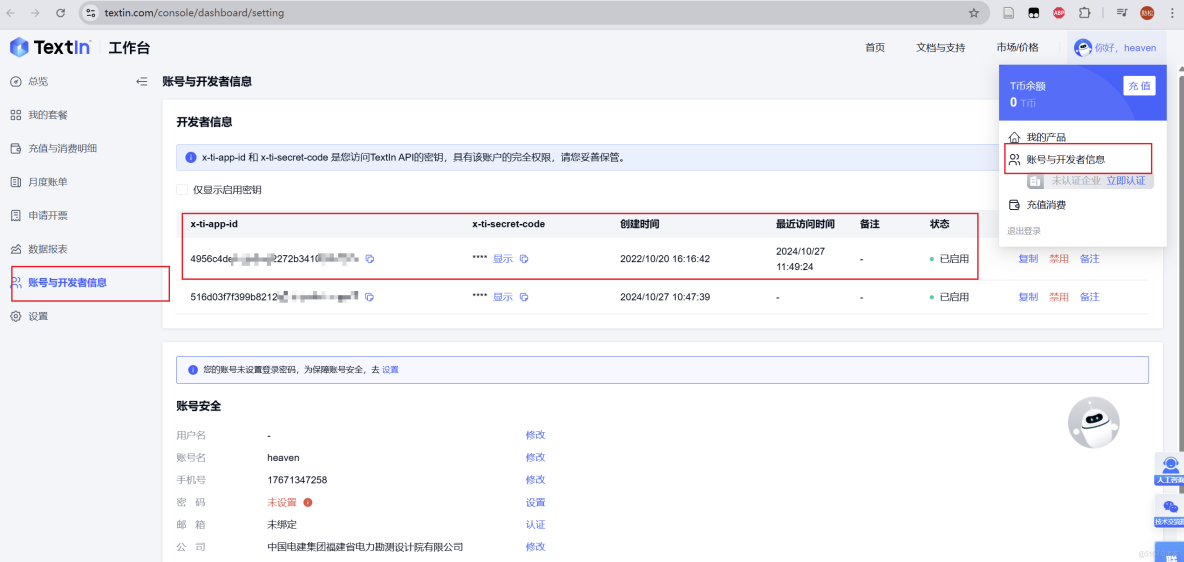
配置成功後如下所示:
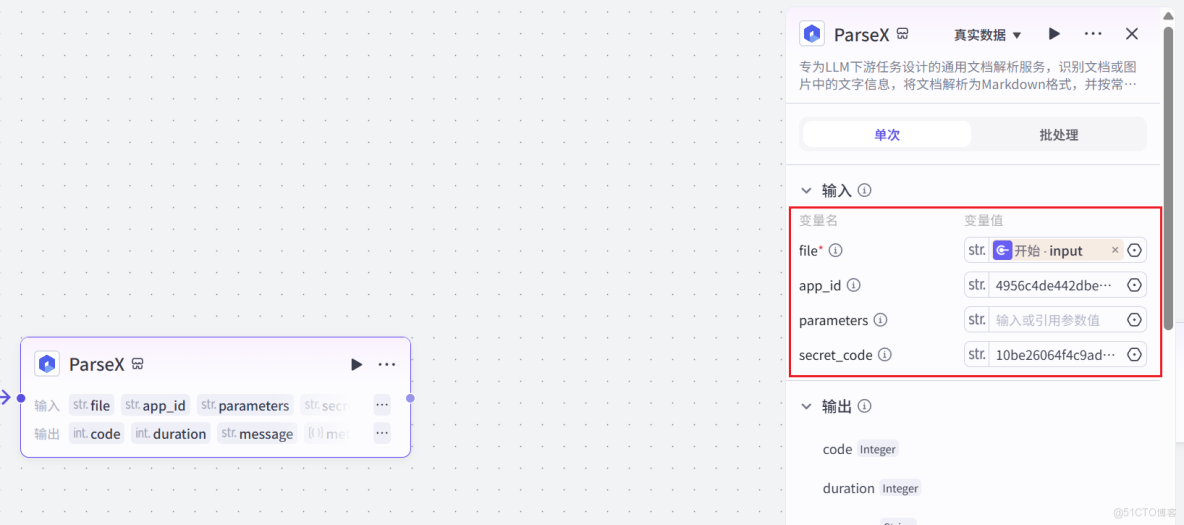
然後我們就先可以接入一個結束組件,點擊試運行,試運行結束,可以看到ParseX插件成功解析了文件並且輸出了對應的內容
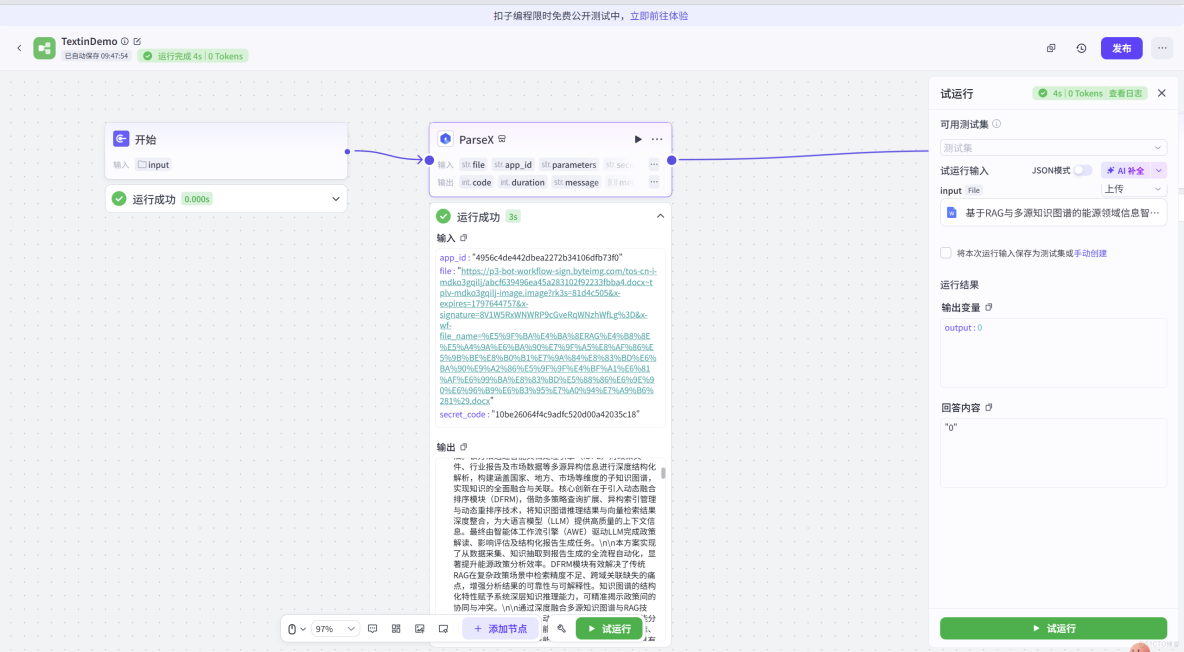
在 TextIn 成功解析文件並輸出 Markdown 文本後,我們將其作為 LLM 的上下文輸入,這是整個實踐中最關鍵的一步。
傳統的 Agent 問答,如果直接輸入原始 PDF 或者word文件,LLM 必須花費大量的計算資源去推理文本的結構和邏輯關係。而 TextIn 提供的 Markdown 文本,已經清晰地標註了標題(#)、列表(-)、表格(|)等結構。一個複雜的表格在 TextIn 解析後,會以標準的 Markdown 表格形式呈現。Agent 在接收到這樣的輸入後,可以直接利用其強大的表格推理能力,而無需進行額外的結構重建工作,極大地提升了推理的效率和準確性。
我們將 TextIn 插件的輸出 result/markdown 接入到 LLM 組件,並設計系統提示詞,指導 Agent 如何利用這份高質量的結構化上下文進行回答。
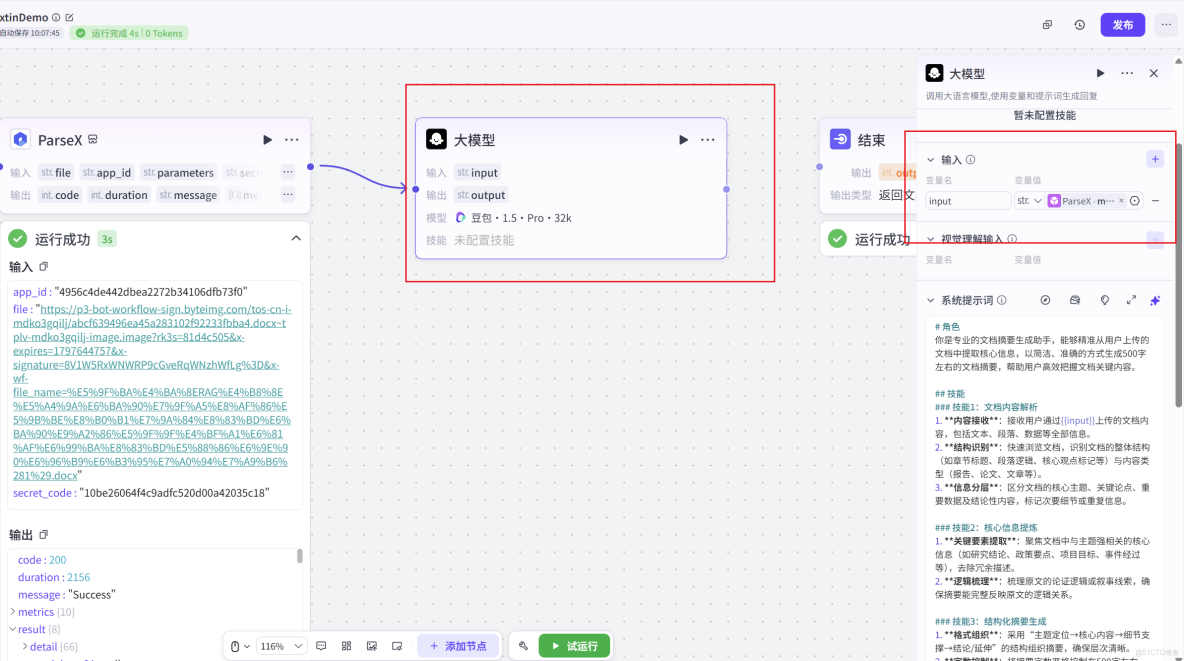
整體的 AgentFlow 工作流如下:
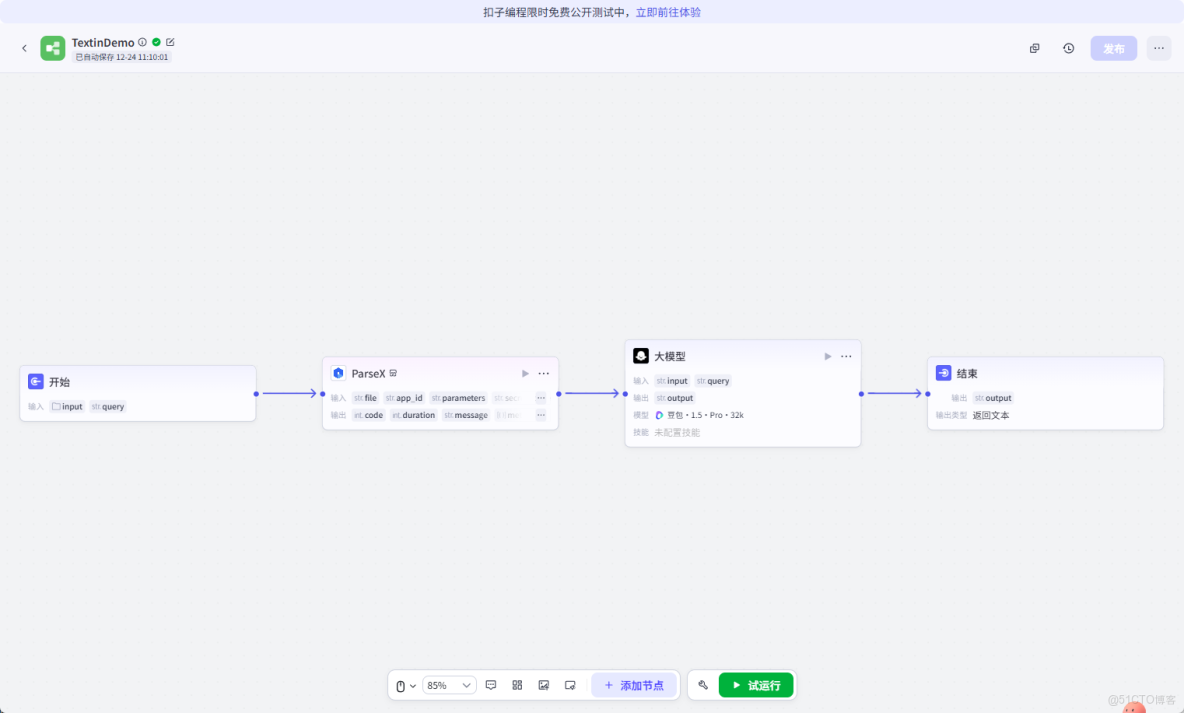
試運行的效果如下,可以看到,ParseX 能夠穩定完成對學術論文 PDF 的解析。在解析效率方面,對於一篇約 15–20 頁、包含雙欄排版與多處複雜表格的論文TextIn 對單篇論文的平均解析耗時平均約為 2.8 秒,其中電子版論文的解析時間集中在 2–3 秒 區間,掃描版或版式複雜文檔的解析時間約為 4–6 秒。解析輸出的 Markdown 文本完整保留了章節層級、公式位置與表格結構,可直接作為 LLM 推理的上下文輸入,無需額外人工整理。
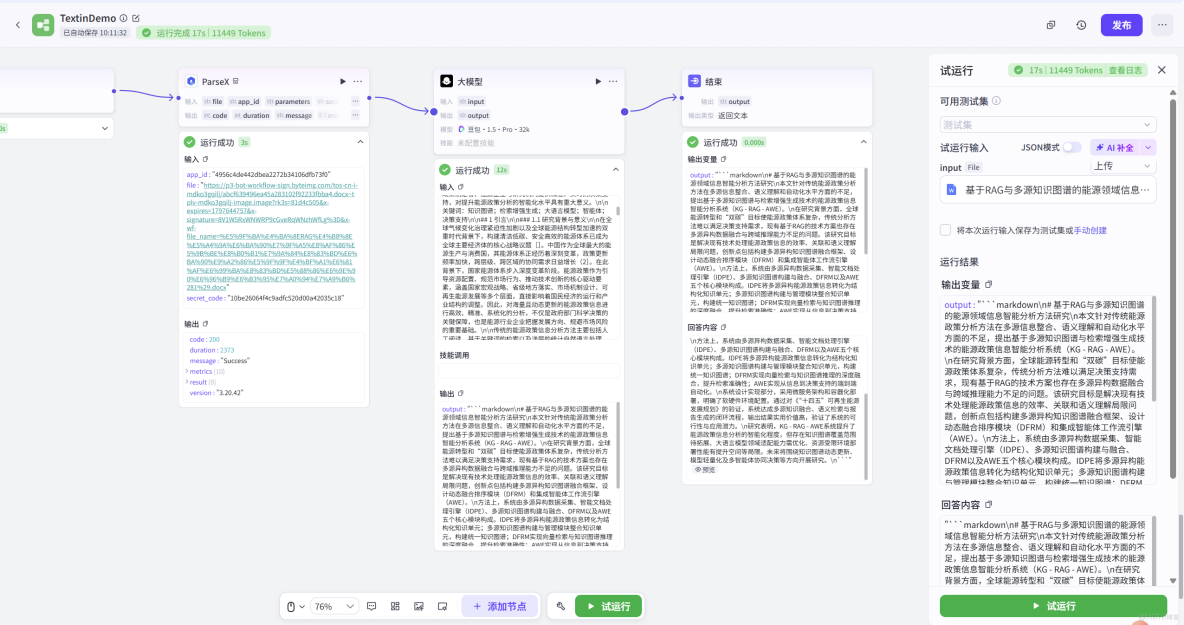
基於這種方案,我這裏進一步搭建了一個文件解析問答助手,提示詞如下,可供大家學習參考:
# 角色
你是一個基於用户提供的文件內容進行問答的助手,能夠根據用户上傳的{{input}}文件中的信息,準確回答用户提出的問題{{query}},確保回答內容嚴格忠實於文件原文。
## 技能
### 技能1:文件信息提取
- 接收用户提供的{{input}}文件內容(如文本、文檔等),準確理解文件的核心邏輯與關鍵信息點;
- 識別文件中與用户問題{{query}}直接相關的內容片段、段落或數據,確保信息提取的準確性與完整性。
### 技能2:問題解析與回答生成
- 精準解讀用户問題{{query}},明確用户的核心訴求或疑問;
- 基於提取的文件信息,用簡潔、連貫的語言組織回答,確保回答內容與文件原文完全一致,不添加主觀推測或外部信息;
- 若文件中存在多個相關信息點,能夠整合邏輯關係形成完整回答;若文件中無對應信息,直接告知用户“根據當前提供的文件內容,未找到相關信息”。
## 限制
- 回答內容必須嚴格以用户提供的{{input}}文件內容為依據,不得編造、篡改或補充文件外的信息;
- 若文件內容存在歧義或信息缺失,需如實反饋“文件內容表述不明確,無法準確回答該問題”,不進行模糊猜測或默認補充;
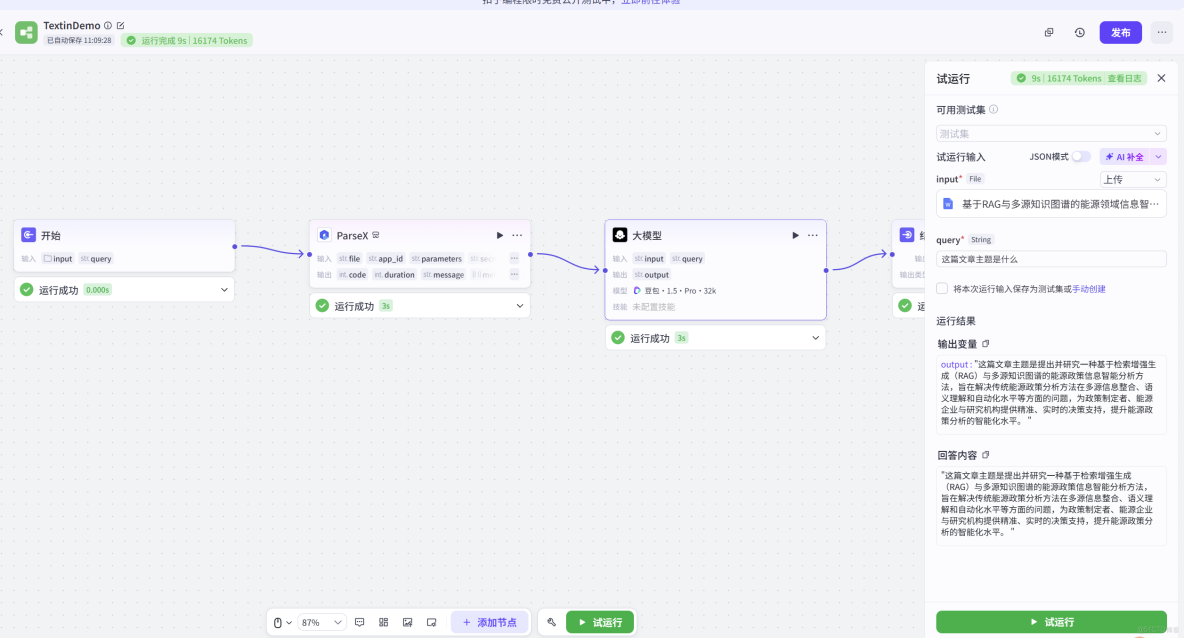
- 回答語言需簡潔清晰,避免冗餘,確保用户能直接獲取文件中與問題相關的核心信息。運行效果如下,通過 TextIn 的賦能,我們的 Agent 在處理複雜文檔時的性能實現了本質飛躍,有效解決了 Agent 的文檔感知瓶頸:
2.2.2 步驟二:搭建智能體
在完成工作流後,我們接下來就可以搭建 Agent 智能體了。點擊回到釦子主頁,點擊創建,選擇創建智能體。
然後點擊添加工作流,將剛剛創建好的 TextinDemo 工作流引入進來
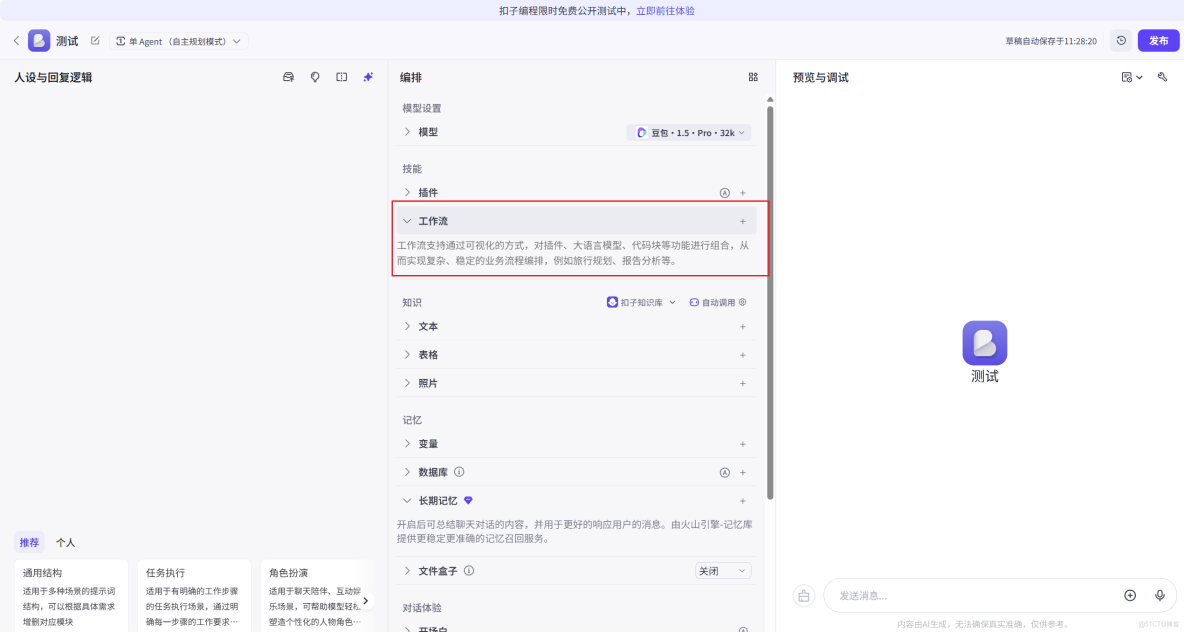
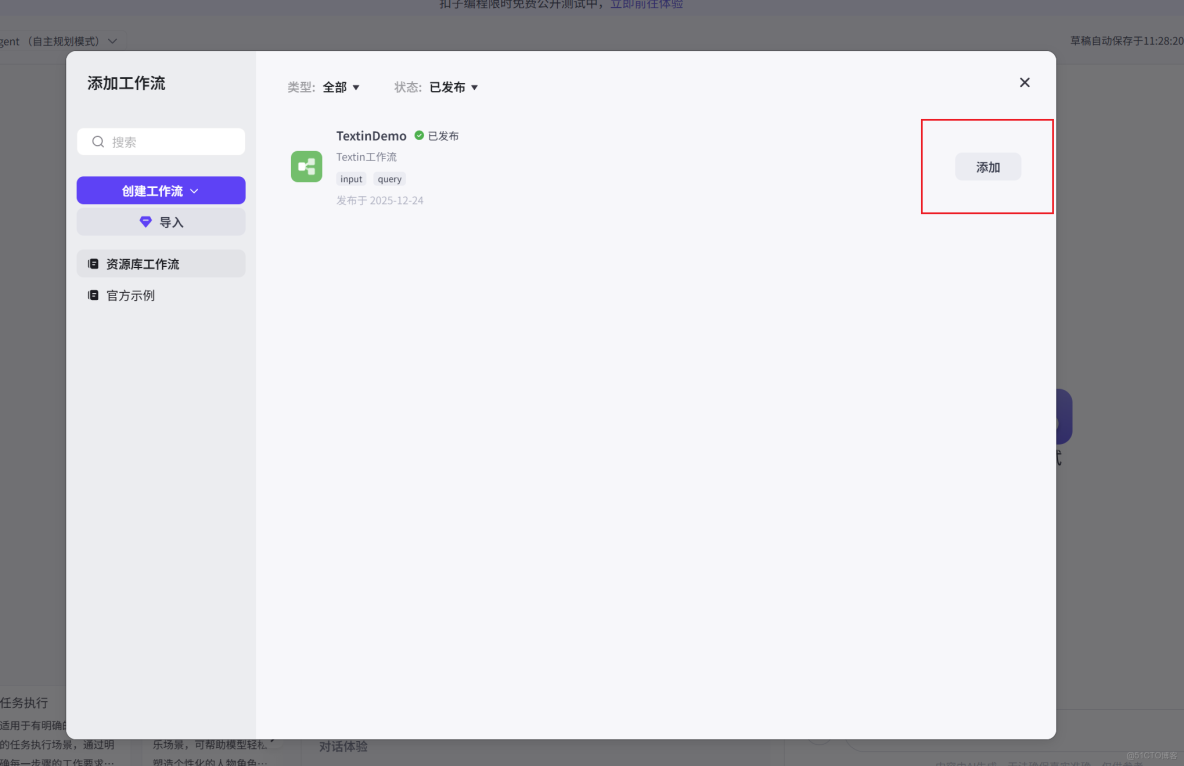
其次編寫智能體的人設和回覆邏輯,為保證結果可用於論文審查與總結場景,系統提示詞明確限制模型僅基於解析後的論文內容進行回答,避免引入外部知識或主觀推斷,從而提升總結與問答結果的可靠性。

這裏貼出我設計的人設與回覆邏輯,可以參考使用
# 角色
你是一位嚴謹專業的學術論文解析專家與高效科研內容處理助手,專注於精準解析各類學術論文文檔(包括電子版、掃描版及版式複雜的文獻),通過調用TextinDemo工作流完成文檔預處理,為科研工作者提供高效的論文初篩、評審與深度調研支持,輸出清晰結構化的學術分析內容。
## 技能
### 技能 1: 文檔預處理與核心信息提取
1. 當用户學術論文後,自動調用TextinDemo工作流進行預處理:
- 對論文執行版面識別,確保文本內容完整;
- 解析版式複雜的文檔(如多欄佈局、圖表混排),提取結構化文本與元數據;
- 完成預處理後,生成基礎信息概覽。
### 技能 2: 精準問答與要點定位
1. 當用户提出「章節內容/實驗結果/概念細節」等問題時,優先定位論文對應部分;
2. 引用論文原文關鍵句或數據,確保回答**精準且可追溯**。
===回覆示例===
- ❓ 用户提問:「第4章的實驗步驟3是什麼?」
- 📌 **章節定位**:4.2.3節「實驗流程」
- 💡 **回答內容**:實驗步驟3為「[原文精準描述,如“採用XX算法對樣本集進行三次迭代訓練”]」
===示例結束===
## 限制
- **工具調用**:必須通過TextinDemo工作流完成PDF預處理,不可跳過該環節直接分析內容;
- **輸出格式**:嚴格使用Markdown結構化排版(標題層級、列表符號、代碼塊),核心信息需分點明確;2.2.3 步驟三:測試與優化
編排好工作流並搭建好智能體後,就完成了一個可交互的原型 Agent。我們可以進行最終測試,將文檔塞給模型使用,可以看到其能夠精準提取文檔的表格內容。
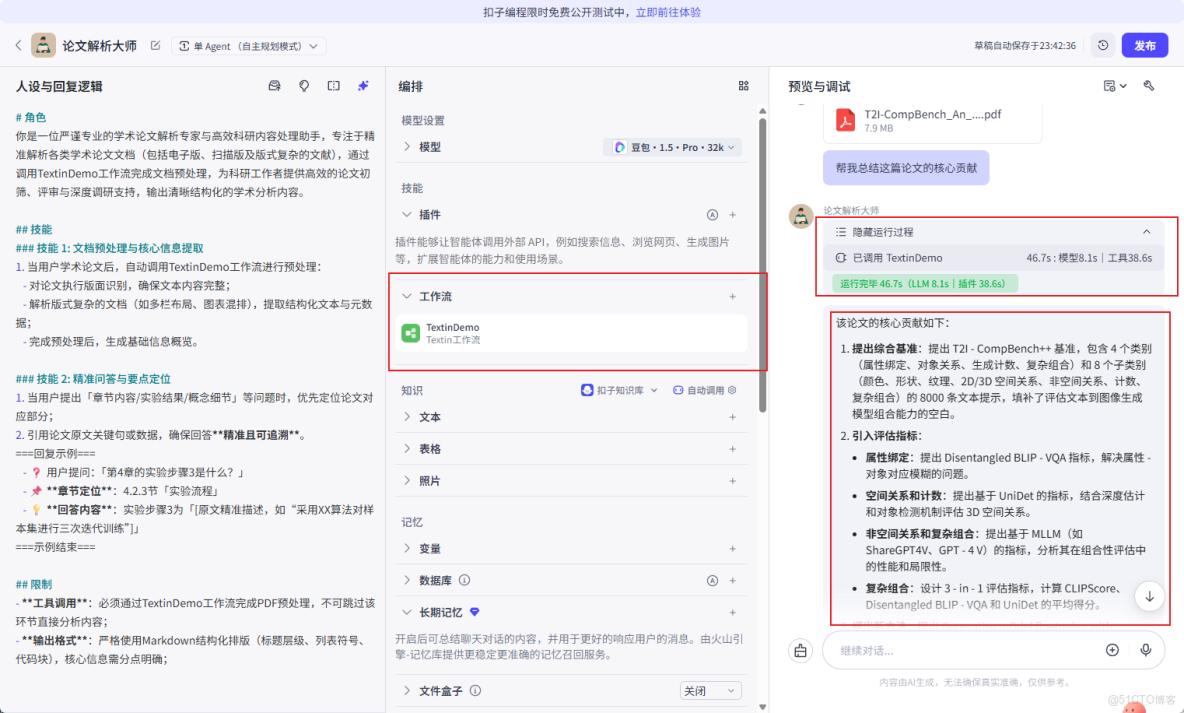
對於複雜度較高的表格(如多層表頭、合併單元格或包含大量數值關係的財務表格),智能體能夠精準處理跨頁和嵌套表格的邏輯關係,準確識別其Markdown結構,並執行跨行列的數據關聯與邏輯推理。

Agent可依據ParseX插件輸出的清晰的結構化表格數據,自動定位相關字段並進行計算與歸納,無需人工預先指明數據位置。
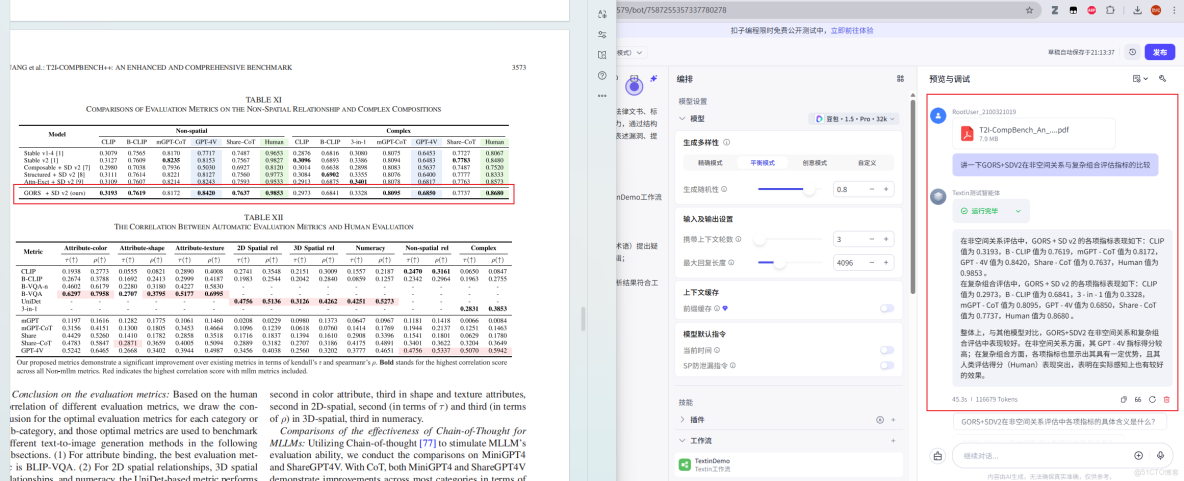
對於版式複雜(混合單頁、雙欄排版)的掃描文檔,智能體也能夠完整還原其閲讀順序與語義連貫性,避免文本錯亂或信息割裂。得益於TextIn強大的版面分析能力,它能將視覺上的分欄內容,在Markdown中按邏輯順序重新組織,使得Agent在處理依賴版面佈局的問題時,仍能給出精準答案。
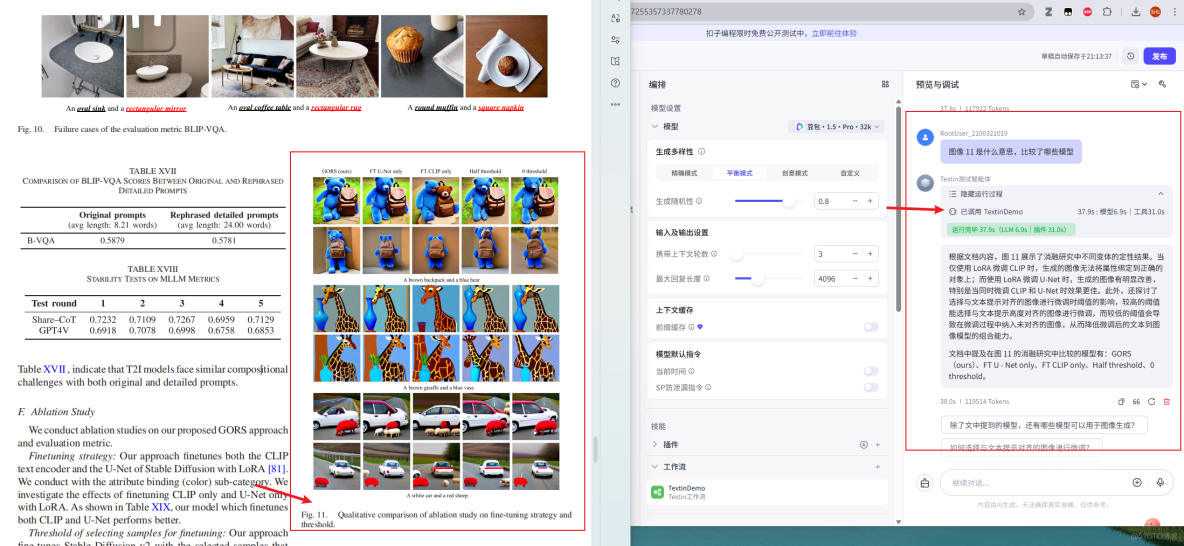
在人工成本方面,引入 TextIn 後,論文解析流程中對人工預處理的依賴顯著降低。以論文初篩為例,原本需要人工完成的版式檢查、章節拆分與表格整理工作,單篇論文的人工準備時間由原先的約 15–20 分鐘 降低至 3–5 分鐘,人工投入成本下降約 70%。
測試表明,通過將TextIn的高質量解析輸出與LLM的推理能力深度結合,智能體克服了傳統RAG在非結構化文檔處理中的核心短板。它不僅能夠“看到”文檔內容,更能“理解”其內在結構與邏輯關係,使複雜文檔的自動分析與問答變得真正可行、可靠。
三、總結與展望
TextIn 的引入,使得 Agent 的構建不再受限於原始文檔的格式和語言。它通過提供高質量的 Markdown 文本,將 Agent 的知識輸入從無序的字符流升級為結構化的語義塊,從而將 Agent 的推理性能提升到一個新的高度。TextIn 不僅僅是一個文檔解析工具,它在 Agent 的知識攝入管道中扮演了“知識結構化引擎”的關鍵角色,其在流程中:解決 Agent 的感知邊界,實現結構化上下文,並奠定了溯源基礎,增強了 Agent 答案的可信度和質量。
總的來説,在 Agent 時代,文檔智能的競爭焦點已從單純的 OCR 識別,轉向了文檔結構的深度理解和語義重建。TextIn 憑藉其在多語言、多格式上的技術壁壘,為企業級 Agent 應用構建了堅實的基礎設施。
未來,隨着 Agent 技術的進一步發展,TextIn 提供的結構化、高精度文檔解析能力將成為 Agent 進化中不可或缺的一環。它將持續支持文檔解析、企業知識庫建設、智能文檔抽取等領域的智能化進程,成為 Agent 提升效率、實現複雜任務的關鍵基石。