一、神經網絡的組成
人工神經網絡(Artificial Neural Networks,簡寫為ANNs)是一種模仿動物神經網絡行為特徵,進行分佈式並行信息處理的算法數學模型。
這種網絡依靠系統的複雜程度,通過調整內部大量節點之間相互連接的關係,從而達到處理信息的目的,並具有自學習和自適應的能力。神經網絡類型眾多,其中最為重要的是多層感知機。為了詳細地描述神經網絡,我們先從最簡單的神經網絡説起。
感知機
感知機是1957年,由Rosenblatt提出會,是神經網絡和支持向量機的基礎。
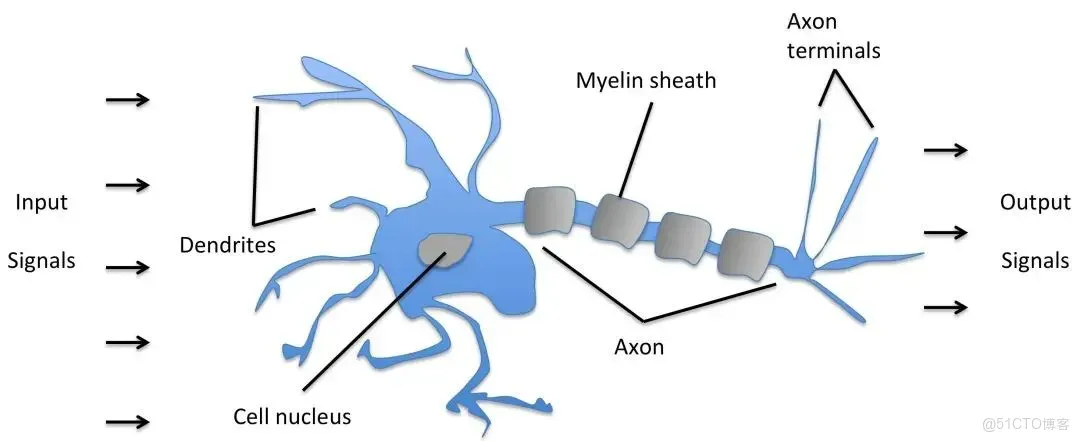
感知機是有生物學上的一個啓發,他的參照對象和理論依據可以參照下圖:(我們的大腦可以認為是一個神經網絡,是一個生物的神經網絡,在這個生物的神經網絡裏邊呢,他的最小單元我們可以認為是一個神經元,一個neuron,這些很多個神經元連接起來形成一個錯綜複雜的網絡,我們把它稱之為神經網絡。
當然我們現在所説的,在深度學習包括機器學習指的神經網絡Neural Networks實際上指的是人工神經網絡Artificial Neural Networks,簡寫為ANNs。我們只是簡化了。
我們人的神經網絡是由這樣一些神經元來構成的,那麼這個神經元他的一些工作機制呢就是通過這樣一個下面圖的結構,首先接收到一些信號,這些信號通過這些樹突(dendrite)組織,樹突組織接收到這些信號送到細胞裏邊的細胞核(nucleus),這些細胞核對接收到的這些信號,這些信號是以什麼形式存在的呢?
這些信號比如説眼睛接收到的光學啊,或者耳朵接收到的聲音信號,到樹突的時候會產生一些微弱的生物電,那麼就形成這樣的一些刺激,那麼在細胞核裏邊對這些收集到的接收到的刺激進行綜合的處理,當他的信號達到了一定的閾值之後,那麼他就會被激活,就會產生一個刺激的輸出。
那麼就會形成一個我們大腦接收到的進一步的信號,那麼他是通過軸突這樣的輸出計算的,這就是我們人腦的一個神經元進行感知的時候大致的一個工作原理。)
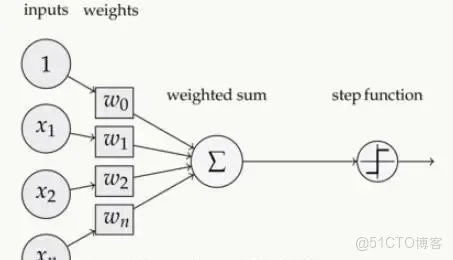
簡單的感知機如下圖所示:

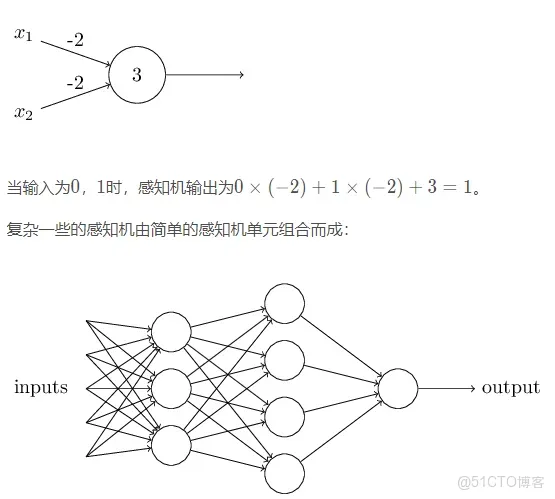
多層感知機

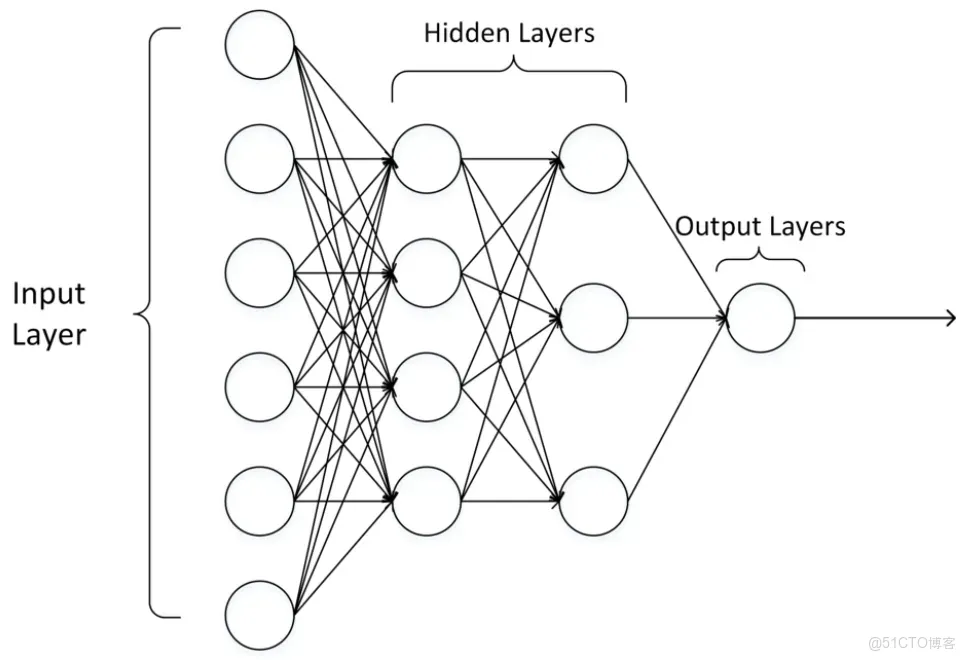
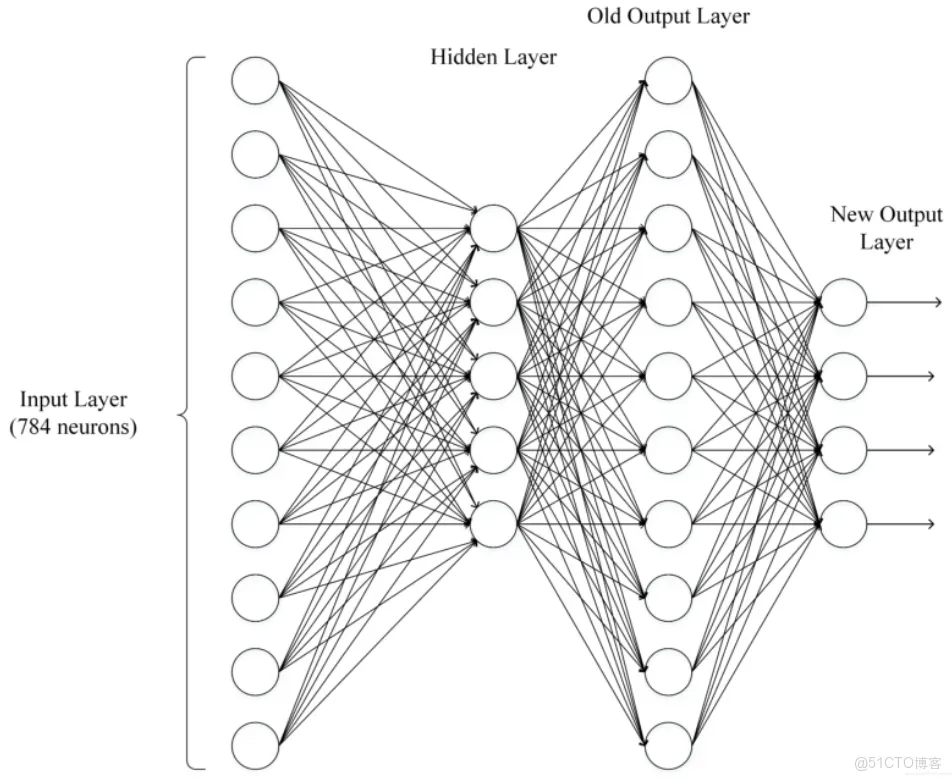
輸出層可以不止有1 11個神經元。隱藏層可以只有1 11層,也可以有多層。輸出層為多個神經元的神經網絡例如下圖所示:
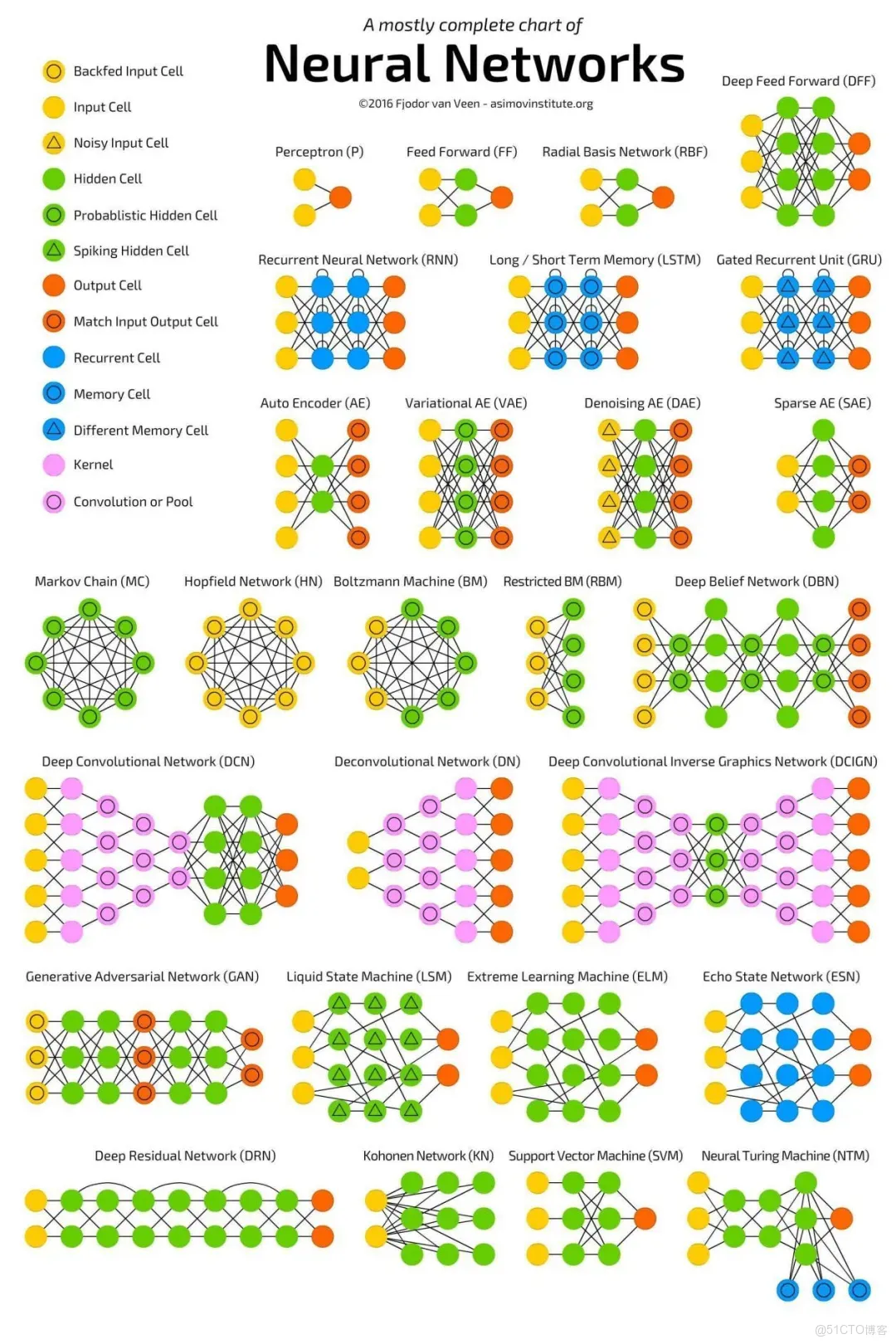
二、神經網絡的常用模型結構
下圖包含了大部分常用的模型:
三、如何選擇深度學習的開發平台
現有的深度學習開源平台主要有 PyTorch, MXNet, CNTK, Theano, TensorFlow, Keras, PaddlePaddle等。那如何選擇一個適合自己的平台呢?
參考1:與現有編程平台、技能整合的難易程度
主要是前期積累的開發經驗和資源,比如編程語言,前期數據集存儲格式等。
參考2: 與相關機器學習、數據處理生態整合的緊密程度
深度學習研究離不開各種數據處理、可視化、統計推斷等軟件包。考慮建模之前,是否具有方便的數據預處理工具?建模之後,是否具有方便的工具進行可視化、統計推斷、數據分析。
參考3:對數據量及硬件的要求和支持
深度學習在不同應用場景的數據量是不一樣的,這也就導致我們可能需要考慮分佈式計算、多GPU計算的問題。
例如,對計算機圖像處理研究的人員往往需要將圖像文件和計算任務分部到多台計算機節點上進行執行。當下每個深度學習平台都在快速發展,每個平台對分佈式計算等場景的支持也在不斷演進。
參考4:深度學習平台的成熟程度
成熟程度的考量是一個比較主觀的考量因素,這些因素可包括:社區的活躍程度;是否容易和開發人員進行交流;當前應用的勢頭。
參考5:平台利用是否多樣性?
有些平台是專門為深度學習研究和應用進行開發的,有些平台對分佈式計算、GPU 等構架都有強大的優化,能否用這些平台/軟件做其他事情?
比如有些深度學習軟件是可以用來求解二次型優化;有些深度學習平台很容易被擴展,被運用在強化學習的應用中。
一般來説,現在做科學研究和競賽用Pytorch較多,工業級的用Tensorflow較多。
四、為什麼深層神經網絡比較難訓練
1.梯度消失:
梯度消失是指通過隱藏層從後向前看,梯度會變的越來越小,説明前面層的學習會顯著慢於後面層的學習,所以學習會卡住,除非梯度變大。
梯度消失的原因受到多種因素影響,例如學習率的大小,網絡參數的初始化,激活函數的邊緣效應等。在深層神經網絡中,每一個神經元計算得到的梯度都會傳遞給前一層,較淺層的神經元接收到的梯度受到之前所有層梯度的影響。如果計算得到的梯度值非常小,隨着層數增多,求出的梯度更新信息將會以指數形式衰減,就會發生梯度消失。下圖是不同隱含層的學習速率:
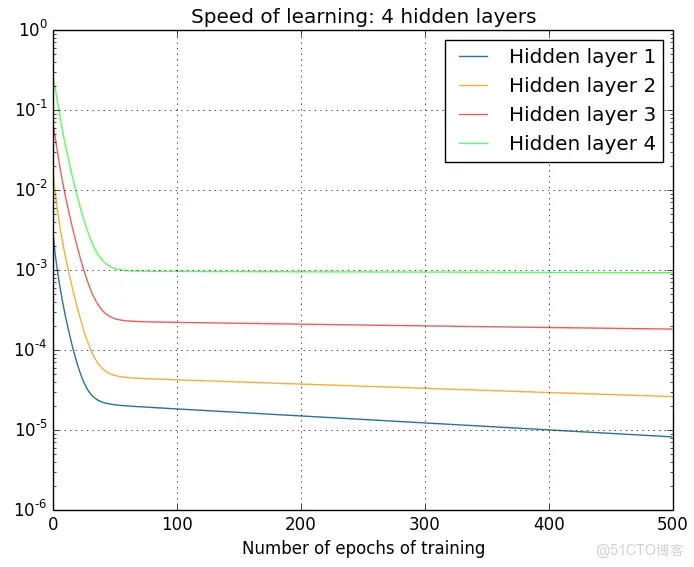
2.梯度爆炸
在深度網絡或循環神經網絡(Recurrent Neural Network, RNN)等網絡結構中,梯度可在網絡更新的過程中不斷累積,變成非常大的梯度,導致網絡權重值的大幅更新,使得網絡不穩定;在極端情況下,權重值甚至會溢出,變為N a N NaNNaN值,再也無法更新。
3.權重矩陣的退化導致模型的有效自由度減少。
參數空間中學習的退化速度減慢,導致減少了模型的有效維數,網絡的可用自由度對學習中梯度範數的貢獻不均衡,隨着相乘矩陣的數量(即網絡深度)的增加,矩陣的乘積變得越來越退化。在有硬飽和邊界的非線性網絡中(例如 ReLU 網絡),隨着深度增加,退化過程會變得越來越快。
Duvenaud等人2014年的論文裏展示了關於該退化過程的可視化:

隨着深度的增加,輸入空間(左上角所示)會在輸入空間中的每個點處被扭曲成越來越細的單絲,只有一個與細絲正交的方向影響網絡的響應。沿着這個方向,網絡實際上對變化變得非常敏感。
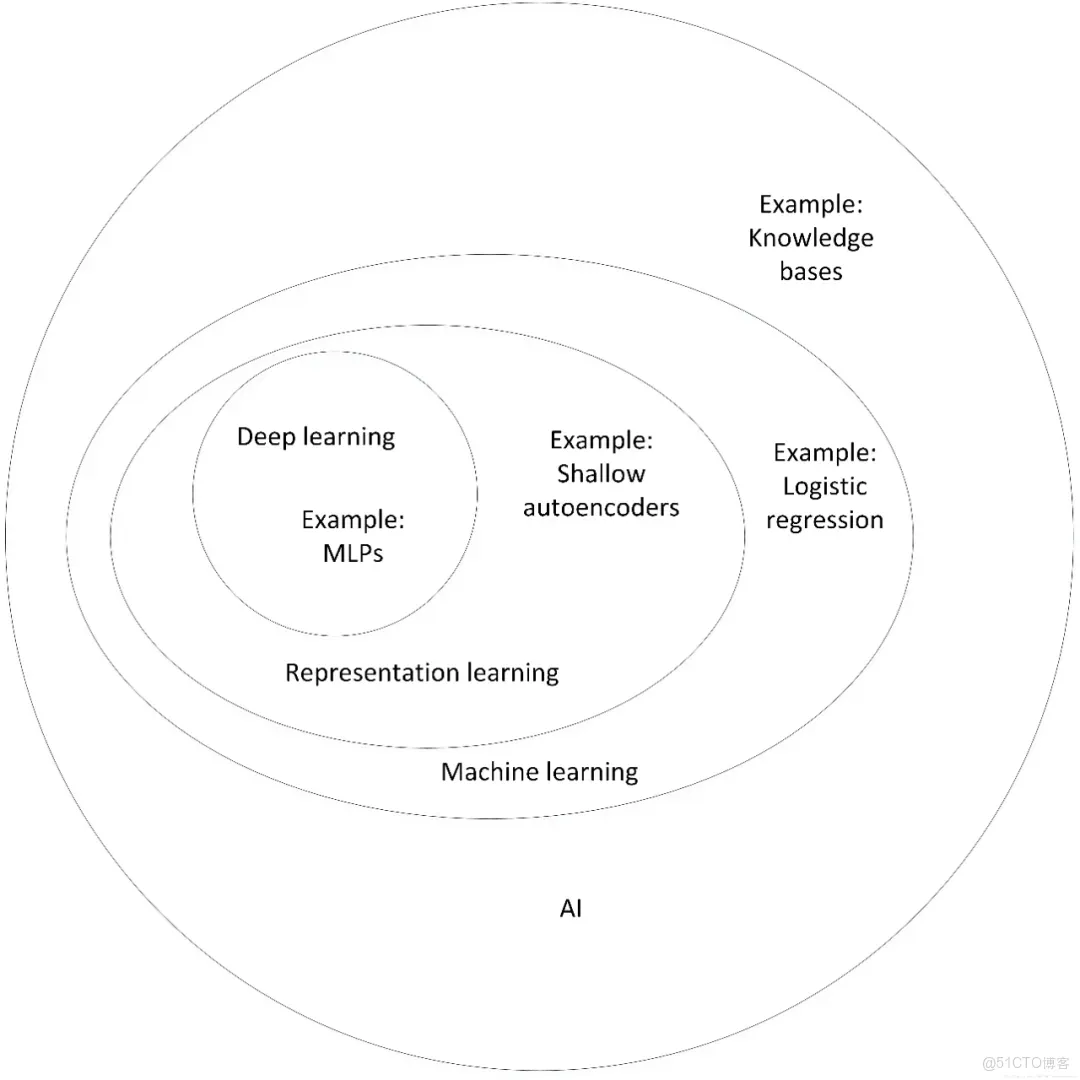
五、深度學習與機器學習的差異或區別
機器學習:利用計算機、概率論、統計學等知識,輸入數據,讓計算機學會新知識。機器學習的過程,就是訓練數據去優化目標函數。
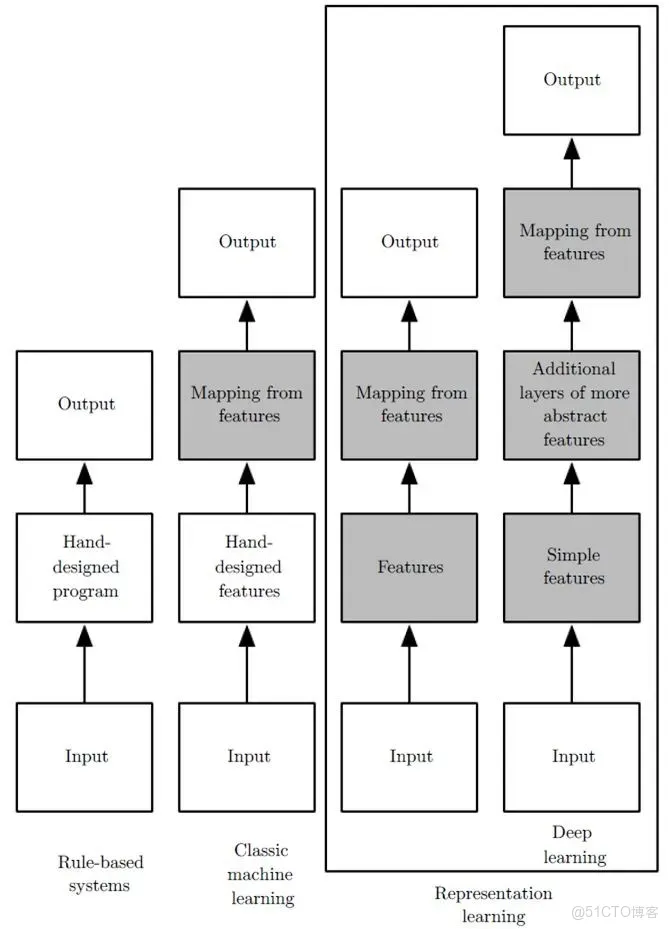
深度學習:是一種特殊的機器學習,具有強大的能力和靈活性。它通過學習將世界表示為嵌套的層次結構,每個表示都與更簡單的特徵相關,而抽象的表示則用於計算更抽象的表示。
傳統的機器學習需要定義一些手工特徵,從而有目的的去提取目標信息, 非常依賴任務的特異性以及設計特徵的專家經驗。而深度學習可以從大數據中先學習簡單的特徵,並從其逐漸學習到更為複雜抽象的深層特徵,不依賴人工的特徵工程,這也是深度學習在大數據時代受歡迎的一大原因。