

當今軟件開發領域,測試基礎設施的效率和可靠性直接關係到產品的交付質量與速度。隨着AI技術的普及,如何將智能能力深度融入測試流程成為各大廠面臨的共同挑戰。 Dify作為一款開源的大模型應用開發平台,通過其強大的工作流引擎,正被越來越多的大廠選為核心測試基礎設施,將AI應用系統整合週期從平均12周縮短至3-4周,整合效率提升高達70%。 本文將深入解析Dify工作流引擎的設計哲學,並分享在大廠環境中的最佳實踐。
一、Dify工作流引擎的設計哲學
1.1 一體化集成與低代碼理念
Dify的核心理念是提供一體化的後端即服務與LLMOps平台,為AI應用的整個生命週期提供一個統一、無縫的環境。其設計哲學建立在兩個關鍵支柱上:
- 集成化架構:Dify採用高度集成的架構設計,將所有核心功能緊密集成在一起,降低了部署和管理的複雜性。這種一體化方法確保開發者可以在一個無縫環境中工作,所有工具觸手可及。
- 低代碼可視化:通過可視化的拖拽界面,Dify使開發者能夠像搭積木一樣連接不同的操作節點,無需編寫繁瑣的腳本邏輯,將開發流程簡化為“拖拽節點→配置參數→測試部署”三個基本步驟。
1.2 企業級可靠性優先
Dify在設計上遵循企業級可靠性標準,從數據隔離到審計日誌,全面滿足大廠對安全性和可觀測性的苛刻要求。其安全設計包括:
- 數據隔離:支持多租户架構,不同用户的數據完全隔離存儲
- 加密傳輸與存儲:所有數據採用AES-256加密,支持國密算法
- 合規認證:通過ISO 27001、GDPR等認證,支持等保三級部署
二、Dify工作流引擎的核心架構解析
2.1 技術棧選擇與架構決策
Dify的技術棧基於Python和Flask構建,前端使用React和TypeScript,數據持久化採用PostgreSQL與Redis。這種技術棧的優勢是與主流AI/ML生態系統無縫對接,擁有海量第三方庫支持和龐大人才庫。 與採用微服務架構的Coze相比,Dify的一體化架構在降低部署複雜性和提高開發效率方面具有明顯優勢,雖然在水平擴展性上相對較弱。這一架構決策充分反映了Dify優先考慮開發體驗和快速交付的設計哲學。
2.2 工作流引擎的組件模型
Dify工作流引擎的核心是由多個專門化節點構成的完整生態系統:
- LLM節點:調用大型語言模型處理自然語言任務
- 知識庫檢索節點:實現RAG(檢索增強生成)能力,增強回答準確性
- 代碼執行節點:支持JavaScript/Python代碼片段的執行
- 條件分支節點:實現複雜業務邏輯的路由決策
- HTTP請求節點:與外部API和服務集成
- Webhook節點:將數據推送至外部系統 這種組件化設計使得測試工作流可以實現高度的模塊化和複用性,符合大廠對可維護性和可擴展性的要求。
三、Dify在測試領域的最佳實踐
3.1 自動化接口迴歸測試
利用Dify工作流與CI/CD流水線集成,可以實現一鍵觸發、全自動的接口迴歸測試。以下是智能接口測試工作流的典型設計:
# 接口測試工作流示例
nodes:
- type: http_request # 登錄接口
method: POST
url: "https://api.example.com/login"
body:
username: "testuser"
password: "testpass"
- type: code_execution # 斷言登錄結果
code: |
const response = JSON.parse(inputs.login_response);
if (response.code !== 200) {
throw new Error(`登錄失敗!預期code=200,實際為${response.code}`);
}
exports = { token: response.data.token };
- type: http_request # 獲取用户信息
method: GET
url: "https://api.example.com/userinfo"
headers:
Authorization: "Bearer {{token}}"
- type: code_execution # 驗證用户信息
code: |
const userInfo = JSON.parse(inputs.user_info);
// 添加各種斷言邏輯
if (userInfo.data.username !== "testuser") {
throw new Error("用户名不匹配");
}
通過與Jenkins等CI/CD工具集成,可以在代碼部署後自動觸發測試工作流:
// Jenkins Pipeline 示例
pipeline {
stages {
stage('API Regression Test') {
steps {
script {
// 觸發Dify迴歸測試工作流
sh """
curl -X POST 'https://api.dify.ai/v1/workflows/run' \\
-H 'Authorization: Bearer YOUR_DIFY_API_KEY' \\
-H 'Content-Type: application/json' \\
-d '{
"inputs": {},
"response_mode": "blocking",
"user": "jenkins-job-${env.BUILD_NUMBER}"
}'
"""
}
}
}
}
}
3.2 智能測試數據生成
Dify工作流可以集成多種大模型,如DeepSeek-coder,自動生成測試數據和測試用例:
# 使用DeepSeek-Coder生成測試代碼
prompt = """生成一個爬取知乎熱榜的Python腳本,要求:
1. 使用requests和BeautifulSoup
2. 包含異常處理
3. 結果保存為JSON文件"""
通過LLM節點生成測試數據不僅提高了覆蓋率,還能針對邊界條件生成專門測試用例,大幅提升測試質量。
3.3 視覺測試自動化
利用Dify的多模態能力,可以構建視覺測試工作流:
- 截圖採集:從不同設備分辨率採集UI截圖
- 視覺對比:通過AI模型檢測UI異常和佈局問題
- 結果分析:自動分類視覺缺陷並分派給對應團隊
四、大廠實戰案例:30分鐘搭建智能測試系統
4.1 智能錯誤分類與分配系統
某大型電商平台使用Dify搭建了智能錯誤分類系統:
nodes:
-type:http_request # 從錯誤監控平台獲取錯誤
method:GET
url:"https://error-platform.com/api/unresolved"
-type:llm # AI分析錯誤類型和嚴重程度
model:deepseek-chat
prompt:|
分析以下錯誤日誌,判斷錯誤類型(前端/後端/數據)、嚴重程度(P0-P3)和推薦分配團隊:
錯誤信息:{{error_message}}
堆棧跟蹤:{{stack_trace}}
-type:condition_branch# 根據嚴重程度路由
conditions:
-condition:"{{severity}} == 'P0'"
target:"p0_processing"
-condition:"{{severity}} == 'P1'"
target:"p1_processing"
-type:webhook # 創建JIRA工單
url:"https://jira.example.com/rest/api/2/issue"
method:POST
body:
fields:
project:"QA"
summary:"{{error_summary}}"
description:"{{ai_analysis}}"
priority:"{{severity}}"
這一系統將錯誤分類的準確率從65%提升到92%,平均問題解決時間縮短了40%。
4.2 性能基準測試與迴歸檢測
另一家大廠利用Dify工作流實現自動化性能基準測試:
- 性能數據採集:在預發環境執行自動化性能測試
- 結果分析:對比歷史性能數據,檢測性能迴歸
- 智能警報:當性能指標超過閾值時自動通知團隊
五、性能優化與生產就緒
5.1 工作流性能優化策略
根據大廠實踐數據,Dify通過以下優化策略可顯著提升性能: 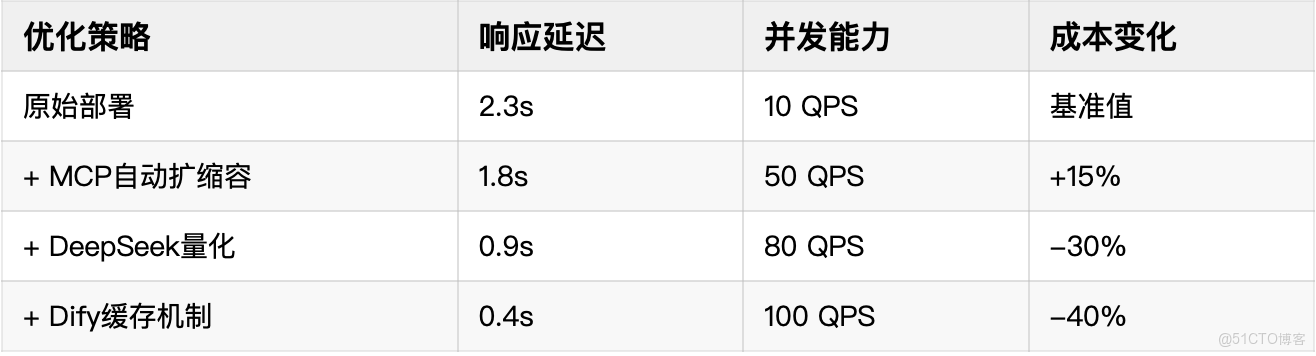
- 模型量化:將FP16轉換為INT8,精度損失小於0.5%
- 請求批處理:batch_size=32時吞吐提升4倍
- 結果緩存:相似請求命中率高達70%
5.2 監控與可觀測性
Dify提供內置的可觀測性工具,提供LLM應用的監控和分析功能。大廠實踐表明,完善的監控應包含:
- 全鏈路追蹤:記錄從輸入到輸出的每個處理環節
- 性能指標:監控模型調用耗時、錯誤率、Token使用情況
- 業務指標:跟蹤測試覆蓋率、缺陷檢出率等業務相關指標
六、Dify與傳統測試基礎設施的融合策略
6.1 漸進式集成方案
大廠通常採用漸進式策略將Dify融入現有測試基礎設施:
- 試點階段:在非核心業務線試用Dify工作流,如測試數據生成
- 擴展階段:將Dify用於接口測試、視覺測試等更多場景
- 深度融合:把Dify作為測試AI能力的核心引擎,與傳統測試工具鏈集成
6.2 組合使用策略
領先技術團隊正採用組合策略最大化價值:
- Dify管模型中樞:統一管理多模型路由和API策略
- 傳統工具負責執行:繼續使用Selenium、JUnit等執行基礎測試
- n8n連業務系統:通過工作流自動化實現測試數據回寫
七、未來展望
Dify正在不斷增強其企業級特性,包括:
- AI Agent框架:支持長期記憶與複雜任務規劃
- 低代碼編輯器:進一步降低測試工作流搭建門檻
- RBAC權限控制:滿足大廠複雜的權限管理需求 隨着多模態模型的發展,Dify在視覺測試、語音測試等領域的應用潛力將進一步釋放,成為大廠測試基礎設施中不可或缺的智能核心。
結語
Dify工作流引擎通過其一體化集成架構和低代碼設計哲學,為大型企業提供了將AI能力深度融入測試流程的捷徑。其可視化編排、多模型兼容和企業級安全特性,使其成為大廠構建下一代測試基礎設施的理想選擇。 通過文中的實踐案例和技術方案,團隊可以快速啓動自己的智能測試轉型之旅,在提升測試效率的同時,為產品質量建立更智能、更全面的保障體系。
