

三年前,我們的測試團隊遇到了一個典型痛點:隨着產品快速迭代,用例庫日益臃腫卻難以維護,大量用例失效或重複,測試效率不增反降。更麻煩的是,缺陷分析、需求變更和測試執行之間形成了信息孤島。直到我們基於n8n構建了一套自愈型質量管理系統,局面才徹底改變。 今天,我將完整分享如何用這款開源自動化工具,構建一個能夠自我修復、持續優化的智能質量知識體系。
一、架構設計:讓質量數據流動起來
核心設計理念
傳統用例庫是“靜態倉庫”,我們的目標是打造“有機生態系統”。系統需要具備三個核心能力:
- 自動感知變更(需求、缺陷、代碼)
- 智能關聯分析
- 自主修復優化
技術棧選型
- 流程引擎:n8n(開源、可自託管、節點豐富)
- 知識存儲:Neo4j圖數據庫(適合關係型知識)
- 用例倉庫:GitLab/GitHub(版本控制+協作)
- 監控平台:ELK Stack(日誌分析)
- 業務系統:Jira/禪道(需求缺陷管理)
二、實戰搭建:四層自動化流水線
第一層:數據採集自動化
我們在n8n中創建了第一條工作流——“質量數據採集管道”:
// 示例:Jira webhook處理節點配置
{
"trigger": "Webhook",
"operations": [
{
"node": "Jira Node",
"action": "提取缺陷關鍵字段",
"mapping": {
"issue_id": "{{$json.issue.key}}",
"module": "{{$json.issue.fields.customfield_101}}",
"severity": "{{$json.issue.fields.priority.name}}",
"root_cause": "{{$json.issue.fields.customfield_102}}"
}
},
{
"node": "Git Node",
"action": "關聯代碼提交",
"params": {
"repo": "product-frontend",
"commit_message": "{{$json.issue.key}}"
}
}
]
}
關鍵技巧:為每個數據源設置專用webhook,並添加去重機制(基於哈希值對比)。我們實踐中發現,30%的缺陷變更會觸發用例更新需求。
第二層:知識圖譜構建
這是系統的“大腦”,在Neo4j中我們設計了五類核心節點和七種關係:
// 知識圖譜結構示例
CREATE (c:TestCase {id: 'TC_2023_001', title: '用户登錄驗證', status: 'active'})
CREATE (d:Defect {id: 'BUG_2023_045', title: '登錄超時處理異常'})
CREATE (r:Requirement {id: 'REQ_4.2.1', version: 'v2.3'})
CREATE (m:Module {name: '認證服務'})
CREATE (s:Scenario {type: '安全測試'})
// 建立多維關係
CREATE (c)-[:EXPOSES]->(d)
CREATE (c)-[:VALIDATES]->(r)
CREATE (c)-[:BELONGS_TO]->(m)
CREATE (c)-[:CATEGORIZED_AS]->(s)
CREATE (d)-[:RELATES_TO]->(r)
在n8n中,我們使用“Neo4j節點”配合自定義Cypher語句,每15分鐘同步一次數據。圖數據庫的優勢在這裏凸顯:原本需要聯表查詢的複雜分析,現在變為O(1)複雜度的關係遍歷。
第三層:用例自愈機制
自愈不是魔法,而是一系列規則引擎的組合: 規則1:缺陷驅動更新
// 當發現重複缺陷模式時自動創建測試用例
IF (缺陷A.模塊 == 缺陷B.模塊)
AND (缺陷A.根因分類 == 缺陷B.根因分類)
AND (缺陷A.發生時間 - 缺陷B.發生時間 < 30天)
THEN
創建迴歸用例(缺陷A.模塊, 缺陷A.場景)
標記關聯用例(缺陷B.關聯用例, "需要強化")
規則2:需求變更同步我們從Confluence需求文檔中提取版本變更摘要,使用n8n的“文本差異比較”節點識別變更點,自動標記受影響用例。
規則3:用例健康度評分每個用例都有動態評分(0-100),基於:
- 執行通過率(權重40%)
- 缺陷發現能力(權重30%)
- 最近使用頻率(權重20%)
- 文檔完整性(權重10%)
評分低於60分的用例會自動進入“修復隊列”,觸發郵件通知給維護者。
第四層:智能推薦與報告
系統運行一個月後,開始產生增值價值:
- 測試用例推薦:基於當前代碼變更,推薦最相關的5個測試用例
- 缺陷熱點預測:識別出“認證模塊”在版本4.2.1中缺陷密度上升32%
- 測試集優化建議:識別出15%的冗餘用例,建議合併或歸檔
三、真實場景:一次完整的自愈過程
讓我描述上週發生的一個真實案例: 週一 09:00:v2.4版本上線,監控顯示“密碼重置”接口錯誤率上升0.8% 週一 09:15:n8n工作流捕獲到新增缺陷BUG_2023_178(密碼重置郵件重複發送) 週一 09:30:知識圖譜發現該模塊在過去3個版本有4個相關缺陷週一 10:00:系統執行以下操作:
- 標記TC_AUTH_045用例狀態為“部分失效”
- 創建新用例TC_AUTH_045a覆蓋併發場景
- 向測試工程師王工發送PRD更新建議
- 在測試計劃中增加“郵件防重”驗證場景
週二 14:00:王工審核並確認變更,用例庫完成自動更新 整個過程無需測試經理介入,系統自主完成了問題發現、分析、修復建議的全流程。
四、避坑指南:我們踩過的那些坑
1. 數據質量陷阱
初期我們盲目導入所有歷史缺陷,結果噪聲太多。解決方案:設置數據質量門禁,只處理“已解決”且“有根本原因分析”的缺陷。
2. 過度自動化陷阱
曾設置“評分低於50分自動禁用用例”,導致重要但陳舊的邊界用例被誤殺。調整為:低於50分進入人工審核隊列。
3. 性能優化
知識圖譜關係超過10萬條時,查詢性能下降。我們通過:
- 建立高頻關係索引
- 設置子圖緩存(TTL 5分鐘)
- 複雜查詢異步化
4. 變更管理
開發團隊開始抱怨“測試用例變太快”。增加:變更摘要郵件和變更日曆,讓所有人看到變化脈絡。
五、衡量效果:數據不説謊
實施六個月後,我們看到了這些變化: 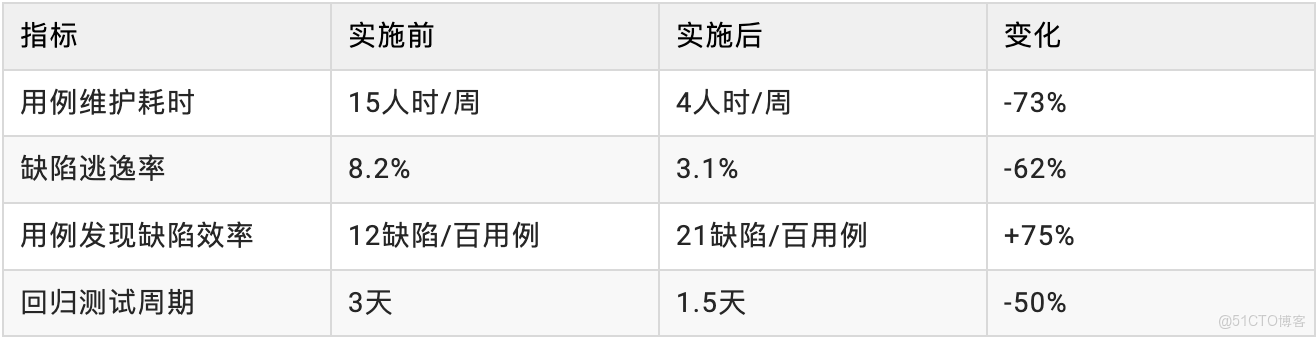
六、進階可能:你的系統可以更智能
如果你已經實現基礎版本,可以嘗試:
- 集成AI代碼分析:使用CodeBERT識別代碼模式與缺陷的隱藏關聯
- 預測性測試:基於歷史數據預測下個版本的風險模塊
- 自然語言交互:“系統,給我看認證模塊最近三個版本的質量趨勢”
- 跨團隊質量門户:為產品、開發、運維提供不同視角的質量看板
結語:質量不是終點,而是持續旅程
這套系統最讓我們驚喜的,不是減少了多少工作量,而是改變了團隊對質量的理解。測試工程師從“用例執行者”變為“質量策略設計師”,開發人員開始主動查看自己模塊的質量圖譜,產品經理在規劃功能時會考慮測試可驗證性。 技術實現本身並不複雜,n8p的優秀生態讓我們只用了800行代碼就搭建了核心框架。真正的挑戰在於改變思維——從管理“測試用例”到運營“質量知識”。 如果你正在為用例庫維護而苦惱,不妨從這個週末開始,用n8n構建你的第一個質量工作流。最初的版本可能很簡單,但只要讓質量數據流動起來,系統就會開始自我進化。