
Transformer 中的 Softmax 注意力因二次複雜度難以適配視覺任務,線性注意力雖將複雜度降至線性,但輸出特徵圖的低秩特性導致空間建模能力不足為解決這一線性注意力的低秩困境而提出。就是,性能顯著落後於 Softmax 注意力,RALA 正
原模型
改進後的
1.RALA原理
RALA 從 KV 緩衝和輸出特徵兩個關鍵環節提升矩陣秩:針對 KV 緩衝,引入上下文感知的重排係數為每個 token 分配權重,增強信息豐富度與多樣性,提升其秩;針對輸出特徵,通過通道維度的特徵交互策略,結合原始 token 信息進行調製,使輸出特徵達到滿秩狀態,從而在保持線性複雜度的同時,強化麻煩空間特徵建模能力。
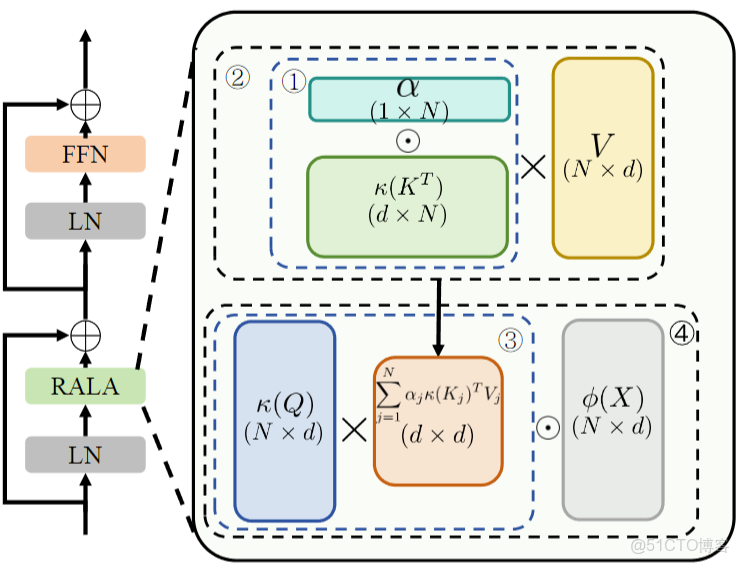
RALA 的核心結構包含 KV 緩衝秩增強模塊和輸出特徵秩增強模塊:前者藉助權重係數調整 KV 緩衝的計算方式,後者採用 Hadamard 乘積融合原始 token 變換特徵與 KV 緩衝交互結果;基於 RALA 構建的 RAVLT 網絡,採用經典 Transformer 塊設計,包含線性注意力層與 FFN 層,通過 CPE 給予位置編碼,整體為分層式通用視覺骨幹網絡。
2.RALA習作思路
(一)目標檢測場景
RALA 通過提升特徵矩陣秩,增強了特徵的多樣性與表達能力,能夠更精準地捕捉目標的細節信息與全局關聯,同時線性複雜度保證了檢測過程的高效性,可在不顯著增加計算開銷的前提下,提升對不同尺度、形態目標的識別與定位能力,兼顧檢測精度與推理速度。
(二)圖像分割場景
RALA 的滿秩特徵輸出使模型能更好地建模像素級別的空間關係與語義信息,有效緩解線性注意力在細粒度特徵學習上的不足,同時高效的計算特性支持大分辨率特徵圖處理,有助於精準分割不同語義類別區域,提升分割結果的邊界完整性與類別一致性。
3. YOLO與RALA的結合
RALA 的線性複雜度可在不大幅增加 YOLO 計算負擔的前提下,提升特徵表達能力,助力 YOLO 更好地捕捉目標細節與全局關聯;其滿秩特徵能增強 YOLO 對小目標、複雜場景目標的識別能力,進一步優化檢測精度與泛化性能。
4.RALA代碼部分
YOLO12模型改進手段,快速發論文,總有適合你的改進,還不改進上車_嗶哩嗶哩_bilibili
YOLOv12 論文結構解析:強勢來臨,超越 YOLOv11!_嗶哩嗶哩_bilibili
代碼獲取:YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. RALA引入到YOLOv12中
第一: 先新建一個v12_changemodel,將下面的核心代碼複製到下面這個路徑當中,如下圖如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。
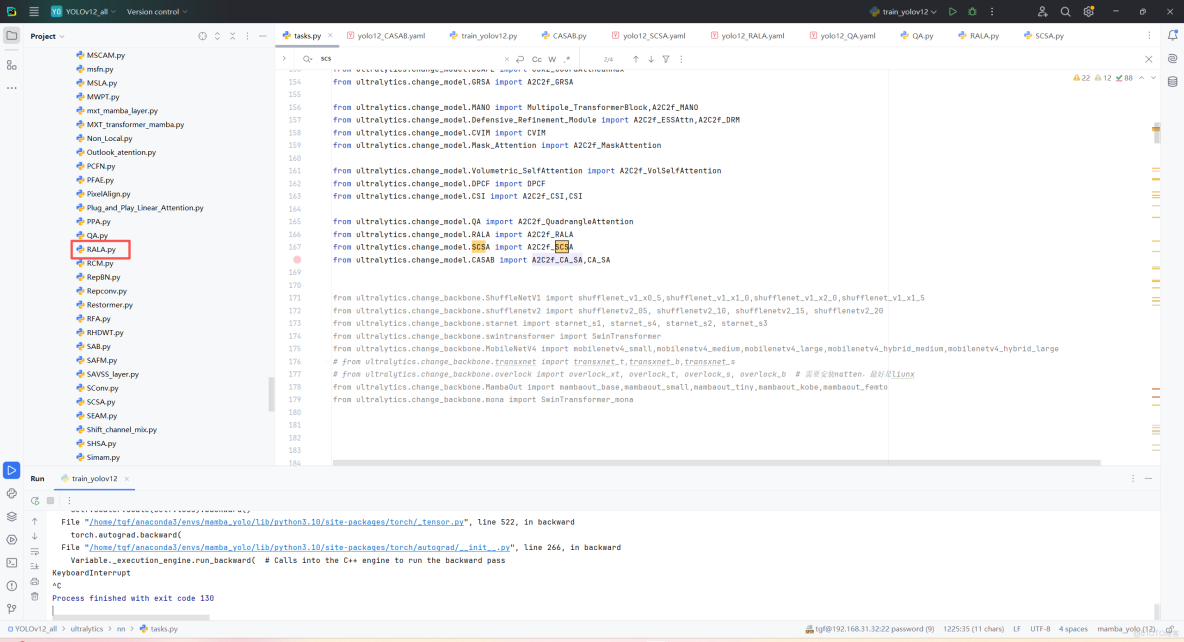
第二:在task.py中導入包
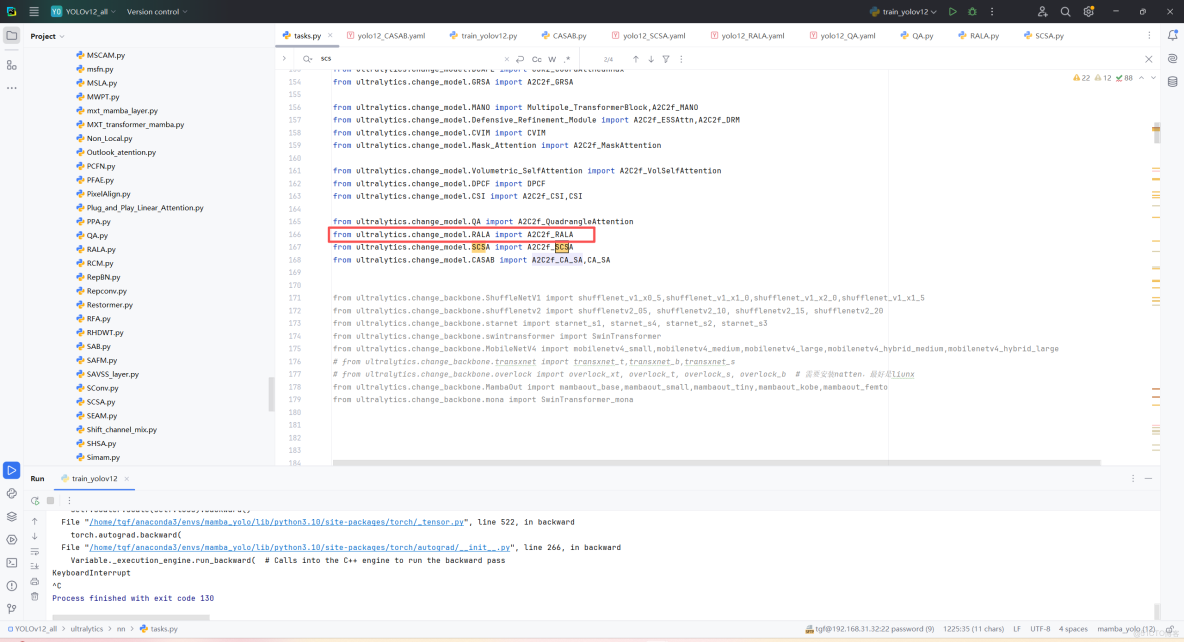
第三:在task.py中的模型配置部分下面代碼
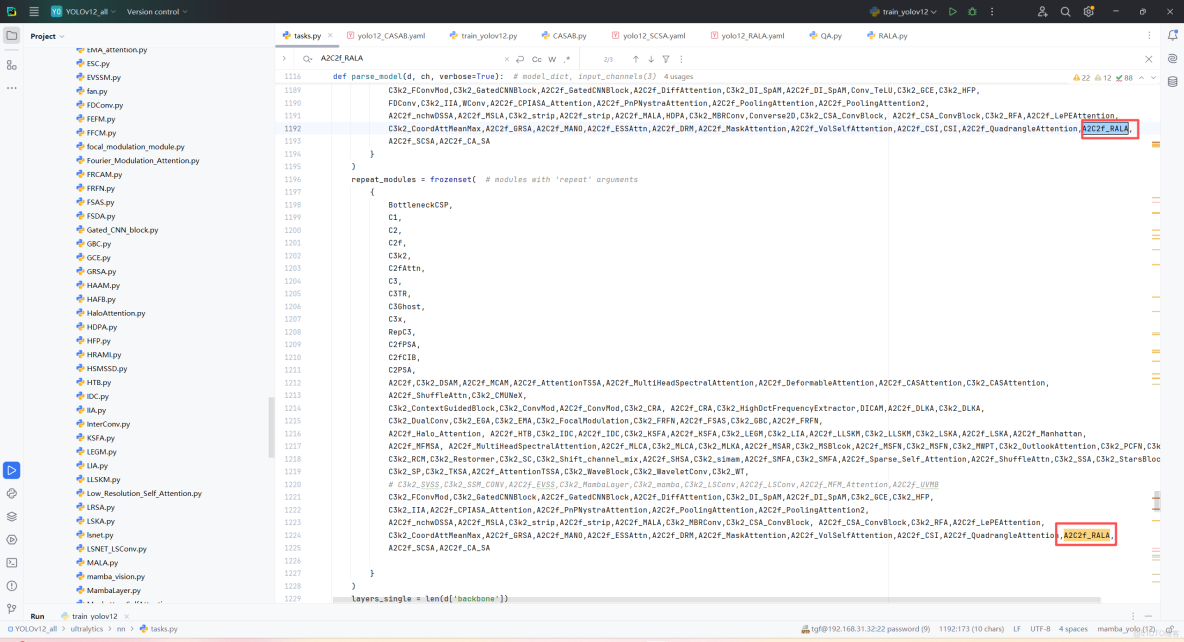
第四:將模型配置文件複製到YOLOV11.YAMY文件中
第五:運行代碼
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型並加載預訓練權重訓練模型
model = YOLO("/home/tgf/tgf/yolo/model/YOLO12_All/ultralytics/cfg/models/12/yolo12_RALA.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是單類別檢測
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)