

最新案例動態,請查閲【案例共創】基於機器學習的鑽石電商定價策略優化:數據驅動的精準價格預測。小夥伴們快來領取華為開發者空間進行實操吧!
本案例由開發者:天津師範大學協同育人項目–翟羽佳提供
1 概述
1.1 案例介紹
年複合增長率達 12.4%。然而,鑽石作為高客單價、非標品類的代表,其價格受多維度因素影響(如 4C 標準、市場供需),傳統定價模式依賴人工經驗,存在主觀性強、響應速度慢、利潤空間難控等問題。對電商平台而言,用户行為數據(如瀏覽、比價、購買決策週期)是優化運營的關鍵。麥肯錫研究指出,數據驅動的動態定價策略可使企業利潤提升 5-15%,但多數中小電商缺乏技術能力,面臨用户轉化率低促銷資源浪費等痛點。
本案例通過數據科學手段,將機器學習技術與業務目標緊密結合,具體體現在以下幾個方面:
聚類算法與用户標籤體系:通過聚類算法對用户進行分羣,構建用户標籤體系,幫助企業精準識別高價值用户羣體。
迴歸模型與價格預測:通過 XGBoost、隨機森林等迴歸模型,準確預測鑽石價格,幫助企業優化定價策略和庫存管理。
數據驅動的營銷優化:基於用户分羣和價格預測結果,制定個性化的營銷策略,提升廣告投放的精準度和用户轉化率,最終實現ROI的提升。
1.2 適用對象
- 數據科學與機器學習者
- 電商行業從業者
- 商業分析與戰略制定者
1.3 案例時間
本案例總時長預計60分鐘。
1.4 案例流程

説明:
- 登錄開發者空間,啓動Notebook;
- 在Notebook中編寫代碼運行調試。
1.5 資源總覽
本案例預計花費0元。
|
資源名稱 |
規格 |
單價(元) |
時長(分鐘) |
|
開發者空間-Notebook
|
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
|
免費
|
60
|
2 資源與環境準備
2.1 啓動Notebook
參考“DeepSeek模型API調用及參數調試(開發者空間Notebook版)”案例的第2.2章節啓動Notebook。
2.2 安裝依賴庫
打開終端:
安裝代碼中使用到的第三方庫:
pip install numpy
pip install pandas
pip install matplotlib
pip install scikit-learn
pip install seaborn
pip install xgboost執行命令,結果如下:
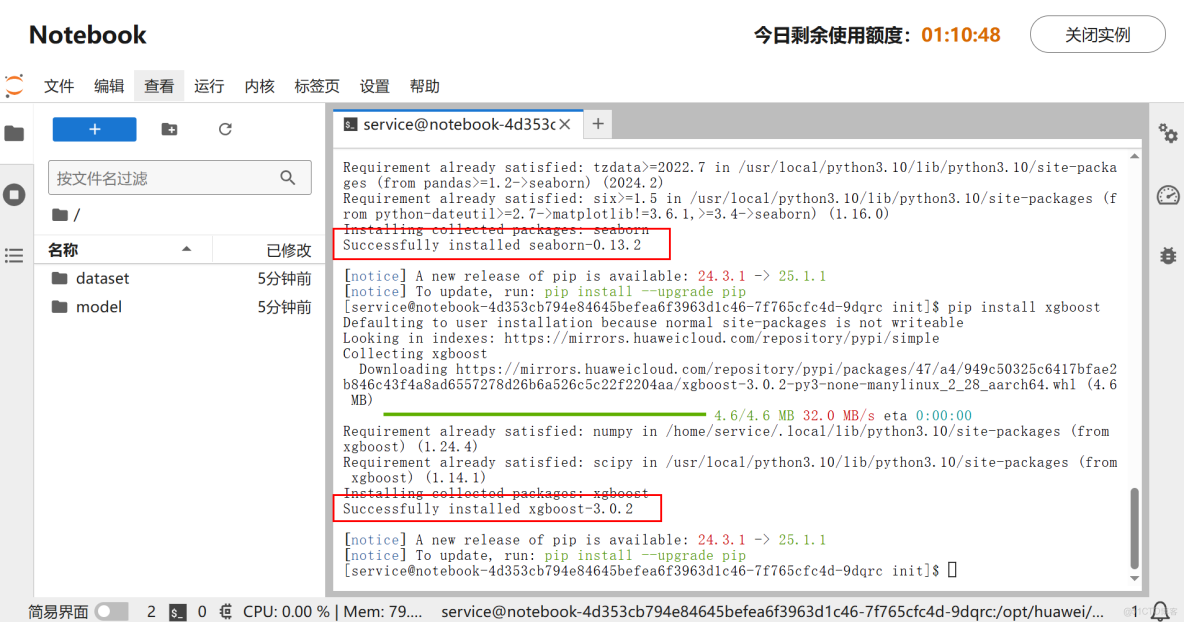
注意:如果安裝失敗,可以使用國內鏡像和最新庫名進行安裝:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple seaborn
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost當安裝完成後,系統會返回所有已成功安裝的庫,如下圖安裝第三方庫安裝成功,通過pip list查看所有已安裝的第三方庫:
pip list


3 代碼運行及結果展示
3.1 導入必要的庫
numpy:用於 n 維數組處理和數值計算的三方庫。
pandas:用於數據分析、數據處理的三方庫。
matplotlib:Python中的2D繪圖庫。
scikit-learn:是一個基於Python的開源機器學習庫,提供分類、迴歸、聚類、降維等算法,並集成數據預處理、模型評估等功能,廣泛應用於數據分析和人工智能領域。
seaborn:是基於 Python 的Matplotlib的數據可視化庫。
xgboost:基於梯度提升(Gradient Boosting)的決策樹算法,廣泛應用於結構化數據的分類和迴歸任務。
3.2 數據加載與預處理
數據準備:將如下鏈接數據集下載,並通過notebook上傳。
<https://case-aac4.obs.cn-north-4.myhuaweicloud.com/diamonds.csv>
下載到本地的數據:
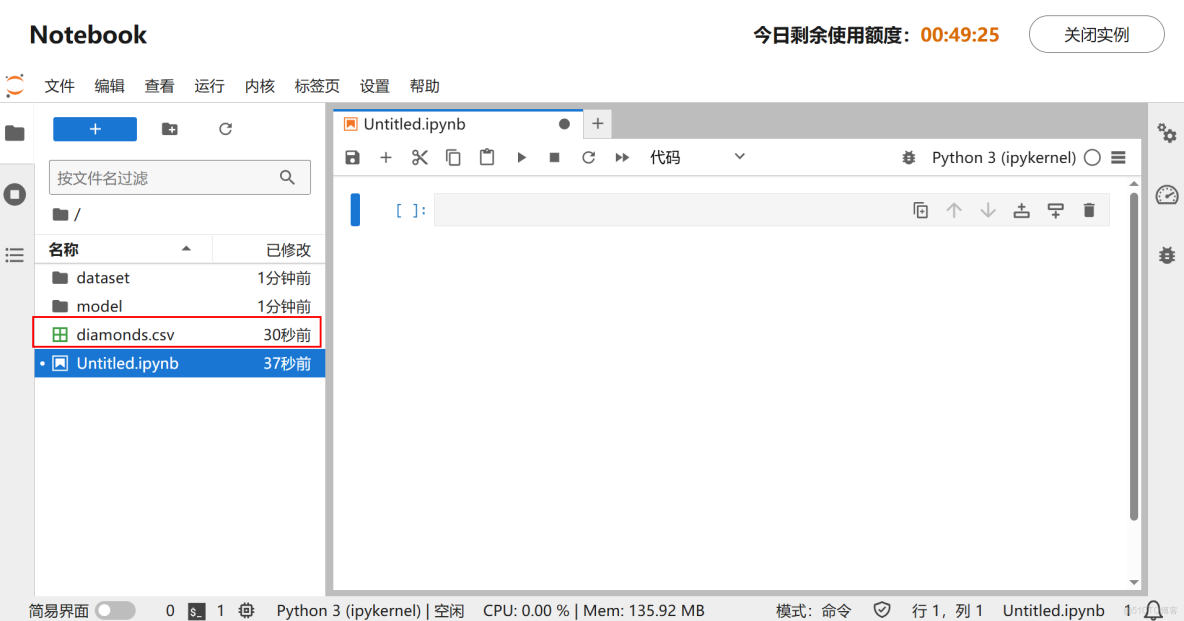
將文件拖拽到Notebook左側代碼同級目錄下,數據上傳成功如下圖所示:
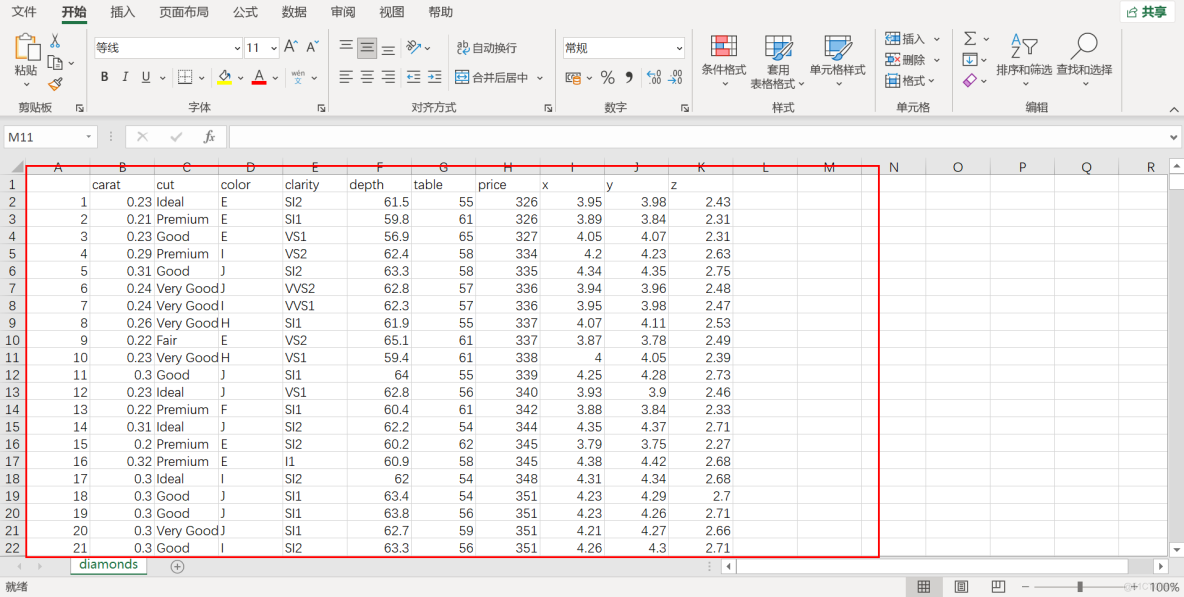
數據集示例:
3.3 運行代碼及結果展示
在Notebook的新執行框中輸入如下代碼並運行:
# 導入所需的 Python 庫
# NumPy: 用於高效數值計算,提供多維數組對象和工具
import numpy as np
# Pandas: 用於數據處理和分析,提供 DataFrame 和 Series 數據結構
import pandas as pd
# Seaborn: 基於 Matplotlib 的高級可視化庫,用於繪製統計圖表
import seaborn as sns
# Matplotlib: Python 的基礎繪圖庫,用於創建靜態、動畫和交互式可視化
import matplotlib as mpl
# Matplotlib.pyplot: 提供一個類似 MATLAB 的繪圖接口,用於快速創建圖表
import matplotlib.pyplot as plt
# Matplotlib.pylab: 提供一個集成的接口,結合了 NumPy 和 Matplotlib 的功能
import matplotlib.pylab as pylab
# OneHotEncoder: 用於將分類變量轉換為獨熱編碼
from sklearn.preprocessing import OneHotEncoder
# LabelEncoder: 用於將分類標籤轉換為數值標籤
from sklearn.preprocessing import LabelEncoder
# train_test_split: 用於將數據集劃分為訓練集和測試集
from sklearn.model_selection import train_test_split
# StandardScaler: 用於對特徵進行標準化(均值為 0,標準差為 1)
from sklearn.preprocessing import StandardScaler
# PCA: 主成分分析,用於降維和特徵提取
from sklearn.decomposition import PCA# Pipeline: 用於構建機器學習流水線,簡化模型構建過程
from sklearn.pipeline import Pipeline
# DecisionTreeRegressor: 決策樹迴歸器,用於迴歸任務
from sklearn.tree import DecisionTreeRegressor
# RandomForestRegressor: 隨機森林迴歸器,用於迴歸任務
from sklearn.ensemble import RandomForestRegressor
# LinearRegression: 線性迴歸模型,用於迴歸任務
from sklearn.linear_model import LinearRegression
# XGBRegressor: XGBoost 迴歸器,基於梯度提升的高效機器學習模型
from xgboost import XGBRegressor
# KNeighborsRegressor: K 近鄰迴歸器,基於最近鄰的迴歸算法
from sklearn.neighbors import KNeighborsRegressor
# cross_val_score: 用於交叉驗證,評估模型性能
from sklearn.model_selection import cross_val_score
# mean_squared_error: 用於計算均方誤差,評估迴歸模型的性能
from sklearn.metrics import mean_squared_error
# metrics: 提供多種評估指標,用於模型性能評估
from sklearn import metrics
if __name__ == '__main__':
# 讀取 CSV 文件
data = pd.read_csv("diamonds.csv")
data = data.head(1000)
# 第一列看起來只是索引,因此將其刪除
data = data.drop(["Unnamed: 0"], axis=1)
# 顯示數據的描述性統計信息
data.describe()
# 刪除尺寸為零的鑽石記錄
data = data.drop(data[data["x"]==0].index)
data = data.drop(data[data["y"]==0].index)
data = data.drop(data[data["z"]==0].index)
# 再次顯示數據的形狀,以確認刪除操作
data.shape
# 設置色調
shade = ["#835656", "#baa0a0", "#ffc7c8", "#a9a799", "#65634a"]
# 繪製成對關係圖,使用"cut"作為色調
ax = sns.pairplot(data, hue= "cut",palette=shade)
# 繪製價格與'y'特徵的迴歸線
ax = sns.regplot(x="price", y="y", data=data, fit_reg=True, scatter_kws={"color": "#a9a799"}, line_kws={"color": "#835656"})
ax.set_title("Regression Line on Price vs 'y'", color="#4e4c39")
# 繪製價格與'z'特徵的迴歸線
ax= sns.regplot(x="price", y="z", data=data, fit_reg=True, scatter_kws={"color": "#a9a799"}, line_kws={"color": "#835656"})
ax.set_title("Regression Line on Price vs 'z'", color="#4e4c39")# 繪製價格與深度特徵的迴歸線
ax= sns.regplot(x="price", y="depth", data=data, fit_reg=True, scatter_kws={"color": "#a9a799"}, line_kws={"color": "#835656"})
ax.set_title("Regression Line on Price vs Depth", color="#4e4c39")
# 繪製價格與枱面特徵的迴歸線
ax=sns.regplot(x="price", y="table", data=data, fit_reg=True, scatter_kws={"color": "#a9a799"}, line_kws={"color": "#835656"})
ax.set_title("Regression Line on Price vs Table", color="#4e4c39")
# 刪除異常值
data = data[(data["depth"]<75)&(data["depth"]>45)]
data = data[(data["table"]<80)&(data["table"]>40)]
data = data[(data["x"]<30)]
data = data[(data["y"]<30)]
data = data[(data["z"]<30)&(data["z"]>2)]
# 再次顯示數據的形狀,以確認刪除操作
data.shape
# 使用 Seaborn 庫的 pairplot 函數創建一個配對圖
ax=sns.pairplot(data, hue= "cut",palette=shade)
# 獲取分類變量的列表
s = (data.dtypes =="object")
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
# 繪製切割質量與價格的提琴圖
plt.figure(figsize=(12,8))
ax = sns.violinplot(x="cut",y="price", hue='cut', data=data, palette=shade,legend=False)
ax.set_title("Violinplot For Cut vs Price", color="#4e4c39")
ax.set_ylabel("Price", color="#4e4c39")
ax.set_xlabel("Cut", color="#4e4c39")
# 繪製顏色與價格的提琴圖
# 設置繪圖尺寸
plt.figure(figsize=(12,8))
# 設置顏色調色板 shade_1,用於繪製顏色與價格的提琴圖
shade_1 = ["#835656","#b38182", "#baa0a0","#ffc7c8","#d0cd85", "#a9a799", "#65634a"]
# 繪製顏色與價格的提琴圖,設置顏色調色板為 shade_1,按數量縮放
ax = sns.violinplot(x="color",y="price", hue='color',data=data, palette=shade_1,legend=False)
# 設置圖表標題和座標軸標籤的顏色
ax.set_title("Violinplot For Color vs Price", color="#4e4c39")
ax.set_ylabel("Price", color="#4e4c39")
ax.set_xlabel("Color", color="#4e4c39")# 繪製淨度與價格的提琴圖
# 設置繪圖尺寸
plt.figure(figsize=(12,8))
# 設置顏色調色板 shade_2,用於繪製淨度與價格的提琴圖
shade_2 = ["#835656","#b38182", "#baa0a0","#ffc7c8","#f1f1f1","#d0cd85", "#a9a799", "#65634a"]
# 繪製淨度與價格的提琴圖,設置顏色調色板為 shade_2,按數量縮放
ax = sns.violinplot(x="clarity",y="price",hue='clarity', data=data, palette=shade_2,legend=False)
# 設置圖表標題和座標軸標籤的顏色
ax.set_title("Violinplot For Clarity vs Price", color="#4e4c39")
ax.set_ylabel("Price", color="#4e4c39")
ax.set_xlabel("Clarity", color="#4e4c39")
# 創建數據副本,避免更改原始數據
label_data = data.copy()
# 創建 LabelEncoder 實例
label_encoder = LabelEncoder()
# 遍歷分類變量列表,應用標籤編碼器
for col in object_cols:
label_data[col] = label_encoder.fit_transform(label_data[col])
# 顯示轉換後的數據前五行
label_data.head()
# 顯示數據的描述性統計信息
data.describe()
# 設置顏色映射 cmap,用於繪製相關性熱圖
cmap = sns.diverging_palette(70,20,s=50, l=40, n=6,as_cmap=True)
# 計算轉換後數據的協方差矩陣
corrmat= label_data.corr()
# 設置繪圖尺寸
f, ax = plt.subplots(figsize=(12,12))
# 繪製相關性熱圖,設置顏色映射為 cmap,並顯示數值註釋
sns.heatmap(corrmat,cmap=cmap,annot=True, )
# 將特徵 X 賦值為除去價格的所有列,目標變量 y 賦值為價格列
X= label_data.drop(["price"],axis =1)
y= label_data["price"]
# 將數據集劃分為訓練集和測試集,測試集大小為 25%,隨機種子為 7
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.25, random_state=7)
# 構建不同迴歸模型的管道,每個管道包括標準化和模型
pipeline_lr=Pipeline([("scalar1",StandardScaler()), ("lr_classifier",LinearRegression())])
pipeline_dt=Pipeline([("scalar2",StandardScaler()), ("dt_classifier",DecisionTreeRegressor())])
pipeline_rf=Pipeline([("scalar3",StandardScaler()), ("rf_classifier",RandomForestRegressor())])
pipeline_kn=Pipeline([("scalar4",StandardScaler()), ("rf_classifier",KNeighborsRegressor())])
pipeline_xgb=Pipeline([("scalar5",StandardScaler()), ("rf_classifier",XGBRegressor())])
# 構建不同迴歸模型的管道,每個管道包括標準化和模型
pipelines = [pipeline_lr, pipeline_dt, pipeline_rf, pipeline_kn, pipeline_xgb]
# 創建管道字典 pipe_dict,用於方便引用模型類型
pipe_dict = {0: "LinearRegression", 1: "DecisionTree", 2: "RandomForest",3: "KNeighbors", 4: "XGBRegressor"}
# 遍歷每個管道,擬合訓練數據
for pipe in pipelines:
pipe.fit(X_train, y_train)
# 初始化一個空列表,用於存儲不同模型的交叉驗證結果
cv_results_rms = []
# 遍歷 pipelines 列表中的每個模型及其索引
for i, model in enumerate(pipelines):
# 使用 10 折交叉驗證計算模型的負均方根誤差
cv_score = cross_val_score(model, X_train,y_train,scoring="neg_root_mean_squared_error", cv=10)
# 將交叉驗證結果添加到 cv_results_rms 列表
cv_results_rms.append(cv_score)
# 打印每個模型的平均交叉驗證結果
print("%s: %f " % (pipe_dict[i], cv_score.mean()))
# 使用 XGBRegressor 模型對測試數據進行預測
pred = pipeline_xgb.predict(X_test)
# 打印模型評估指標
print("R^2:",metrics.r2_score(y_test, pred))
print("Adjusted R^2:",1 - (1-metrics.r2_score(y_test, pred))*(len(y_test)-1)/(len(y_test)-X_test.shape[1]-1))
print("MAE:",metrics.mean_absolute_error(y_test, pred))
print("MSE:",metrics.mean_squared_error(y_test, pred))
print("RMSE:",np.sqrt(metrics.mean_squared_error(y_test, pred)))點擊左上角運行按鈕,運行代碼:
數據結果:
Categorical variables:
['cut', 'color', 'clarity']
LinearRegression: -209.588493
DecisionTree: -57.556786
RandomForest: -48.680239
KNeighbors: -58.089888
XGBRegressor: -66.447094
R^2: 0.9958575367927551
Adjusted R^2: 0.9957021944224834
MAE: 40.27821731567383
MSE: 2548.892578125
RMSE: 50.4865583905756圖示結果:
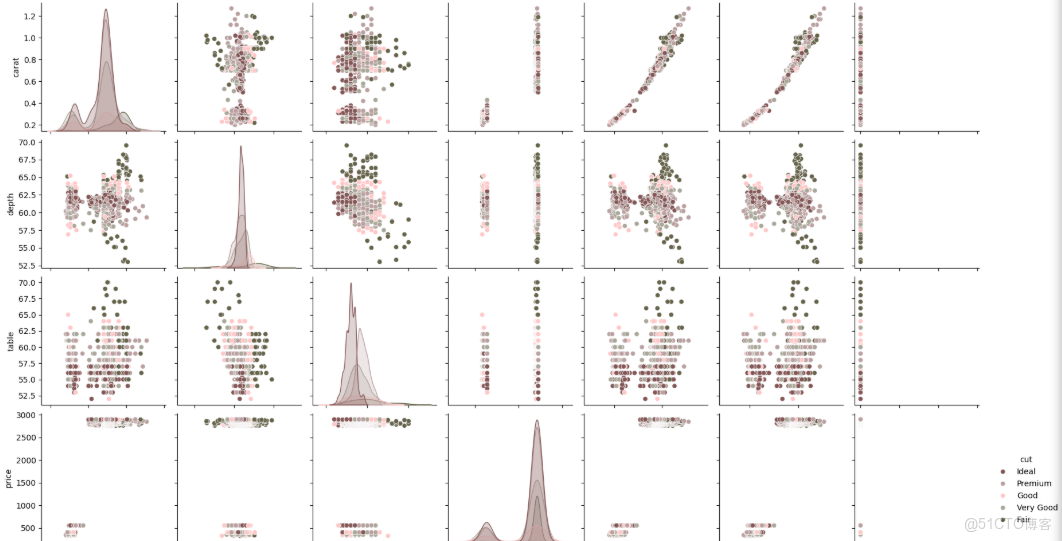

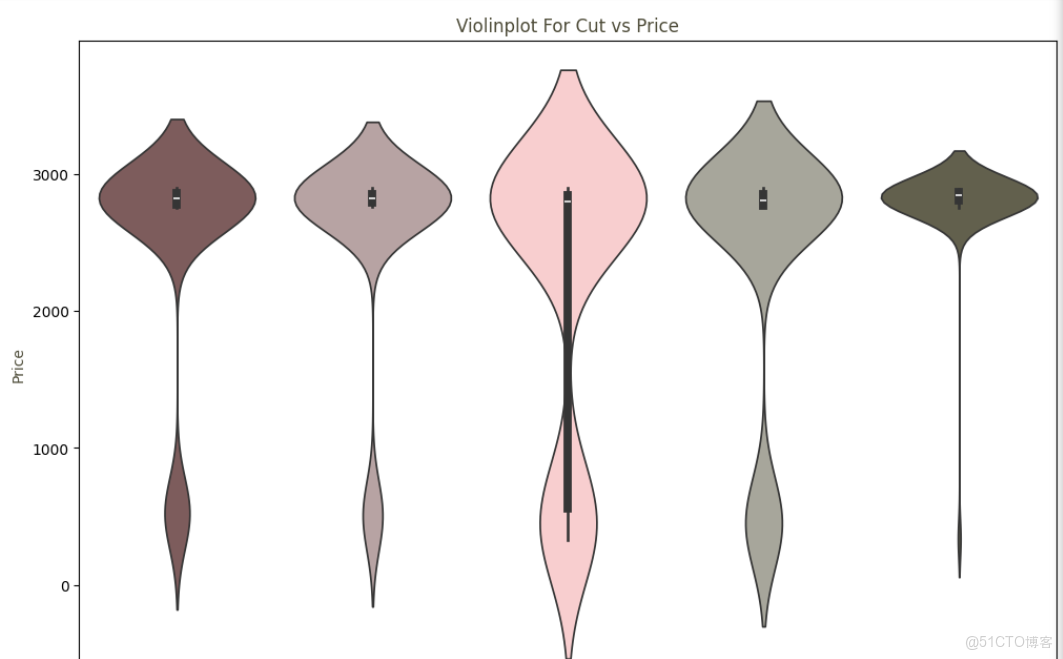

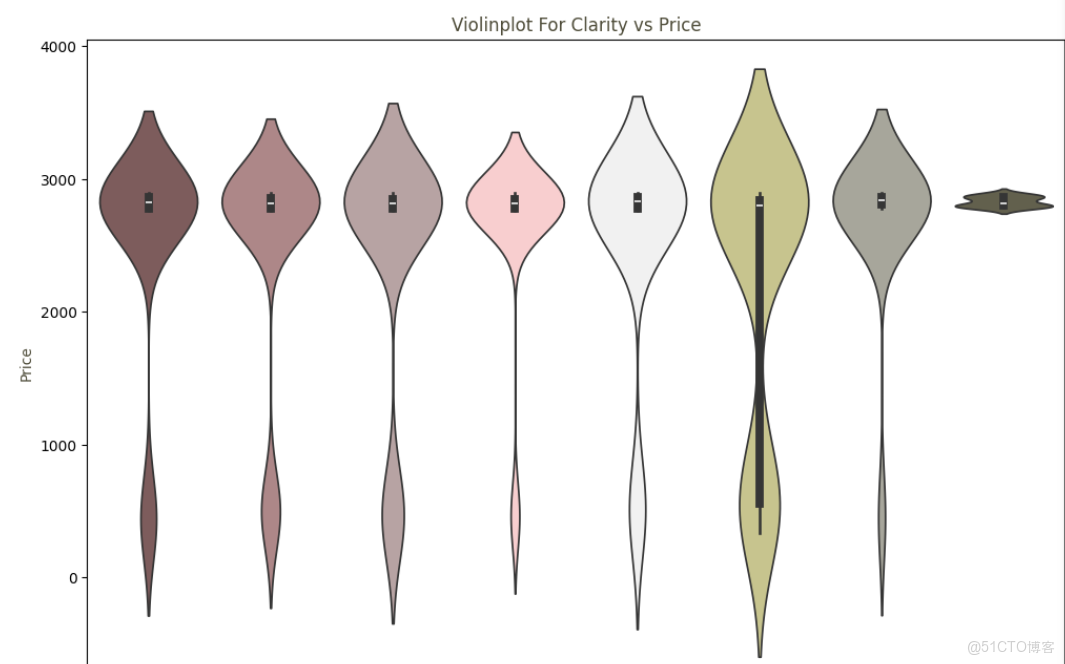
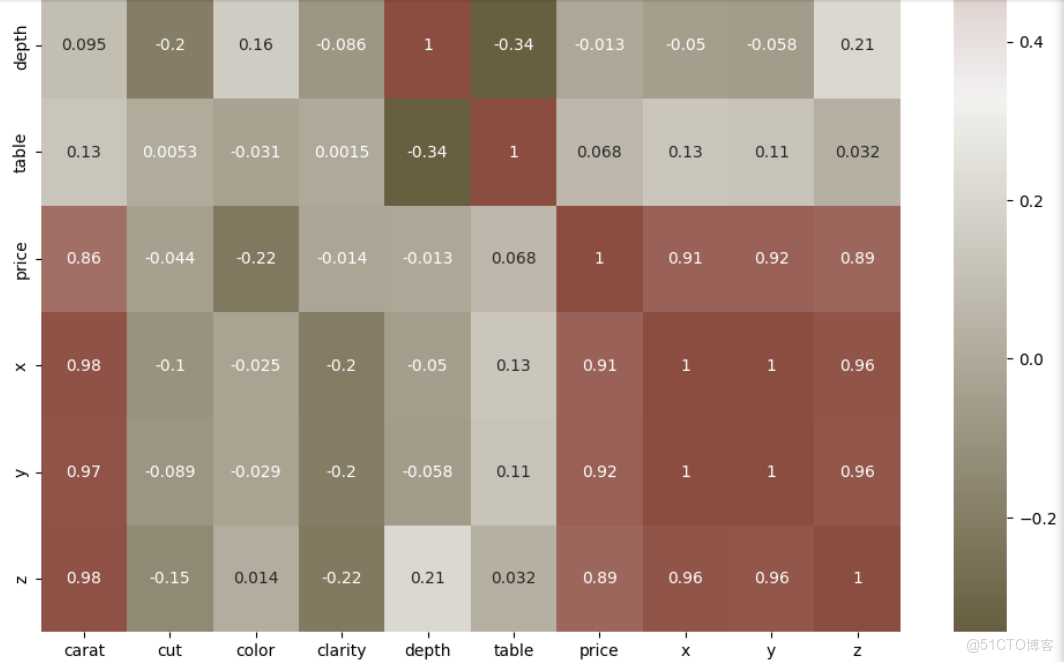
3.4 擴展閲讀與資源推薦
- 參考書籍
• 《Python 數據科學手冊》(Jake VanderPlas):涵蓋 NumPy、Pandas、Matplotlib 等核心庫的實戰技巧,適合快速掌握數據清洗、分析與可視化技能。書中代碼示例豐富,可直接應用於鑽石價格預測項目。
• 《 華為雲人工智能實踐指南》 :系統講解華為雲 AI 服務(如 ModelArts、MRS)的落地應用,包含數據存儲、模型訓練到部署的全流程案例,適合進階學習雲原生 AI 開發。
- 在線資源
• 華為雲學院-數據分析微認證課程:課程鏈接:涵蓋數據預處理、機器學習模型構建及華為雲工具鏈使用,完成課程可獲取官方認證證書。
• Kaggle 競賽案例:參考類似項目(如鑽石價格預測 ),學習基於機器學習的鑽石電商定價優化策略,實現數據驅動的精準價格預測。
- 工具文檔
• 代碼託管與協作:
– CodeArts:華為雲提供的代碼託管和項目管理服務。
• 數據可視化:
– Matplotlib:Python 的 2D 繪圖庫,用於生成折線圖、散點圖等。
– Seaborn:基於 Matplotlib 的 Python 數據可視化庫,專注於統計圖形。
• 數據處理與分析:
– Pandas:Python 數據分析庫,提供數據結構和數據分析工具。
– NumPy:Python 科學計算庫,用於處理大型多維數組和矩陣。
• 機器學習:
– Scikit-learn:Python 機器學習庫,提供簡單有效的數據挖掘和數據分析工具。
– XGBoost:基於梯度提升的機器學習庫,用於分類、迴歸等任務。
這些工具和文檔在項目實施過程中起到了關鍵作用,提供了必要的功能支持、指導以及最佳實踐。通過以上資源,讀者可深化數據科學理論、提升工程實踐能力,並掌握華為雲生態工具的高效使用,為複雜業務場景提供端到端解決方案。