

最新案例動態,請查閲【案例共創】線性分類器與支持向量機 - 新聞標題主題分類(SVM)。小夥伴們快來領取華為開發者空間進行實操吧!
本案例由:梅科爾工作室提供
1 概述
1.1 案例介紹
在機器學習領域,分類的目標是指將具有相似特徵的對象聚集。而一個線性分類器則透過特徵的線性組合來做出分類決定,以達到此種目的。
支持向量機(Support Vector Machine, SVM)是一種廣泛應用於機器學習的監督學習模型,主要用於分類和迴歸任務。其核心思想是通過尋找一個最優超平面,將不同類別的樣本分開,並最大化類別之間的間隔。
本案例通過在開發者空間Notebook中,基於SVM並使用MindSpore框架進行數據預處理和詞向量訓練,對新聞標題進行預測分類。
通過本案例可以對線性分類器與⽀持向量機進行學習,同時瞭解MindSpore框架的使用。
1.2 適用對象
- 企業
- 個人開發者
- 高校學生
1.3 案例時間
本案例總時長預計30分鐘。
1.4 案例流程
説明:
- 登錄開發者空間,啓動Notebook;
- 在Notebook中編寫代碼運行調試。
1.5 資源總覽
本案例預計花費總計0元。
|
資源名稱 |
規格 |
單價(元) |
時長(分鐘) |
|
開發者空間—Notebook
|
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
|
免費
|
30
|
2 資源與開發環境準備
2.1 啓動Notebook
參考“DeepSeek模型API調用及參數調試(開發者空間Notebook版)”案例的第2.2章節啓動Notebook。
2.2 安裝依賴庫
在Notebook的新執行框中輸入如下代碼並運行,安裝所有依賴庫。
!pip install --upgrade pip setuptools wheel
!pip install numpy
!pip install mindspore
!pip install jieba
!pip install scikit-learn
!pip install joblib
!pip install pandas
!pip install gensim3 新聞標題主題分類
- 導入必要的庫
- jieba:用於中文文本的分詞處理。
- numpy (np):用於數值計算和數組操作。
- pandas (pd):用於數據處理和分析。
- subprocess:用於執行系統命令,例如下載數據集。
- mindspore:深度學習框架,用於構建和訓練模型。
- gensim.models.word2vec.Word2Vec:用於訓練詞向量模型。
- sklearn.model_selection.train_test_split:用於劃分訓練集和測試集。
- sklearn.metrics.accuracy_score, classification_report:用於評估模型性能。
- joblib:用於保存和加載模型。
在Notebook的新執行框中輸入如下代碼並運行,導入所有使用到的庫。
import jieba
import numpy as np
import pandas as pd
import subprocess
import mindspore as ms
from mindspore import Tensor, nn, ops
from mindspore.dataset import GeneratorDataset
from gensim.models.word2vec import Word2Vec
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import joblib3.1 下載數據集
使用Git命令從遠程倉庫下載新聞標題分類的數據集。如果下載成功,打印“文件下載成功!”;如果失敗,打印錯誤信息。
在Notebook的新執行框中輸入如下代碼並運行:
command = ["git", "clone", "https://source-xihe.mindspore.cn/makercxj/NewsTitle_classify.git"]
# 執行命令
try:
subprocess.run(command, check=True)
print("文件下載成功!")
except subprocess.CalledProcessError as e:
print(f"下載失敗: {e}")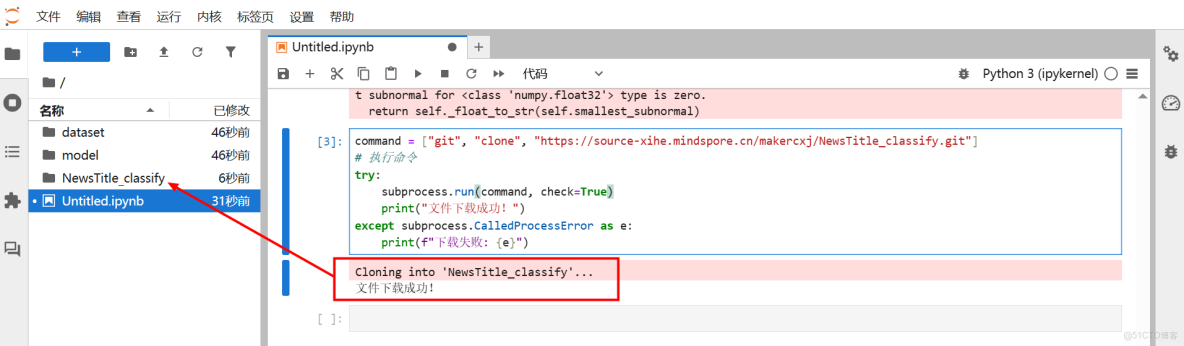
3.2 加載數據
使用Pandas讀取兩個文本文件,一個是文化體育類新聞標題(正類),另一個是生態環境類新
聞標題(負類)。
在Notebook的新執行框中輸入如下代碼並運行:
pos = pd.read_csv('NewsTitle_classify/culture_title.txt', encoding='UTF-8', header=None)
neg = pd.read_csv('NewsTitle_classify/nature_title.txt', encoding='UTF-8',header=None)3.3 數據預處理
對每個新聞標題進行分詞處理,將標題切分成一個個的詞。
在Notebook的新執行框中輸入如下代碼並運行:
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x))
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x))合併數據和標籤
將正類和負類的分詞結果合併為一個數組x,創建標籤數組y,正類標籤為1,負類標籤為0。
在Notebook的新執行框中輸入如下代碼並運行:
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)), np.zeros(len(neg))))3.4 訓練詞向量
使用Word2Vec模型訓練詞向量,將每個詞映射到300維的向量空間,並保存訓練好的詞向量模型。
在Notebook的新執行框中輸入如下代碼並運行:
word2vec = Word2Vec(x, vector_size=300, window=3, min_count=5, sg=1, hs=1,epochs=10, workers=25)
word2vec.save('word2vec.model')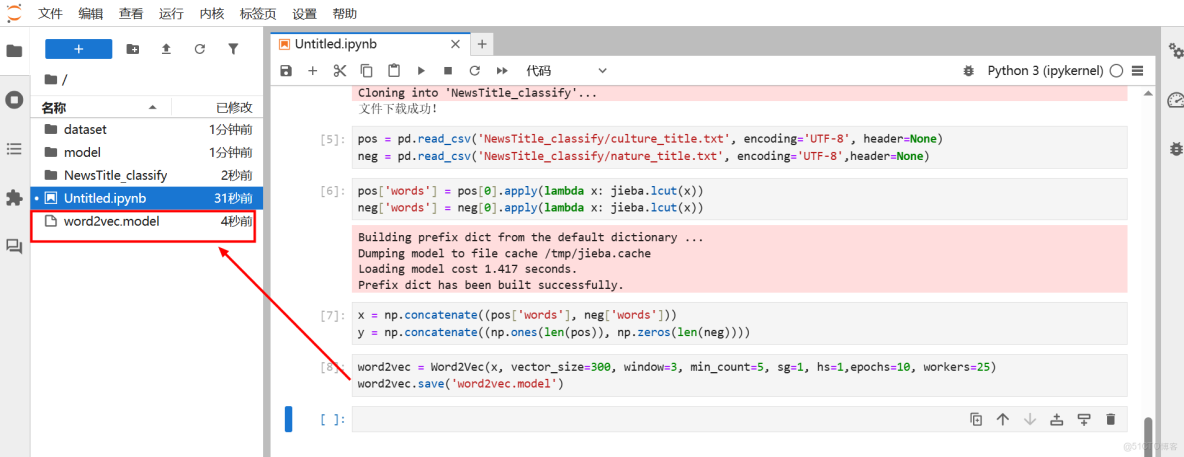
3.5 定義函數將詞向量轉換為特徵向量
定義函數total_vector ,將每個新聞標題的詞向量相加,得到一個固定長度的特徵向量。
在Notebook的新執行框中輸入如下代碼並運行:
def total_vector(words):
vec = np.zeros(300)
for word in words:
try:
vec += word2vec.wv[word]
except KeyError:
continue
return vec3.6 生成訓練數據的特徵向量
將所有新聞標題轉換為特徵向量,形成訓練數據。
在Notebook的新執行框中輸入如下代碼並運行:
train_vec = np.array([total_vector(words) for words in x])3.7 劃分訓練集和測試集
將數據集劃分為訓練集和測試集,測試集佔20%。
在Notebook的新執行框中輸入如下代碼並運行:
X_train, X_test, y_train, y_test = train_test_split(train_vec, y,test_size=0.2, random_state=42)
3.8 轉換為MindSpore tensor
將NumPy數組轉換為MindSpore的Tensor,以便在MindSpore框架中使用。
在Notebook的新執行框中輸入如下代碼並運行:
X_train_ms = Tensor(X_train, dtype=ms.float32)
y_train_ms = Tensor(y_train, dtype=ms.float32)
X_test_ms = Tensor(X_test, dtype=ms.float32)
y_test_ms = Tensor(y_test, dtype=ms.float32)3.9 定義SVM模型(使用邏輯迴歸替代)
定義一個簡單的線性模型,用於二分類任務。
在Notebook的新執行框中輸入如下代碼並運行:
class SVM(nn.Cell):
def __init__(self, input_size):
super(SVM, self).__init__()
self.linear = nn.Dense(input_size, 1)
def construct(self, x):
return self.linear(x)3.10 初始化模型、損失函數和優化器
初始化模型、二分類交叉熵損失函數和Adam優化器。
在Notebook的新執行框中輸入如下代碼並運行:
model = SVM(300)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = nn.Adam(model.trainable_params(), learning_rate=0.001)3.11 定義訓練網絡
使用MindSpore的WithLossCell 和TrainOneStepCell 構建訓練網絡。
在Notebook的新執行框中輸入如下代碼並運行:
net_with_loss = nn.WithLossCell(model, loss_fn)
train_net = nn.TrainOneStepCell(net_with_loss, optimizer)3.12 訓練模型
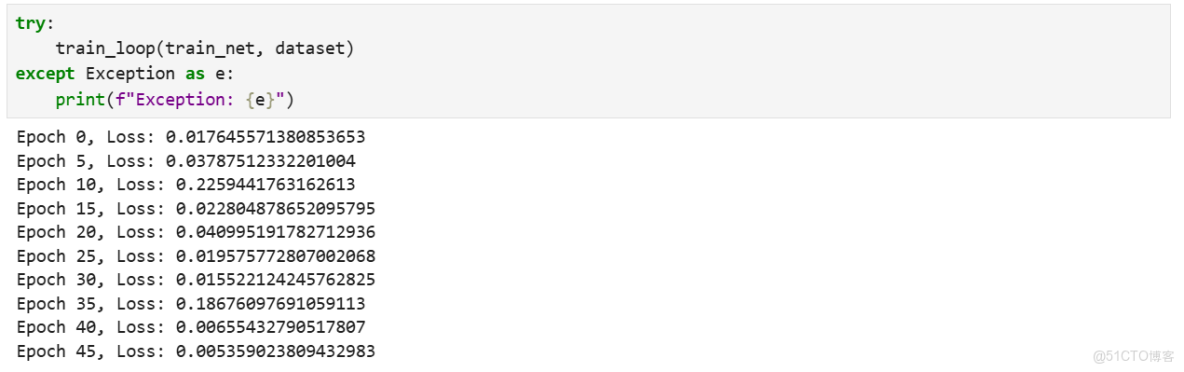
定義訓練循環,訓練模型50個epoch,並每5個epoch打印一次損失值。
在Notebook的新執行框中輸入如下代碼並運行:
def train_loop(train_net, dataset):
model.set_train()
for epoch in range(50):
for data, label in dataset:
label = label.view(-1, 1)
loss = train_net(data, label)
if epoch % 5 == 0:
print(f"Epoch {epoch}, Loss: {loss.asnumpy()}")3.13 創建數據集
使用MindSpore的GeneratorDataset 創建數據集,並設置批量大小為32。
在Notebook的新執行框中輸入如下代碼並運行:
dataset = GeneratorDataset(list(zip(X_train_ms, y_train_ms)), ['data','label'])
dataset = dataset.batch(32)3.14 訓練模型
調用訓練函數,開始訓練模型。
在Notebook的新執行框中輸入如下代碼並運行:
try:
train_loop(train_net, dataset)
except Exception as e:
print(f"Exception: {e}")訓練結果打印如下(每次運行結果不盡相同,內容僅作參考):
3.15 在測試集上評估模型
將模型設置為評估模式,對測試集進行預測,並計算準確率和分類報告。
在Notebook的新執行框中輸入如下代碼並運行:
model.set_train(False)
y_pred = (model(X_test_ms).asnumpy() 0.5).astype(int)
print(f"模型準確率: {accuracy_score(y_test, y_pred):.4f}")
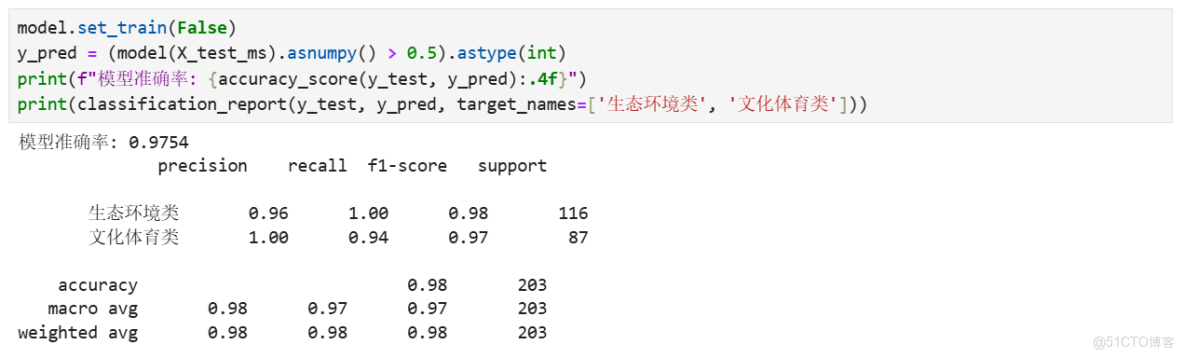
print(classification_report(y_test, y_pred, target_names=['生態環境類', '文化體育類']))評估結果參考如下(每次運行結果不盡相同,內容僅作參考):
3.16 定義預測函數
定義預測函數,對新輸入的文本進行分類預測。
在Notebook的新執行框中輸入如下代碼並運行:
def svm_predict(query):
words = jieba.lcut(query)
vec = total_vector(words)
vec_ms = Tensor(vec.reshape(1, -1), dtype=ms.float32)
result = (model(vec_ms).asnumpy() 0.5).astype(int)
proba = ops.Sigmoid()(model(vec_ms)).asnumpy()[0][0]
if int(result) == 1:
print(f'類別:文化體育類 (概率: {proba:.4f})')
else:
print(f'類別:生態環境類 (概率: {1 - proba:.4f})')3.17 測試預測
測試兩個示例文本的分類結果。
在Notebook的新執行框中輸入如下代碼並運行:
svm_predict('文化體育融合新發展,全民共享健康生活')
svm_predict('生態修復與保護加速推進,綠色發展繪就美麗未來')測試結果參考如下(每次運行結果不盡相同,內容僅作參考):

4 總結
根據上述訓練預測結果,總結如下:
4.1 模型性能
- 模型在測試集上的準確率達到97.54%,表明模型具有很高的分類準確性。
- 分類報告顯示,模型對兩個類別的精確度(precision)、召回率(recall)和F1分數都非常高。
4.2 預測能力
模型能夠對新的新聞標題進行準確分類,並給出分類的概率值。例如:
- 對於標題“文化體育融合新發展,全民共享健康生活”,模型預測其屬於“文化體育類”,
概率為0.8426。
- 對於標題“生態修復與保護加速推進,綠色發展繪就美麗未來”,模型預測其屬於“生態環
境類”,概率為0.9994。
4.3 模型保存與部署
- 保存訓練好的詞向量模型,便於後續的應用和部署。
- MindSpore提供了豐富的工具和模塊,支持模型的進一步優化和部署。
至此,新聞標題主題分類案例結束。點擊鏈接參考完整案例代碼。