

最新案例動態,請查閲【案例共創】線性迴歸 - 汽車行駛里程與油耗關係預測。小夥伴們快來領取華為開發者空間進行實操吧!
本案例由:梅科爾工作室提供
1 概述
1.1 案例介紹
在機器學習領域,線性迴歸就是使用一個線性函數(多項式迴歸可以是曲線)去擬合給定的訓練集,測試時,對輸入的x值,返回這個線性函數的y值。最終目標是找到y=Θ0 + Θ1x1 + Θ2x2 + …… + Θnxn 函數式中的Θ0、Θ1、Θ2、……、Θn值。
本案例通過在開發者空間Notebook中,基於numpy並使用MindSpore框架進行訓練神經網絡,輸出汽車行駛里程和油耗之間的關係預測。
通過本案例可以對線性迴歸進行學習,同時瞭解MindSpore框架的使用。
1.2 適用對象
- 企業
- 個人開發者
- 高校學生
1.3 案例時間
本案例總時長預計30分鐘。
1.4 案例流程
説明:
- 登錄開發者空間,啓動Notebook;
- 在Notebook中編寫代碼運行調試。
1.5 資源總覽
本案例預計花費總計0元。
|
資源名稱 |
規格 |
單價(元) |
時長(分鐘) |
|
開發者空間—Notebook |
NPU basic · 1 * NPU 910B · 8v CPU · 24GB
euler2.9-py310-torch2.1.0-cann8.0-openmind0.9.1-notebook
|
免費 |
30 |
2 資源與開發環境準備
2.1 啓動Notebook
參考“DeepSeek模型API調用及參數調試(開發者空間Notebook版)”案例的第2.2章節啓動Notebook。
2.2 安裝依賴庫
在Notebook的新執行框中輸入如下代碼並運行,安裝所有依賴庫。
!pip install numpy
!pip install mindspore
!pip install pandas
!pip install matplotlib3 汽車行駛里程與油耗關係預測
1. 導入必要的庫
- numpy (np):用於數值計算。
- mindspore:用於構建和訓練神經網絡。
- 張量操作:提供張量數據結構和相關的操作。
- 神經網絡構建:用於定義模型、損失函數和優化器。
- 自動微分:自動計算梯度,用於模型的訓練。
- 數據轉換:將numpy數組轉換為Tensor,以便在mindspore框架中進行計算。
- **模型輸入和輸出:**作為模型的輸入和輸出數據類型。
在Notebook的新執行框中輸入如下代碼並運行,導入所有使用到的庫。
import numpy as np
import mindspore as ms
from mindspore import Tensor
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore", category=UserWarning)2. 數據加載與預處理 數據準備:將如下鏈接數據集下載,並通過notebook上傳。 <https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0038/auto-mpg.data>
下載到本地的數據

點擊Notebook左上角上傳按鈕,選中下載的數據集,進行上傳。
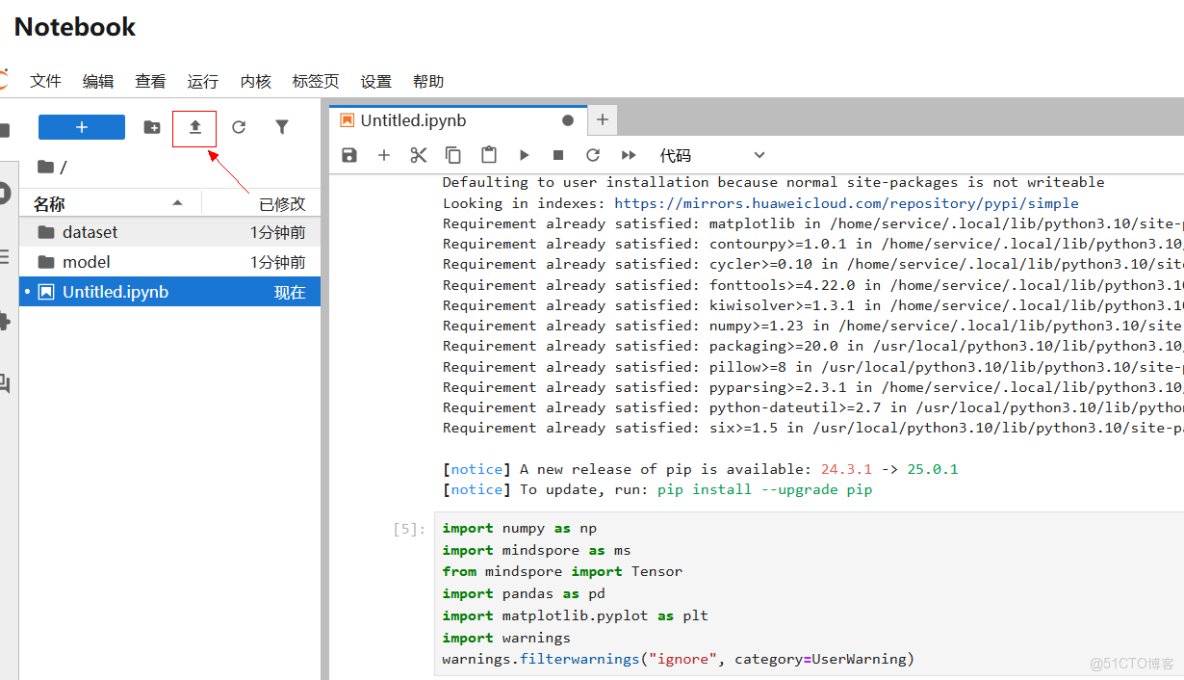
數據上傳成功:
在Notebook的新執行框中輸入如下代碼並運行:
# 加載數據
path = 'auto-mpg.data'
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight",
"acceleration", "model year", "origin", "car name"]
cars = pd.read_csv(path, delim_whitespace=True, names=columns)
# 數據預處理
cars = cars[cars.horsepower != '?']
cars['horsepower'] = cars['horsepower'].astype(float)數據準備: ▪ 這段代碼使用pandas 加載汽車數據集,並對數據進行初步處理。由於數據中
的“horsepower”列包含字符串“?”,代碼過濾掉這些行,並將“horsepower”列轉換
為浮點數類型。這一步是必要的,因為機器學習模型需要數值型數據進行訓練。
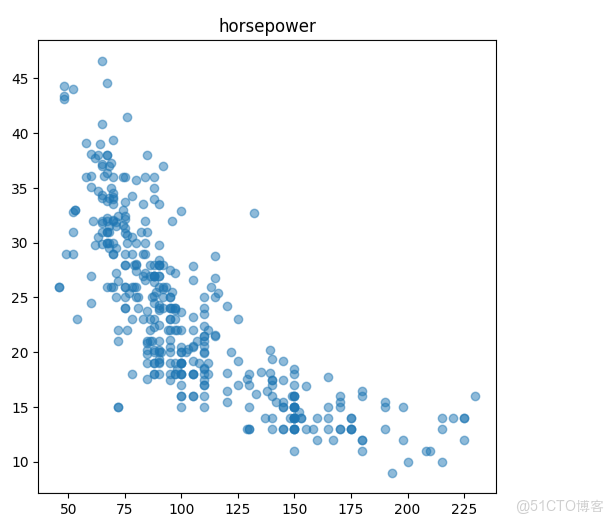
3. 數據可視化
這裏使用 matplotlib 打造了一個可視化界面,展示了不同特性(氣缸數、排量、重量、加速度、馬力)與燃油效率(mpg)之間的關係。這一步有助於理解數據特性以及各特性與目標變量之間的關係。
在Notebook的新執行框中輸入如下代碼並運行:
#可視化數據
fig = plt.figure(figsize=(13, 20))
ax1 = fig.add_subplot(321)
ax2 = fig.add_subplot(322)
ax3 = fig.add_subplot(323)
ax4 = fig.add_subplot(324)
ax5 = fig.add_subplot(325)
ax1.scatter(cars['cylinders'], cars['mpg'], alpha=0.5)
ax1.set_title('cylinders')
ax2.scatter(cars['displacement'], cars['mpg'], alpha=0.5)
ax2.set_title('displacement')
ax3.scatter(cars['weight'], cars['mpg'], alpha=0.5)
ax3.set_title('weight')
ax4.scatter(cars['acceleration'], cars['mpg'], alpha=0.5)
ax4.set_title('acceleration')
ax5.scatter(cars['horsepower'], cars['mpg'], alpha=0.5)
ax5.set_title('horsepower')
plt.show()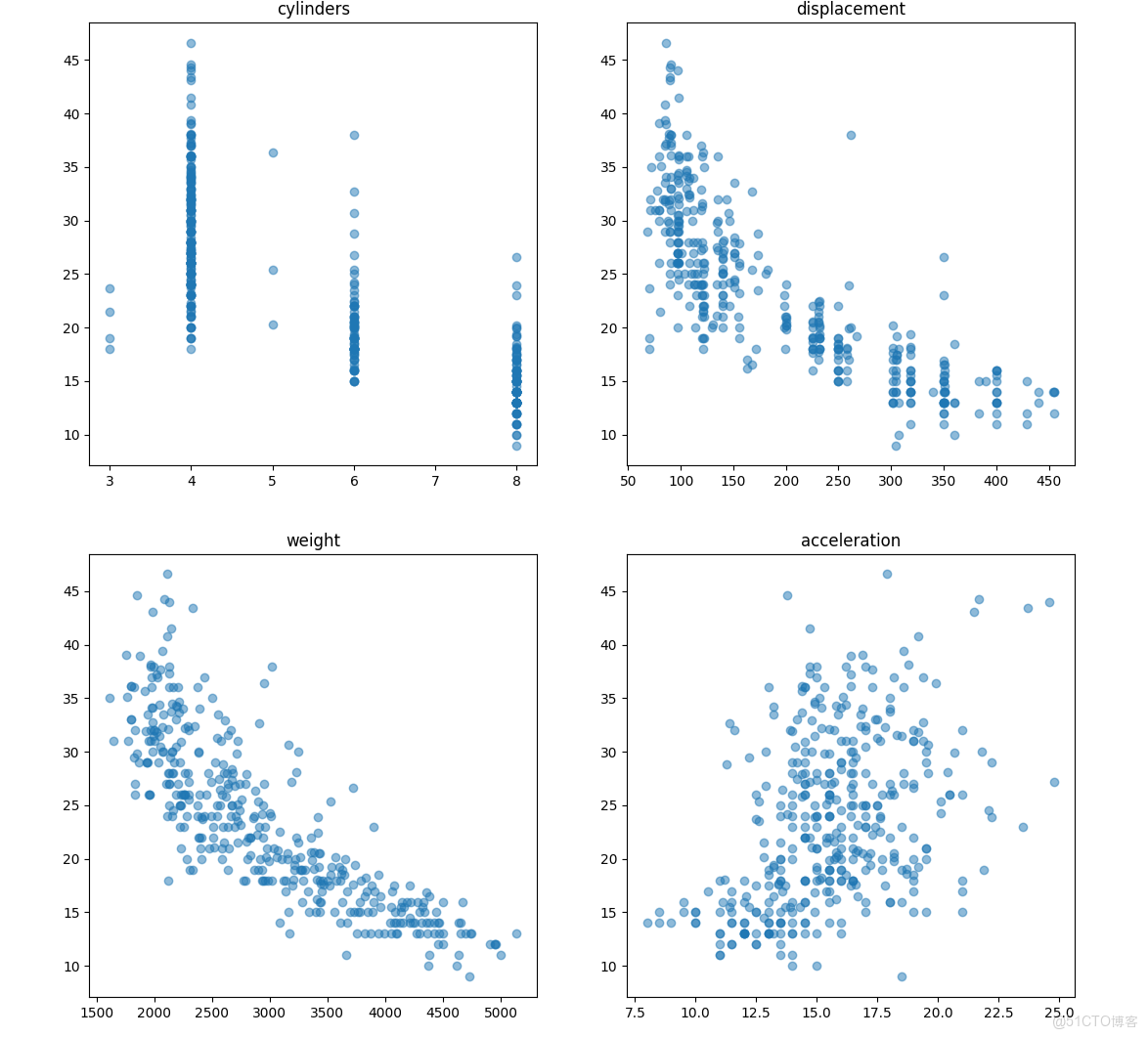
4. 準備數據集
這個模塊將“weight”選為特徵變量,“mpg”作為目標變量。然後使用 train_test_split函數將數據劃分為訓練集和測試集,測試集佔總數據的20%。這是為了在訓練模型後有一個獨立的數據集來評估模型的性能。
在Notebook的新執行框中輸入如下代碼並運行:
# 準備數據
Y = cars['mpg']
X = cars[['weight']]
# 劃分數據集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2,
random_state=0)5. 數據轉換為MindSpore張量
將數據轉換為 MindSpore 張量,以便在 MindSpore 框架中使用這些數據進行模型訓練。
在Notebook的新執行框中輸入如下代碼並運行:
# 轉換為 MindSpore 張量
X_train_tensor = Tensor(X_train.values, dtype=ms.float32)
Y_train_tensor = Tensor(Y_train.values, dtype=ms.float32)
X_test_tensor = Tensor(X_test.values, dtype=ms.float32)
Y_test_tensor = Tensor(Y_test.values, dtype=ms.float32)6. 模型訓練與評估
將數據從 MindSpore 張量轉換回 numpy 數組,用於訓練 scikit-learn 的線性迴歸模型。輸出模型的權重和偏置,並計算模型在測試集上的得分,以評估模型的性能。
在Notebook的新執行框中輸入如下代碼並運行:
# 轉換回 numpy 數組用於 scikit-learn 模型
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1, 1)
Y_train = Y_train.values
Y_test = Y_test.values
# 構建和訓練線性迴歸模型
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, Y_train)
# 輸出模型參數
print(f"Weight: {lr.coef_[0]}, Bias: {lr.intercept_}")
# 評估模型
print(f"Score: {lr.score(X_test, Y_test)}")7. 可視化結果
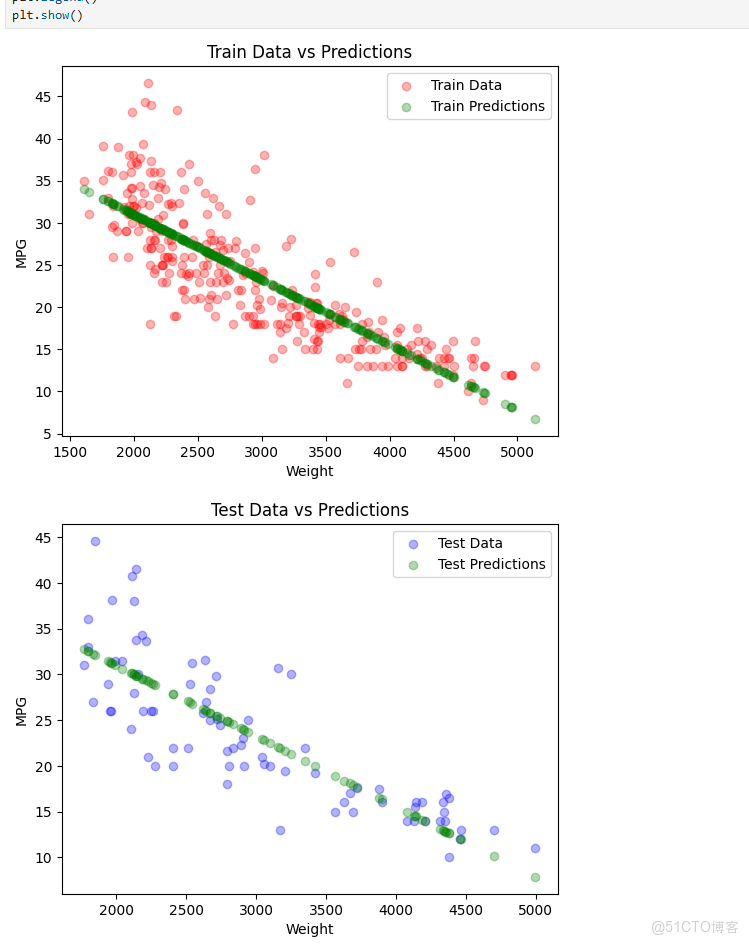
繪製了訓練集和測試集的預測結果與真實值的散點圖,幫助直觀地評估模型的預測性能。
在Notebook的新執行框中輸入如下代碼並運行:
# 可視化結果
plt.scatter(X_train, Y_train, color='red', alpha=0.3, label='Train Data')
plt.scatter(X_train, lr.predict(X_train), color='green', alpha=0.3,
label='Train Predictions')
plt.xlabel('Weight')
plt.ylabel('MPG')
plt.title('Train Data vs Predictions')
plt.legend()
plt.show()
plt.scatter(X_test, Y_test, color='blue', alpha=0.3, label='Test Data')
plt.scatter(X_test, lr.predict(X_test), color='green', alpha=0.3, label='Test Predictions')
plt.xlabel('Weight')
plt.ylabel('MPG')
plt.title('Test Data vs Predictions')
plt.legend()
plt.show()運行結果:
8. 計算黑塞矩陣
黑塞矩陣計算:將 X_train 轉換為包含偏置項的 numpy 數組,然後計算其轉置與⾃⾝的點積,得到黑塞矩陣。
在Notebook的新執行框中輸入如下代碼並運行:
# 計算⿊塞矩陣
X_matrix = X_train.copy()
X_matrix = np.hstack((X_matrix, np.ones((X_matrix.shape[0], 1)))) # 添加偏置項
Hessian = np.dot(X_matrix.T, X_matrix)
print(f"黑塞矩陣:\n{Hessian}")
4 總結
根據上述訓練預測結果,總結如下:
1. 模型參數
- 訓練完成後,模型會輸出兩個參數:Bias(偏置項)和Weight(里程數的權重)。
2. 可視化
- 可視化預測結果。
3. 黑塞矩陣
- 計算了黑塞矩陣,用於衡量損失函數在參數空間中的曲率,反映了模型參數的敏感性和優化的穩定性。